快速搭建BI商业报表平台
这里写目录标题一、MySQL基础知识1.delete和truncate的区别:2.SQL查询基本语法3.数据准备4.简单查询5.条件查询where6.聚合查询7.分组查询:gourp by8.排序查询:order by9.分页查询:limit10.多表查询11.子查询二、可视化ETL平台——Kettle1.ETL功能2.Kettle使用3.快速入门实战1. 将txt文件中的数据写入Excel表格中
一、MySQL基础知识
1.delete和truncate的区别:
- delete:DML命令,一条一条删除
- truncate:DDL命令,类似于将整张表删除,然后重新创建一张一样的空表
2.SQL查询基本语法
select 1 from 2 where 3 group by 4 having 5 order by 6 limit 7;
-
1:用于决定查询的结果中有哪些列,给定哪些列,结果就会显示这些列
- 写列的名字,多列用逗号隔开
- *号代表所有的列
-
2:用于表示查询哪张表,给定表的名字
-
3:条件查询,只有满足条件的数据才会被返回
- 不满足条件的数据会被过滤掉,不会在结果中显示
- 符合where条件的行才会在结果中显示
-
4:用于实现分组的,将多条数据按照某一列或者多列进行分组,划分到同一组中
- 用于实现统计分析
- 语法:group by col
-
5:用于实现分组后的条件过滤
- 功能类似于where
- 满足having后的条件就会出现在结果中
- 不满足条件就会被过滤掉
- 与where的区别
- where:分组之前过滤
- having:分组之后过滤
-
6:用于实现将查询的结果按照某一列或者多列进行排序
- order by col [ asc | desc]
- asc:升序排序
- desc:降序排序
- 如果不指定,默认是升序排序
-
7:用于实现分页输出
3.数据准备
#创建商品表:
create table product(
pid int,
pname varchar(20),
price double,
category_id varchar(32)
);
INSERT INTO product(pid,pname,price,category_id) VALUES(1,'联想',5000,'c001');
INSERT INTO product(pid,pname,price,category_id) VALUES(2,'海尔',3000,'c001');
INSERT INTO product(pid,pname,price,category_id) VALUES(3,'雷神',5000,'c001');
INSERT INTO product(pid,pname,price,category_id) VALUES(4,'杰克琼斯',800,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(5,'真维斯',200,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(6,'花花公子',440,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(7,'劲霸',2000,'c002');
INSERT INTO product(pid,pname,price,category_id) VALUES(8,'香奈儿',800,'c003');
INSERT INTO product(pid,pname,price,category_id) VALUES(9,'相宜本草',200,'c003');
INSERT INTO product(pid,pname,price,category_id) VALUES(10,'面霸',5,'c003');
INSERT INTO product(pid,pname,price,category_id) VALUES(11,'好想你枣',56,'c004');
INSERT INTO product(pid,pname,price,category_id) VALUES(12,'香飘飘奶茶',1,'c005');
INSERT INTO product(pid,pname,price,category_id) VALUES(13,'海澜之家',1,'c002');
4.简单查询
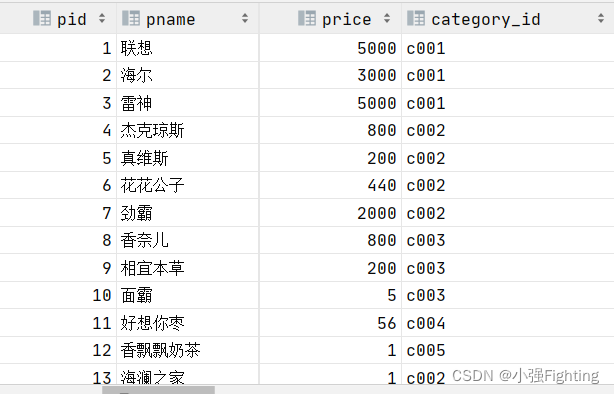
1.查询所有的商品信息
select * from product;
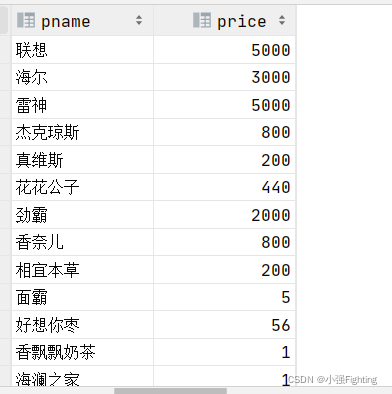
2.查询所有的商品名称和价格
select pname,price from product;
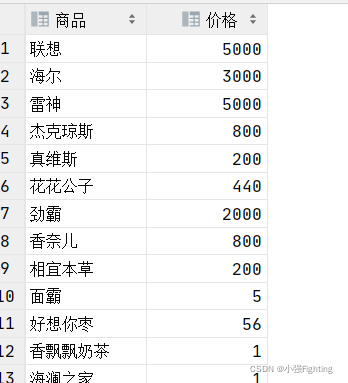
3.查询所有的商品名称和价格,结果的列名称分别为商品和价格
select pname '商品',price '价格' from product;
4.查询所有的商品价格,并去掉重复价格
select distinct price from product;
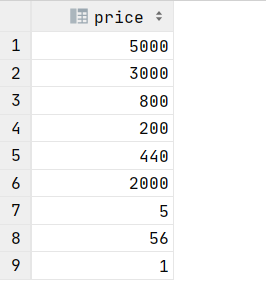
distinct:用于对列值进行去重
5.将所有商品价格+10元显示
select price as '价格',price+10 as '修改后'from product;
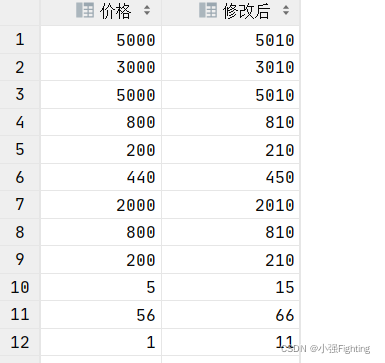
as:用于给列或者表取别名
直接对数值类型的列进行运算
- 加:+
- 减:-
- 乘:*
- 除:/
5.条件查询where
1.查询商品名称为“花花公子”的商品所有信息
select * from product where pname='花花公子';

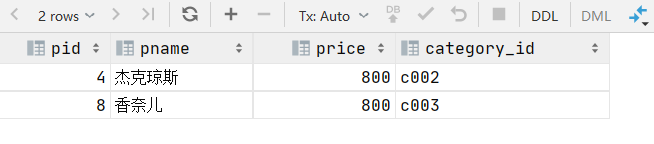
2.查询价格为800商品
select * from product where price='800';
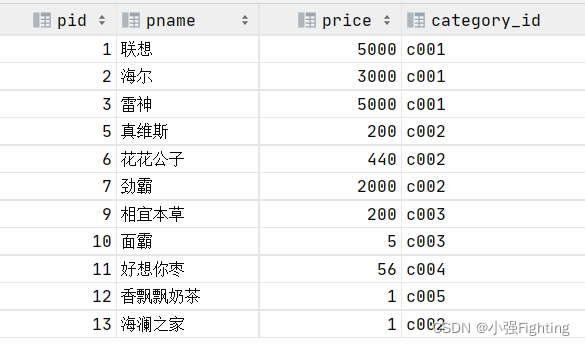
3.查询价格不是800的所有商品
select * from product where price!=800;
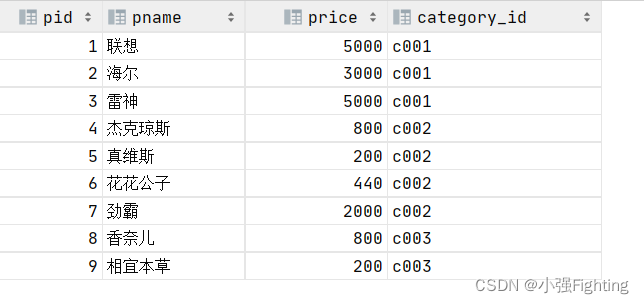
4.查询商品价格大于60元的所有商品信息
select * from product where price>60;
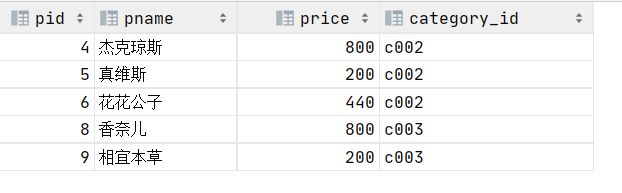
5.查询商品价格在200到1000之间所有商品
select * from product where price between 200 and 1000;
-
等于:=
-
不等于:!=
-
小于:<
-
大于:>
-
小于等于:<=
-
大于等于:>=
6.查询商品价格是200或800的所有商品
select * from product where price=200 or price=800;
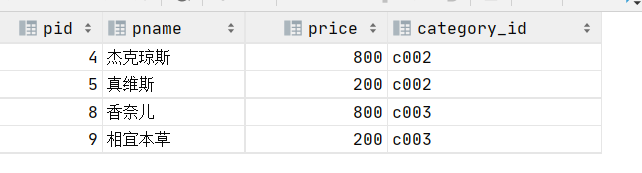
or:或者关系,两个条件满足其中一个即可
7.查询含有’霸’字的所有商品
select * from product where pname like '%霸%';

select * from product where pname like '香%';
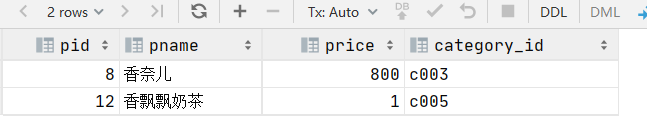
8.查询第二个字为’想’的所有商品
select * from product where pname like '_想%';

%:任意多个字符
_:表示一个字符
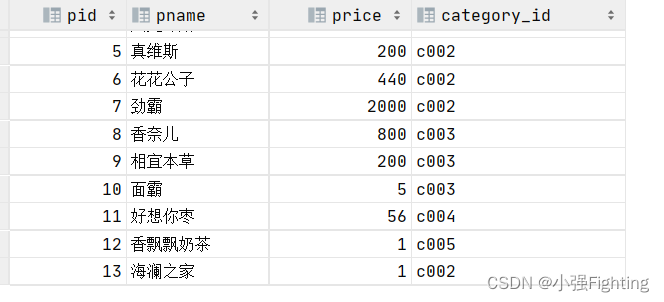
9.查询没有分类的商品
insert into product values(14,'weiC 100',9.9,null);
select * from product where category_id is null;

10.查询有分类的商品
select * from product where category_id is not null;
6.聚合查询
MYSQL默认为我们提供的常见的聚合函数
- count(colname):统计某一列的行数,统计个数,null不参与统计
- sum(colname):计算某一列的所有值的和,只能对数值类型求和,如果不是数值,结果为0
- max(colname):计算某一列的所有值中的最大值
- min(colname):计算某一列的所有值中的最小值
- avg(colname):计算某一列的平均值
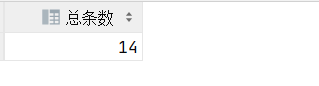
1.查询商品的总条数
select count(pid) as '总条数'from product;
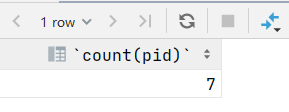
2.查询价格大于200商品的总条数
select count(pid) from product where price>200;
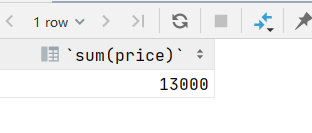
3.查询分类为’c001’的所有商品价格的总和
select sum(price) from product where category_id='c001';
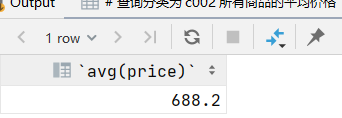
4.查询分类为’c002’所有商品的平均价格
select avg(price) from product where category_id='c002';
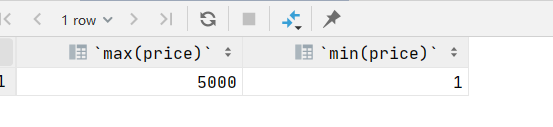
5.查询商品的最大价格和最小价格
select max(price),min(price) from product;
7.分组查询:gourp by
- 关键字:group by col …… having
- 功能:按照某些列进行分组,对分组后的数据进行处理,一般都会搭配聚合函数使用
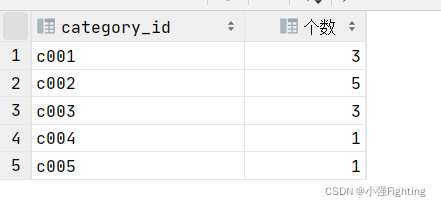
1.统计各个分类商品的个数
select category_id, count(pid) as '个数' from product group by category_id;
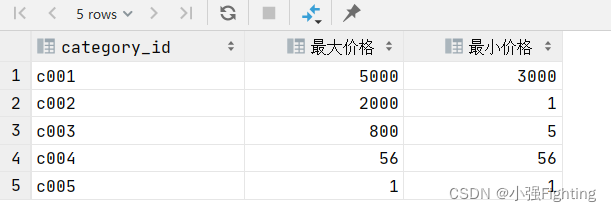
2.统计查询每种分类中的商品的最大价格和最小价格
select category_id,max(price) as '最大价格',min(price) as '最小价格'from product group by category_id;
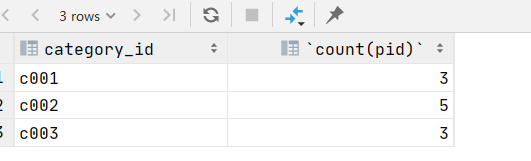
3.统计各个分类商品的个数,且只显示个数大于1的数据
select category_id,count(pid) from product group by category_id having count(pid)>1;
- 需要对分组后的结果再进行行的过滤
- where:实现对数据行的过滤,指定条件- 这个需求中不能使用where
- 因为where会在group by之前执行,而个数是在分组之后才产生的列
- having:实现对数据行的过滤,指定条件,写法与where一致
- 用于分组之后结果数据的过滤
- 对分组以后的 结果进行过滤
- 什么时候用where,什么时候用having
- 你要过滤的条件是分组之前就存在的,还是分组以后才产生的
8.排序查询:order by
- 关键字:order by col…… 【 asc | desc】
- 功能:将结果按照某些列进行升序或者 降序的排序来显示
- 默认是升序
- asc:升序
- desc:降序
1.查询所有商品的信息,并按照价格降序排序
select * from product order by price desc;
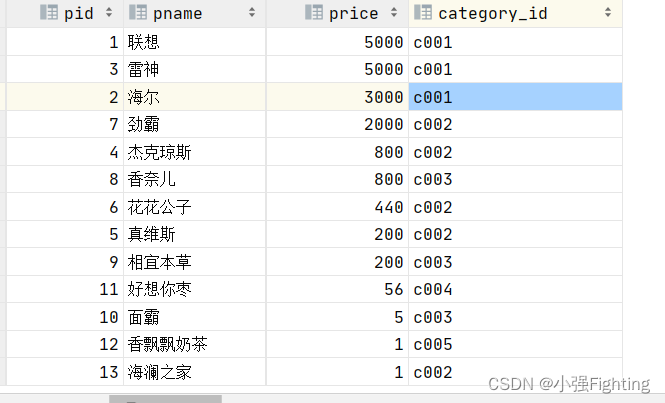
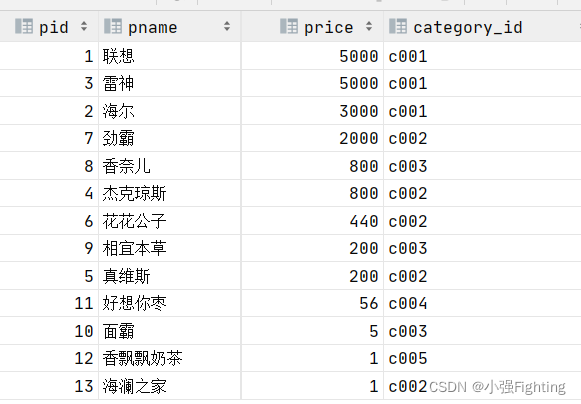
2.查询所有商品的信息,并按照价格排序(降序),如果价格相同,以分类排序(降序)
select * from product order by price desc,category_id desc;
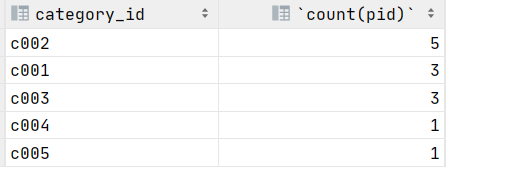
3.统计各个分类商品的个数 ,并按照个数降序排序
select category_id,count(pid) from product group by category_id order by count(pid) desc ;
9.分页查询:limit
- 关键字:limit
- 功能:限制输出的结果
- 语法:limit M,N
- M:你想从第M+1条开始显示
- N:显示N条
1.查询product表的前5条记录
select * from product limit 5;
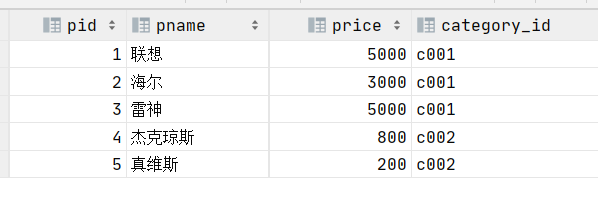
2.查询product表的第4条和第5条记录
select * from product limit 3,2;

