
项目实战-知行教育大数据分析平台-02
实战项目:知行教育大数据分析平台
目录
一、Sqoop的使用
1、介绍
sqoop属于apache旗下,最早是cloudera公司的,主要是用于数据的导入与导出工作,将关系型数据库(mysql,Oracle,...)的数据导入到hadoop生态圈(HDFS,HIVE,Hbase,...),将hadoop生态圈中的数据导出到关系型数据库中。
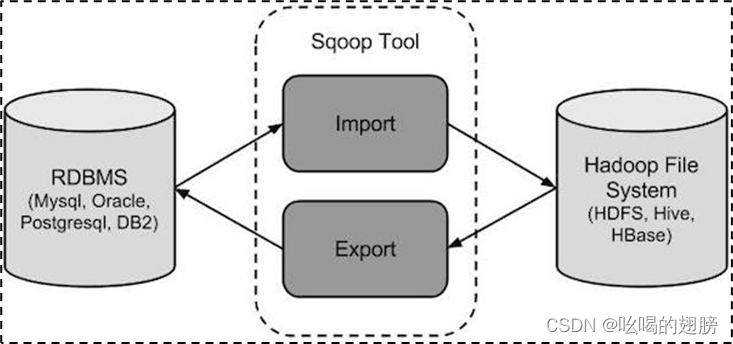
sqoop目前有两个版本:sqoop1,sqoop2,其中sqoop1较常用。sqoop1以Client客户端的形式存在和运行,即没有任务时是没有进程存在的。通俗上讲就是在运行时sqoop1自动启动,不运行无任务时自动关闭,不占用资源,不需要手动启动与停止某些服务。sqoop2是以B/S服务器方式运行的,即始终会有个server服务器进程在运行,无任务时同样会占据一定的资源。
sqoop的本质同样是将导入或导出命令转化为MapReduce程序来执行(只有map任务)。此外sqoop是将select查询出的数据进行导入和导出。
sqoop version : 查看已安装的sqoop版本
2、mysql->hive的两种方式
通过sqoop将关系型数据库的数据导入到hive中主要有两种方式:sqoop原生API和Hcatalog API,这两种方式作用一样但有一些不同之处:
A、数据格式支持:
原生API仅支持textfile格式,即只能将关系型数据库中的数据以textfile格式导入
Hcatalog API支持多种hive存储格式包括:textfile,ORC,sequencefile,parquet.....
B、数据覆盖:
原生API支持数据覆盖,追加操作
Hcatalog API不支持数据覆盖,每一次都是追加操作
C、字段名:
原生API:关系型数据库和hive中表的字段名比较随意,更多关注字段的顺序,会将关系型数据库的第一个字段给hive表的第一个字段......,至于双方的字段名可以不同。
Hcatalog API:按照字段名进行导入操作,不关心顺序
建议:在导入时,保证顺序和字段名都一致。
原生API:

Hcatalog API

针对不同字段名,想要使用HCatalog方式将数据插入,可以使用下面的方式:将select查询出的结果起别名,使之与hive表字段名一致。

本项目使用Hcatalog方式,因为我们在hive中所建的表都是orc格式。
3、sqoop基本操作
sqoop help : 查看帮助文档
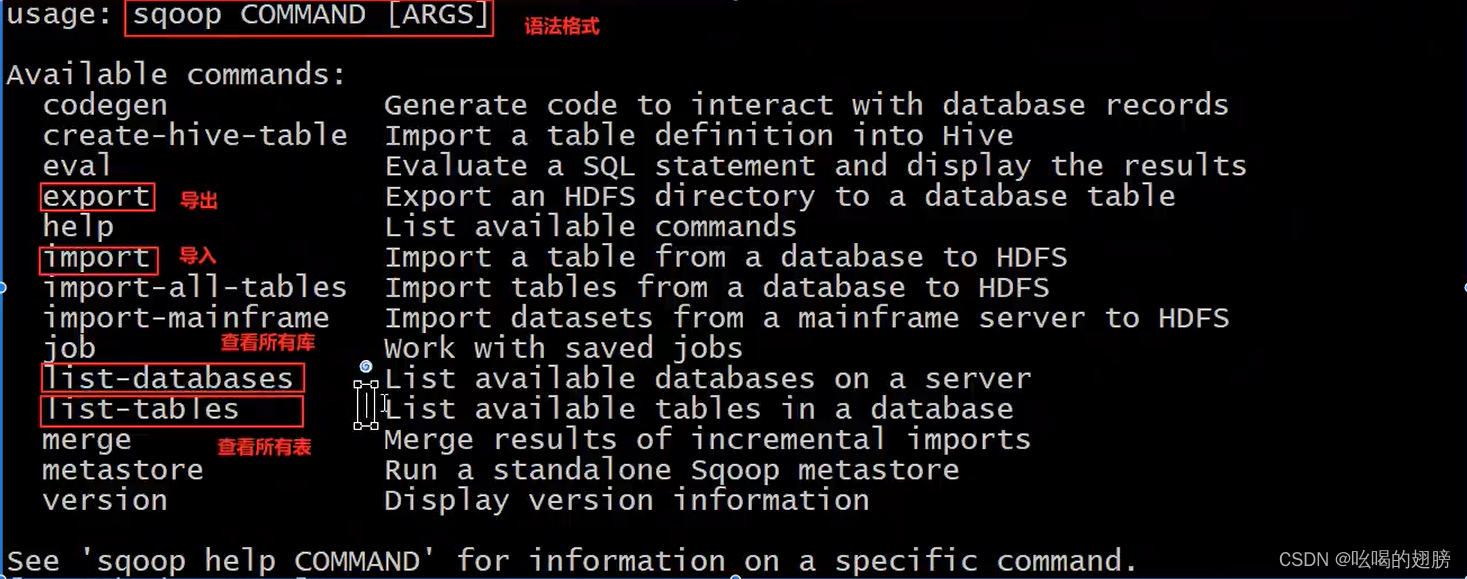
查看mysql中的数据库:
1)sqoop list-databases 显然单独这个命令是不行的,列出数据库,列出哪个数据库并没有指明,缺少一些东西,但到这里不会写了。
2)sqoop list-databases --help : 查看某一个命令的帮助文档
3)sqoop list-databases --connect jdbc:mysql://hadoop01:3306 --username root --password 123456
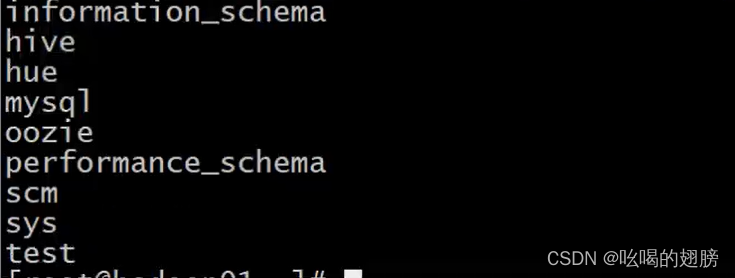
这里的hive,hue,oozie,scm分别用于存储hive,hue,oozie,cm组件的元数据

查看hue数据库中的所有表:
1)sqoop list-tables --help
2)sqoop list-tables --connect jdbc:mysql://hadoop01:3306/hue --username root --password 123456
可以换行书写命令:

