HIT-大数据分析Lab1:数据预处理-实验记录
本文是哈工大大数据分析实验1的完整实验记录,包括环境搭建,相关基础知识以及完整的实验解析,希望对后来人有所帮助(小白help小白)
本文是哈工大大数据分析实验1的完整实验记录,包含环境配置,相关知识介绍以及实验解析。希望对后来人有帮助(新手小白没什么头绪,走一步查一步对应的博客o(╥﹏╥)o),博客链接之间会穿插一些我自己的理解,讲的不是太好,介意的话可以顺序点开推荐博客的链接详细阅读
环境配置
基于Linux的Hadoop伪分布式安装
环境配置方面,我使用ubuntu虚拟机进行hadoop伪分布集群搭建(小白主要怕都装在windows后续其他实验可能会出现环境冲突,但我后来发现,直接在windows底下搭建环境流程的复杂程度也差不多,怕麻烦的话直接无脑windows)
这里有个小tip,就是windows上下载的安装包/其他文件,都可以通过拖拽的形式复制到虚拟机里边,可以不需要再配置共享文件夹(当然如果希望虚拟机和本机上同时共享最新版本的文件,还是需要配置一下的)或者通过ssh才能向虚拟机传文件
具体环境配置可以参考这篇博客,我全程跟下来没有发现错误(至于版本问题大家自己再去查一下其他资料,jdk/hadoop版本过高过低都可能有问题)
基于Linux的Hadoop伪分布式安装
修改配置文件的时候会用到vim,相关的操作命令如下,其实只要掌握"i"和":wq"好像也就够用了
vim命令大全
每次启动HDFS伪分布式系统,在控制台输入的指令如下:
# '#'后为注释,使用时可删去
# 启动hdfs
start-all.sh
# 显示进程:有6个进程表示正常
jps
# 退出hdfs
#如果中途停止实验,在关闭虚拟机之前一定一定要先退出hdfs,要不hdfs会出问题,可能需要重新格式化hdfs
stop-all.sh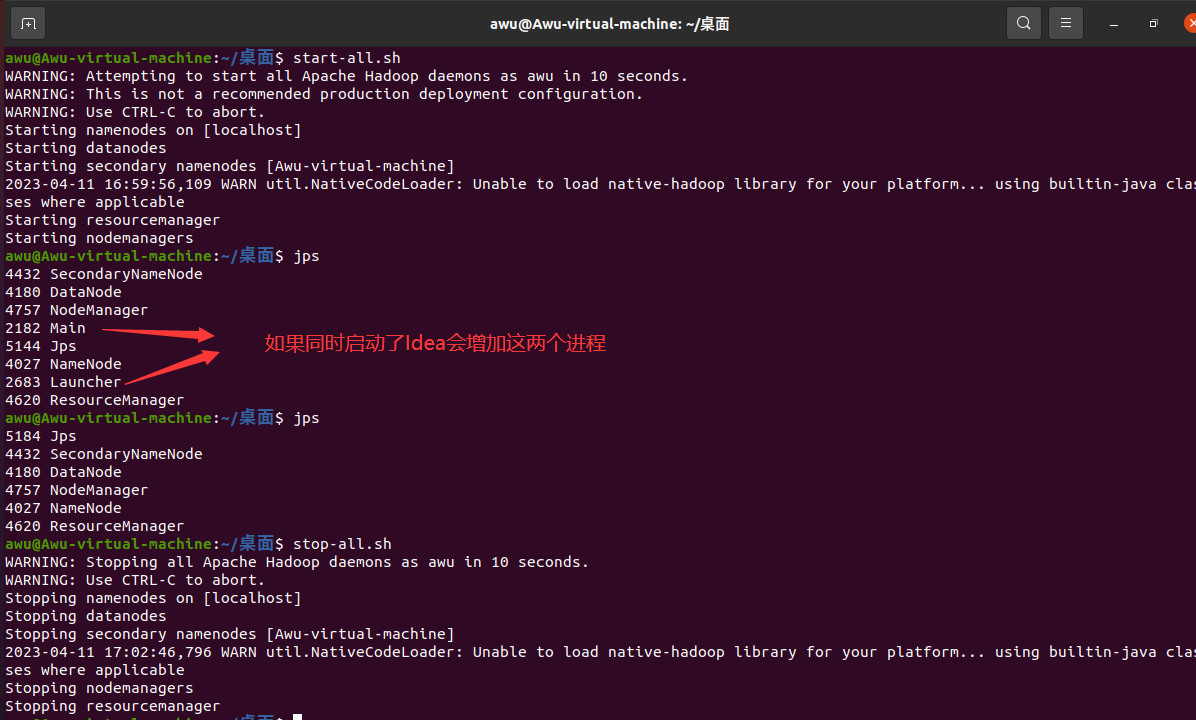
Idea安装配置
由于编程需要,我在ubantu也装了idea,此处安装专业版本和社区版本对实验没有影响
因为需要调用hadoop的包,所以需要在idea导入相关的jar包
project structure 》module 》dependencies
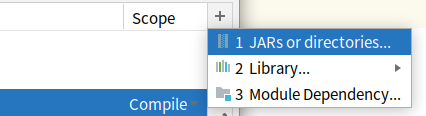
无脑勾选<hadoop安装路径>/share/hadoop下的6个文件夹

上传实验数据
这里需要学习一部分HDFS的相关指令,上传文件命令可参考这篇博客,同样的也只需要学习其中几个命令,比如"hdfs dfs -mkdir""hadoop fs -put"差不多够用了
如何上传文件到hdfs?