3.查询商品个数最多的分类的前三名
select category_id,count(pid) from product group by category_id order by count(pid) desc limit 3;
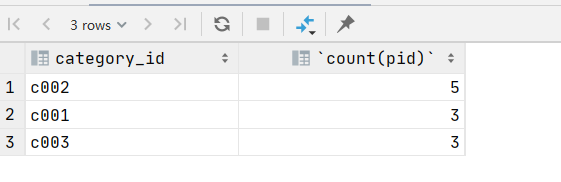
10.多表查询
数据准备
CREATE TABLE category (
cid VARCHAR(32) ,
cname VARCHAR(50)
);
#分类
INSERT INTO category(cid,cname) VALUES('c001','家电');
INSERT INTO category(cid,cname) VALUES('c002','服饰');
INSERT INTO category(cid,cname) VALUES('c003','化妆品');
INSERT INTO category(cid,cname) VALUES('c004','吃的');
INSERT INTO category(cid,cname) VALUES('c005','喝的');
1.查询每个商品的名称以及所属分类的名称
select pname,cname from product,category where product.category_id=category.cid;
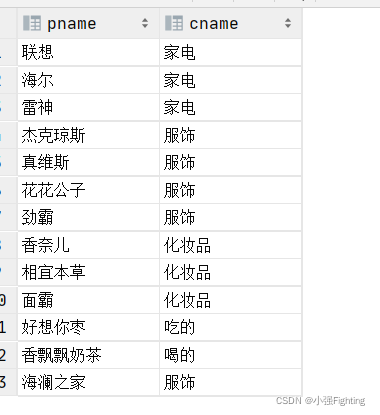
2.统计每个分类名称对应的商品个数
select c.cname,count(pid) as numb from product p join category c on p.category_id=c.cid
group by c.cname;
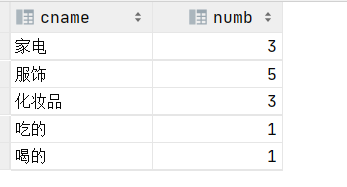
3.统计除了吃的分类以外的所有分类的商品个数,并显示个数最多的前三个分类
select cname,count(cname) from product p join category c on p.category_id=c.cid
group by cname having cname!='吃的' order by count(cname) desc limit 3;
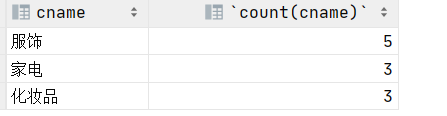
inner join:内连接,inner可以省略
- 关联条件中,两张表都有这个值,结果就有
- 类似于集合中两个集合的交集
left outer join:左外连接,outer可以省略
- 关联条件中,左表中有,结果就有
- 类似于集合中左表的全集
right outer join:右外连接,outer可以省略
- 关联条件中,右表中有,结果就有
- 类似于集合中右表的全集
full join:全连接
- 关联条件中,两张表任意一边有,结果就有
- 类似于集合中的两张表全集
11.子查询
在select语句中嵌套select语句
1.查询化妆品这个分类对应的所有商品信息
select * from product where product.category_id=(
select cid from category where cname='化妆品');
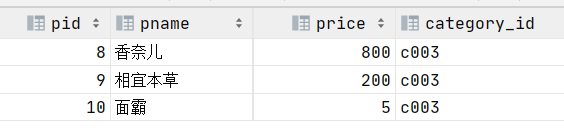
2.查询相宜本草对应的分类的名称
select * from category where cid=(
select category_id from product where pname='相宜本草');
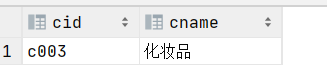
二、可视化ETL平台——Kettle
1.ETL功能
功能:实现数据的预处理,数据清洗过程,将原始数据经过ETL处理变成想要的数据,进行下一步的应用
- 实现
- 抽取:读取需要处理的原始数据
- 转换:将原始数据转换为目标数据
- 过滤:将不需要的数据过滤掉
- 原始数据中有100列
- 实际需要30列
- 过滤掉70列
- 补全:将需要用到的数据补全
- 每一个访问网站或者APP时,会有一个IP地址
- 后台通过IP能获取到我们当前所在的国家、省份、城市
- 转换:原始数据的格式不是我们想要的格式,转换为想要的格式
- 原始数据:22/Aug/2020:12:20:35
- |
- | 转换
- |
- 目标格式:2020-08-22 12:20:35
- 过滤:将不需要的数据过滤掉
- 加载:将处理好的目标数据放入数据仓库中
2.Kettle使用
1.转换
- 功能:实现数据的预处理,数据清洗过程,将原始数据经过ETL处理变成想要的数据,进行下一步的应用
- 实现
- 抽取:读取需要处理的原始数据
- 转换:将原始数据转换为目标数据
- 过滤:将不需要的数据过滤掉
- 原始数据中有100列
- 实际需要30列
- 过滤掉70列
- 补全:将需要用到的数据补全
- 每一个访问网站或者APP时,会有一个IP地址
- 后台通过IP能获取到我们当前所在的国家、省份、城市
- 转换:原始数据的格式不是我们想要的格式,转换为想要的格式
- 原始数据:22/Aug/2020:12:20:35
- |
- | 转换
- |