4、sqoop的数据导入操作
数据准备:
create database test default character set utf8mb4 collate utf8mb4_unicode_ci;
use test;
create table emp
(
id int not null
primary key,
name varchar(32) null,
deg varchar(32) null,
salary int null,
dept varchar(32) null
);
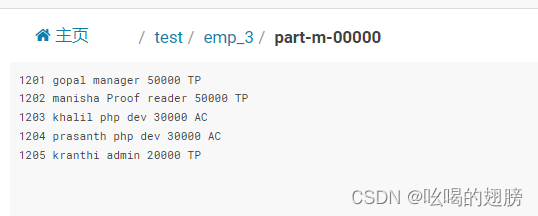
INSERT INTO emp (id, name, deg, salary, dept) VALUES (1201, 'gopal', 'manager', 50000, 'TP');
INSERT INTO emp (id, name, deg, salary, dept) VALUES (1202, 'manisha', 'Proof reader', 50000, 'TP');
INSERT INTO emp (id, name, deg, salary, dept) VALUES (1203, 'khalil', 'php dev', 30000, 'AC');
INSERT INTO emp (id, name, deg, salary, dept) VALUES (1204, 'prasanth', 'php dev', 30000, 'AC');
INSERT INTO emp (id, name, deg, salary, dept) VALUES (1205, 'kranthi', 'admin', 20000, 'TP');
create table emp_add
(
id int not null
primary key,
hno varchar(32) null,
street varchar(32) null,
city varchar(32) null
);
INSERT INTO emp_add (id, hno, street, city) VALUES (1201, '288A', 'vgiri', 'jublee');
INSERT INTO emp_add (id, hno, street, city) VALUES (1202, '108I', 'aoc', 'sec-bad');
INSERT INTO emp_add (id, hno, street, city) VALUES (1203, '144Z', 'pgutta', 'hyd');
INSERT INTO emp_add (id, hno, street, city) VALUES (1204, '78B', 'old city', 'sec-bad');
INSERT INTO emp_add (id, hno, street, city) VALUES (1205, '720X', 'hitec', 'sec-bad');
create table emp_conn
(
id int not null
primary key,
phno varchar(32) null,
email varchar(32) null
);
INSERT INTO emp_conn (id, phno, email) VALUES (1201, '2356742', 'gopal@tp.com');
INSERT INTO emp_conn (id, phno, email) VALUES (1202, '1661663', 'manisha@tp.com');
INSERT INTO emp_conn (id, phno, email) VALUES (1203, '8887776', 'khalil@ac.com');
INSERT INTO emp_conn (id, phno, email) VALUES (1204, '9988774', 'prasanth@ac.com');
INSERT INTO emp_conn (id, phno, email) VALUES (1205, '1231231', 'kranthi@tp.com');(1)将mysql中的数据导入到HDFS(全量导入),以emp表为例
sqoop import --help
# 不指定目标位置默认导入至操作用户的hdfs家目录下:hdfs的家目录为/user/用户名。在此目录下会创建一个以导入表的表名为名称的文件夹,在此文件夹下默认每一条数据运行一个map任务产生一个数据文件(数据量少的情况,如果数据量大就不是一个数据运行一个map任务了,具体由cpu个数即yarn决定),数据的默认分隔符为“,”。
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp
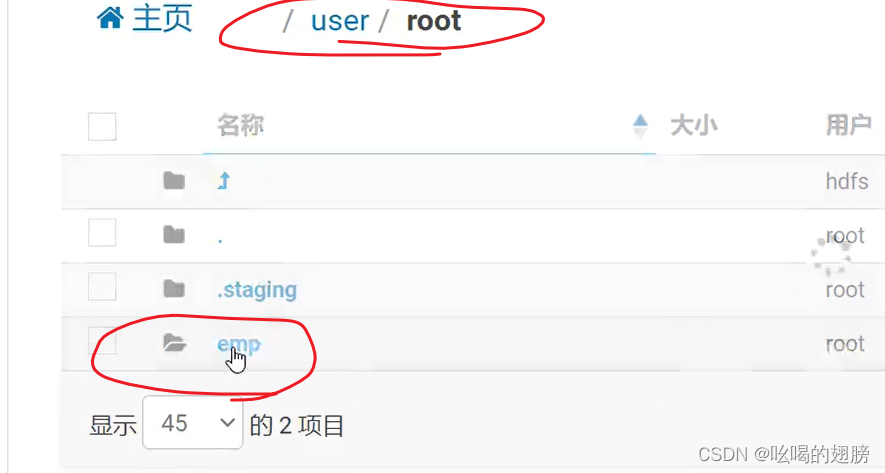
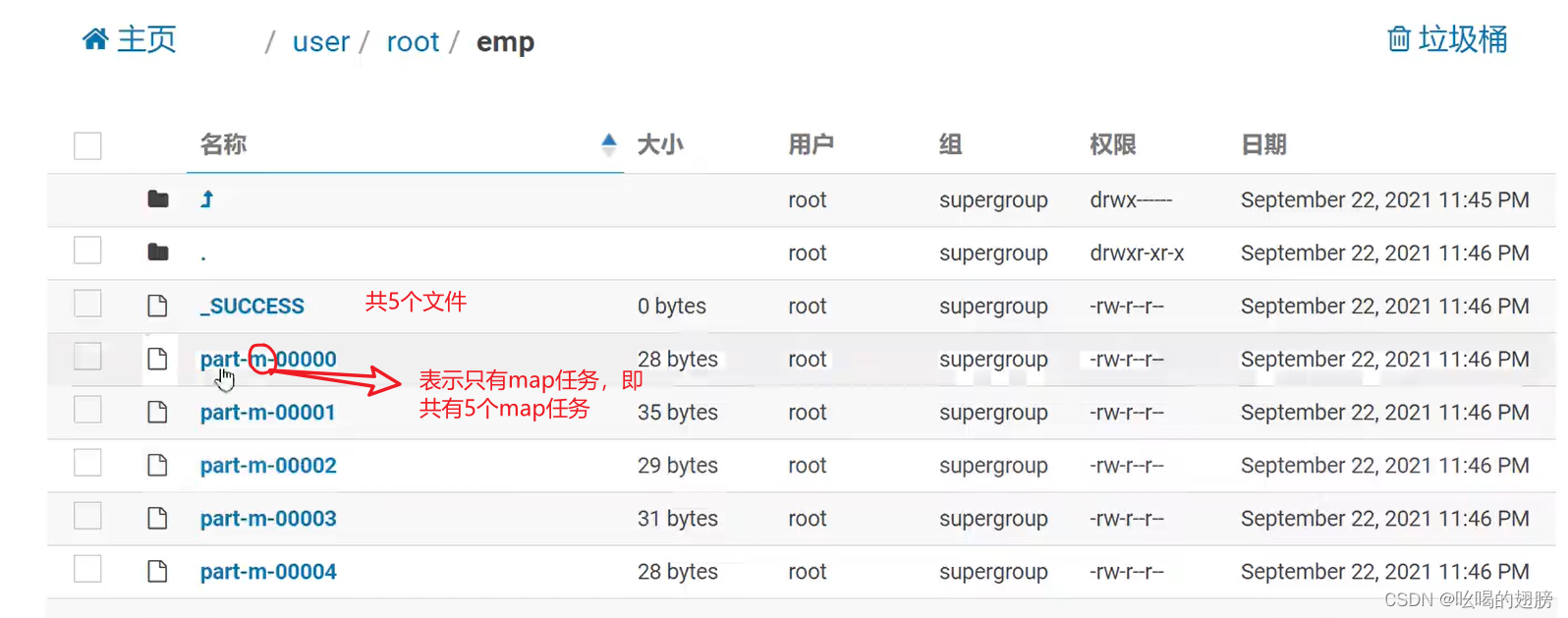
打开YARN,可以看到有5个map任务没有reduce任务。

# 指定目标位置
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp \
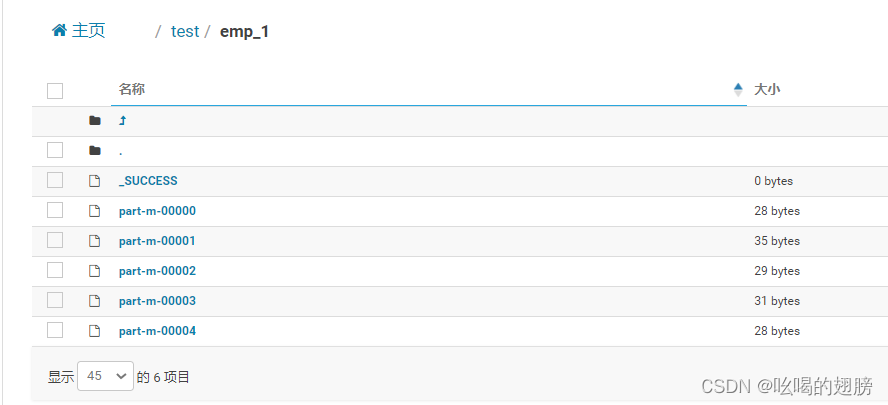
--delete-target-dir \
--target-dir /test/emp_1 # 不存在可以自动创建,不会在该目录下创建emp文件夹了,直接导入数据
# 指定map数量
-m 1 # 设置只用1个map任务执行,不需要划分
-m 2 # 需要在指定一个参数指定在哪个位置划分
--split-by <字段名> # 按指定字段平均划分
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp \
--delete-target-dir \
--target-dir /test/emp_2 \
-m 2 \
--split-by id