注意Hadoop3.之后,Namenode的web默认访问端口为9870,已经不是博客写的50070,浏览器直接搜"localhost:9870"就会弹出网页,搜索框里搜索新建文件夹的名字就可以知道是否成功上传文件了
至于其他更多指令,可以查看上面这篇博客引用的另外一篇博客
HDFS基本命令行操作及上传文件的简单API
Hadoop相关知识学习
实验根据指导书的提示,需要用到map-reduce,这里可以参考一波官方文档Hadoop Map/Reduce教程,但是从我个人角度,官方文档对我帮助不大,所以我找了其他参考价值更大的博客
MapReduce程序总览
官方文档主要介绍了各个组件的作用,但是并没有太细致的讲解程序的流程(比如参数传递之类的,但是这个对程序的编写很重要,毕竟使用mapper&reducer时是靠重写里边的函数来具体实现功能的),所以我找了其他几篇详细注释了程序流程的博客
MapReduce基础入门(一)
【其他更多博客可见-涂涂的主页-第5页的某些文章】
Mapper / Reducer
从上面那篇博客中,我们可以学习到
/**
* WordCount程序Mapper重写
* Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
*
* KEYIN 是指框架读取到的数据的key的类型,在默认的InputFormat下,读到的key是一行文本的起始偏移量,所以key的类型是Long
* VALUEIN 是指框架读取到的数据的value的类型,在默认的InputFormat下,读到的value是一行文本的内容,所以value的类型是String
* KEYOUT 是指用户自定义逻辑方法返回的数据中key的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的key是单词,所以是String
* VALUEOUT 是指用户自定义逻辑方法返回的数据中value的类型,由用户业务逻辑决定,在此wordcount程序中,我们输出的value是单词的数量,所以是Integer
*
* 但是,String ,Long等jdk中自带的数据类型,在序列化时,效率比较低,hadoop为了提高序列化效率,自定义了一套序列化框架
* 所以,在hadoop的程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop序列化框架的数据类型
*
* Long ----> LongWritable
* String ----> Text
* Integer ----> IntWritable
* Null ----> NullWritable
*/
static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
for(String word: words){
context.write(new Text(word), new IntWritable(1));
}
}
}/**
* WordCount程序Reducer重写
* 首先,和前面一样,Reducer类也有输入和输出,输入就是Map阶段的处理结果,输出就是Reduce最后的输出
* reducetask在调我们写的reduce方法,reducetask应该收到了前一阶段(map阶段)中所有maptask输出的数据中的一部分
* (数据的key.hashcode%reducetask数==本reductask号),所以reducetaks的输入类型必须和maptask的输出类型一样
*
* reducetask将这些收到kv数据拿来处理时,是这样调用我们的reduce方法的:
* 先将自己收到的所有的kv对按照k分组(根据k是否相同)
* 将某一组kv中的第一个kv中的k传给reduce方法的key变量,把这一组kv中所有的v用一个迭代器传给reduce方法的变量values
*/
static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
for(IntWritable v: values){
sum += v.get();
}
context.write(key, new IntWritable(sum));
}
}从这里边我们大概知道了Mapper&Reducer类的四个参数分别是:输入key,输入value,输出key,输出value;其中Mapper类输出与Reducer输入类型相对应。具体类型可以根据程序实际编写的内容在main函数中通过setMapOutputKeyClass / setMapOutputValueClass & setOutputKeyClass / setOutputValueClass指定,并且为了程序效率通常使用序列化的类型
map函数中有三个参数,前两个参数与Mapper参数列表的前两个相对应,表示输入数据的key和value;第三个参数Context表示map函数的输出,类型与Mapper参数列表后两个相对应;reduce函数也大概如此,但是第二个参数是Mapper产生的相同key对应的不同value的集合,故具体处理时,通常是一个遍历框架
但是在理解学长火炬的过程中,我发现实现功能时,不仅仅只重写了map/reduce函数,还重写了Mapper/Reducer类下的其他函数,所以我又学习了其他博客
MapReduce学习笔记(二)——Mapper、Reducer和Driver
大家也可以通过在idea中ctrl然后选中Mapper/Reducer查看默认类是怎么编写的
Mapper中一共有4个方法分别为seup、run、map、cleanup。setup在run中最先执行,cleanup在run中最后执行,run方法中会循环执行map方法,map方法是我们需要在现在这个类中重写的,这个方法中主要执行业务相关的内容,当map不符合应用要求时,可以试着通过增加setup和cleanup的内容来满足应用的需求
// Mapper类中默认的run函数
public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKeyValue()) {
this.map(context.getCurrentKey(), context.getCurrentValue(), context);
}
} finally {