- 目标格式:2020-08-22 12:20:35
- 过滤:将不需要的数据过滤掉
- 加载:将处理好的目标数据放入数据仓库中
2.作业
-
功能:将多个转换根据需求构建任务流
- 任务流:很多个任务【每一个转换程序】根据自动运行的条件来运行就是任务流
- 实际工作中,一次要执行很多个转换任务,如何实现这些任务的自动化执行
- 自动运行
- 第一种:定时运行
- 每天的00:01分开始自动运行
- 第二种:依赖关系
- A先运行,A运行成功,B就自动运行
- 第一种:定时运行
-
举例
-
转换1:实现对数据的过滤
-
转换2:实现对数据的补全
-
转换3:实现对数据的转换
-
作业:一个任务流
- 转换1:每天00:10分自动运行
- 转换2:转换1运行成功,转换2就开始运行
- 转换3:转换2运行成功,转换3就开始运行
-
3.快速入门实战
1. 将txt文件中的数据写入Excel表格中
(1)关键转换流程图:
新建一个转换任务
将输入和输出拖入流程图的面板中
连线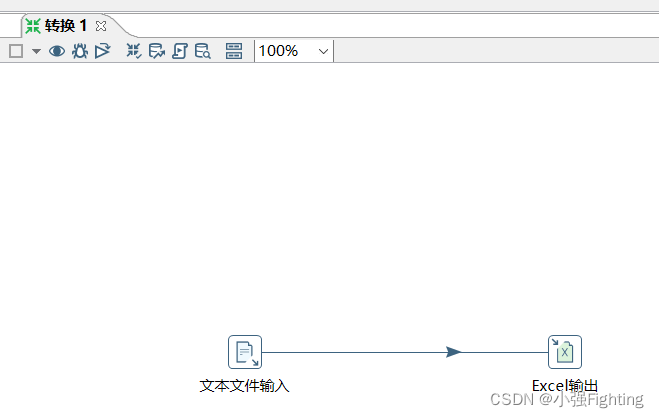
(2)配置输入
关联文件
配置文件的格式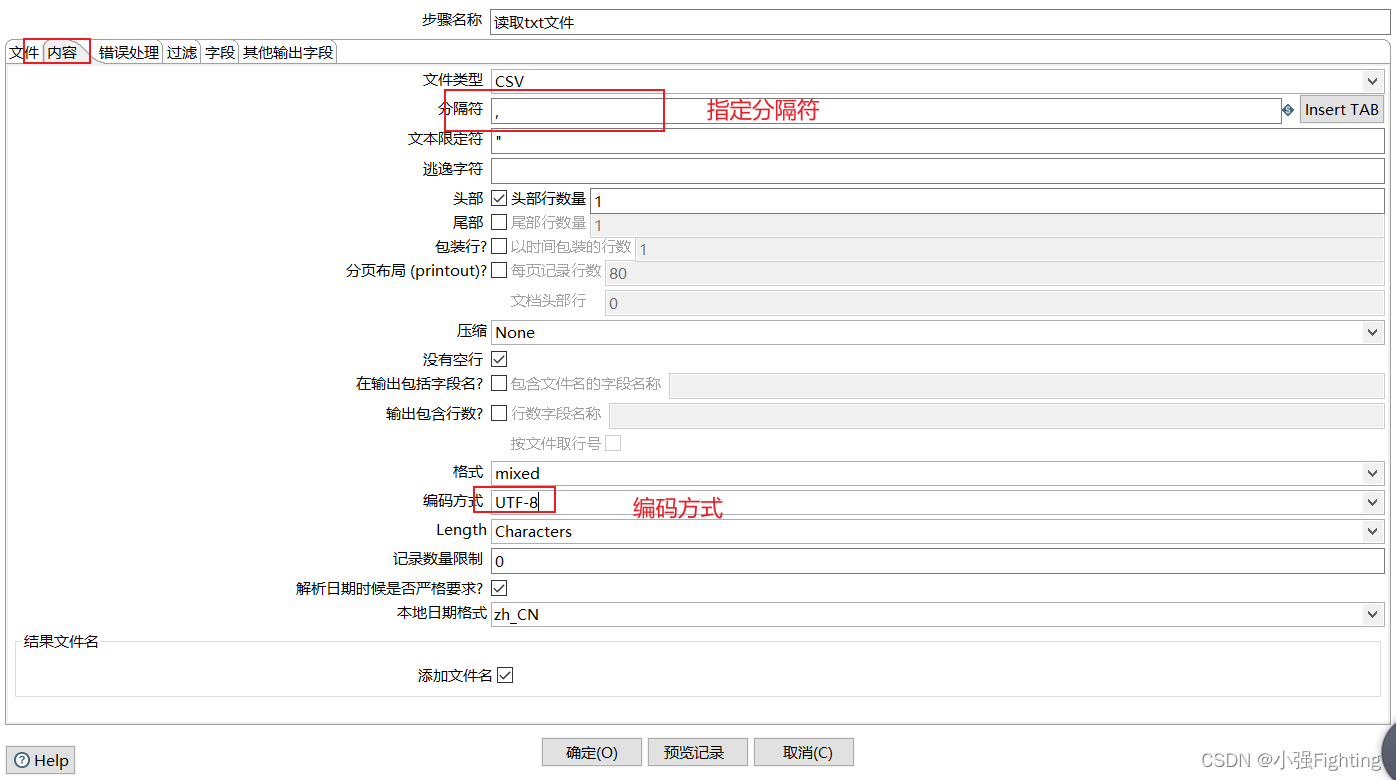
选择输出到下一步的数据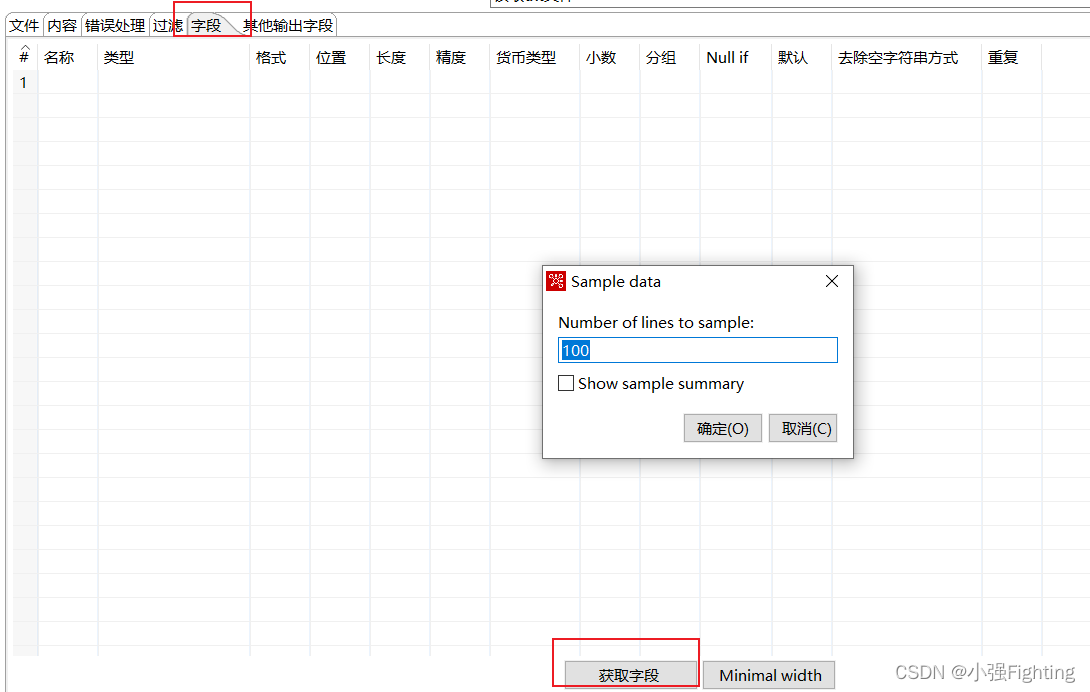
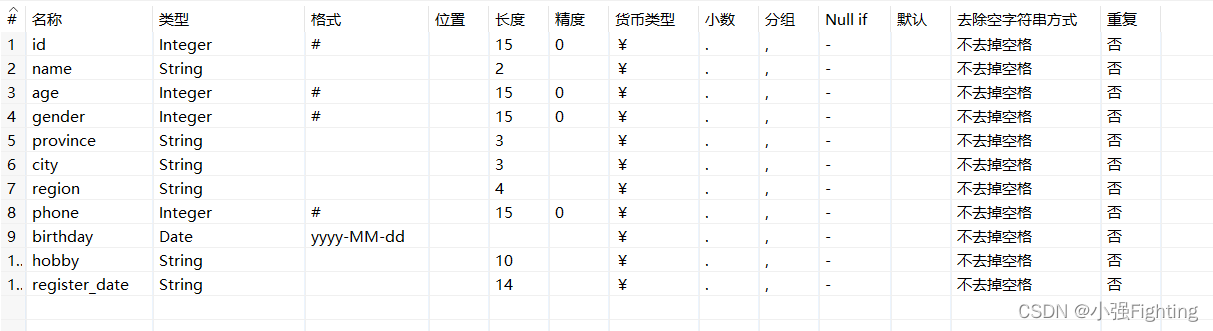
(3)配置输出
输出目标文件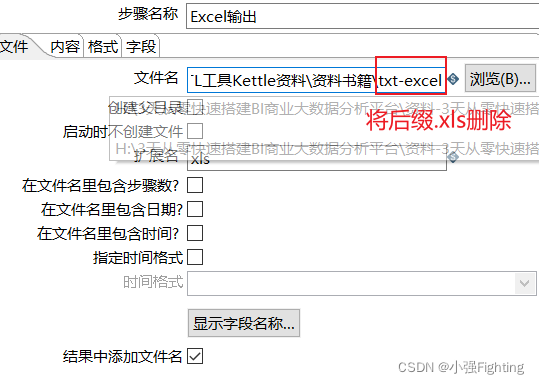
预览输出信息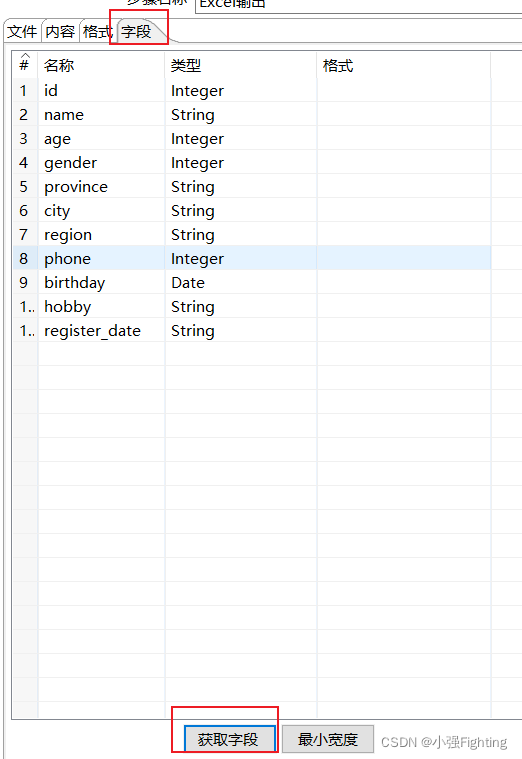
测试运行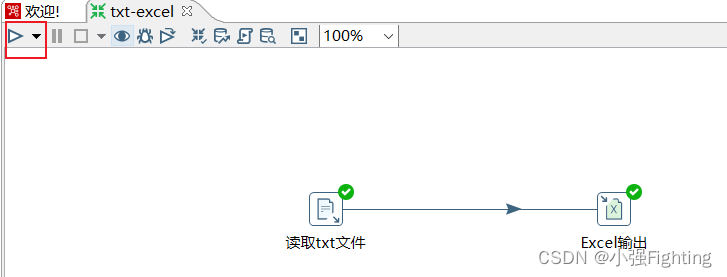
查看结果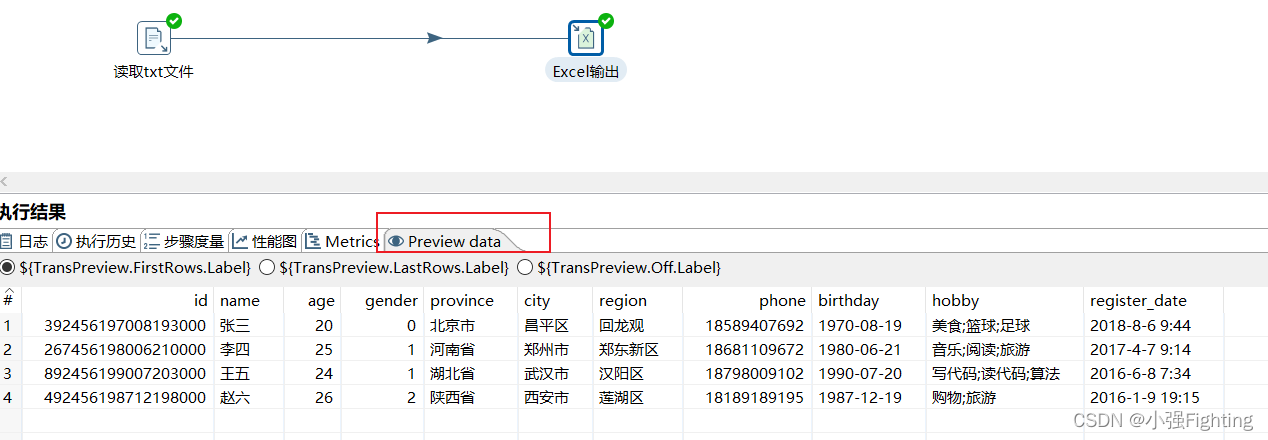
2. 读取Excel文件中的数据,存储MySQL中
(1)构建转换流程图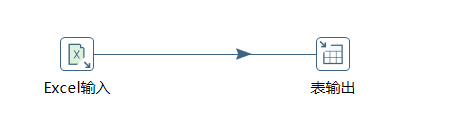
(2)配置输入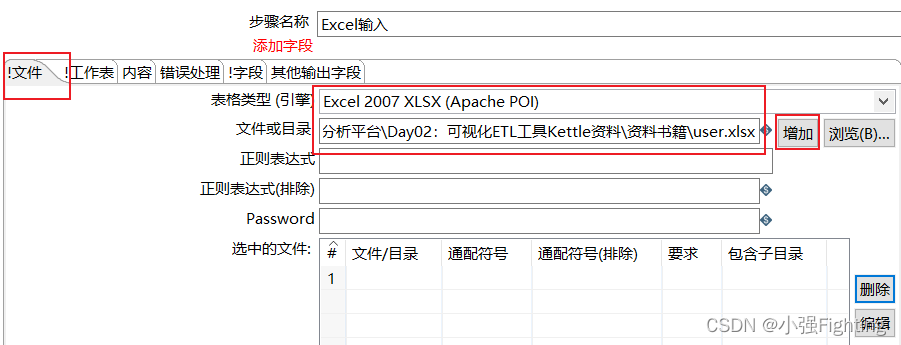
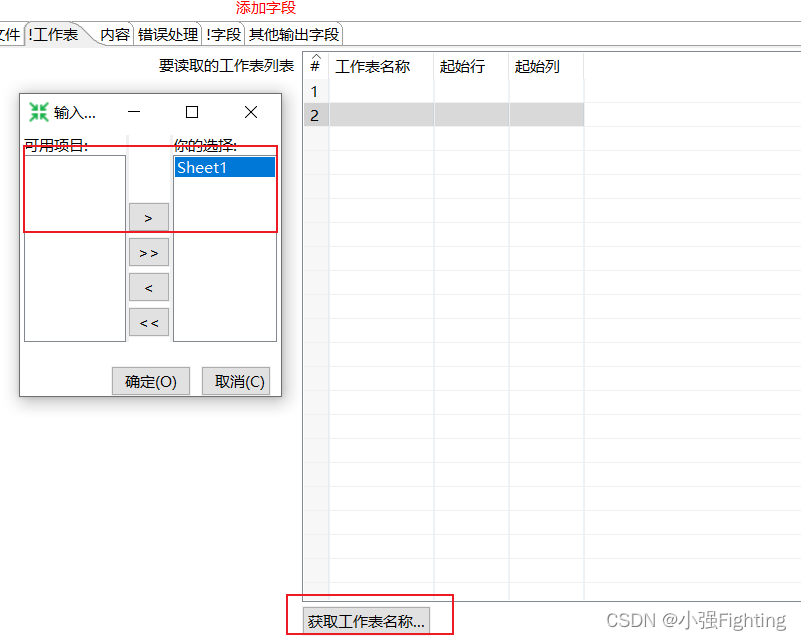
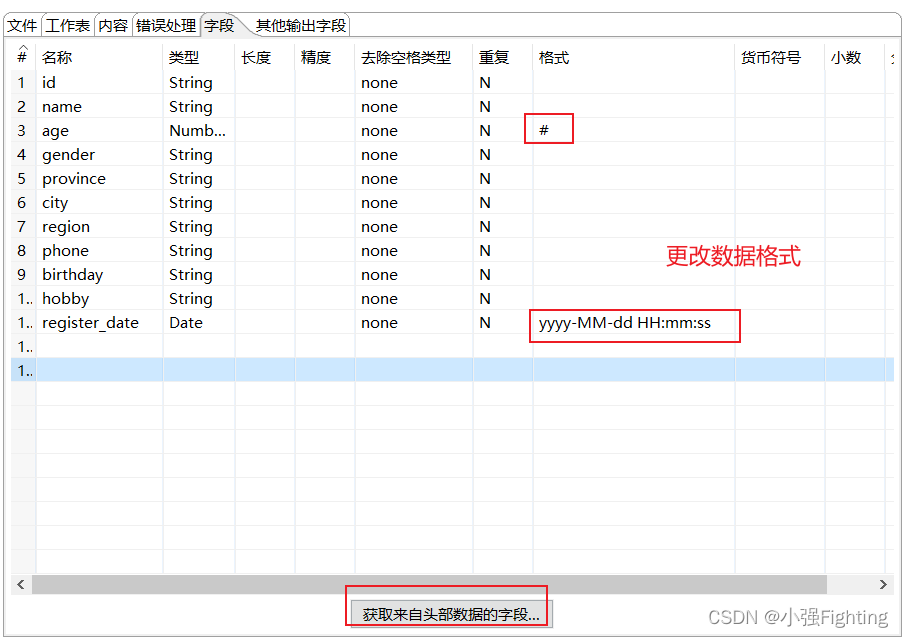
(3)配置输出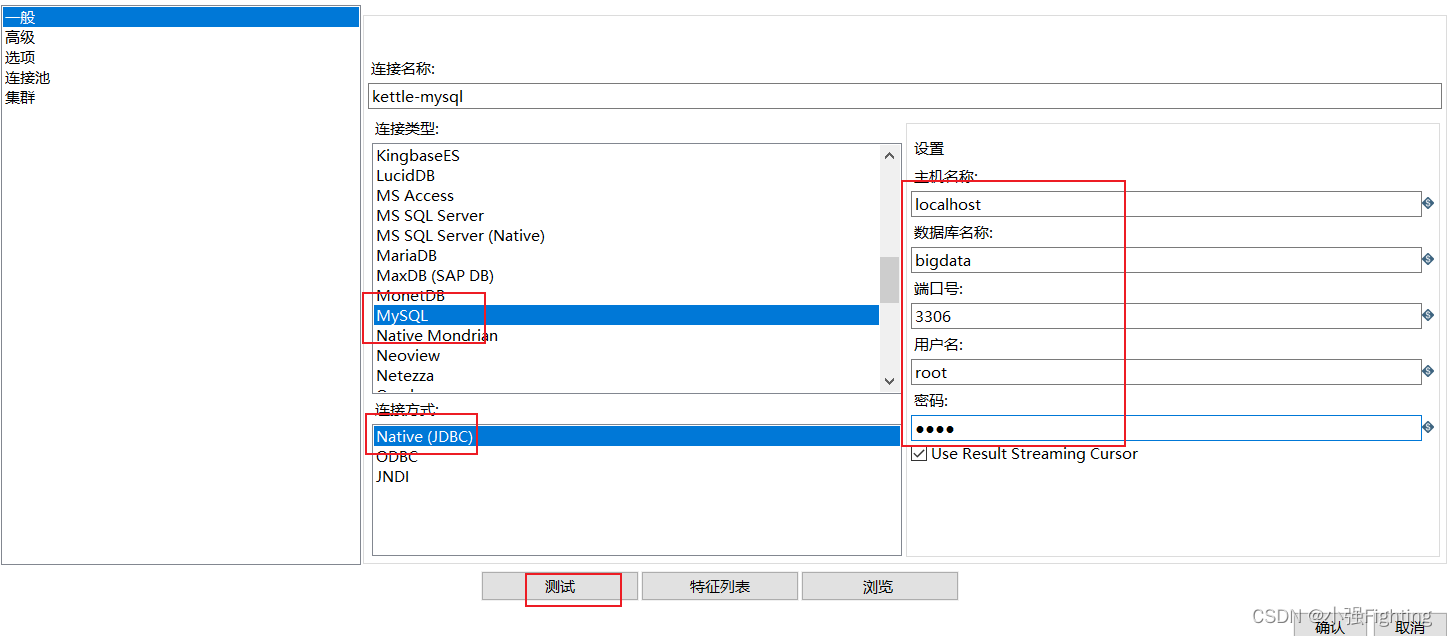
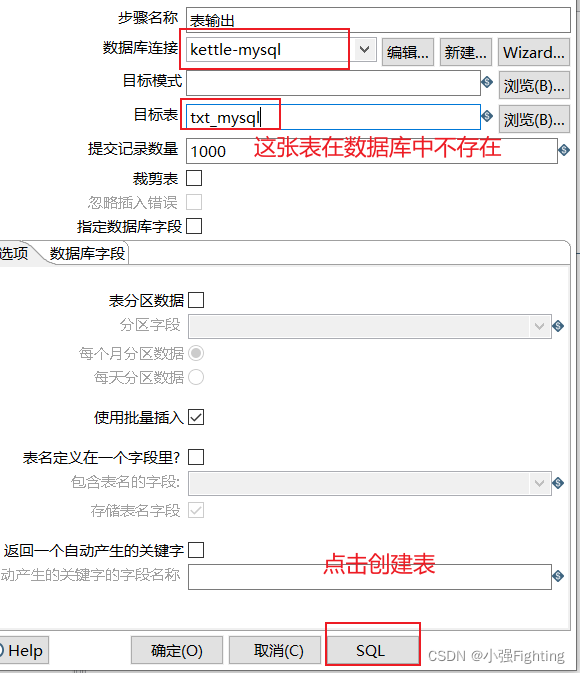
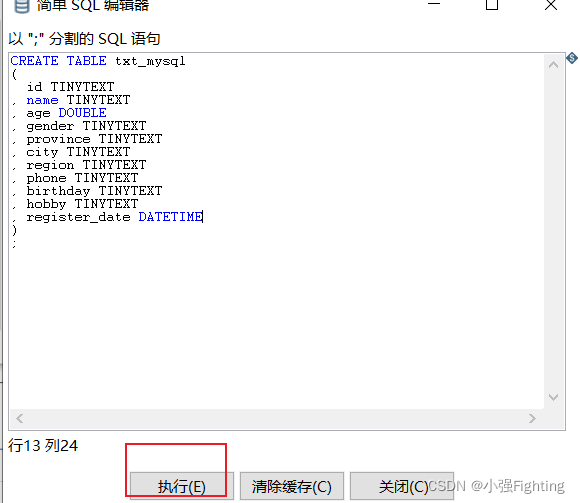
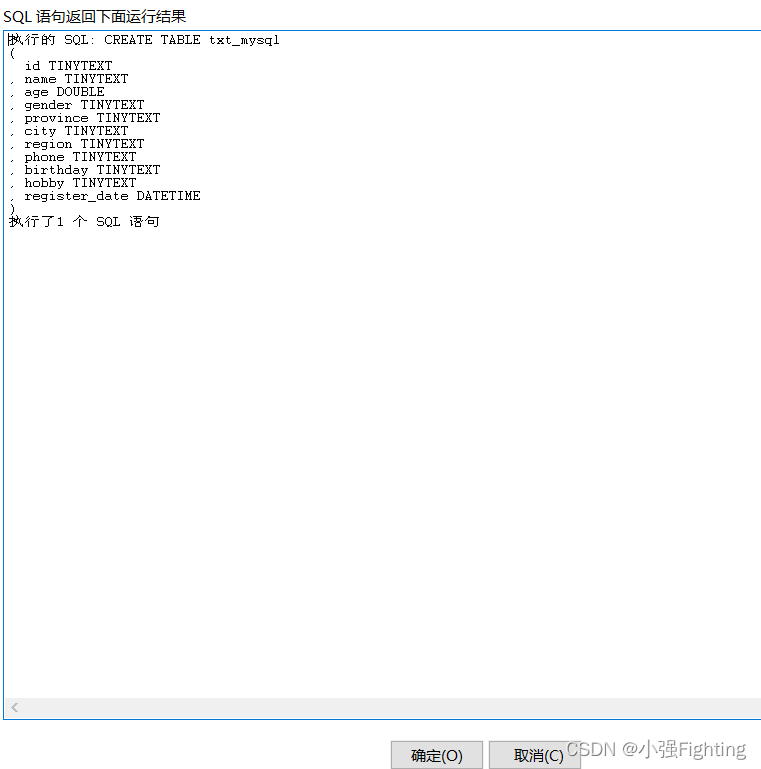
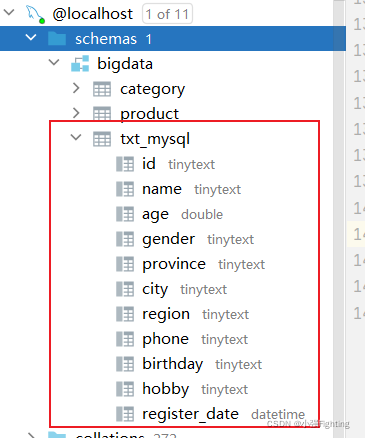
(4)执行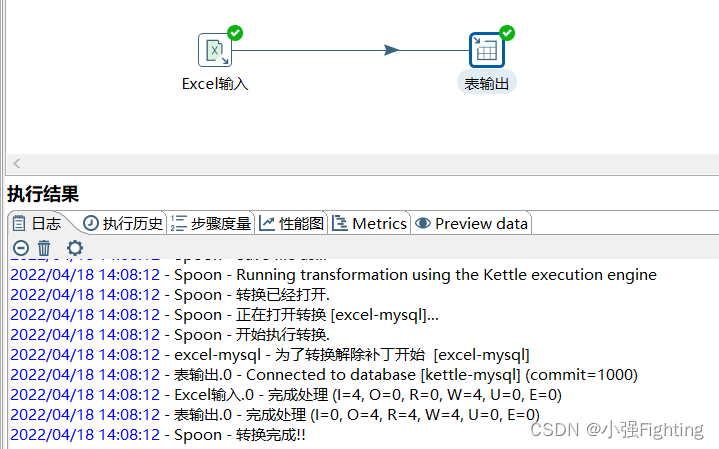
预览结果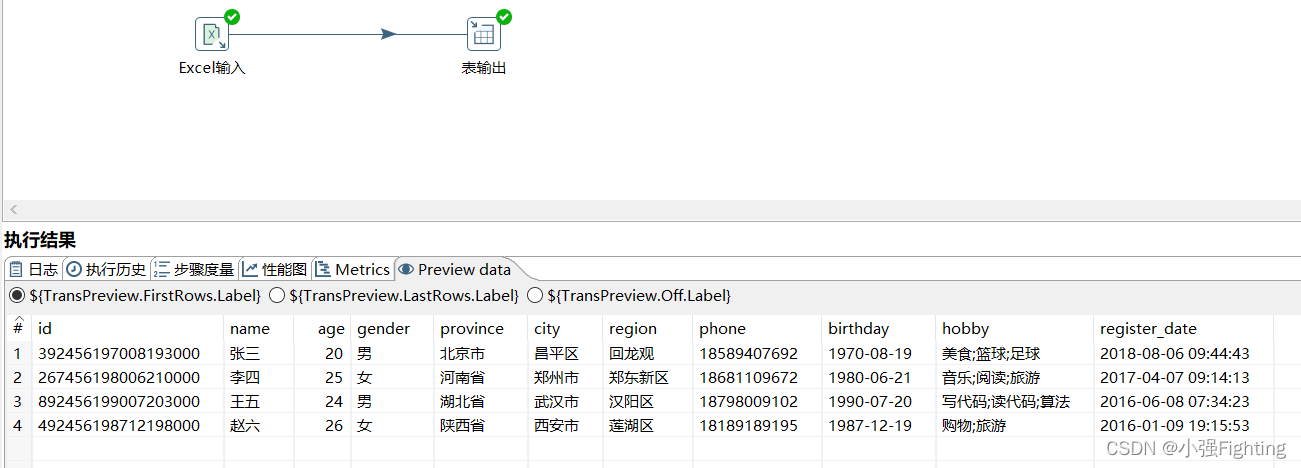
3.将t_user中的数据,同步到t_user1这张表中
(1)输入配置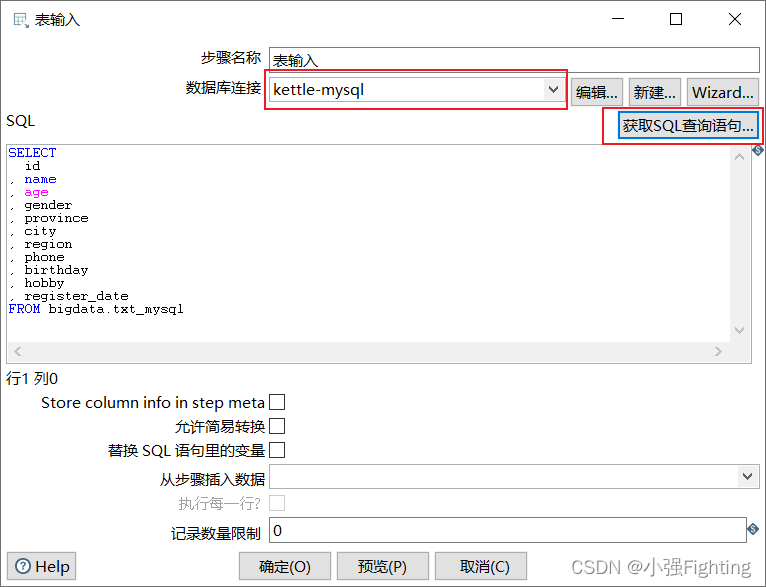
(2)输出配置
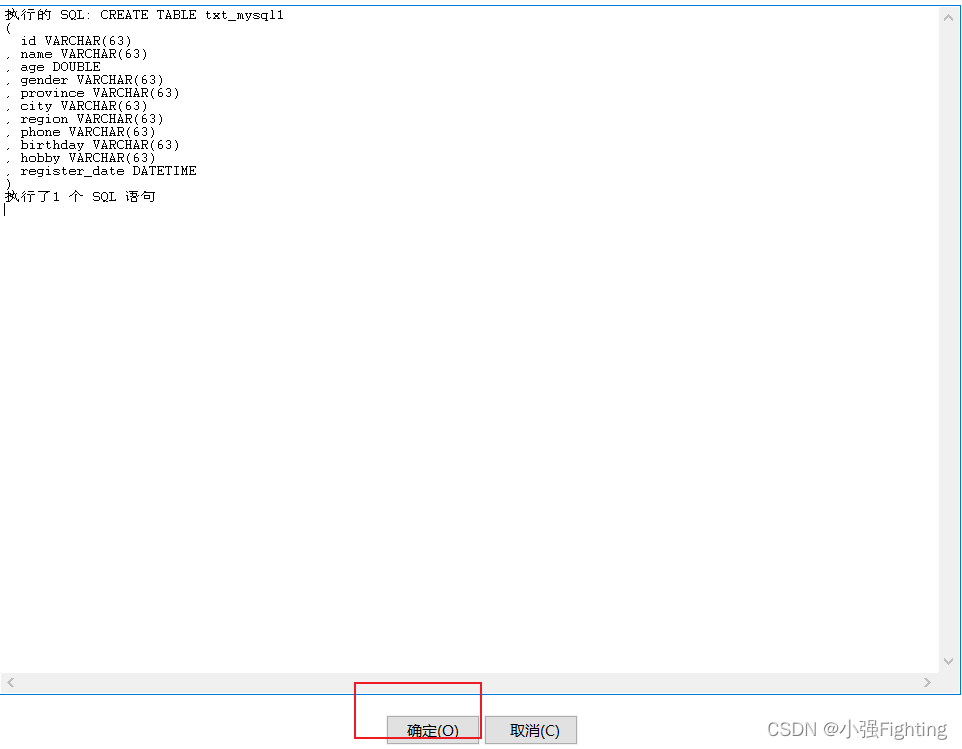
(3)执行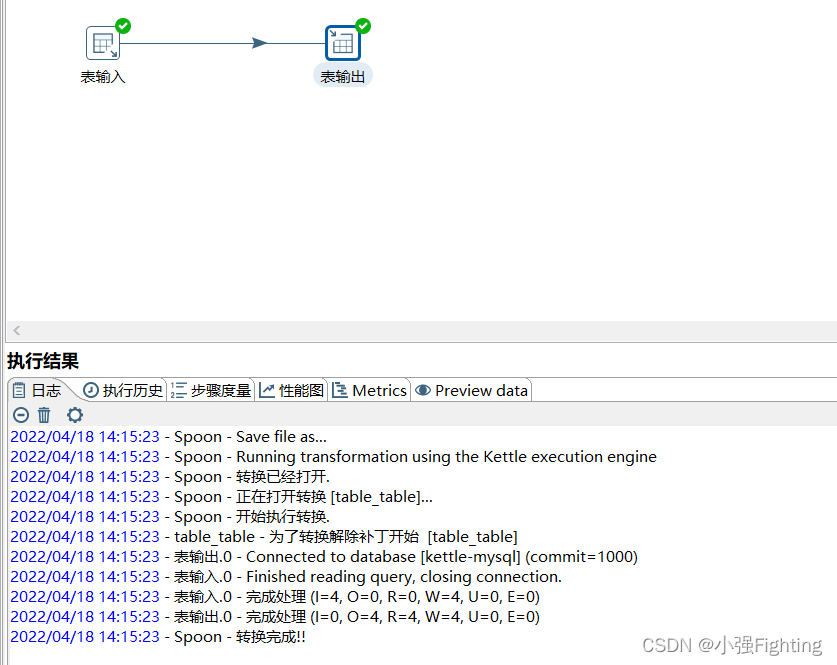 查看结果
查看结果
4.将 A表的数据同步到B表中,保证B表的数据与A表的数据一致,实现是不断更新的操作
(1)输入配置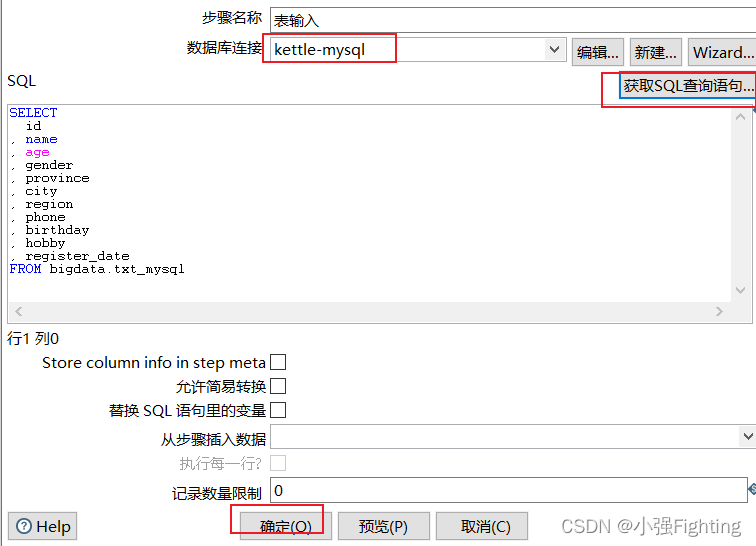
(2)输出配置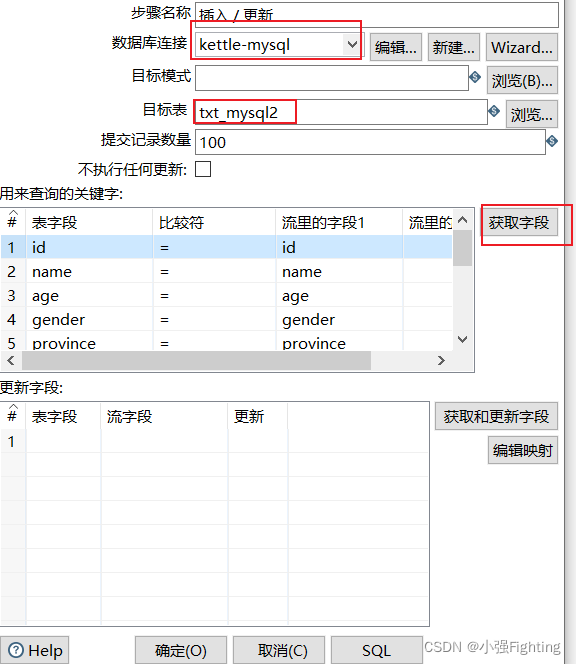
查询关键字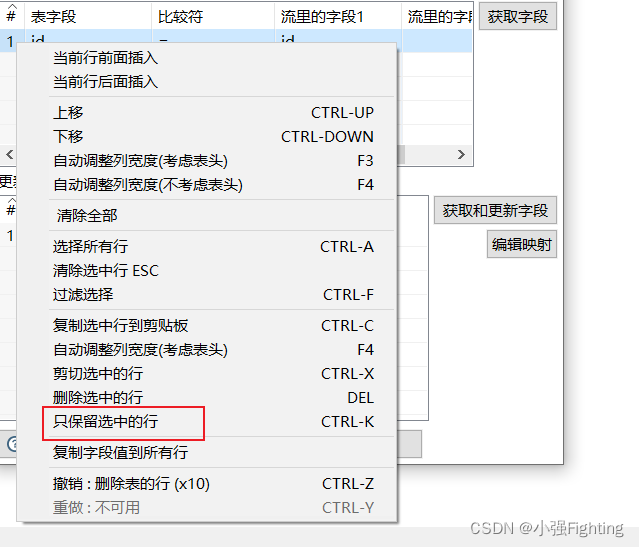
更新字段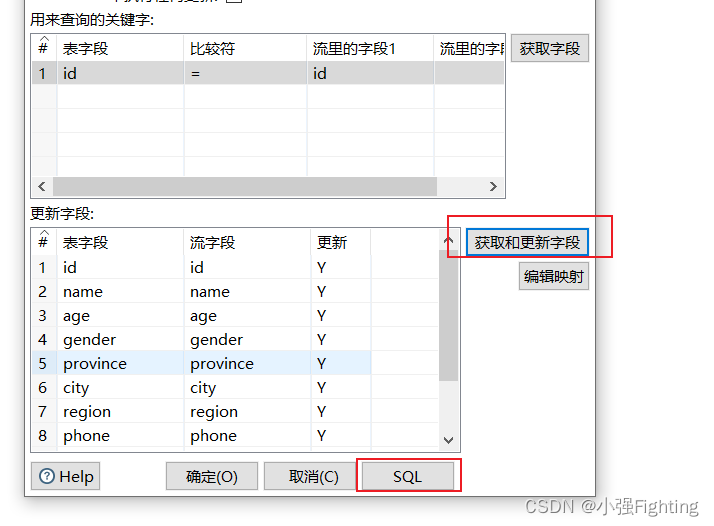
执行SQl语句,创建表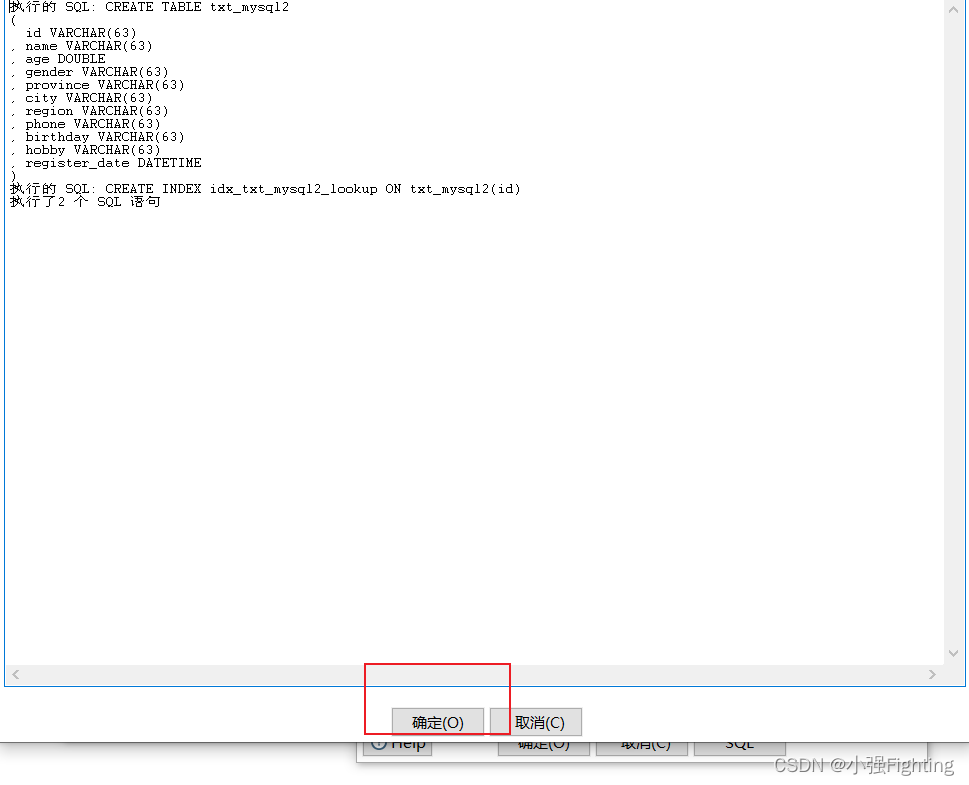
(3)执行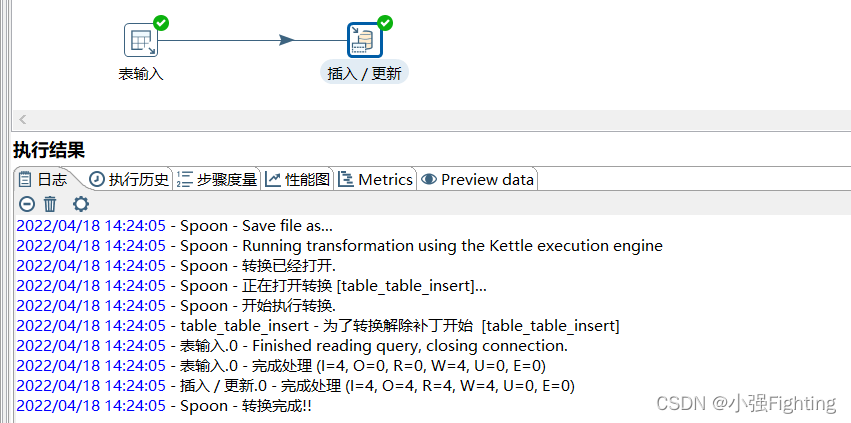
修改表中内容,再次运行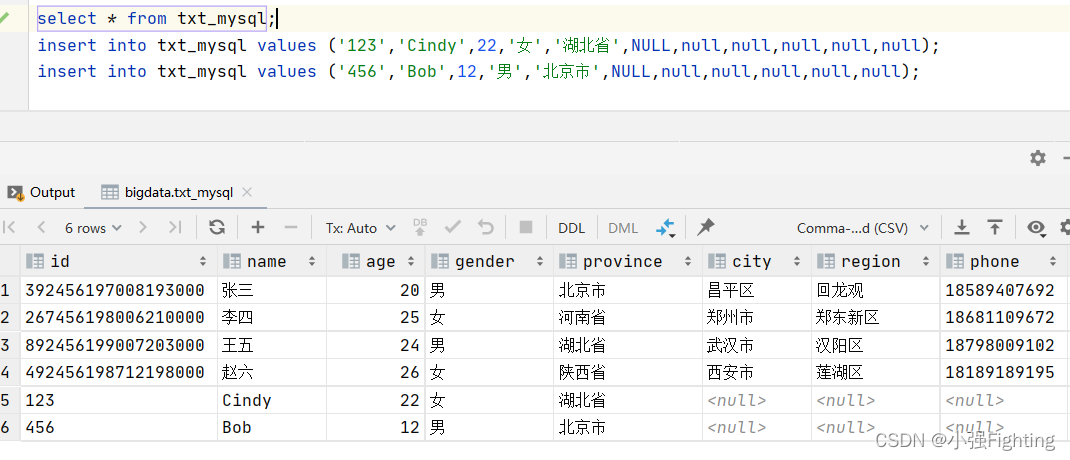
观察txt_mysql2中的数据
同步业务
- 全量:每次将所有的数据都同步一份
- 保证A和B是一致的
- 每次先删除B所有内容,然后,再同步
- 程序的性能比较差,数据量大了以后,非常慢,不建议使用
- 表输出:全量的组件
- 保证A和B是一致的
- 增量:每次将发生更新的数据同步,没有发生更新就是已经同步过的数据不再同步
- 保证A和B是一致的
- 工作中都使用增量的方式
- 插入更新:增量的组件
4.Kettle Job
1、Job的功能
- 转换:实现一种数据的转换处理,是一个转换任务
- 作业:实现多个转换任务按照一定的规则运行,就是一个任务流
- 时间规则:从00:10分开始,每5种运行一次
- 依赖规则:A成功了,就执行B
- 功能:将多个转换根据彼此之间的 关系实现任务流运行
2、Job开发
需求:每5s就运行一个Kettle的转换任务
(1)构建一个作业