# 指定分隔符
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp \
--delete-target-dir \
--target-dir /test/emp_3 \
-m 1 \
--input-fields-terminated-by '\001' \ # 识别mysql中表的分隔符为\001,我们mysql中的表的分隔符是\001所以可以正确识别
--fields-terminated-by '\001' # 指定输出的分隔符,默认逗号
(2)将mysql中的数据全量导入到Hive中,以emp_add表为例
首先在导入之前必须在Hive中创建一个目标表:(注意一般情况下,都需要手动在hive中创表,然后在导入,但是sqoop支持自动创表,需要添加一些参数,实际应用过程中使用较少)
create database sqoop_hive_test;
use sqoop_hive_test;
create table emp_add_hive
(
id int,
hno string,
street string,
city string
)
row format delimited fields terminated by '\t'
stored as orc ;然后就可以使用sqoop完成数据导入操作了
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp_add \
--fields-terminated-by '\t' \
--hcatalog-database sqoop_hive_test \
--hcatalog-table emp_add_hive \
在hive中可以查到数据了select * from emp_add_hive;
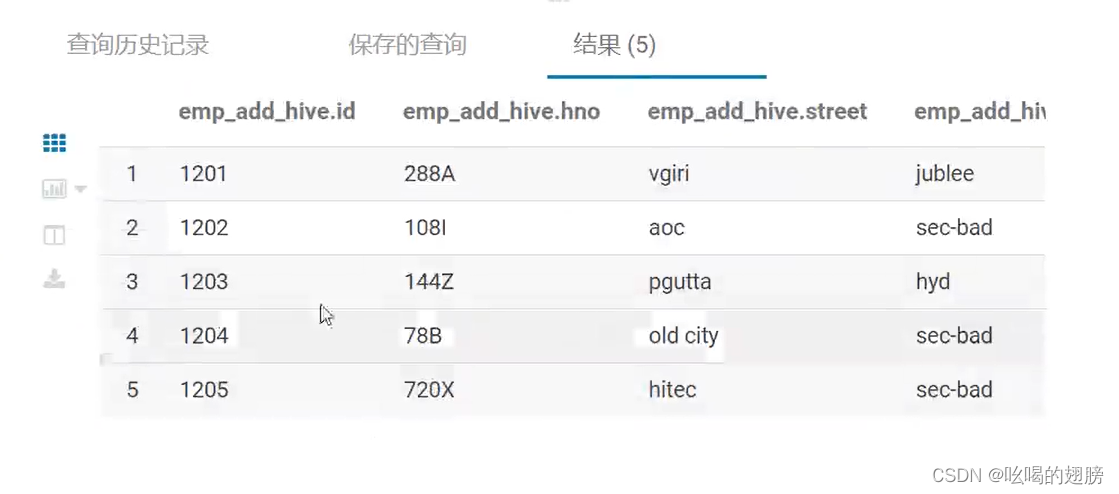
hive中的数据库,表实质都是在hdfs上,默认位置为/user/hvie/warehouse/:
(3)将mysql的数据条件(增量)导入到hdfs,以emp为例(上文已经对emp表的数据导入了,现在在mysql的emp表中新增一些数据,将新增的数据导入到hdfs)
mysql-emp表新增数据:
1206 zhangsan php dev 30000 AC
1207 lisi php dev 40000 AC
方式一:通过where方式
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp \
--where 'id > 1205' \
--delete-target-dir \
--target-dir /test/emp_2 \
-m 2 \
--split-by id
# 想要实现增量导入需要加入分区
方式二:通过sql方式
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
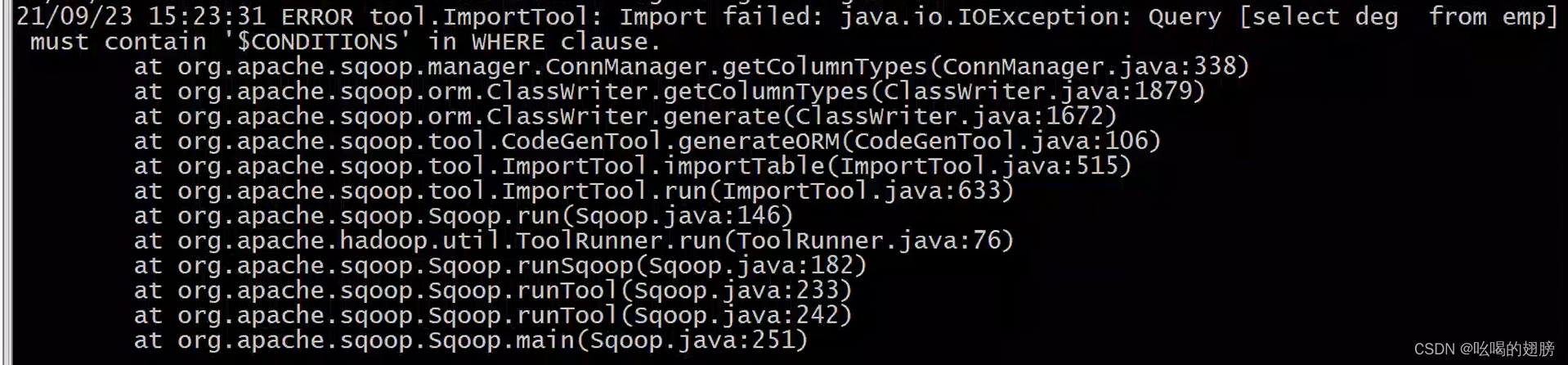
--query 'select deg from emp where $CONDITIONS' \ # sql后面不能加分号
# 这里就很灵活了"select * from emp where id > 1205 and \$CONDITIONS"
--delete-target-dir \ # 去掉即可实现追加,增量导入
--target-dir /test/emp_4 \
-m 2 \
--split-by id
注意在--query参数中必须加where $CONDITIONS 或 and $CONDITIONS语法,为了便于理解一般使用where 1=1 AND $CONDITIONS,这是sqoop的语法要求。此外如果sql语句是双引号包裹$CONDITIONS前面需要加\转义,单引号不需要。不加where $CONDITIONS会报错:
(4)将mysql中的数据条件(增量)导入到hive中,以emp_add表为例
mysql-emp_add表新增数据:
1206 111 aaa bbb
1207 222 ccc ddd
方式一:通过where方式
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp_add \
--where 'id > 1205' \ # 必须加单引号
--fields-terminated-by '\t' \
--hcatalog-database sqoop_hive_test \
--hcatalog-table emp_add_hive \
-m 1
方式二:通过sql方式
sqoop import \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--query "select * from emp_add where id > 1205 and \$CONDITIONS" \
--fields-terminated-by '\t' \
--hcatalog-database sqoop_hive_test \
--hcatalog-table emp_add_hive \
-m 1
5、sqoop的数据导出操作
将hive中的emp_add_hive表数据导出到mysql中
首先在MySQL中创建目标表(必须手动创建,sqoop无法自动创建)
create table test.emp_add_mysql(
id int ,
hno varchar(32),
street varchar(32),
city varchar(32)
);然后使用sqoop导出数据
sqoop export \
--connect jdbc:mysql://hadoop01:3306/test \
--username root \
--password 123456 \
--table emp_add_mysql \
--hcatalog-database sqoop_hive_test \
--hcatalog-table emp_add_hive \
-m 1
存在的问题:如果hive中表数据存在中文,通过上述sqoop命令,会出现中文乱码的问题。
解决方法:
sqoop export \
--connect jdbc:mysql://hadoop01:3306/test?useUnicode=true&characterEncoding=utf-8 \
--username root \
--password 123456 \
--table emp_add_mysql \
--hcatalog-database sqoop_hive_test \
--hcatalog-table emp_add_hive \
-m 1
注意在抽取过程中可能会出现数据倾斜问题:Sqoop导数据时的数据倾和斜解决办法_sqoop数据倾斜_ice_047的博客-CSDN博客
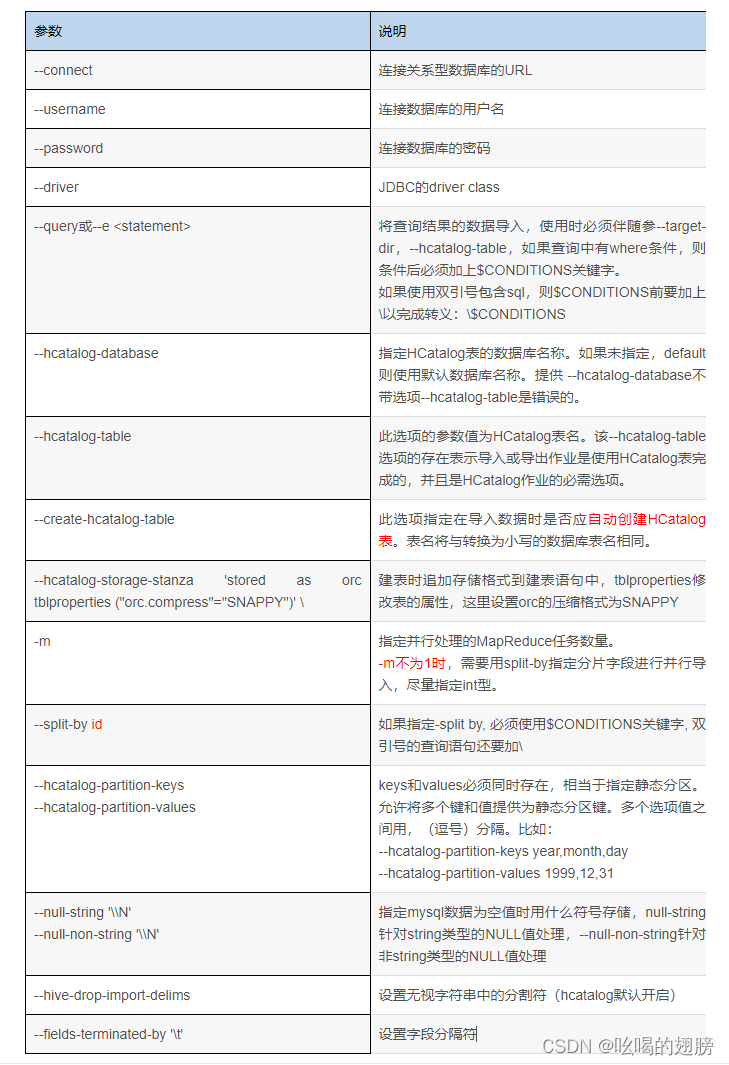
6、sqoop的相关常见参数
二、访问咨询主题看板
1、需求分析
需求分为调研需求和开发需求,一般调研需求由产品经理或其他人员提供,我们的任务是将调研需求转化为开发需求。最初始的需求就是调研需求,可能有上百个,我们真要一个一个的实现吗?显然太费劲了。经过认真分析,这些上百个需求本质上可以转化为几个(例如5个)主要需求,即这些需求实现了其他需求就都实现了,这就是调研需求转化开发需求的过程。又比如产品经理只给了我们一个需求,这个需求很宽泛,我们需要将其转化为具体的多个开发需求。
转化方法:首先将每一个需求所涉及的维度、指标、表、字段分析出来,然后在此基础之上,找到那些数据需要清洗,那些数据需要转换,如果有多个表,表与表之间的关联条件是什么。
需求一: (图片所示内容全部为产品经理给我们提供的调研需求)