this.cleanup(context);
}
}Reducer大概情况也与Mapper相似
// Reducer类中默认的run函数
public void run(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException {
this.setup(context);
try {
while(context.nextKey()) {
this.reduce(context.getCurrentKey(), context.getValues(), context);
Iterator<VALUEIN> iter = context.getValues().iterator();
if (iter instanceof ValueIterator) {
((ValueIterator)iter).resetBackupStore();
}
}
} finally {
this.cleanup(context);
}
}Hadoop数据类型
Hadoop有自己的数据类型,这是因为MapReduce是基于磁盘的计算框架,会产生大量的磁盘IO,从而产生大量的序列化/反序列化操作,而Java自带的Serializable是一个繁杂的完整框架,直接使用它对本就耗费资源的MR来说无疑是雪上加霜,因此Hadoop有着自己的数据类型,分为内建类型和用户自定义类型
内建类型
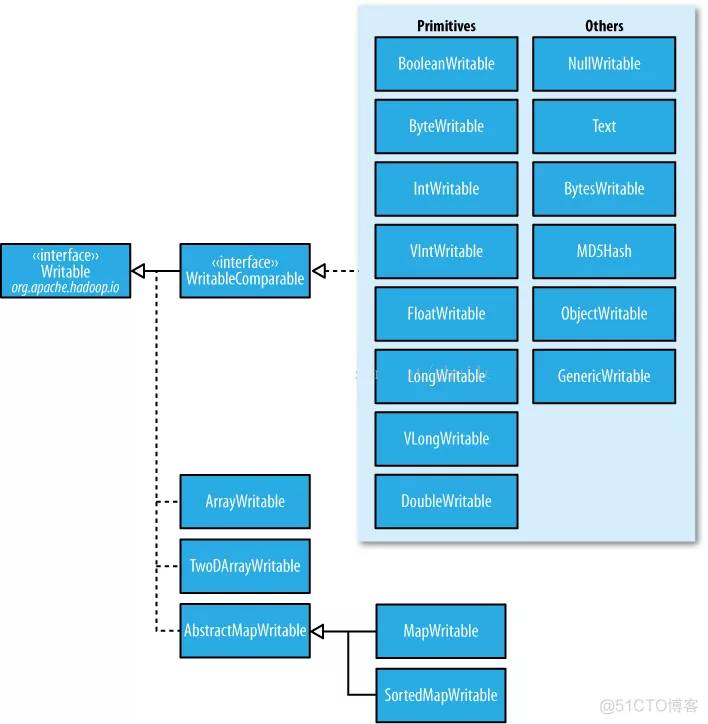
hadoop包装了java的基本数据类型使他们实现以上的接口而且给予实现细节,这些类都实现了WritableComparable接口,能够在不同的hadoop节点之间毫无障碍的传输了
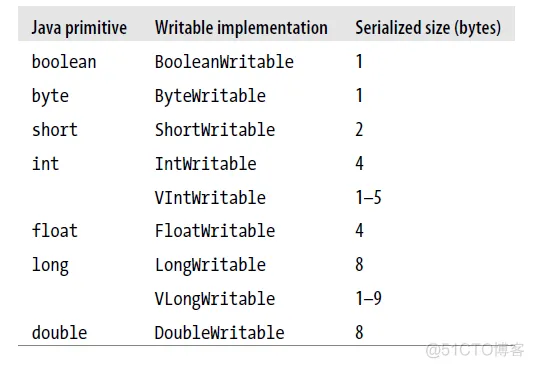
BooleanWritable : 标准布尔型数值
ByteWritable : 单字节数值
DoubleWritable : 双字节数值
FloatWritable : 浮点数
IntWritable : 整型数
LongWritable : 长整型数
Text : 使用UTF8格式存储的文本
NullWritable : 当<key, value>中的key或value为空时使用
用户自定义
实现WritableComparable或Writable接口即可
但是注意,如果你的自定义类型是要放在value上那么两个接口实现那个都行,但是如果你要放在key上那么必须实现WritableComparable,不然MR分组排序会因为没有比较方法而报错,同时这也是多级排序的实现方法
正式实验
数据抽样
1. 本次实验采取分层抽样的方式,选取D中的某一属性A,按A进行分层抽样,将抽样结果保存至HDFS中命名为D_Sample;
2. Tips:在Map阶段以属性A作为Key,然后在Reduce阶段进行抽样,如果属性是连续属性,可以考虑进行离散化;
【 3.1节中的分层抽样所使用的属性A为user_career属性 】
大致思路是在 Mapper:标出当前行对应的career,输出形式为 (career字段值,本行内容),然后在Reducer:根据不同的career自动分组,每一组按照固定的比例(概率)进行抽样【这部分代码我是照着火炬写的】在编写过程中发现了导包的重要性
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class Sample {
// 本类用于实现分层抽样,使用的属性是user_career(12个属性中的第11个)
// Mapper:标出当前行对应的career
public static final class SampleMapper extends Mapper<LongWritable,Text, Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// 切割出一个个单词
// 注意|前要加转义字符
String[] list = line.split("\\|");
// career赋值成对应的值
Text career = new Text();
career.set(list[10]);
// 相当于只是在每一行前边加了一个head:career
context.write(career,value);
}
}
// Reduce:根据不同的career自动分组,每一组按照固定的比例(概率)进行抽样
public static final class SampleReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for(Text item:values){
// 产生1-100的随机数
int num = (int)(Math.random()*100);
// 抽样比例为1/5
if(num<20){
context.write(item,new Text(""));
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 定义文件输入输出路径
String input = "hdfs://localhost:9000/dataPreprocess/data.txt";
String out = "hdfs://localhost:9000/D_Sample";
// 创建conf和job
Configuration conf=new Configuration();
Job job = Job.getInstance(conf,"Sample");
// 设置jar包所在路径
job.setJarByClass(Sample.class);
// 指定Mapper类和Reducer类
job.setMapperClass(SampleMapper.class);
job.setReducerClass(SampleReducer.class);
// 指定maptask输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 制定reducetask输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定mapreducer程序数据的输入输出路径
Path inputPath = new Path(input);