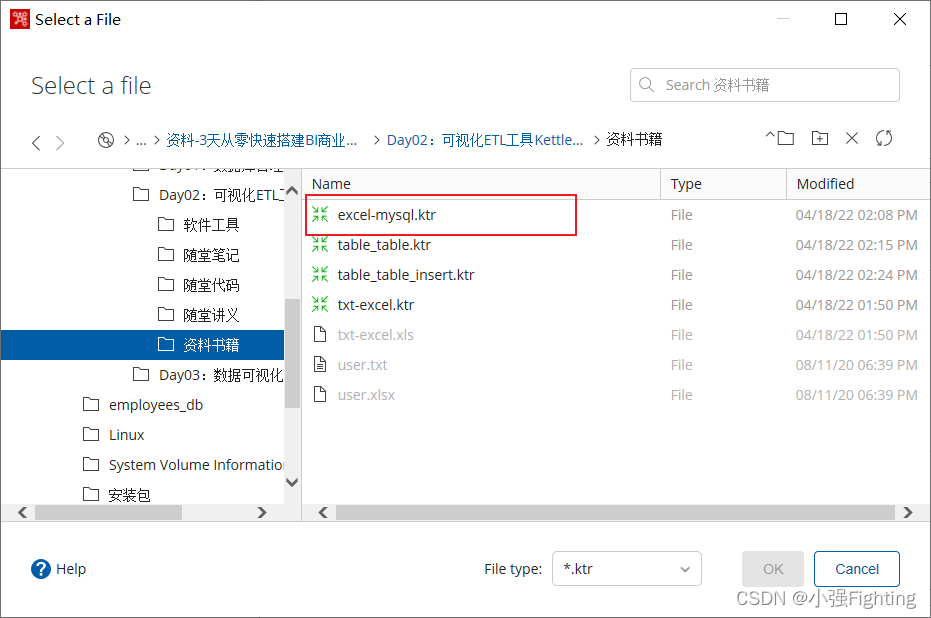
(2)配置转换任务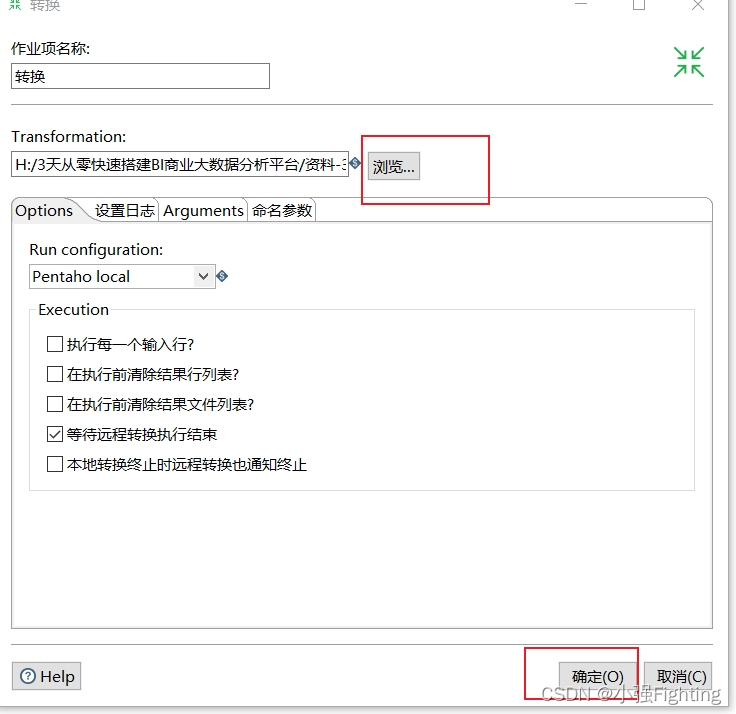
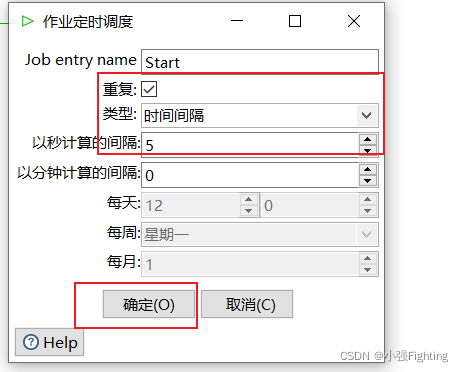
(3)启动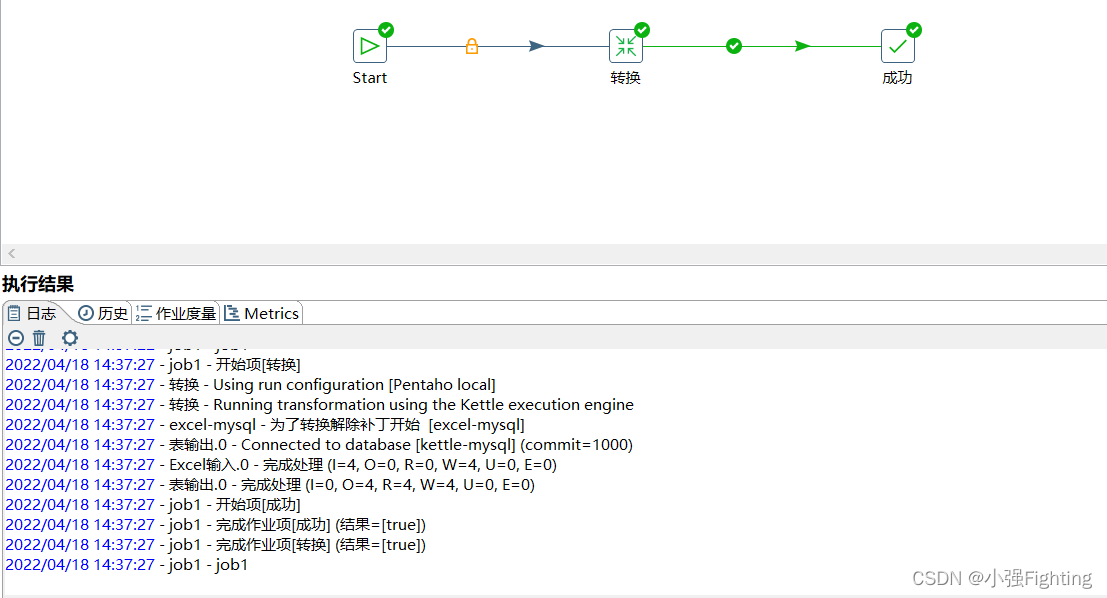
停止
三、商业BI可视化FineBI及电商订单综合案例
本案例围绕某个互联网小型电商的订单业务来开发。某电商公司,每天都有一些的用户会在线上采购商品,该电商公司想通过数据分析,查看每一天的电商经营情况。例如:电商公司的运营部门想要清楚的看到每天的订单笔数、订单的下单总额、不同支付类型对应的订单笔数和总额等等。
1 .技术方案介绍
本案例基于MySQL数据库,使用Kettle、帆软FineBI实现数据可视化。案例使用MySQL作为数据分析的存储以及查询引擎、以Kettle作为数据处理脚本执行工具、以及帆软FineBI实现数据可视化展示。
2. 案例架构说明及数据准备
1.系统架构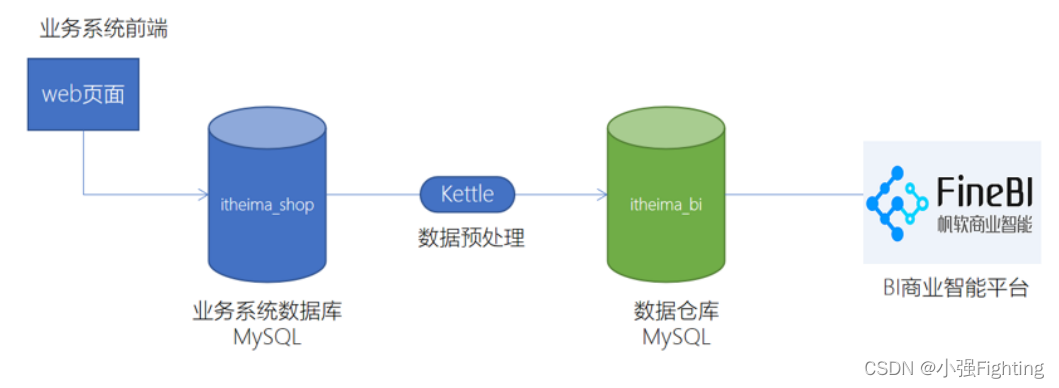
基于MySQL搭建数据仓库
基于Kettle进行数据处理
帆软FineBI基于MySQL搭建的数据仓库进行数据分析
2.数据流程图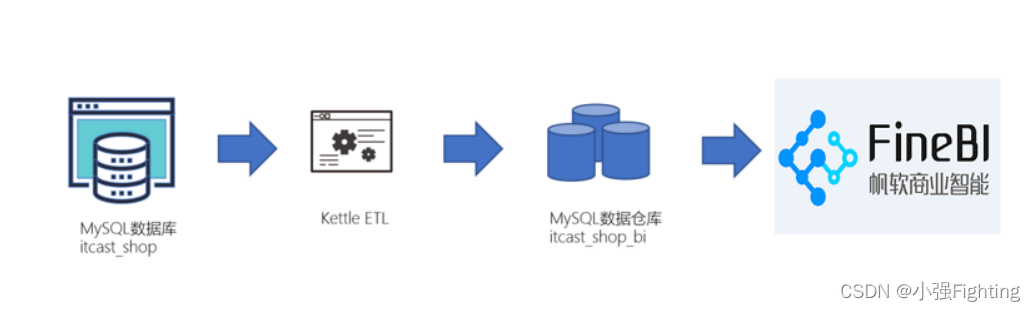
通过Kettle将MySQL业务系统数据库中,将数据抽取出来,然后装载到MySQL数据仓库中。
编写SQL脚本,对MySQL数据仓库中的数据进行数据分析(分组、聚合等),并将分析后的结
果保存。
使用 FineBI 将保存下来的分析结果以图形的方式展示出来。
3. 创建bigdata数据库并导入数据
为了完成本次案例,我们需要提前准备好 itcast_shop 数据库,我们准备好了一个SQL脚本文件【itcast_shop_v1.2.sql】,里面有很多的一些SQL语句,这些SQL语句会自动创建数据库、表,并将数据插入到表中。我们只需要使用DataGrip将SQL脚本文件执行下就可以了。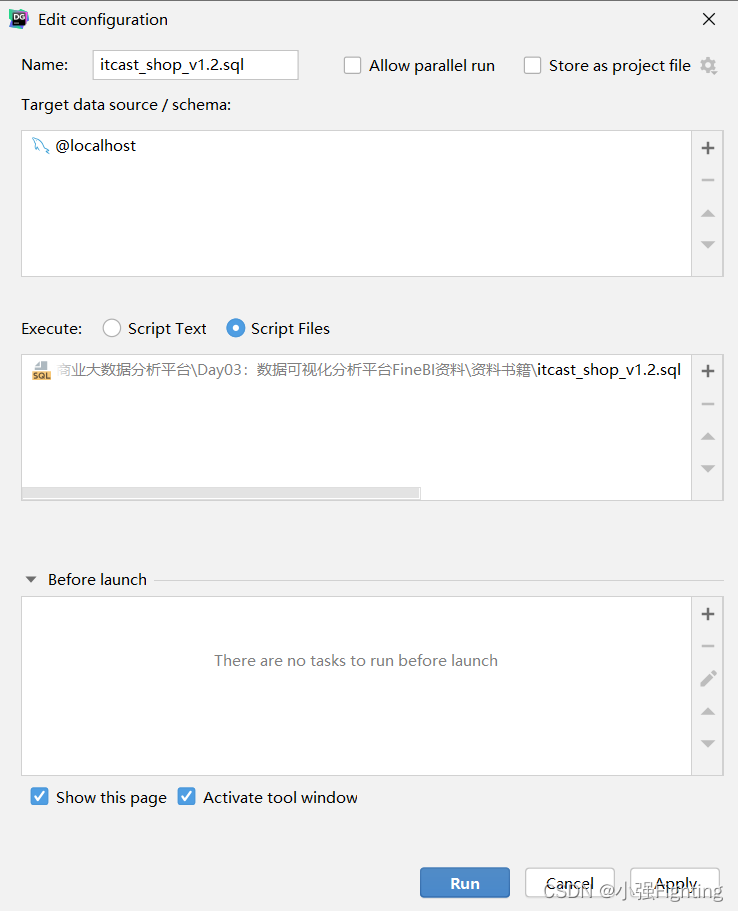
4.创建 itcast_shop_bi 数据仓库
create database if not exists itcast_shop_bi DEFAULT CHARACTER SET utf8;
3. MySQL数据分析开发
1.表结构概览
本次的综合案例,一共有六张表,分别为:

2.Kettle实现ETL到数据仓库
目前,itcast_shop_bi 中是没有任何数据的,是一个空的数据库。而后续我们的所有数据分析都将在该数据库中进行。我们第一件事情就是要将 「itcast_shop」数据库中的所有表抽取到「itcast_shop_bi」数据库中。要抽取并装载数据到「itcast_shop_bi」中,我们首先要在「itcast_shop_bi」中创建对应的表。
1 数据抽取业务分析
我们已经大概熟悉了上面的6张表,这6张表不是所有数据一次性原封不动地同步到数据仓库中,而是有一些处理细节。考虑以下几个业务场景:
1).每一天都需要进行订单的分析,例如:2020年4月18日一共有多少笔订单、订单的总额是多少。
2).每一天都需要进行用户的分析,例如:2020年4月18日一共注册有多少个用户。
3).商品分类、区域的变化率很少,因为分类、区域几乎都是常年不变的。
4).商品的数据相对变化频率较高,因为可能每天都会有商品信息的更新。

全量同步抽取:将所有数据同步抽取到数据仓库
增量同步抽取:只抽取抽取新增的数据到数据仓库
3 每周数据抽取作业开发

根据之前的分析,行政区域表为全量同步抽取,所以我们只需要全部抽取到数据仓库中建表即可。但需要注意:我们需要清晰地标识出数据是哪天抽取过来的,所以需要额外添加一个当前日期的字段。
- 以订单表为例
(1)建立数据库连接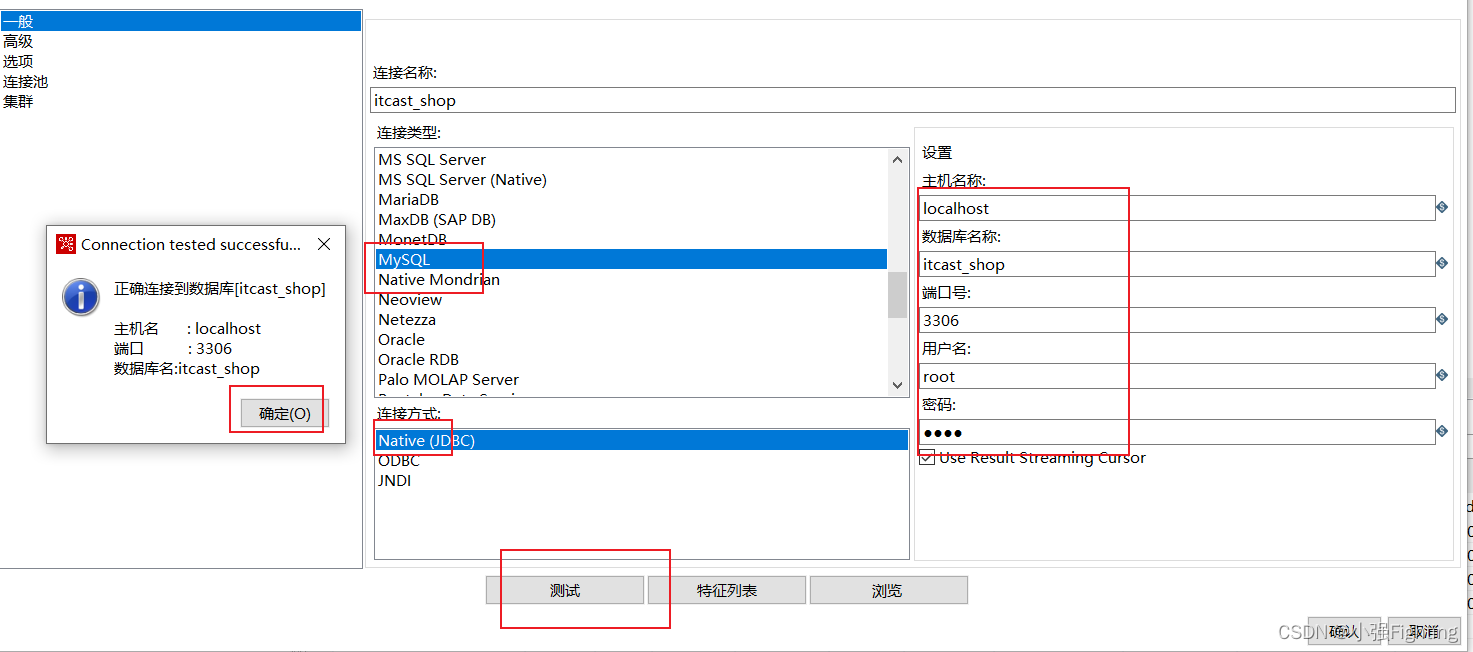
(2)输入配置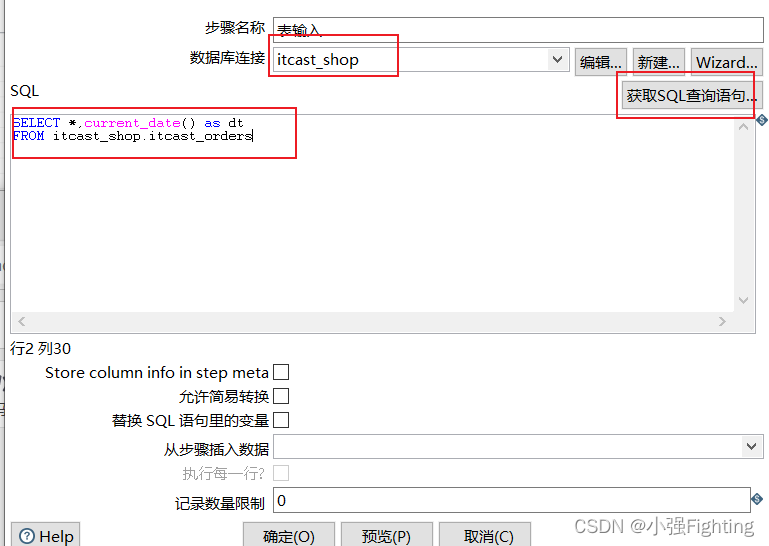
SELECT *,current_date() as dt
FROM itcast_shop.itcast_orders
(3)插入/更新配置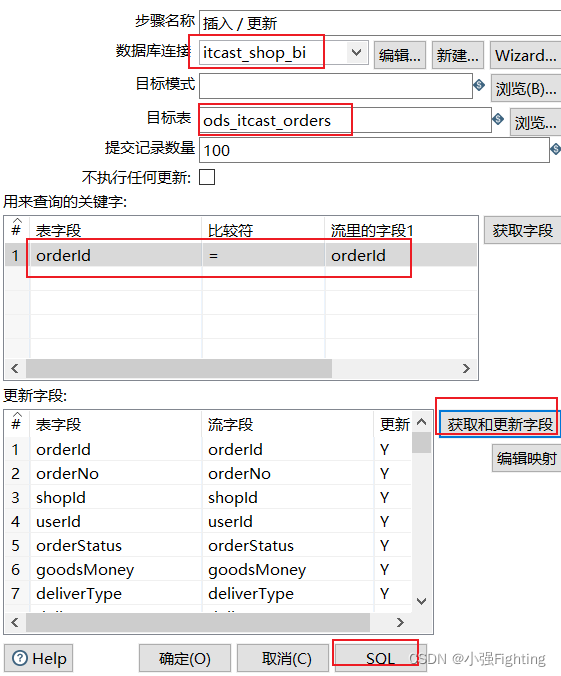
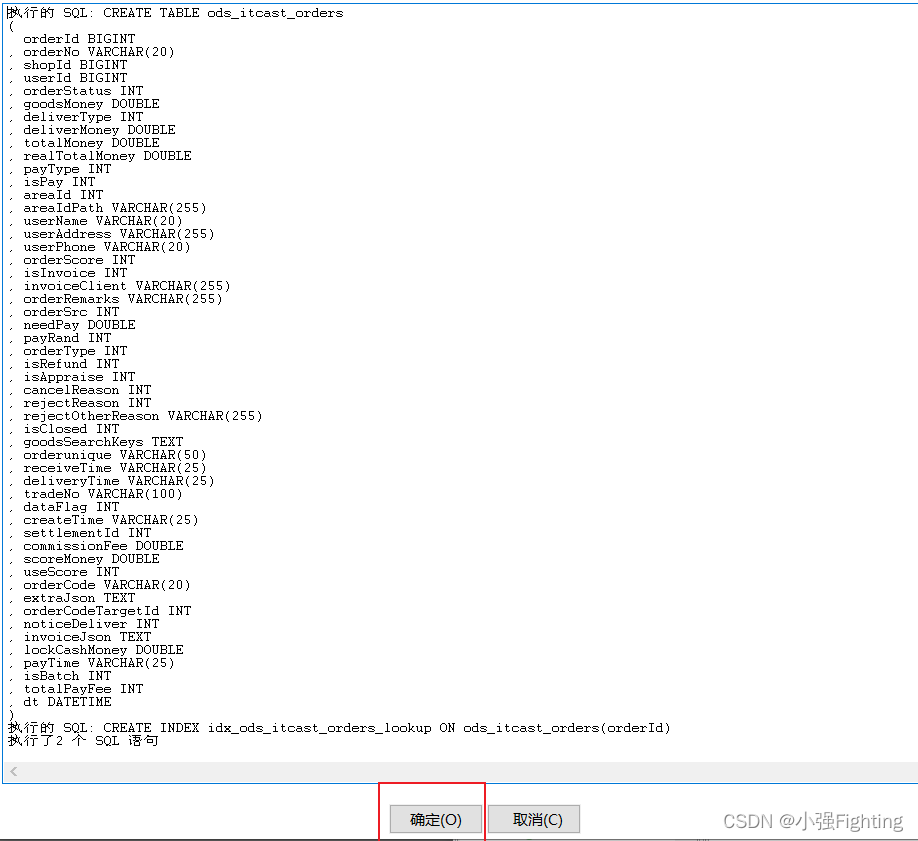
(4)测试运行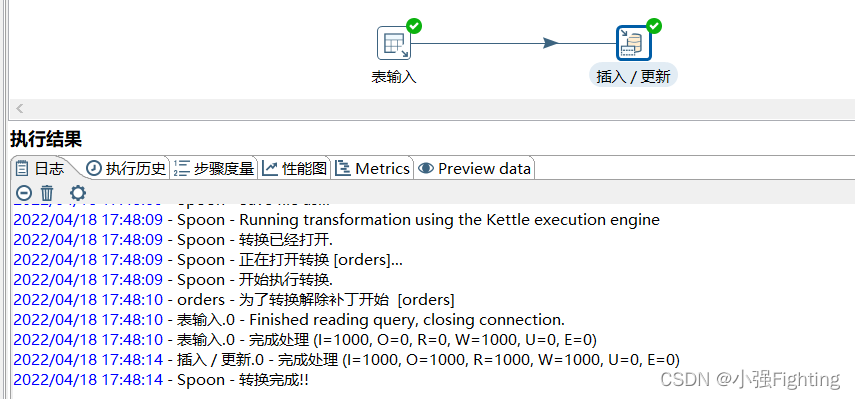
(5)构建作业,每天执行一次
配置转换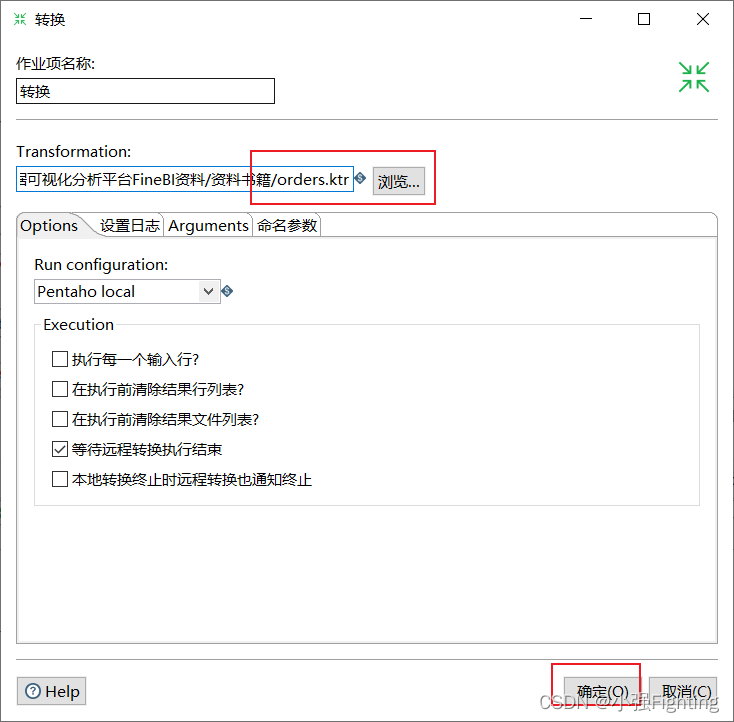
配置开始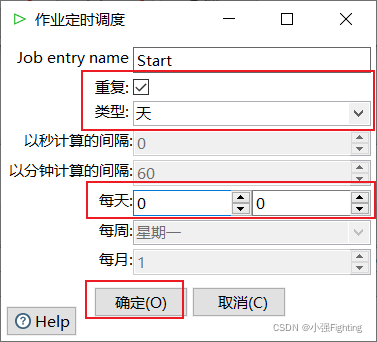
4.直接导入ETL以后的数据
四、MySQL分析开发
1、每日订单总额/总笔数分析
(1) 明确数据分析目标——统计每天的订单总金额及订单总笔数
(2) 创建用于保存数据分析结果的表
use itcast_shop_bi;
create table app_order_total(
id int primary key auto_increment,
dt date,
total_money double,
total_cnt int
);
(3)编写SQL语句进行数据分析
- substring:截取数据
- round:指定保留几位小数
# 创建用于保存数据分析结果的表
use itcast_shop_bi;
create table app_order_total(
id int primary key auto_increment,
dt date,
total_money double,
total_cnt int
);
# 实现分析
select
substring(createTime,1,10) as dt,
round(sum(realTotalMoney),2) as total_money,
count(orderId) as total_cnt
from ods_itcast_orders
where substring(createTime,1,10)='2019-09-05'
group by substring(createTime,1,10);
# 保存结果
insert into app_order_total
select
null,
substring(createTime,1,10) as dt,
round(sum(realTotalMoney),2) as total_money,
count(orderId) as total_cnt
from ods_itcast_orders
where substring(createTime,1,10)='2019-09-05'
group by substring(createTime,1,10);
2、下订单用户总数分析
# 建表
create table app_order_user(
id int primary key auto_increment,
dt date,
total_user_cnt int
);
# 实现
select
substring(createTime, 1, 10) as dt,
count(distinct userId) as total_user_cnt
from ods_itcast_orders
group by substring(createTime, 1, 10);
# 保存
insert into app_order_user
select
null,
substring(createTime, 1, 10) as dt,
count(distinct userId) as total_user_cnt
from ods_itcast_orders
group by substring(createTime, 1, 10);

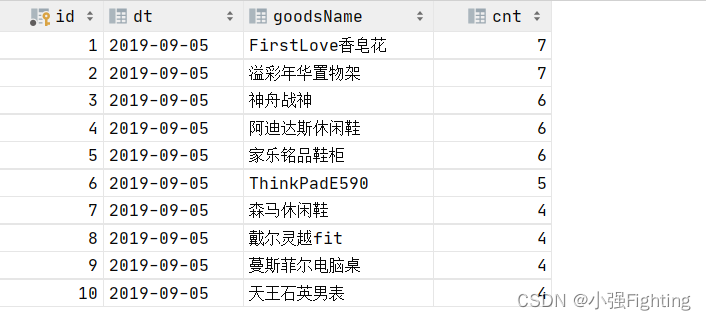
3、 热门商品top10
需求:统计所有订单中哪些商品被购买的次数最多的前10名
# 建表
create table app_goods_top10(
id int primary key auto_increment,
dt date,
goodsName varchar(100),
cnt int
);
# 查询
select
b.goodsName,
count(*) as cnt,
substring(b.createTime,1,10)
from ods_itcast_order_goods a join ods_itcast_goods b on a.goodsId=b.goodsId
group by b.goodsName,substring(b.createTime,1,10)
order by cnt desc
limit 10;
# 保存
insert into app_goods_top10
select
null,
substring(b.createTime,1,10),
b.goodsName,
count(*) as cnt
from ods_itcast_order_goods a join ods_itcast_goods b on a.goodsId=b.goodsId
group by b.goodsName,substring(b.createTime,1,10)
order by cnt desc
limit 10;
4、每天每小时上架商品个数
需求:统计每天每个小时上架的商品个数
# 查询
select
substring(createTime,1,10) daystr,
substring(createTime,12,2) hourstr,
count(*) cnt
from ods_itcast_goods
group by substring(createTime,1,10),substring(createTime,12,2)
order by daystr,hourstr;
# 建表
create table app_hour_goods(
id int primary key auto_increment,
daystr date,
hourstr varchar(10),
cnt int
);
# 保存
insert into app_hour_goods
select
null,
substring(createTime,1,10) daystr,
substring(createTime,12,2) hourstr,
count(*) cnt
from ods_itcast_goods
group by substring(createTime,1,10),substring(createTime,12,2)
order by daystr,hourstr;
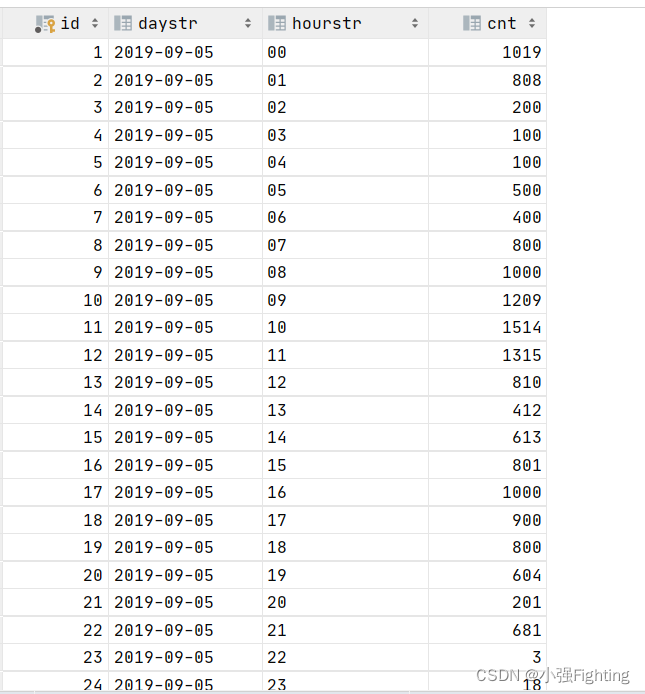
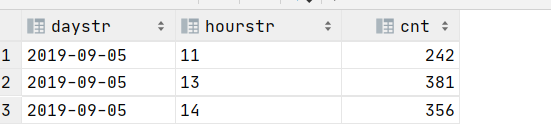
5、每天每小时订单笔数
需求:统计每天每个小时订单的个数
# 查询
select
substring(createTime,1,10) daystr,
substring(createTime,12,2) hourstr,
count(*) cnt
from ods_itcast_orders
group by substring(createTime,1,10),substring(createTime,12,2)
order by daystr,hourstr;
# 建表
create table app_hour_orders(
id int primary key auto_increment,
daystr date,
hourstr varchar(10),
cnt int
);
# 保存
insert into app_hour_orders
select
null,
substring(createTime,1,10) daystr,
substring(createTime,12,2) hourstr,
count(*) cnt
from ods_itcast_orders
group by substring(createTime,1,10),substring(createTime,12,2)
order by daystr,hourstr;
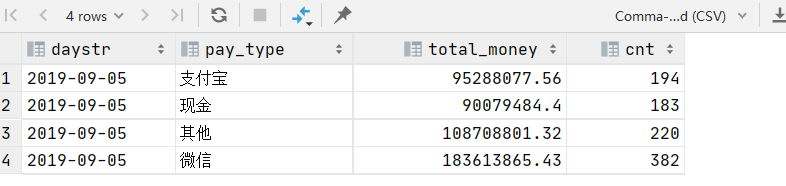
6、每天不同支付方式订单总额/订单笔数
# 查询
select
substring(createTime,1,10) daystr,
case payType when 1 then '支付宝' when 2 then '微信' when 3 then '现金' else '其他' end as pay_type,
round(sum(realTotalMoney),2) as total_money,
count(orderId) as cnt
from ods_itcast_orders
group by substring(createTime,1,10),payType;
# 建表
create table app_order_paytype(
id int primary key auto_increment,
dt date,
pay_type varchar(100),
total_money double,
total_cnt int
);
# 保存
insert into app_order_paytype
select
null,
substring(createTime,1,10) daystr,
case payType when 1 then '支付宝' when 2 then '微信' when 3 then '现金' else '其他' end as pay_type,
round(sum(realTotalMoney),2) as total_money,
count(orderId) as cnt
from ods_itcast_orders
group by substring(createTime,1,10),payType;
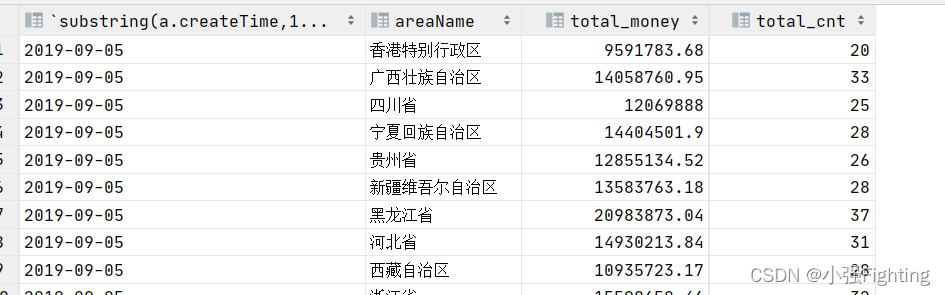
7、每天各省份订单总金额、订单总笔数
需求:统计每天每个省份的订单总金额以及订单总个数
# 查询
select
substring(a.createTime,1,10),
areaName,
round(sum(realTotalMoney),2) total_money,
count(orderId) total_cnt
from ods_itcast_orders a join ods_itcast_area b on a.areaId=b.areaId
group by substring(a.createTime,1,10),areaName;
# 建表
create table app_order_province(
id int primary key auto_increment,
daystr date,
province varchar(100),
total_money double,
total_cnt int
);
# 保存
insert into app_order_province
select
null,
substring(a.createTime,1,10),
areaName,
round(sum(realTotalMoney),2) total_money,
count(orderId) total_cnt
from ods_itcast_orders a join ods_itcast_area b on a.areaId=b.areaId
group by substring(a.createTime,1,10),areaName;
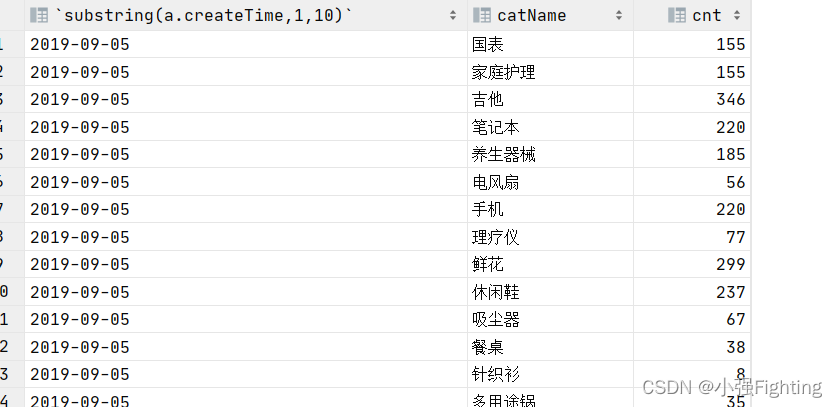
8、每天不同商品分类订单个数统计
需求:统计每天不同商品分类对应订单的个数
# 查询
select
substring(a.createTime,1,10),
c.catName,
count(*) cnt
from
ods_itcast_order_goods a join ods_itcast_goods b on a.goodsId=b.goodsId
join ods_itcast_good_cats c on b.goodsCatId=c.catId
group by substring(a.createTime,1,10),catName;
# 建表
create table app_cat_cnt(
id int primary key auto_increment,
daystr date,
catName varchar(100),
cnt int
);
# 保存
insert into app_cat_cnt
select
null,
substring(a.createTime,1,10),
c.catName,
count(*) cnt
from
ods_itcast_order_goods a join ods_itcast_goods b on a.goodsId=b.goodsId
join ods_itcast_good_cats c on b.goodsCatId=c.catId
group by substring(a.createTime,1,10),catName;
五、FineBI实现数据可视化
1.启动登录
2.构建连接
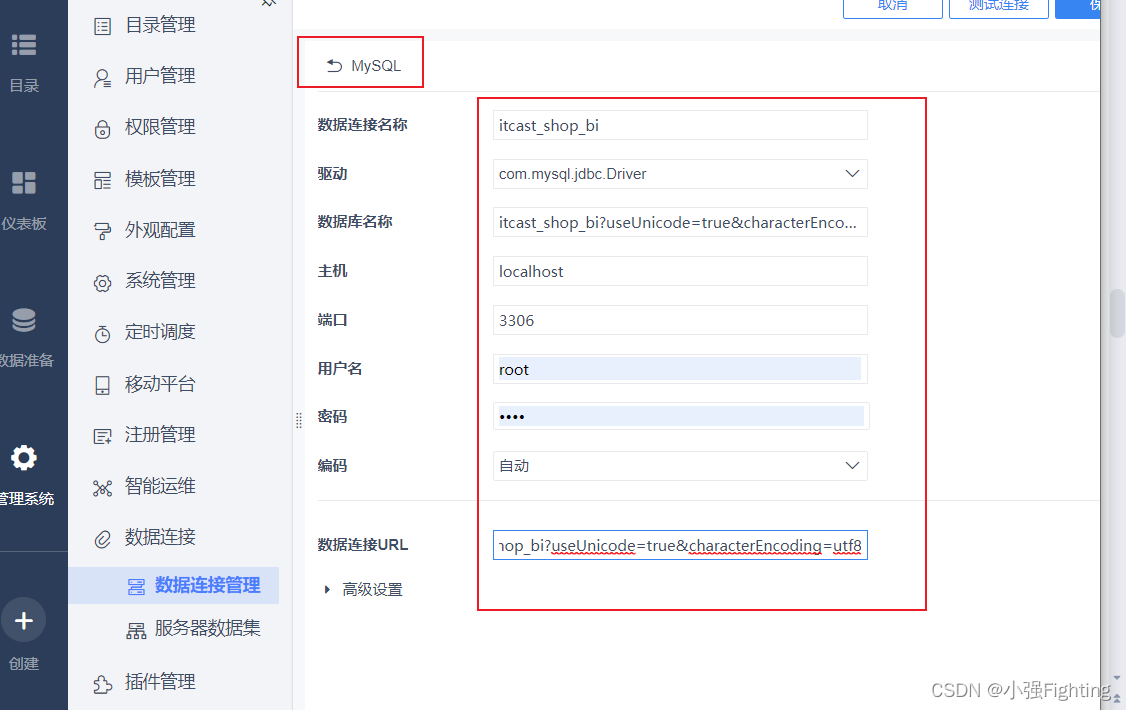
数据连接名称:itcast_shop_bi
数据库名称:itcast_shop_bi
主机:localhost
端口3306
用户名:root
密码:123456
数据连接URL:jdbc:mysql://localhost:3306/itcast_shop_bi?useUnicode=true&characterEncoding=utf8
测试连接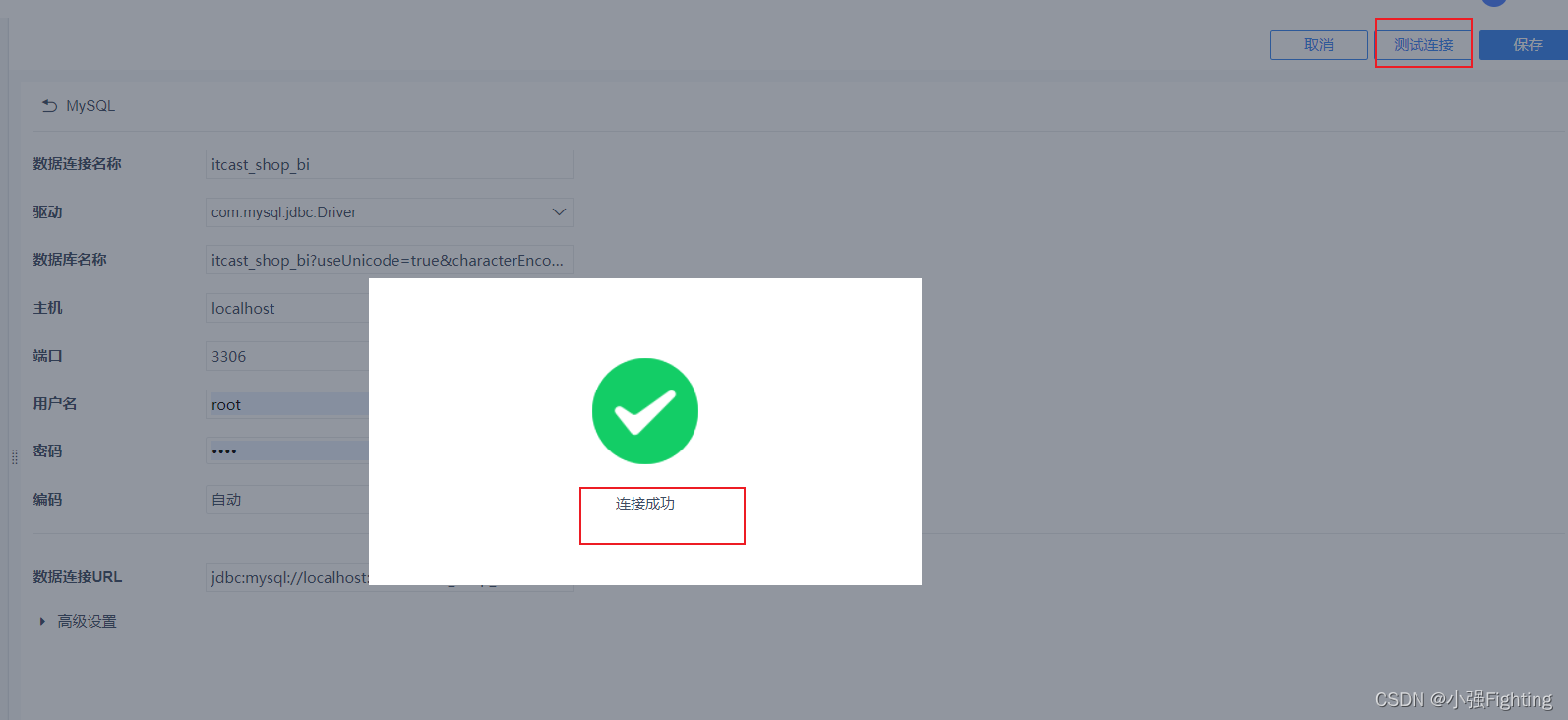
3.配置数据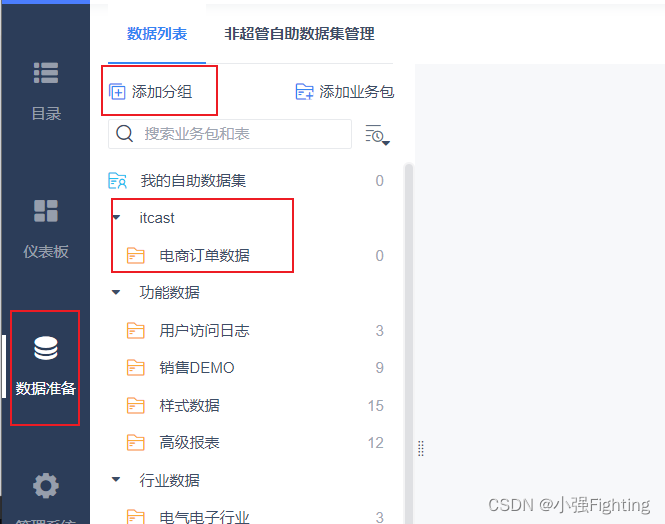