注意:这里的sql语句只是方便我们理解该需求会用到那些表和那些字段,理解产品经理的意图,并不是让我们直接拿来复制粘贴的,如果这样还要我们做什么?
维度:时间维度(年,季度,月,天,小时)
指标:访问客户量
表:web_chat_ems_2019_12表以及其他月份的表(事实表)
字段:时间维度:create_time(显然该字段应该是有年,月,日,时,分,秒;为了后续分析方便create_time字段需要拆分为年yearinfo,季度quarterinfo,月monthinfo,天dayinfo,小时hourinfo5个字段(转换T))。当发现一个字段涵盖多个将要分析的维度数据时,可以尝试将其拆分出来。
指标字段:sid------说明:先去重在统计操作
需求二:

维度:时间维度:年,季度,月,天,小时
区域维度
指标:访问量
表:web_chat_ems_2019_12表以及其他月份的表(事实表)
字段:时间维度:create_time
转换操作:将create_time后期转换为yearinfo,quarterinfo,monthinfo,dayinfo,
hourinfo
区域维度:area(从sql可知区域知道了,具体的城市就知道了)
指标字段:sid 先去重在统计操作
需求三:

维度:时间维度:年,季度,月,天
地区维度:省,市就是区域维度
指标:咨询率具体来讲是
咨询量
访问量(在需求二中已经计算完成了,此处可以省略)
表:web_chat_ems_2019_12表以及其他月份的表
字段:时间维度:create_time
地区维度:area
指标字段:sid
区分咨询量字段:msg_count >=1
说明:当遇到指标需要计算比率问题时,一般的处理方案是只需要计算其分子分母的指标即可,在最后DWS层和DA层进行最后的统计计算。
需求四:

维度:时间维度:年,季度,月,天,小时
指标:访问量(在需求一已算,不需要关心)
咨询量
表:web_chat_ems_2019_12表以及其他月份的表
字段:时间维度:create_time
指标字段:sid
区分咨询量字段:msg_count >=1
需求五:

维度:时间维度:天,小时
指标:访问量(需求一已算)
需求六:
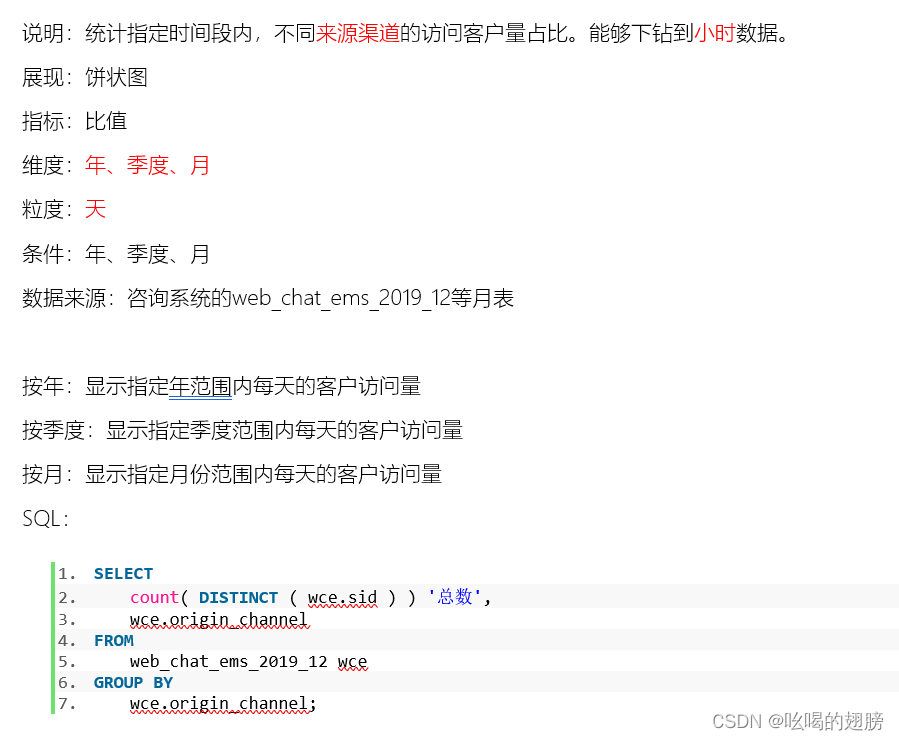
占比:
各个渠道访问量/总访问量
各个渠道下 咨询量/访问量(按这个来)
维度:时间维度:年,季度,月,天,小时
来源渠道维度
指标:访问量
咨询量
表:web_chat_ems_2019_12表以及其他月份的表
字段:时间维度:create_time
来源渠道维度:origin_channel
指标字段:sid
区分咨询量字段:msg_count >=1
需求七:

占比:
各个搜索来源访问量/总访问量(按这个来)
各个搜索来源下 咨询量/访问量
维度:时间维度:年,季度,月,天,小时
搜索来源维度
指标:总访问量(需求一已算)
各个搜索来源访问量
表:web_chat_ems_2019_12表以及其他月份的表
字段:时间维度:create_time
搜索来源维度:seo_source
指标字段:sid
需求八:

维度:时间维度:年,季度,月,天,小时
页面维度
指标:访问量
表:web_chat_text_ems_2019_11表(事实表)
字段:时间维度:?
页面维度:from_url
指标字段:count(1)
问题:时间维度字段缺失
解决方案:1)查看这个表是否有时间字段
2)如果没有,这个表是否与另一个表有关联
3)如果都解决不了,找需求方
需求汇总:
涉及维度:
固有维度:
时间维度:年,季度,月,天,小时
产品属性维度:
区域维度
来源渠道维度
搜索来源维度
页面维度
涉及指标:访问量
咨询量
涉及表:
事实表:web_chat_ems_2019_12表,web_chat_text_ems_2019_11表
维度表:没有(数仓建模不需要DIM层)
涉及字段:
时间维度:web_chat_ems:create_time
区域维度:web_chat_ems:area
来源渠道维度:web_chat_ems:origin_channel
搜索来源维度:web_chat_ems:seo_source
页面维度:web_chat_text_ems:from_url
指标字段:web_chat_ems:
访问量:sid
咨询量:sid
web_chat_text_ems:
访问量:count(1)
区分咨询量字段:web_chat_ems:msg_count >=1
需要清洗数据:没有
需要转换字段:时间字段
将create_time后期转换为yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo
查看表结构:见下文,web_chat_ems表是访问咨询数据表,web_chat_text_ems表是访问咨询数据表的附属表,这两张表是一对一的关系,该关系的表实质就是一张表(后续可以考虑将两张表集成在一起),因此web_chat_text_ems表的时间字段可以使用web_chat_ems:create_time。
2、业务数据准备
在mysql中创建数据库:
create database nev default character set utf8mb4 collate utf8mb4_unicode_ci;
在nev数据库中导入nev.sql并执行:会自动创建好对应的表并添加数据。执行过程中出现2006-MySQL server has gone away 错误 MySQL dump 10.13 Distrib 5.6.42,for Linux(x86_64)错误,是因为nev.sql文件太大,一次传输的数据量太大超过了max_allowed_packet阈值。解决方法:select @@max_allowed_packet;
set global max_allowed_packet = 10*1024*1024*1024;
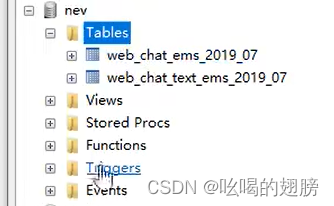
create table web_chat_ems_2019_07
(
id int auto_increment comment '主键' primary key,
create_date_time timestamp null comment '数据创建时间',
session_id varchar(48) default '' not null comment '会话系统sessionId',
sid varchar(48) collate utf8_bin default '' not null comment '访客id',
create_time datetime null comment '会话创建时间',
seo_source varchar(255) collate utf8_bin default '' null comment '搜索来源',
seo_keywords varchar(512) collate utf8_bin default '' null comment '关键字',
ip varchar(48) collate utf8_bin default '' null comment 'IP地址',
area varchar(255) collate utf8_bin default '' null comment '地域',
country varchar(16) collate utf8_bin default '' null comment '所在国家',
province varchar(16) collate utf8_bin default '' null comment '省',
city varchar(255) collate utf8_bin default '' null comment '城市',
origin_channel varchar(32) collate utf8_bin default '' null comment '来源渠道(广告)',