Path outputPath = new Path(out);
FileInputFormat.setInputPaths(job,inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion?0:1);
}
}
期间报了好几个错误,在这里大致记录一下【也许有些包不是一定要导入的,大家可以自己判断】:
Exception in thread "main" java.lang.NoClassDefFoundError: org/slf4j/LoggerFactory
at org.apache.hadoop.conf.Configuration.<clinit>(Configuration.java:229)
at Sample.main(Sample.java:57)
Caused by: java.lang.ClassNotFoundException: org.slf4j.LoggerFactory
at java.net .URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 2 more
解决方法:导入commons-logging.jar包,下载网址如下 https://commons.apache.org/proper/commons-logging/download_logging.cgi ,选择bin.tar.gz
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/htrace/core/Tracer$Builder
at org.apache.hadoop.fs.FsTracer.get(FsTracer.java:42)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:3460)
at org.apache.hadoop.fs.FileSystem.access$300(FileSystem.java:174)
at org.apache.hadoop.fs.FileSystem$Cache.getInternal(FileSystem.java:3574)
at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:3521)
at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:540)
at org.apache.hadoop.fs.Path.getFileSystem(Path.java:365)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.setInputPaths(FileInputFormat.java:530)
at Sample.main(Sample.java:73)
Caused by: java.lang.ClassNotFoundException: org.apache.htrace.core.Tracer$Builder
at java.net .URLClassLoader.findClass(URLClassLoader.java:387)
at java.lang.ClassLoader.loadClass(ClassLoader.java:418)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:352)
at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
... 9 more
解决方法:加入$HADOOP_HOME/share/hadoop/common/lib下的jar包,可以直接添加这个文件作为依赖
最后整个项目的依赖如图:
点击运行就夸夸一顿跑,控制台输出一堆消息,结束后到localhost:9870里查找,可以发现文件成功输出
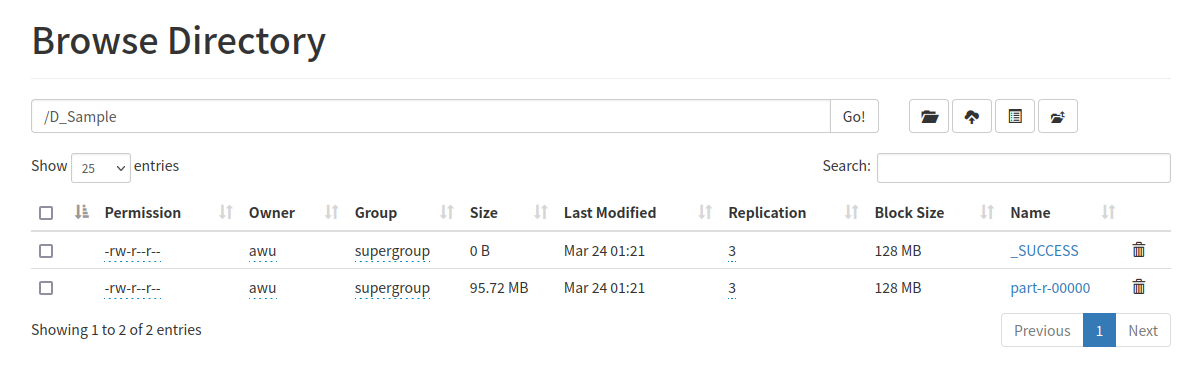
查找资料后可知,reduce最后输出结果保存在part-r-00000中,后续如果需要利用这一步的结果,就需要用其作为输入文件
MapReduce输出格式:
默认情况下只有一个 Reduce,输出只有一个文件,默认文件名为 part-r-00000,输出文件的个数与 Reduce 的个数一致。 如果有两个Reduce,输出结果就有两个文件,第一个为part-r-00000,第二个为part-r-00001,依次类推
数据过滤
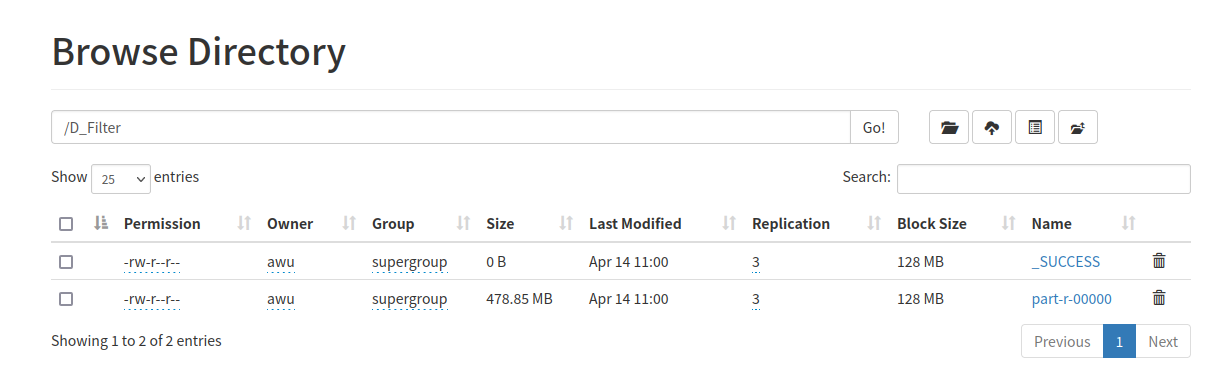
1. 选取D_Sample中的某一连续属性B进行排序,我们认为取值排名在1%~99%之间的值为正常值,
即其它值为奇异值,我们需要过滤掉原始数据集合D中属性B取值为奇异值的数据;
2. 过滤后的数据保存在HDFS中,命名为D_Filter;
【 3.2节中的奇异值过滤所使用的属性B为两个属性,分别是longitude和latitude。为了避免同学们使用额外的流程计算奇异值边界,给定longitude的有效范围为[8.1461259, 11.1993265],latitude的有效范围为[56.5824856, 57.750511],可以在代码中直接使用; 】
做这一步的时候我还以为要调用到排序函数,但是后来发现似乎直接提取有效范围内的数据就可以了(比第一个任务更简单)。因此只需要重写Mapper里的map方法,只有当longitude和latitude取值都落在有效范围内,才保留该条数据(输出给Reducer);对应的main函数只需要在Sample的main函数基础上,改掉一些参数设置就够了
注意,经过我的确认,实验数据是有重复的(我估计可能是同一份数据复制了11份),所以如果重写Reducer没有设置迭代器,而是直接输出(key:""),那么就会达到去重的效果(最终结果只有44.45MB)。如果重写Reducer不希望达到去重效果,那么就得在迭代器里输出,而这种写法就是默认Reducer,所以可以直接不重写,在main中也可不设置 job.setReducerClass (缺省直接调用默认Reducer)
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Filter {