添加数据表app开头的表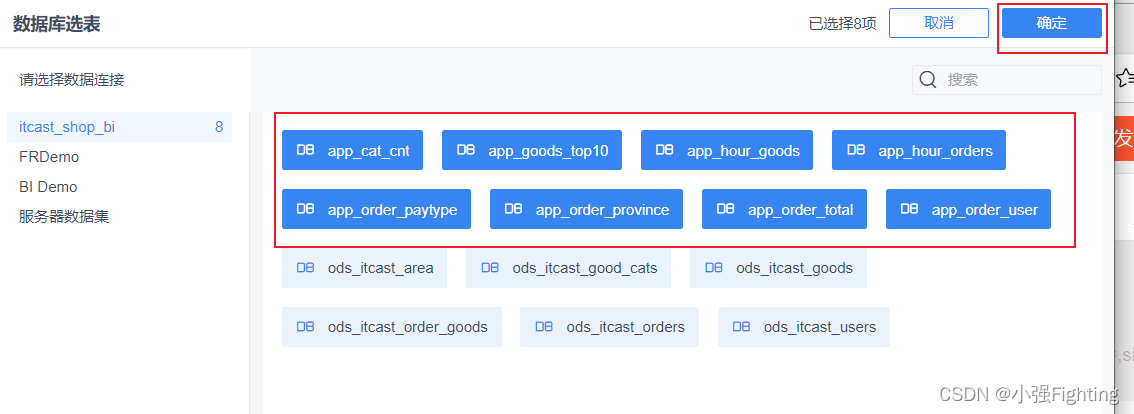
查看数据信息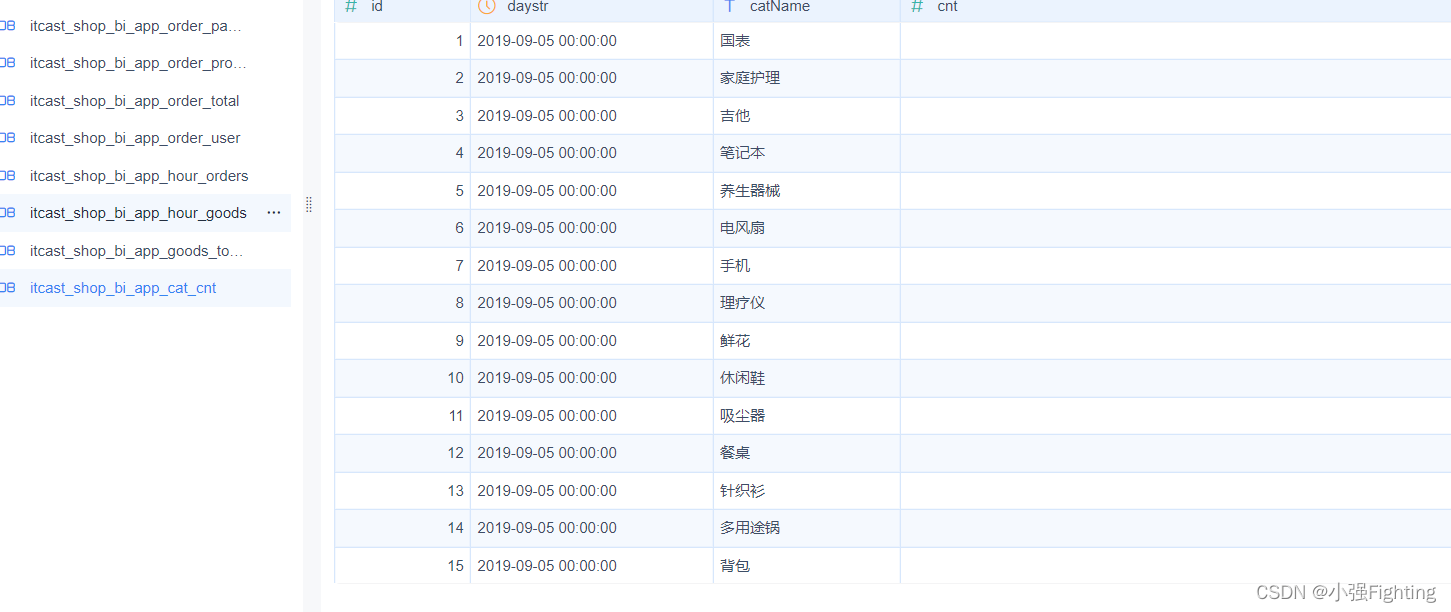
更新业务包,导入数据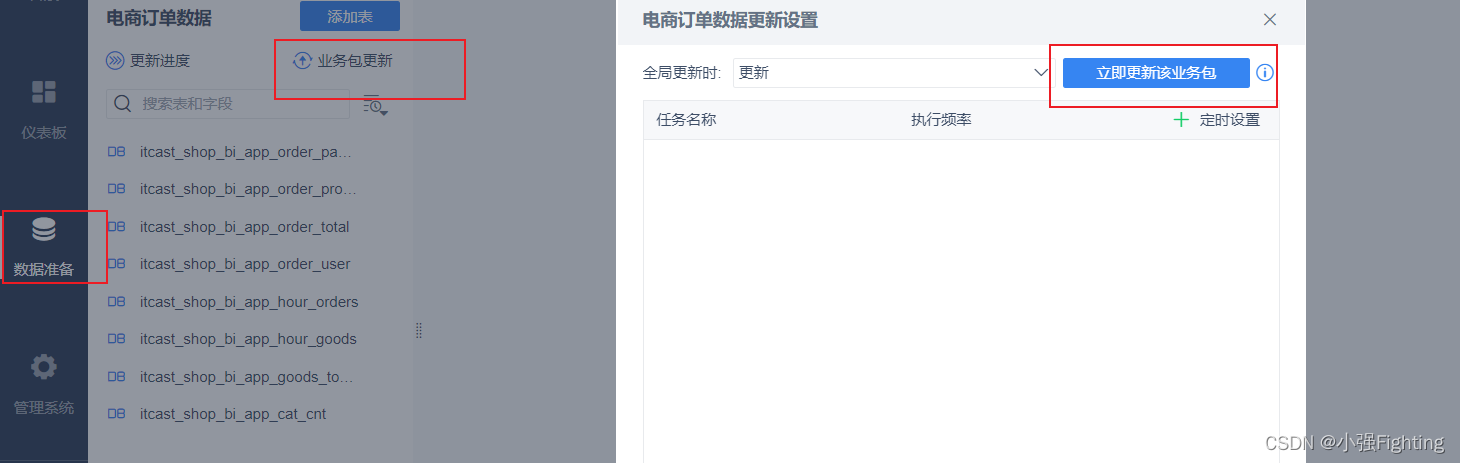
4.构建按仪表盘
新建仪表盘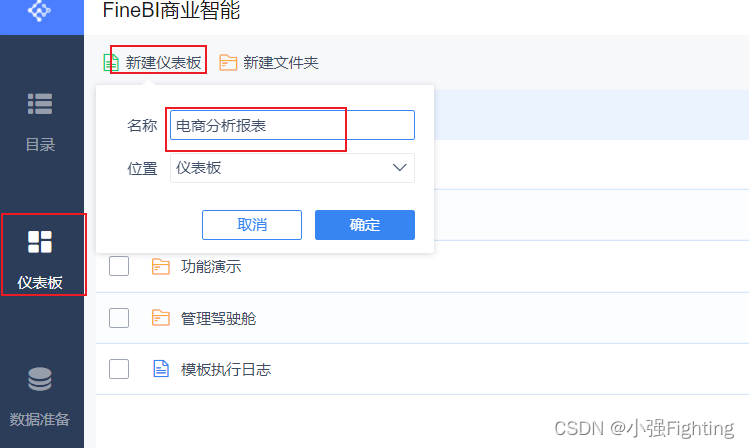
5.添加图表
添加标题

添加组件
1.每日订单总个数
选择数据表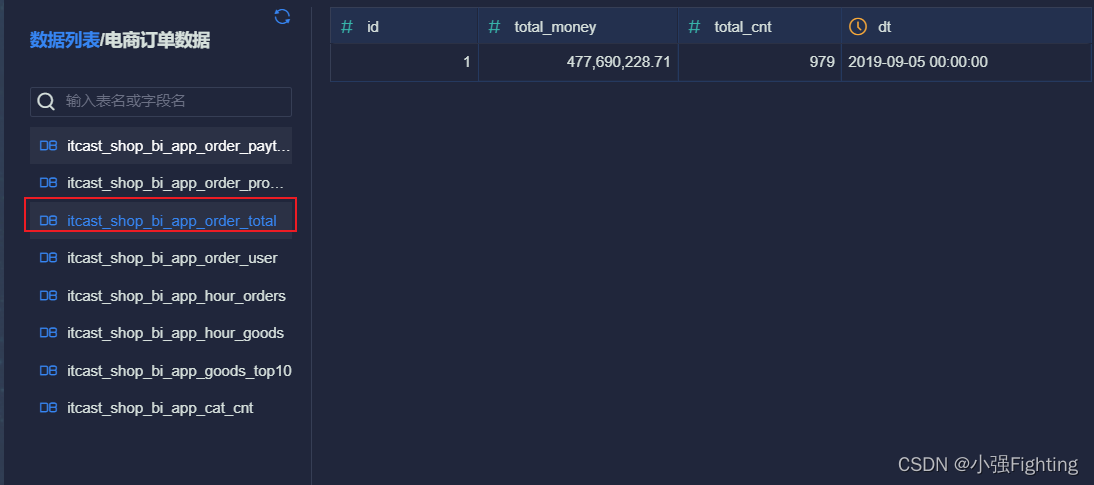
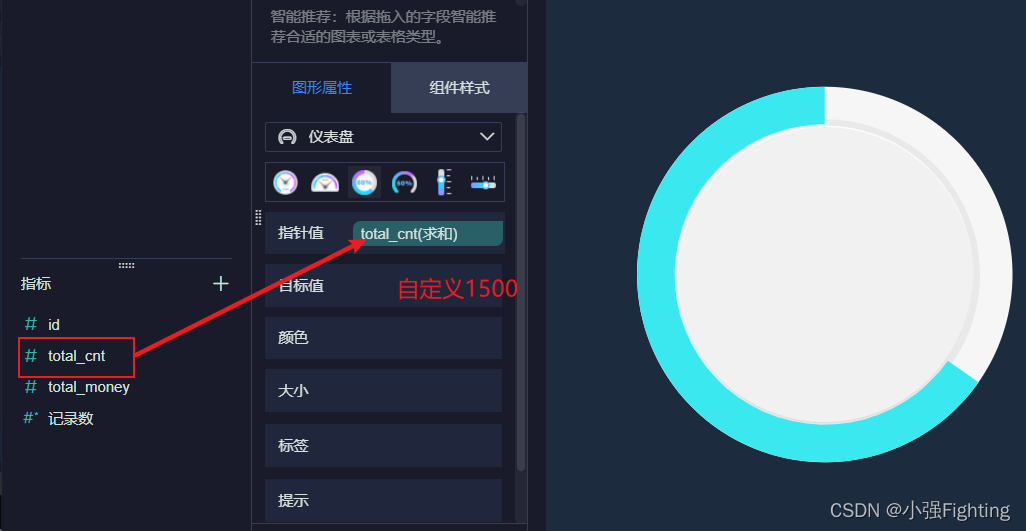
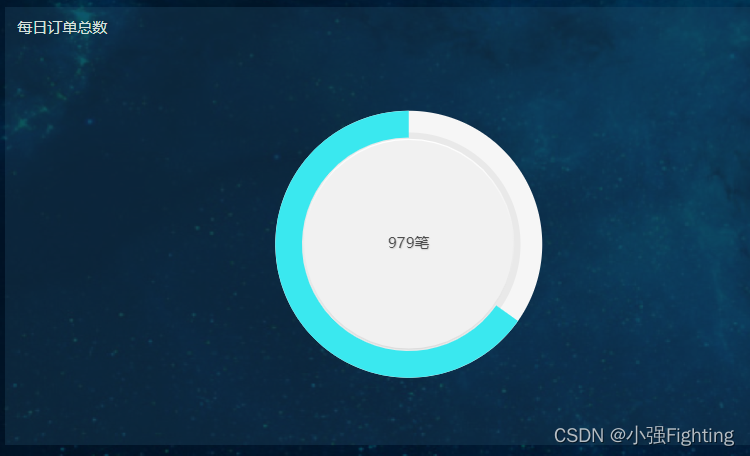
2.每日订单总金额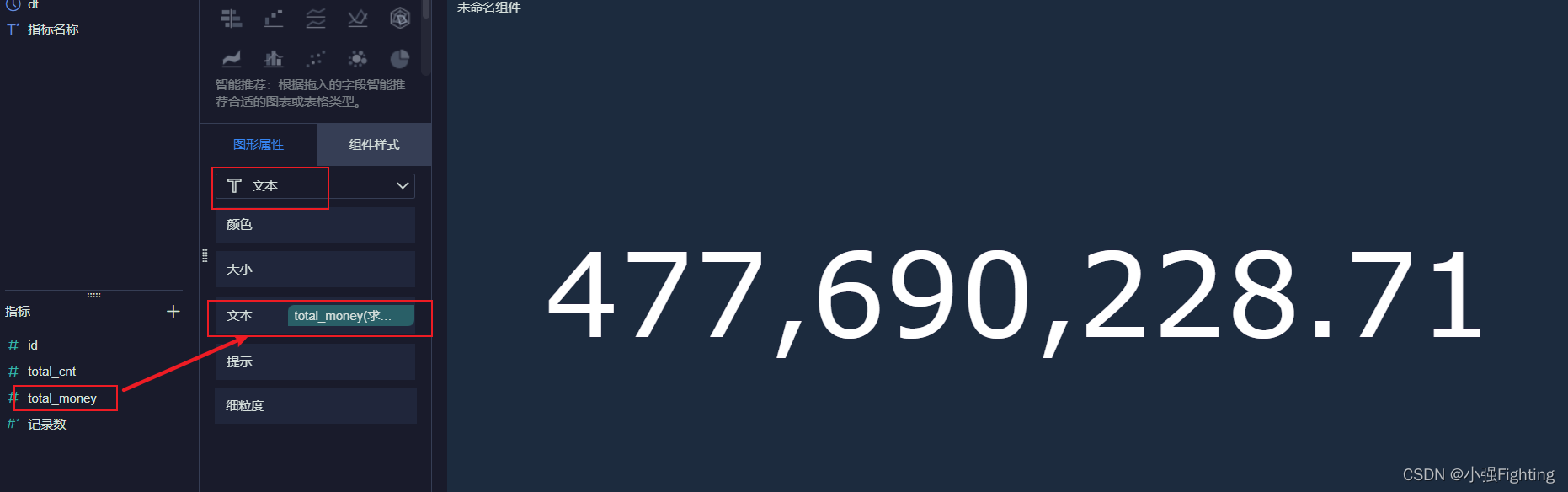