user varchar(255) collate utf8_bin default '' null comment '所属坐席',
manual_time datetime null comment '人工开始时间',
begin_time datetime null comment '坐席领取时间 ',
end_time datetime null comment '会话结束时间',
last_customer_msg_time_stamp datetime null comment '客户最后一条消息的时间',
last_agent_msg_time_stamp datetime null comment '坐席最后一下回复的时间',
reply_msg_count int(12) default 0 null comment '客服回复消息数',
msg_count int(12) default 0 null comment '客户发送消息数',
browser_name varchar(255) collate utf8_bin default '' null comment '浏览器名称',
os_info varchar(255) collate utf8_bin default '' null comment '系统名称'
);
create table web_chat_text_ems_2019_07
(
id int not null comment '主键' primary key,
referrer text collate utf8_bin null comment '上级来源页面',
from_url text collate utf8_bin null comment '会话来源页面',
landing_page_url text collate utf8_bin null comment '访客着陆页面',
url_title text collate utf8_bin null comment '咨询页面title',
platform_description text collate utf8_bin null comment '客户平台信息',
other_params text collate utf8_bin null comment '扩展字段中数据',
history text collate utf8_bin null comment '历史访问记录'
);
# 共10万条数据
# collate utf8_bin表示以二进制的形式存储输入的每个字符,因此会导致数据会区分大小写(collate有核对的意思)大小写敏感
我们使用一个月的数据为例分析,手动建立数仓,后续随着业务数据的增加,产生了新数据,针对新数据使用自动化调度oozie执行即可。
3、建模分析
探讨在hive中如何构建各层,及各层的表
ODS层:源数据层
作用:存储事实表和少量维度表
在ODS层建立与业务数据库完全一致的表(该层有两张表,表结构与web_chat_ems,web_chat_text_ems表一致),此外,在建表时需要构建为分区表,分区字段为时间字段,用于标记在何年何月何日将数据抽取到ODS层。创建分区的目的是方便后续增量抽取。
DIM层:维度层
作用:存储维度表
当前没有维度表数据,DIM层不需要
DWD层:明细层
作用:对ODS层数据进行ETL清洗,和少量维度退化
思考1:是否需要清洗?:不需要清洗,只需要提取有用数据即可
思考2:是否需要转换?:create_time
思考3:是否需要少量维度退化?:需要将事实表合并
将web_chat_ems中create_time字段转换为yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo;将两个事实表进行合并,合并时有三种方案:1)只合并后续需要用的字段;2)当无法确定需要用到哪些字段时,合并全部字段;3)如果表中字段本来就很少,则全部合并即可。
该层只有一张表,web_chat_ems表的字段较多因此只抽取用到的字段,web_chat_text_ems表字段较少全部抽取,因此建表字段为:sid,create_time,seo_source,area,origin_channel,msg_count,yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,referrer,from_url,landing_page_url,url_title,platform_description,other_params,history共18个字段。此外考虑到ip,session_id字段同样可以用于统计上述需求,因为它们与sid一样都可以区分访问的不同,因此我们在上述字段的基础上增加ip,session_id两字段,共20个字段。
DWM层:中间层
作用:对DIM层数据进行维度退化,和提前聚合形成周期快照事实表
思考1:是否需要进行维度退化?:没有DIM,不需要维度退化
思考2:是否需要进行提前聚合操作?:可以尝试按小时进行提前统计,以便后续上卷操作
思考3:当前主题是否可以按照小时进行提前聚合呢?