// 本类用于实现数据过滤,使用的属性是longitude和latitude(12个属性中的第2/3个)
// 指导书已经给出对应属性的有效范围:longitude的有效范围为[8.1461259, 11.1993265]
// latitude的有效范围为[56.5824856, 57.750511]
// 本类只需要重写Mapper,在Mapper中,只有取值在有效范围内的数据才会被保留
public static final class FilterMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 分割操作与在Sample相同
String line = value.toString();
// 切割出一个个单词
// 注意|前要加转义字符
String[] list = line.split("\\|");
// 定义两个double变量存储longitude和latitude
double longitude = Double.parseDouble(list[1]);
double latitude = Double.parseDouble(list[2]);
// 只保留对应属性取值在有效范围内的数据
if (longitude >= 8.1461259 && longitude <= 11.1993265 && latitude >= 56.5824856 && latitude <= 57.750511) {
context.write(value, new Text(""));
}
}
}
// 如果像这样重写Reducer 【直接输出(key:"")】,那么就会达到去重的效果
// 如果希望不去重,那么应该在迭代器内输出(那么这和默认的Reduce也没区别)
public static final class FilterReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key,new Text(""));
}
}
// main函数几乎都相同
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 定义文件输入输出路径
String input = "hdfs://localhost:9000/dataPreprocess/data.txt";
String out = "hdfs://localhost:9000/D_Filter";
// 创建conf和job
Configuration conf=new Configuration();
Job job = Job.getInstance(conf,"Filter");
// 设置jar包所在路径
job.setJarByClass(Filter.class);
// 指定Mapper类和Reducer类
job.setMapperClass(FilterMapper.class);
//job.setReducerClass(FilterReducer.class);
// 指定maptask输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 制定reducetask输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定mapreducer程序数据的输入输出路径
Path inputPath = new Path(input);
Path outputPath = new Path(out);
FileInputFormat.setInputPaths(job,inputPath);
FileOutputFormat.setOutputPath(job,outputPath);
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion?0:1);
}
}
数据格式转换与归一化
1. 一些数据属性可能存在不同的格式,如日期、温度,我们需要转化为统一的格式;另一些属性则往
往需要归一化;
2. 对D_Filter中的数据进行格式转换与归一化,结果保存在HDFS中,仍然命名为D_Filter;
3. 本实验中建议使用的归一化方式为Min-Max归一化
【 3.3中,数据格式属性涉及到属性user_birthday和review_date,这些日期字段可能使用2018-03-21、2018/03/21、March 21, 2019这些格式,转换为哪种格式取决于同学们自己;temperature有华氏与摄氏两种,同样的,目标格式取决于同学们;需要归一化的属性则是rating 】
这一部分其实统共有三个小任务:日期格式统一(可以通过SimpleDateFormat辅助转换),温度格式统一以及rating归一化,其中rating的归一化需要先统计有效rating值的max和min(注意,rating的缺失值为"?"),我一开始觉得这部分至少需要两轮MR来完成,一轮统计rating的max和min,另一轮转化各个属性值。后来发现只要引入public static的全局变量,就可以在一轮之内完成所有任务:即在mapper中第一遍扫描全部数据,统计出rating的max和min,同时完成格式转化;reducer中进行rating的归一化(利用全局max和min)
static:静态修饰符,被static修饰的变量和方法类似于全局变量和全局方法,可以在不创建对象时调用,当然也可以在创建对象之后调用
这一部分我用到了之前不知道的SimpleDateFormat(其实也是从火炬中学习到了,学长都好牛),在这里贴一个博客链接。其实只需要掌握“利用parse提取对应日期信息”以及“利用format转化成相应的日期格式”就够了。当然理论上直接用正则表达式匹配也能完成相应任务,但是显然SimpleDateFormat更省心一些
Java中SimpleDateFormat的用法介绍(代码示例)
官方文档:Class SimpleDateFormat
使用SimpleDateFormat还需注意符号的意义以及不同个数符号对于表义的影响,比如:
y,表示年份,例如yyyy表示4位数字年份,yy表示2位数字年份
M,表示月份,例如MM表示2位数字月份,MMM表示月份的英文缩写,MMMM表示月份的完整英文名称
d,表示月中的日期,例如dd表示2位数字日期