3.每日订单用户数
选择数据表


4.热门商品Top10
选择数据表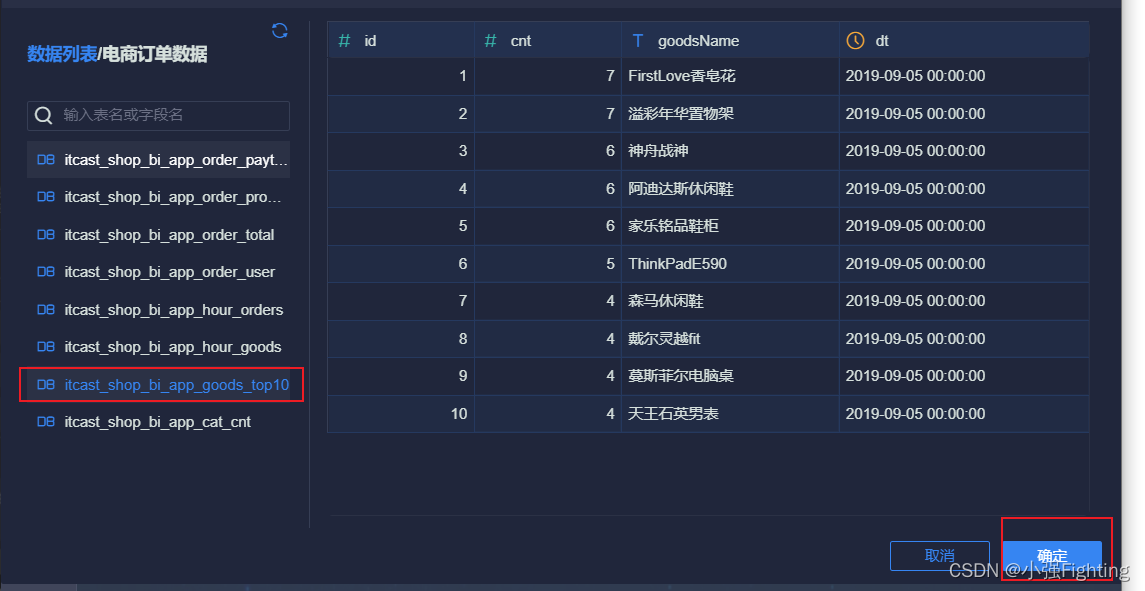
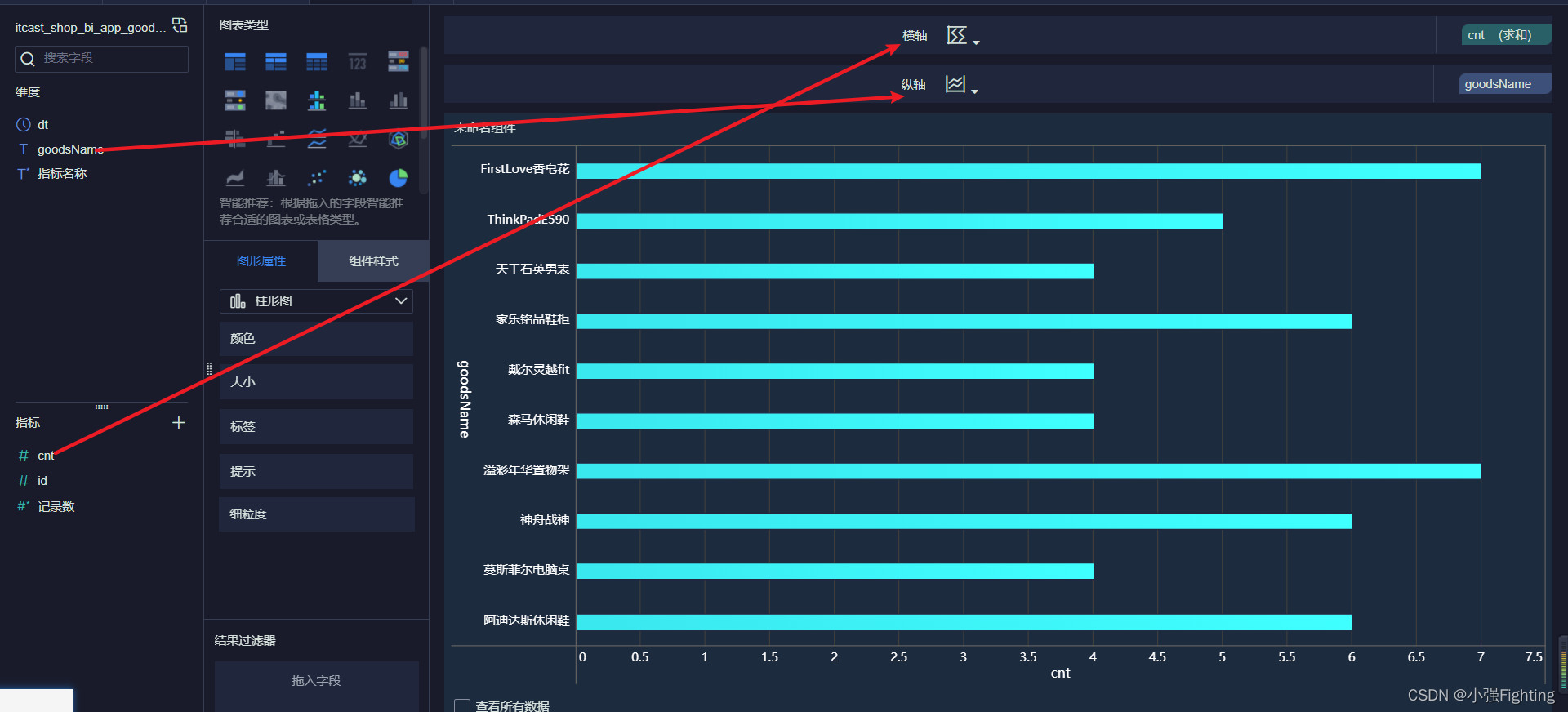
5.每小时商家商品个数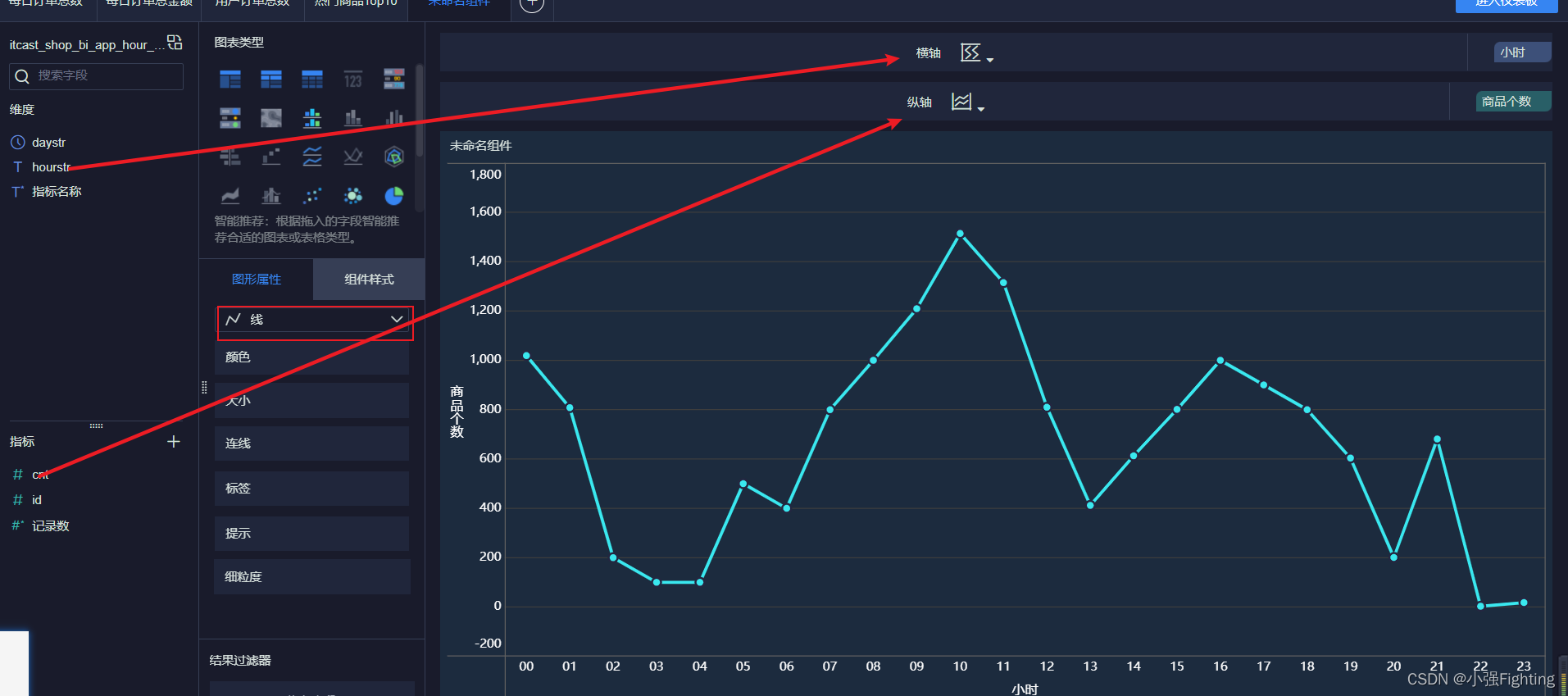
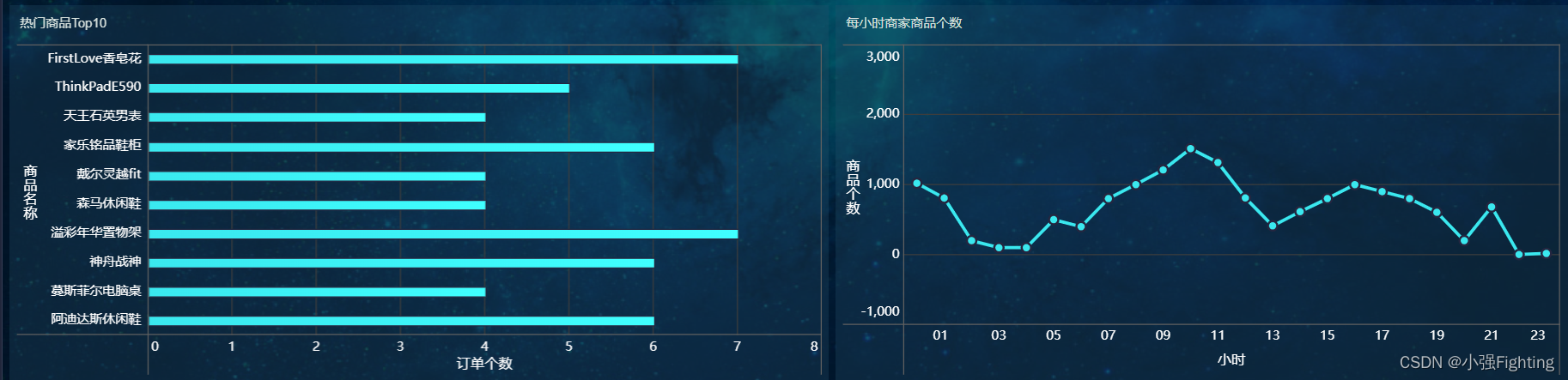
6.每小时订单笔数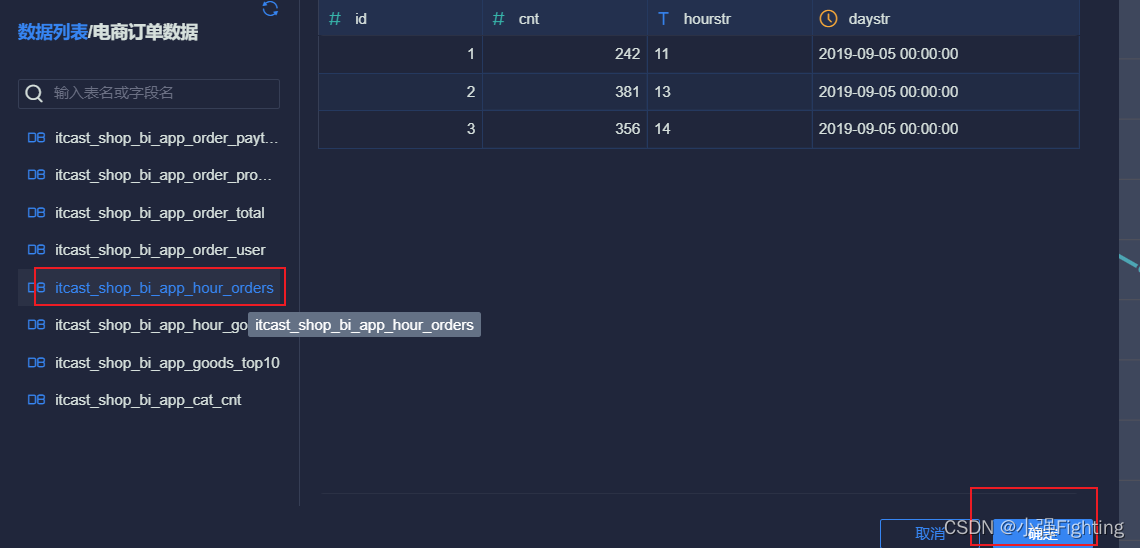
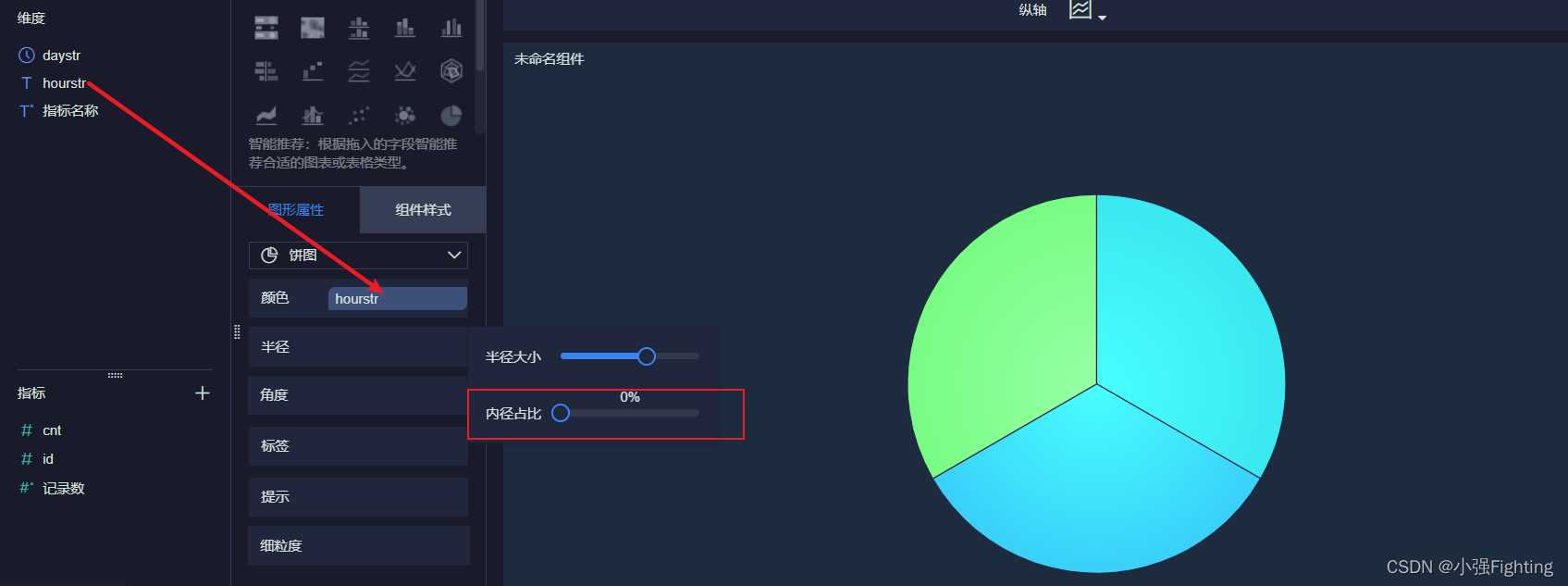
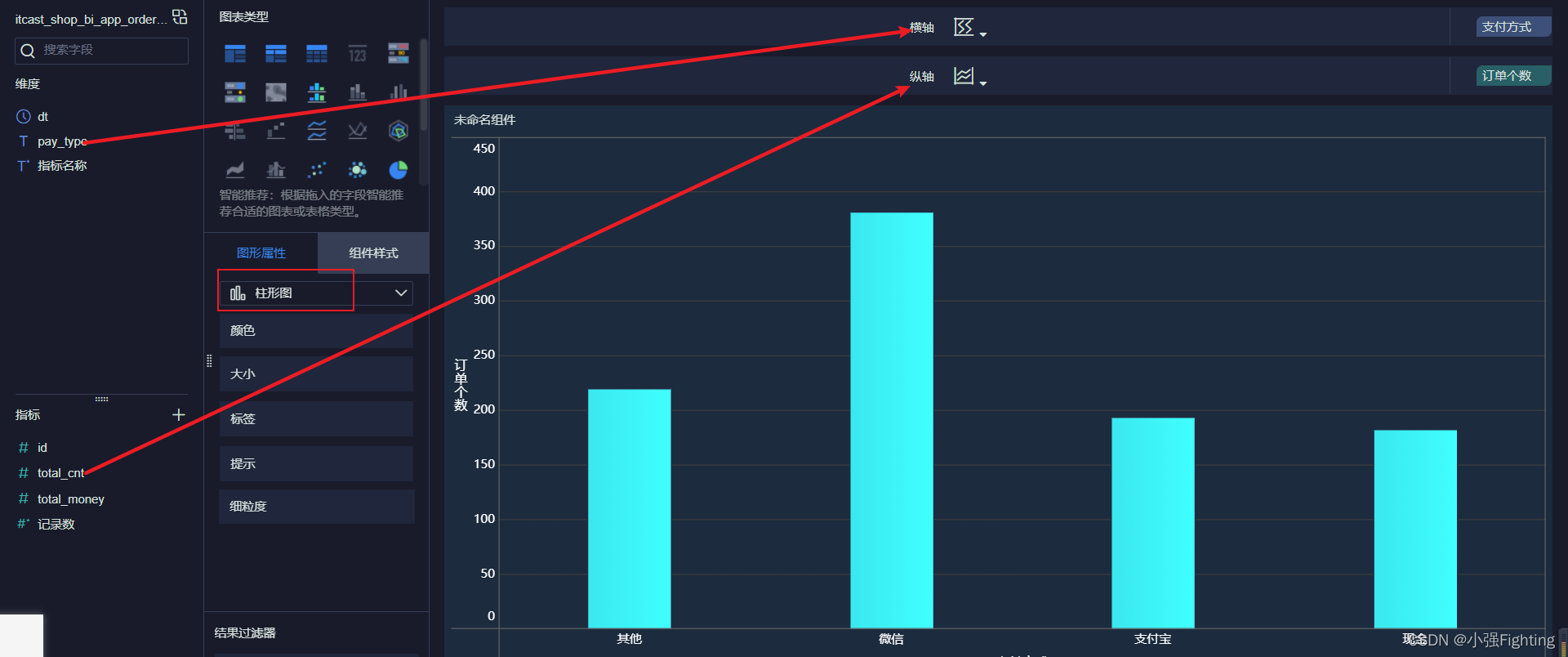
7.不同支付方式订单倾向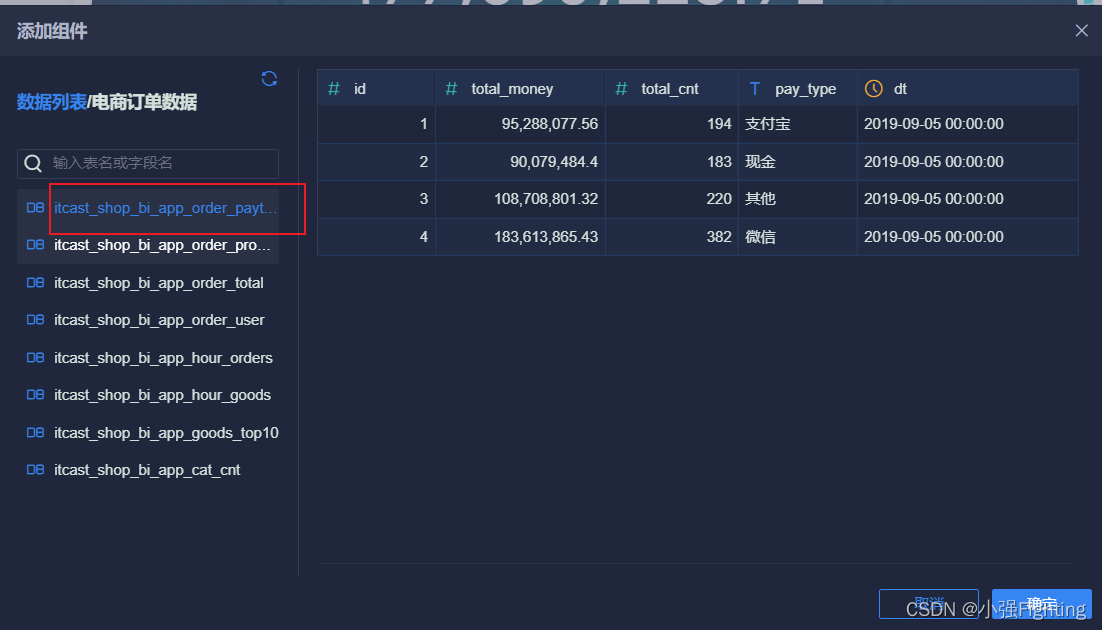