不可以,因为DWD层的数据存在重复问题(sid重复),不能提前聚合,一旦聚合后,会导致后续的统计出现不精确的问题。
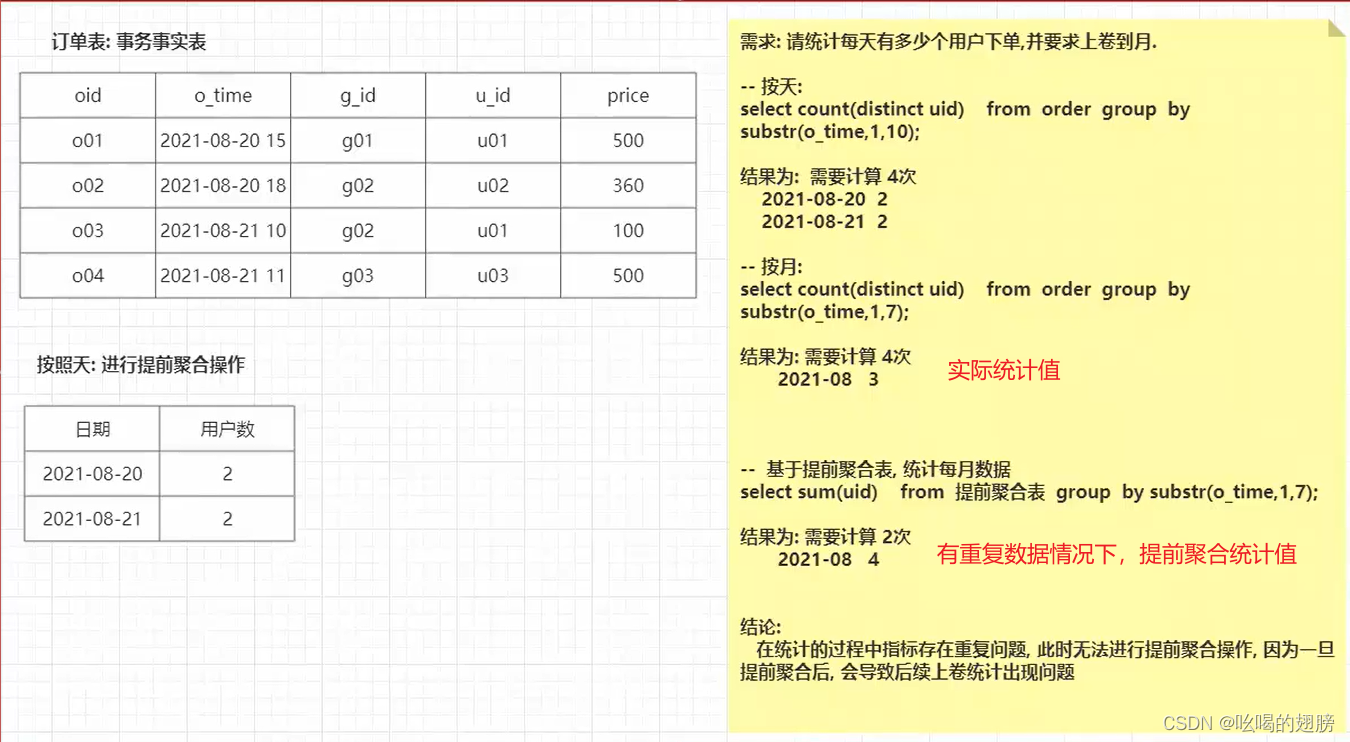
DWM层不需要
DWS层:业务层
作用:细化维度统计操作,存储统计结果
一般一个指标会对应一个统计结果表,本项目的指标有两个,因此该层有两张表:统计访问量的结果表与统计咨询量的结果表。
访问量结果表
统计访问量涉及的维度有:
固有维度:
时间维度:年,季度,月,天,小时
产品属性维度:
区域维度
来源渠道维度
搜索来源维度
页面维度
一共有多少个需求:25个需求(我们需要在一张表统计这25个需求)
年维度:统计每年的总访问量
统计每年各个区域的访问量
统计每年各个来源渠道的访问量
统计每年各个搜索来源的访问量
统计每年各个页面的访问量
......
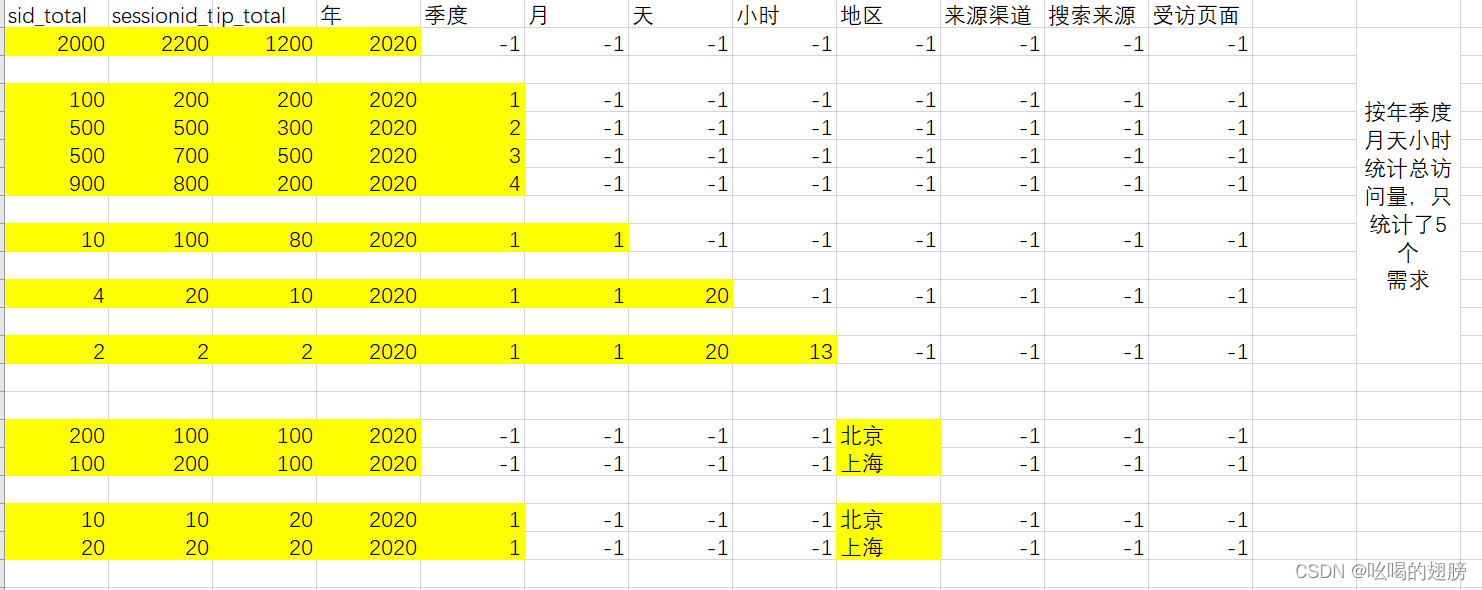
问题1:如何在上表的基础上获取按照年+季度统计各个地区的结果数据?
select * from 上表 where 年!=-1 and 季度!=-1 地区!=-1 and 月=-1 and 天=-1 and 小时=-1 and 来源渠道=-1 and 搜索来源=-1 and 受访页面=-1;
可以看到使用上表后后续获取数据是极其麻烦,因此在上表的基础上添加两个字段分别用于标记时间维度类型和产品属性维度类型。
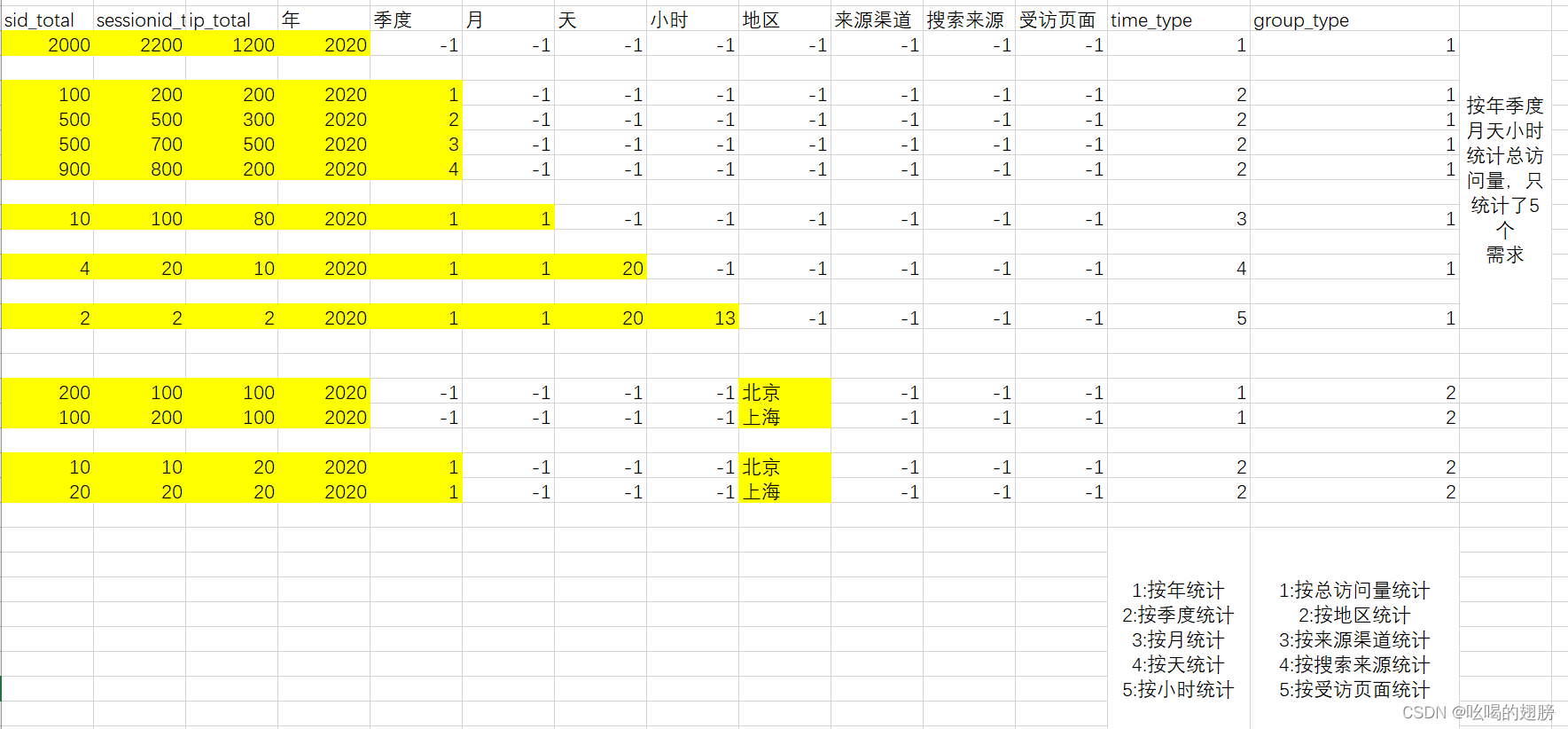
在该表的基础上获取按照年+季度统计各个地区的结果数据:(可以看到获取数据十分方便)
select * from 加入新字段的表 where time_type = 2 and group_type = 2;
问题2:该表的时间字段都是分散的看起来不方便
解决方法:添加time_str字段将时间合并起来,方便查看
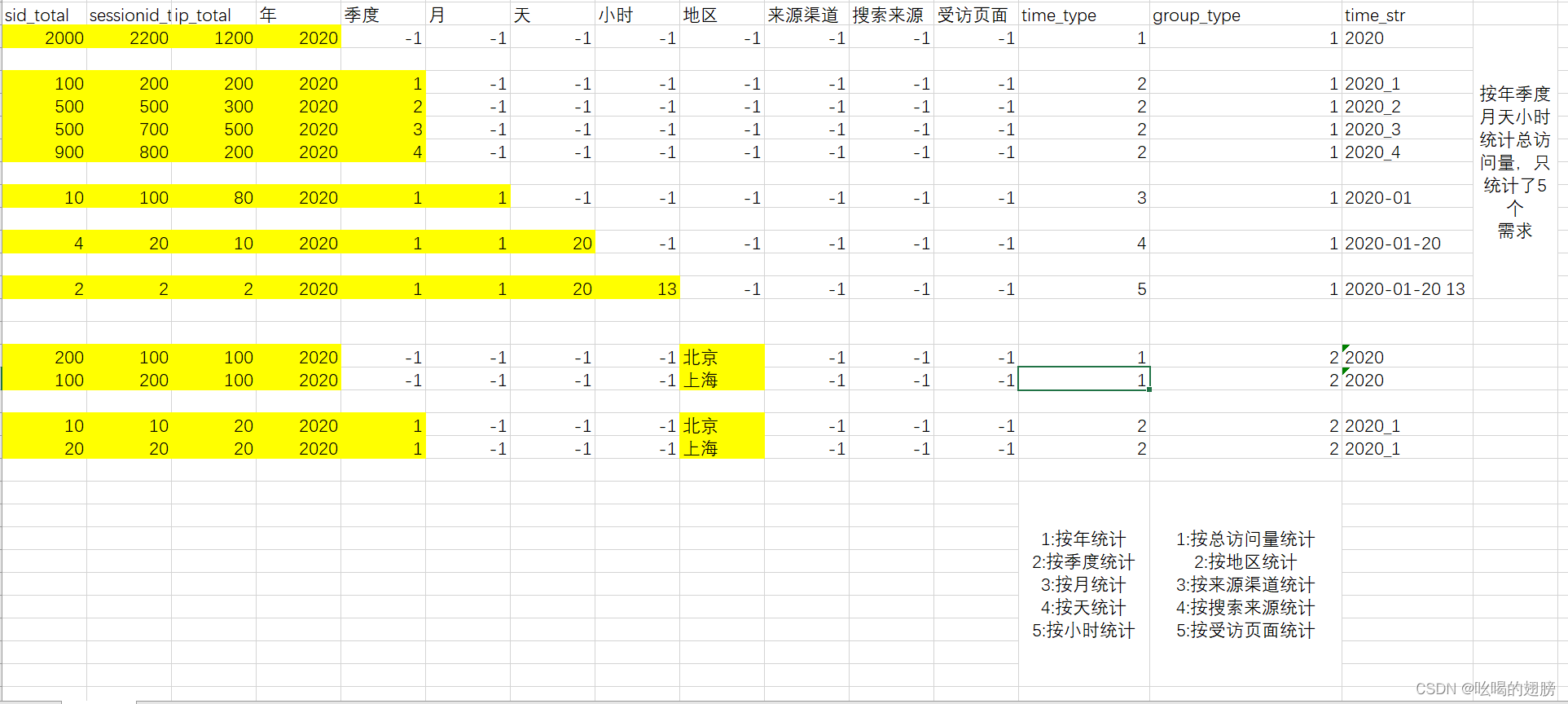
建表字段:指标统计字段+各个维度字段+经验字段
sid_total,sessionid_total,ip_total,yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,area,origin_channel,seo_source,from_url,time_type,group_type,time_str
咨询量结果表
统计咨询量涉及的维度有:
固有维度:
时间维度:年,季度,月,天,小时
产品属性维度:
区域维度
来源渠道维度
建表字段:
sid_total,sessionid_total,ip_total,yearinfo,quarterinfo,monthinfo,dayinfo,hourinfo,area,origin_channel,time_type,group_type,time_str
注意:不存在的维度字段的值,设置为-1(业务指定,表示没有这个维度)
DA层:
作用:对接应用,应用需要什么数据,从DWS层获取数据即可,此层目前不需要做任何处理,DWS层已经可以说得到分析结果了,后续具体用什么,直接取出来简单计算一下即可。
4、建模之前的细节讨论
思考:在创建表的时候,需要考虑那些问题呢?
1)所创建的表采用什么存储格式(orc,textfile...)
2)所创建的表采用什么压缩格式
3)所创建的表采用什么类型(内部表,外部表,分区表,分桶表)
(1)数据存储格式和压缩方案
存储格式选择:
情况一:如果数据不是来源于普通文本文件的数据,一般存储格式选择列式的ORC存储
情况二:如果数据来源于普通文本文件的数据,一般存储格式选择行式的textfile存储
本项目数据来源于mysql数据库,不是普通文本,选择ORC存储格式。使用ORC文件格式可以提高hive读、写和处理数据的能力,textfile格式性能较差。
压缩方案选择:
情况一:写多,读少情况,优先考虑压缩比,建议选择zlib,gz(会将数据压缩的很小)
情况二:写多,读多情况,优先考虑解压缩性能,建议选择snappy,lzo
一般情况下,hive中的ODS层选择zlib压缩方案;hive中其他层选择snappy压缩方案,如果空间比较充足,建议各层选择snappy压缩方案。
本项目OSD层:zlib;其他层:snappy
(2)全量和增量
在进行数据统计分析时,一般来说,第一次统计分析都是全量统计分析,而后续的操作都是在结果的基础上进行增量化统计操作。
全量统计:需要面对公司所有的数据进行统计分析,数据体量一般比较大,一个MR程序运行可能会消耗几天时间,运行过程中可能还会出现一些小错误,很麻烦。
解决方案:A、采用分批次执行(例如公司共有10年的数据,我们可以按年分批次统计,然后进行汇总即可)。B、扩充资源,在加100台服务器(通常情况下不可取,因为全量统计只做一次,后续增量统计一般面对的都是一天的数据,为了只做一次的全量统计扩充资源有点浪费)
增量统计:一般是以T+1模式统计,当前的数据在第二天才会进行统计操作,每天都是统计上一天的数据。
(3)hive的分区
一般情况下,在hive中构建的表都是分区表,因为使用分区表可以减少查询表数据的扫描量,从而提升效率。
hive分区根据插入数据时是否需要手动指定分区分为静态分区,动态分区和混合分区,静态分区在导入数据时需要手动指定分区,动态分区在导入数据时系统会动态判断目标分区,混合分区是静态分区和动态分区的结合。