E,表示星期几,例如EEE表示星期的英文缩写,EEEE表示星期的完整英文名称
H,表示小时(24小时制),例如HH表示2位数字小时数,H表示一位或两位数字小时数
h,表示小时(12小时制),例如hh表示2位数字小时数,h表示一位或两位数字小时数
m,表示分钟,例如mm表示2位数字分钟数
s,表示秒钟,例如ss表示2位数字秒数
S,表示毫秒数,例如SSS表示3位数字毫秒数完整代码如下:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class FormatNormalize {
// 本类用于进行格式转换以及归一化处理
// review_date:12个属性中的第5个
// temperature:12个属性中的第6个
// rating:12个属性中的第7个
// user_birthday:12个属性中的第9个
// 初始化max和min(全局变量)
public static double max = Double.NEGATIVE_INFINITY;
public static double min = Double.POSITIVE_INFINITY;
public static String DateFormatConversion(String s) throws ParseException {
// 匹配 "March 10,1979"
SimpleDateFormat format1 = new SimpleDateFormat("MMMM d,yyyy", Locale.ENGLISH);
// 匹配 ”1975-09-21“
SimpleDateFormat format2 = new SimpleDateFormat("yyyy-MM-dd");
// 匹配 “1997/12/01”
SimpleDateFormat format3 = new SimpleDateFormat("yyyy/MM/dd");
// 第1种格式:转化成第3种格式
if(s.contains(",")){
Date date = format1.parse(s);
return format3.format(date);
}
// 第2种格式:转化成第3种格式
else if(s.contains("-")){
Date date = format2.parse(s);
return format3.format(date);
}
// 第3种格式:直接输出
else{
return s;
}
}
public static final class FormatNormalizeMapper extends Mapper<LongWritable, Text, Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// 切割出一个个单词
// 注意|前要加转义字符
String[] list = line.split("\\|");
// 1. 更新rating的最大最小值
// 如果此时的rating不缺失
if(!list[6].equals("?")){
double rating = Double.parseDouble(list[6]);
if(rating>max){
max = rating;
}
if(rating<min){
min = rating;
}
}
// 2. 统一摄氏度和华氏度
if(list[5].contains("℉")){
float temperature = Float.parseFloat(list[5].substring(0,list[5].length()-1));
temperature = (temperature-32)/1.8f;
String t = String.format("%.1f",temperature)+"℃";
line = line.replace(list[5],t);
}
// 3. 统一日期信息
try {
String review_date = DateFormatConversion(list[4]);
String user_birthday = DateFormatConversion(list[8]);
line = line.replace(list[4],review_date);
line = line.replace(list[8],user_birthday);
} catch (ParseException e) {
e.printStackTrace();
}
// 4. 对应字段输出到reduce进行进一步处理
context.write(new Text(line),new Text(""));
}
}
public static final class FormatNormalizeReducer extends Reducer<Text,Text,Text,Text>{
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// System.out.println("max:"+max+" & min:"+min+"\n\n\n\n");
// 一些重复操作
String line = key.toString();
// 切割出一个个单词
// 注意|前要加转义字符
String[] list = line.split("\\|");
// rating不缺失
if(!list[6].equals("?")){
double rating = Double.parseDouble(list[6]);
// Min-Max归一化
rating = (rating-min)/(max-min);
line = line.replace(list[6],String.valueOf(rating));
}
// 如果不在迭代器中输出,那么就会造成去重的效果
// 题目没有要求去重,所以还是写了迭代器
for(Text value:values){
context.write(new Text(line),new Text(""));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 定义文件输入输出路径
String input = "hdfs://localhost:9000/D_Filter/part-r-00000";