转换成雷达图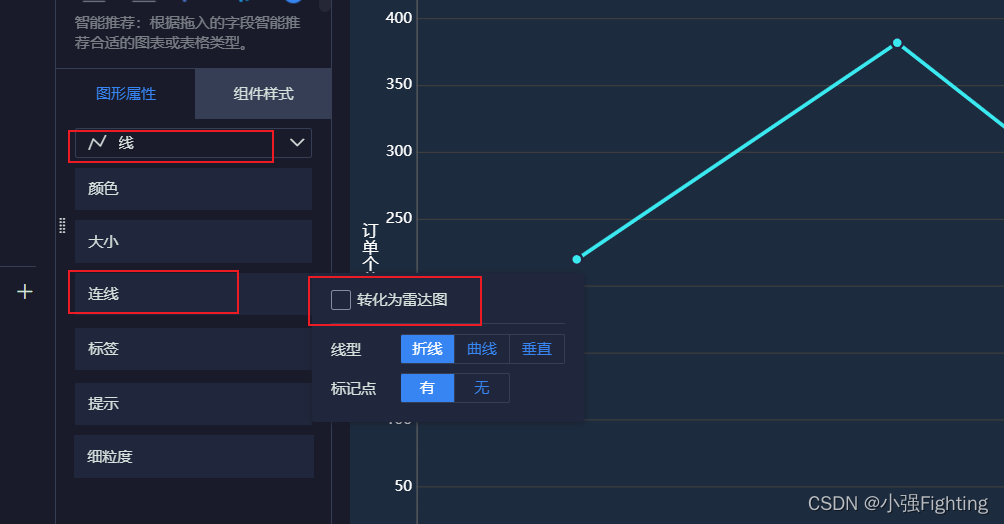
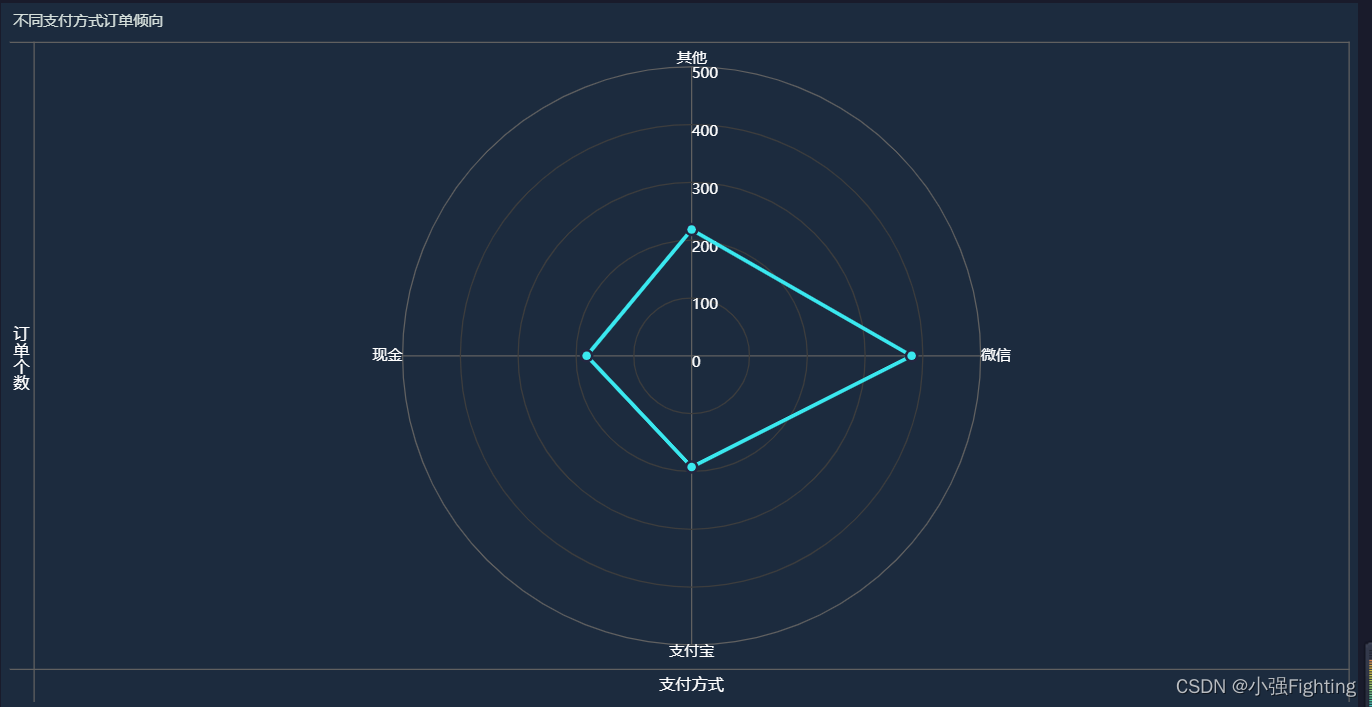
8.不同支付方式订单总额
9.各省份订单个数及订单总额
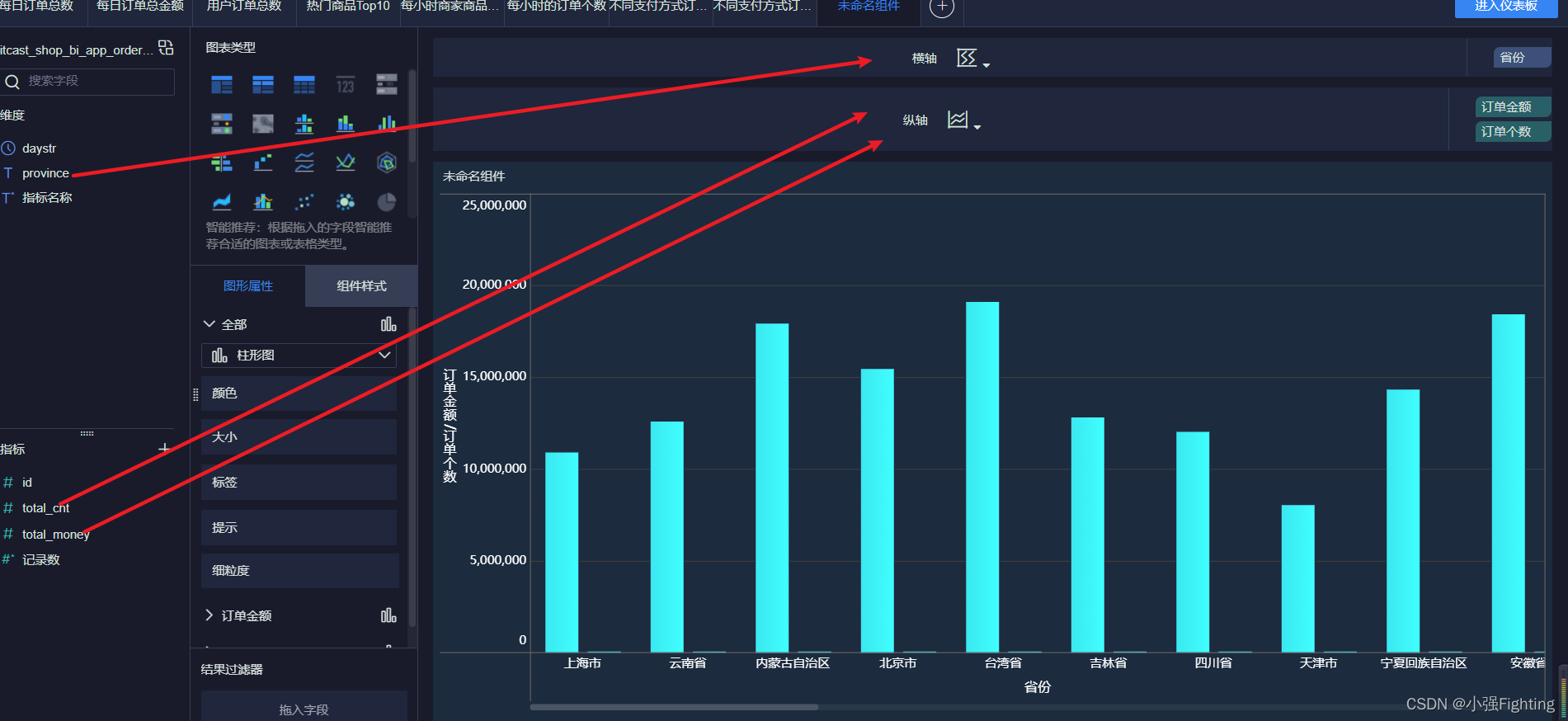
指标并列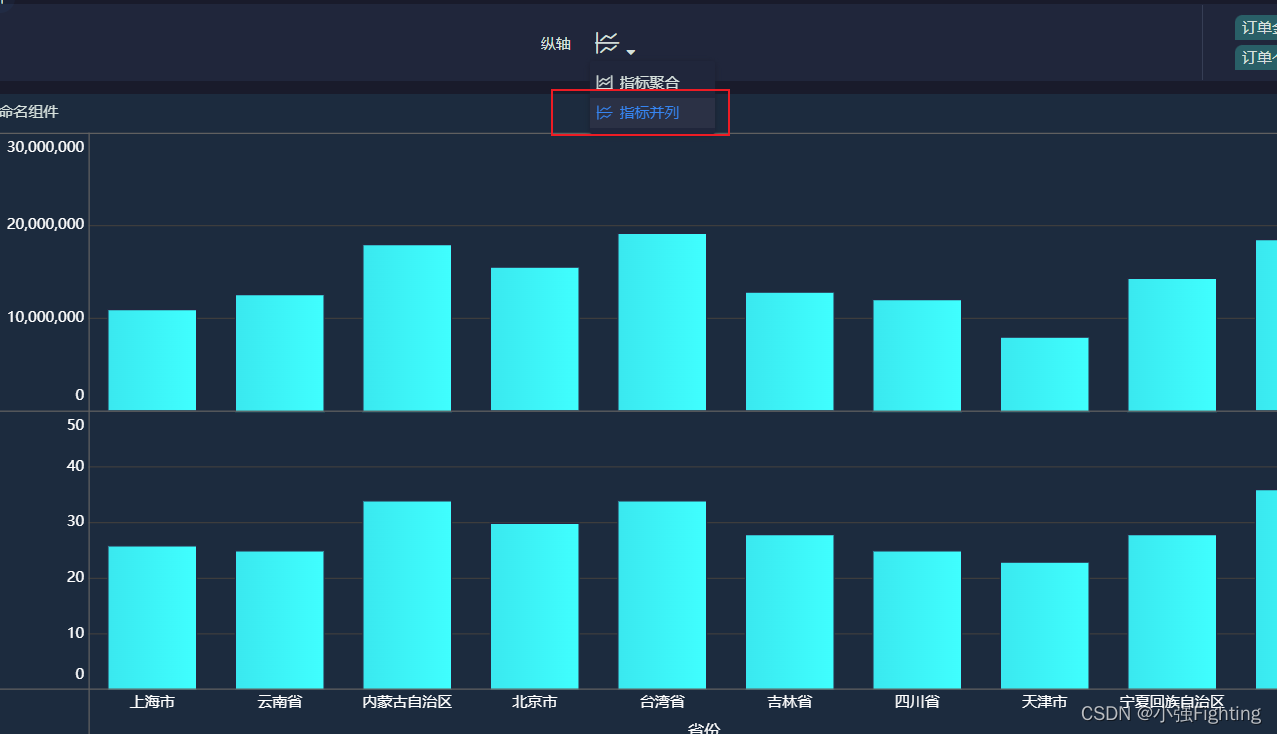
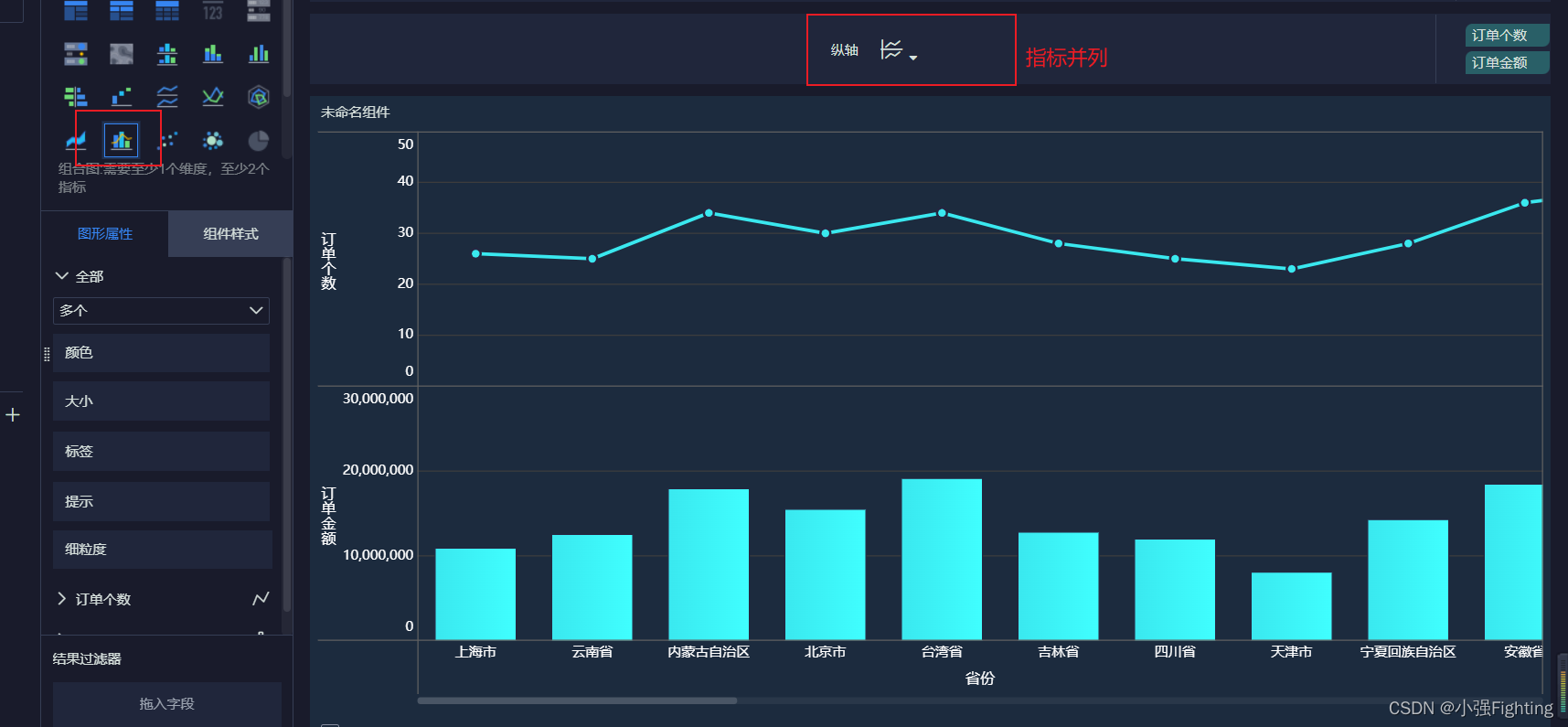
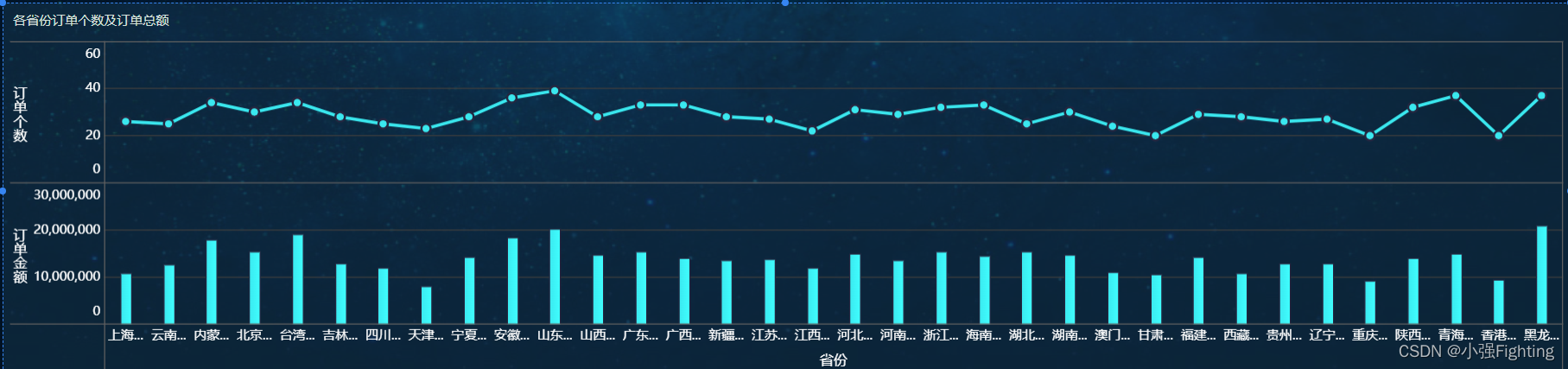
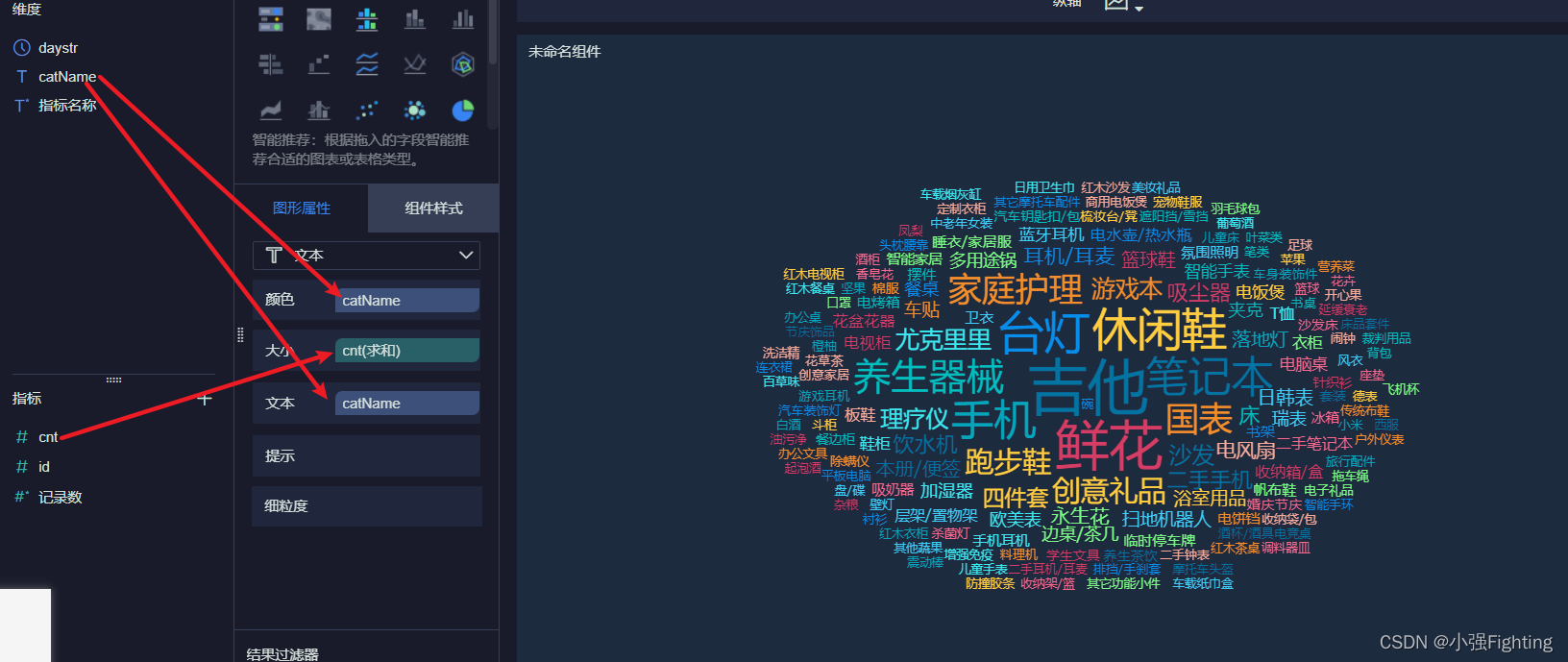
10.订单商品分类词云图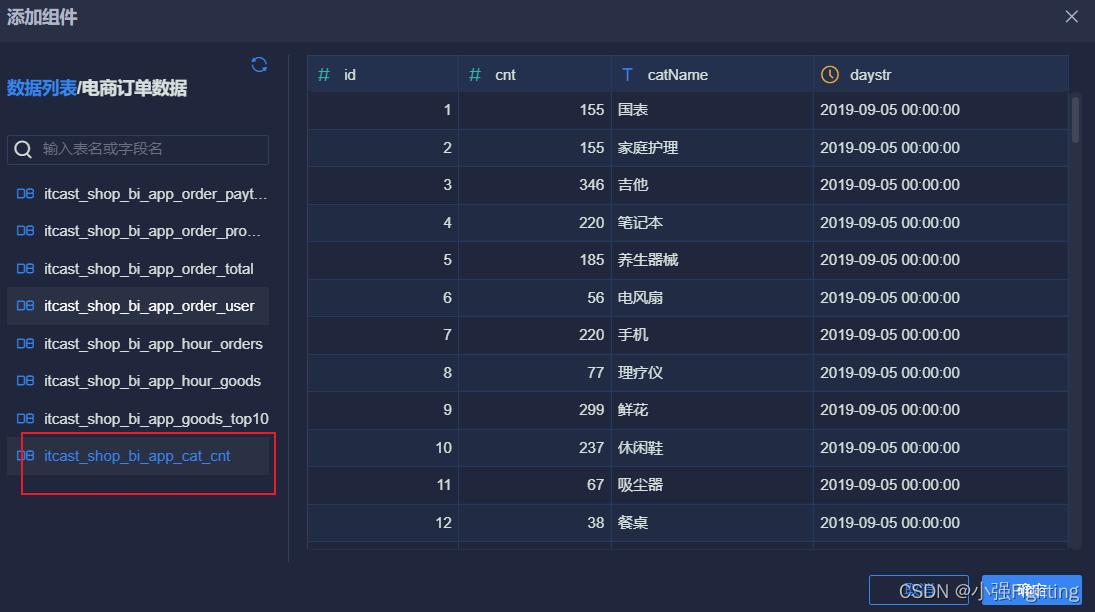


永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)