1)静态分区
创建静态分区:
语法:
create [external] table <table_name> (
<col_name> <data_type> [comment] ...
)partitioned by (<partition col> <col_type>,...)
[stored as textfile|orc|csvfile]
[tblproperties ('<property name>'='<property value>',...)]
[row format <format_name>] # 设置表的行格式,即表在磁盘中的物理存储方式
[location <file_path>];
# 例子
create table test(
id int,
...
)partitioned by (year varchar(50))
row format delimited fields termnated by '\t';导入数据:
load data [local] inpath '<path>' [overwrite] into table <table_name> partition(分区字段=值,...);
insert [overwrite | into] table <table_name> partition(分区字段=值,...) select ...;
2)动态分区
创建动态分区和创建静态分区一样,对于大批量数据的插入分区表,动态分区相当方便。
create table test1(
id int,
...
)partitioned by (year varchar(50),month varchar(50),day varchar(50),hour varchar(50))
row format delimited fields terminated by '\t';导入数据:
insert [overwrite | into] table <table_name> partition(分区字段1,分区字段2...) select ...;
注意:导入之前必须先开启动态分区支持,和非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
# 这个属性默认值是strict,就是要求分区字段必须有一个是静态的分区值。全部动态分区插入,需要设置为nonstrict非严格模式。
保证select语句的最后字段与动态分区字段一致,且顺序也一致
insert into table test1 partition(year,month,day,hour)
select ...year,month,day,hour from xxx;
动态分区的优化:有序动态分区
问题:有的时候动态分区比较多,hive为了提升写入效率,会自动开启多个reduce程序并行执行,此时对内存消耗比较大,可能会出现内存溢出问题。
解决方案:开启有序动态分区,开启后,reduce只能有序的一个一个运行,大大降低了内存消耗,从而能够顺利完成,但是效率会降低。
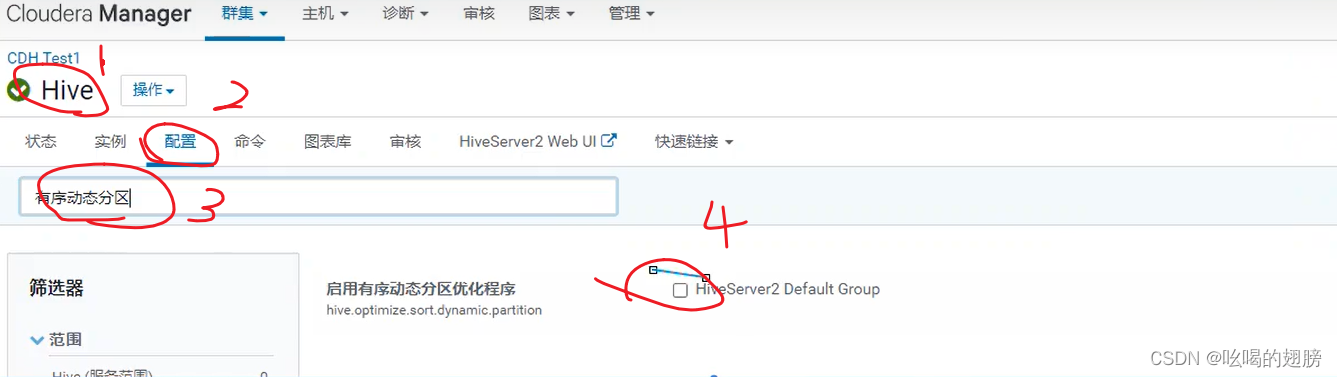
打开CM,进入hive的配置界面搜索“有序动态分区”将其勾选即可开启:(注意在CM中修改配置信息是一种全局的修改,相当于修改hive-site.xml配置文件)
3)混合分区
创建表的语法都一样,混合分区即导入数据时partition关键字中既有静态分区,也有动态分区。
导入数据:
insert [overwrite | into] table <table_name> partition(分区字段1=值,分区字段2,...) select ...;
注意:导入之前必须先开启动态分区支持,和非严格模式
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
动态分区键需要放在静态分区键的后面(因为hdfs上的动态分区目录下不能包含静态分区子目录),即partition关键字中先写静态分区字段,在写动态分区字段。
保证select语句的最后字段与动态分区字段一致,且顺序也一致
insert into table test1 partition(year=‘2020’,month=‘05’,day,hour)
select ...,day,hour from xxx;
如果partition(year, month, day=’05’, hour=’08’),则会报错:FAILED: SemanticException [Error 10094]: Line 1:50 Dynamic partition cannot be the parent of a static partition ''day''。
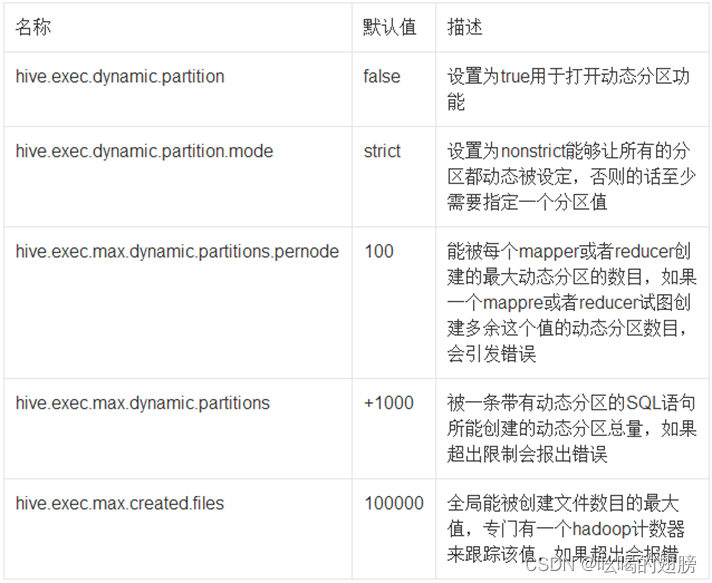
动态分区其他相关属性设置:
(4)内部表与外部表的选择
方式一:判断当前这份数据我们是否具有绝对的控制权(是:内部表,否:外部表)
方式二:后续是否需要对这份数据进行更改操作(是:内部表,否:外部表)

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)