String out = "hdfs://localhost:9000/D_FormatNormalize";
// 创建conf和job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "FormatNormalize");
// 设置jar包所在路径
job.setJarByClass(FormatNormalize.class);
// 指定Mapper类和Reducer类
job.setMapperClass(FormatNormalizeMapper.class);
job.setReducerClass(FormatNormalizeReducer.class);
// 指定maptask输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 制定reducetask输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定mapreducer程序数据的输入输出路径
Path inputPath = new Path(input);
Path outputPath = new Path(out);
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
}
}
指导书要求最终把结果也输出到D_Filter,但是实际上这样写代码会报错(似乎不允许输出输出同一个文件夹),所以我把结果输出到另一个新建文件夹下了
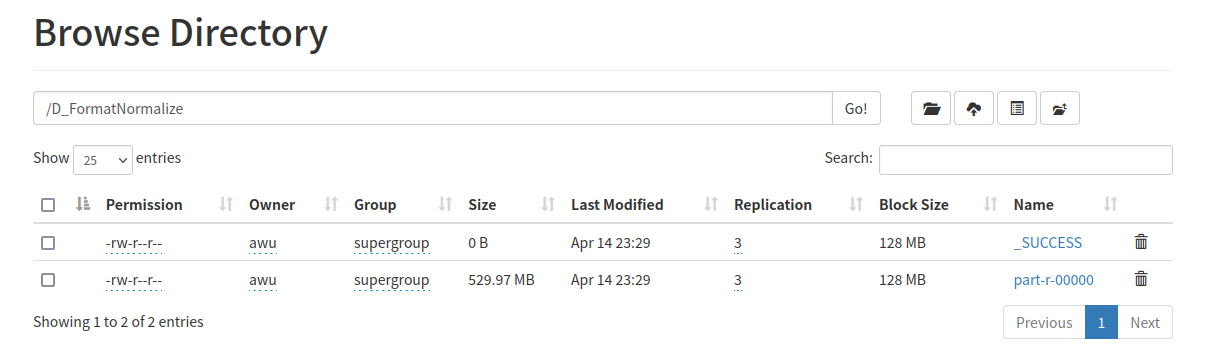
数据清洗(缺失值填充)
1. D_Filter中某些数据在属性E上可能存在缺失,我们需要使用某种方法对E进行填充,然后将数据保
存在HDFS中,命名为D_Done;
2. 填充策略可以考虑使用默认值,也可以使用平均值、中位数,还可以利用相似度寻找与缺失数据相
似的其他数据,然后借此对缺失的数据进行填充;
【3.4中存在缺失值的属性为rating和user_income,根据先验知识,rating近似依赖于user_income、longitude、latitude和altitude,user_income近似依赖于user_nationality和user_career。对rating和user_income的填充可以利用这些依赖关系;】
这一部分任务我选择使用平均值来填充。待填充属性值包括rating和user_income,但由于rating依赖于user_income,所以我决定分两轮MR完成(当然直接一轮填充,只统计当前的有效数据也说的过去)。第一轮填充user_income,第二轮填充rating
首先我创建了一个数据结构Record,包含两个成员变量sum和num,统计属性值的总和以及个数,方便后期计算出对应的平均值
public class Record {
// 本类用于统计当前属性的和以及个数,方便最终求取平均值
private double sum;
private int num;
public Record() {
this.sum = 0;
this.num = 0;
}
public double getSum() {
return sum;
}
public void setSum(double sum) {
this.sum = sum;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
填充思路很简单,还是用上了全局变量的办法,全局设置总体统计量xxRecord(只要待填充属性值不缺失就纳入统计)以及分类统计量xxCount(利用HashMap,统计相同依赖值下的sum和num)。在mapper中计算统计量,在reducer中提取出依赖属性的值,与分类统计量对比,如果有相同依赖值的记录,取对应的sum和num计算出平均值填充进去;否则拿总体统计量的平均值填充
【当然听我朋友说可以调一个工具包直接进行多元线性回归,我猜也许是OLSMultipleLinearRegression,大家可以去试一试】
两个属性值填充的思路以及代码高度相似,所以在这里我就贴其中一个代码就好了
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.HashMap;
public class IncomeFill {
// 本类用于填充具有缺失值的属性user_income
// 其中user_income近似依赖于user_nationality和user_career
// user_income:12个属性中的第12个
// user_nationality:12个属性中的第10个
// user_career:12个属性中的第11个
// 初始化全局变量
// 总体统计
public static Record incomeRecord = new Record();
// 分类统计
public static HashMap<String,Record> incomeCount = new HashMap<>();
// Mapper:对相关属性值进行统计
public static final class IncomeFillMapper extends Mapper<LongWritable, Text, Text,Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 老规矩,先切分出各个属性
String line = value.toString();
// 切割出一个个单词
// 注意|前要加转义字符
String[] list = line.split("\\|");
// 如果此时的income不缺失
if(!list[11].contains("?")){
// 提取相关属性值
String nationality_career = list[10]+list[11];
double income = Double.parseDouble(list[11]);
// 总体记录先往上添加一个
incomeRecord.setNum(incomeRecord.getNum()+1);
incomeRecord.setSum(incomeRecord.getSum()+income);
// 补充分类记录
// 如果之前没有相同nationality_career的记录,则需创建记录
if(!incomeCount.containsKey(nationality_career)){
Record record = new Record();
record.setSum(income);
record.setNum(1);
incomeCount.put(nationality_career,record);
}
// 否则只需更新
else{
Record record = incomeCount.get(nationality_career);
record.setSum(record.getSum()+income);
record.setNum(record.getNum()+1);
}
}
// 无论如何都无脑输出,不对原数据进行修改
context.write(value,new Text(""));
}
}
// Reducer:根据统计信息,填充缺失值
public static final class IncomeFillReducer extends Reducer<Text, Text, Text,Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 还是分割字符串的操作
String line = key.toString();
// 切割出一个个单词
// 注意|前要加转义字符
String[] list = line.split("\\|");
// 只需要对缺失值进行填充修改
if(list[11].contains("?")){
// 提取相关属性值
String nationality_career = list[10]+list[11];
// 有相同类的统计数据存在
if(incomeCount.containsKey(nationality_career)){
// 获取该类的统计平均值
Record record = incomeCount.get(nationality_career);
double income = record.getSum()/record.getNum();
line = line.replace(list[11],String.valueOf(income));
}
// 否则用全体统计平均值填充
else{
double income = incomeRecord.getSum()/incomeRecord.getNum();
line = line.replace(list[11],String.valueOf(income));
}
// 修改待输出的key
key = new Text(line);
}
for(Text value:values){
context.write(key,new Text(""));
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 定义文件输入输出路径
String input = "hdfs://localhost:9000/D_Filter/part-r-00000";
String out = "hdfs://localhost:9000/D_IncomeFill";
// 创建conf和job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "IncomeFill");
// 设置jar包所在路径
job.setJarByClass(IncomeFill.class);
// 指定Mapper类和Reducer类
job.setMapperClass(IncomeFillMapper.class);
job.setReducerClass(IncomeFillReducer.class);
// 指定maptask输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
// 制定reducetask输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 指定mapreducer程序数据的输入输出路径
Path inputPath = new Path(input);
Path outputPath = new Path(out);
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 提交任务
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
/*
// test
Record record = new Record();
record.setSum(88);
record.setNum(5);
incomeCount.put("trytry",record);
Record record1 = incomeCount.get("trytry");
System.out.println(record1.getSum()+" "+record1.getNum());
record1.setSum(100);
record1.setNum(8);
System.out.println(incomeCount.get("trytry").getSum()+" "+incomeCount.get("trytry").getNum());
*/
}
}
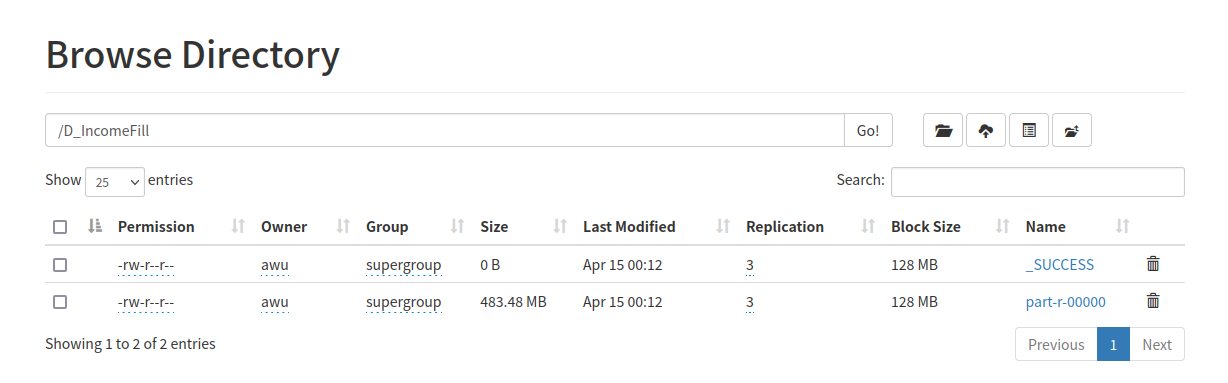
总结
实验到这就结束了,总体来说并不复杂,四个部分的代码都是按要求重写mapper和reducer就够了。整个实验捋下来,反而是配环境最让我痛苦,憨憨配了两回才配成功。
最后得感谢一下学长火炬!!!!!给学长磕磕!如果没有火炬参考,自己从零摸索简直太痛苦了。虽然最后来看几乎就是再复现一遍火炬,但还算是有所收获,也希望大家能自己动手过一遍实验,至少可以稍微学一波知识
学长火炬:哈工大2021年春大数据分析实验整理
最后的最后吐槽一波:CSDN的markdown编辑器也太太太难用了!!!!!!!!生气[○・`Д´・ ○],我调的格式到发布的时候全都没有掉了......

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)