
大数据bigdata Storm实战-股票可视化+阿里云rds,datav组件使用
大数据bigdata Storm实战-股票可视化+阿里云rds,datav组件使用
设计方案一
1.使用storm框架进行搭建,结构如下
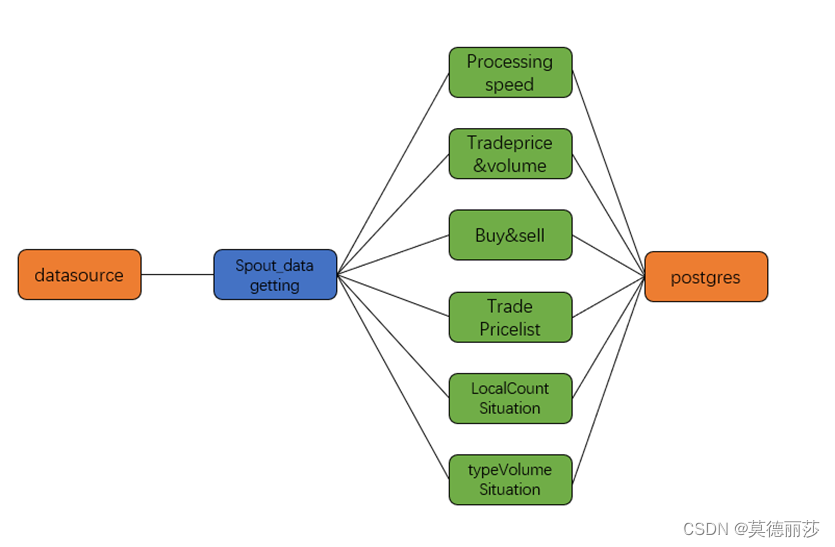
2.采用的调优方法
设计方案二
1.使用storm框架进行搭建,结构如下
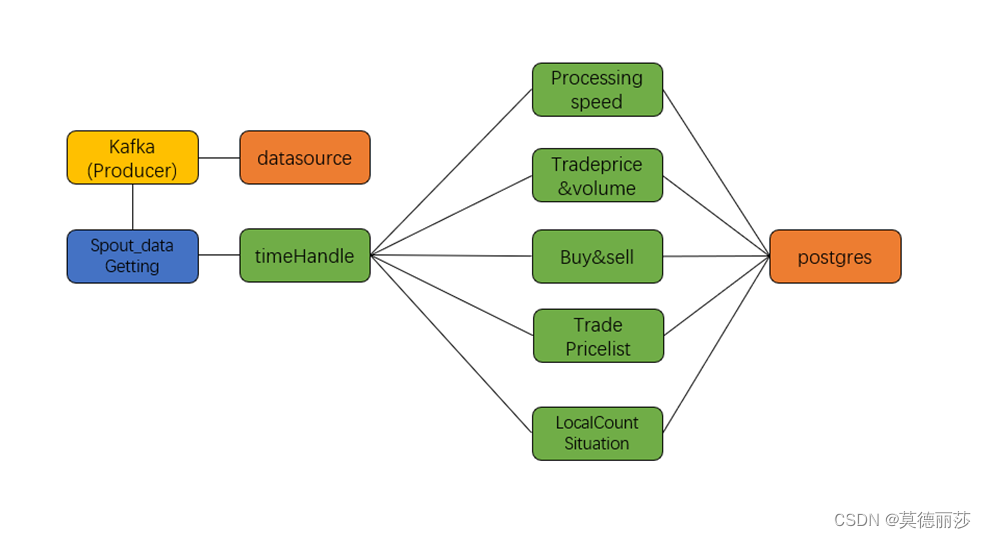
2.采用的调优方法
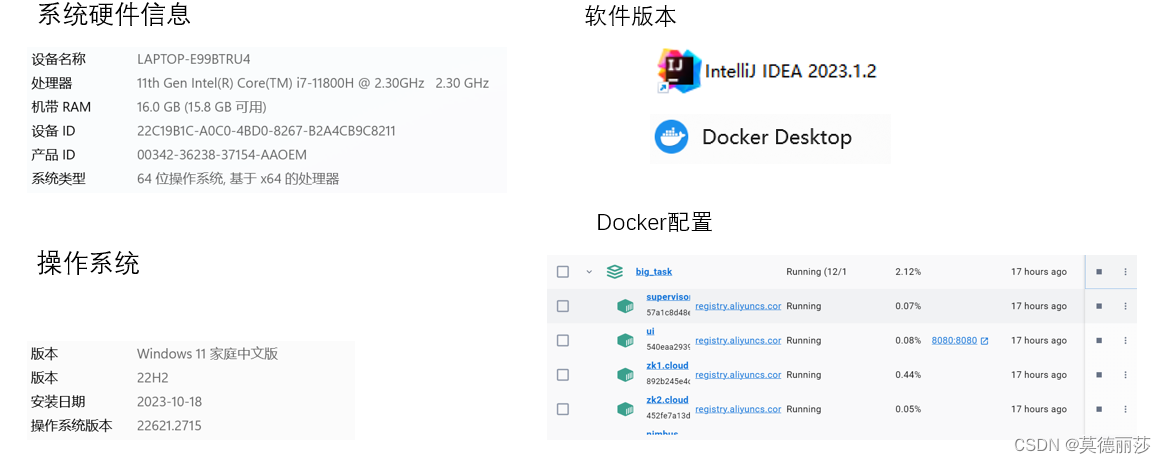
系统的环境说明
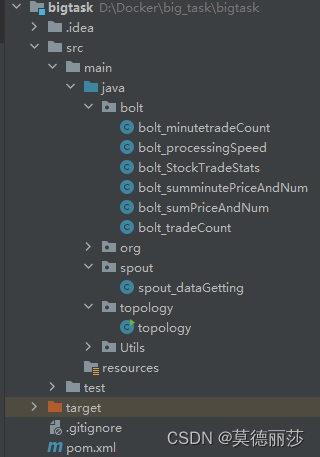
代码结构如下:
从csv文件中实时获取数据流,设置时间戳,更新数据库中的内容, 这里使用的数据库是阿里云的postgre数据库, 可以直接使用navicat进行连接
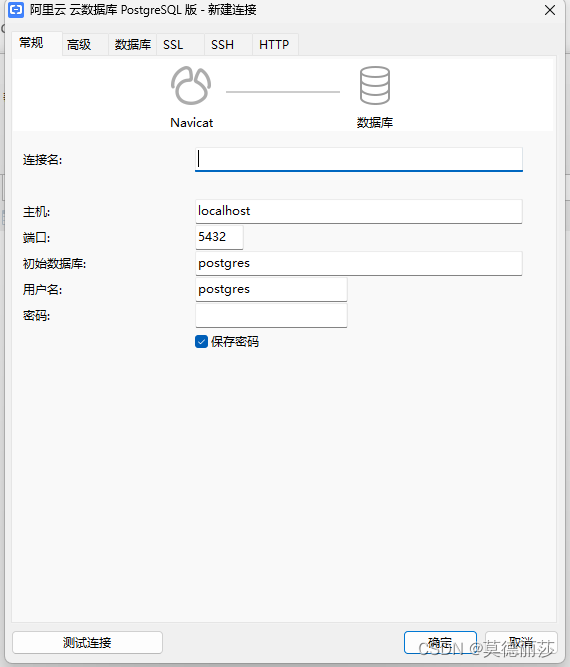
但是要先去阿里云官网申请一个rds
申请后 要等待一段时间, 等收到短信之后就可以看见实例创建成功了
点击进去可以查看到实例id和资源组id
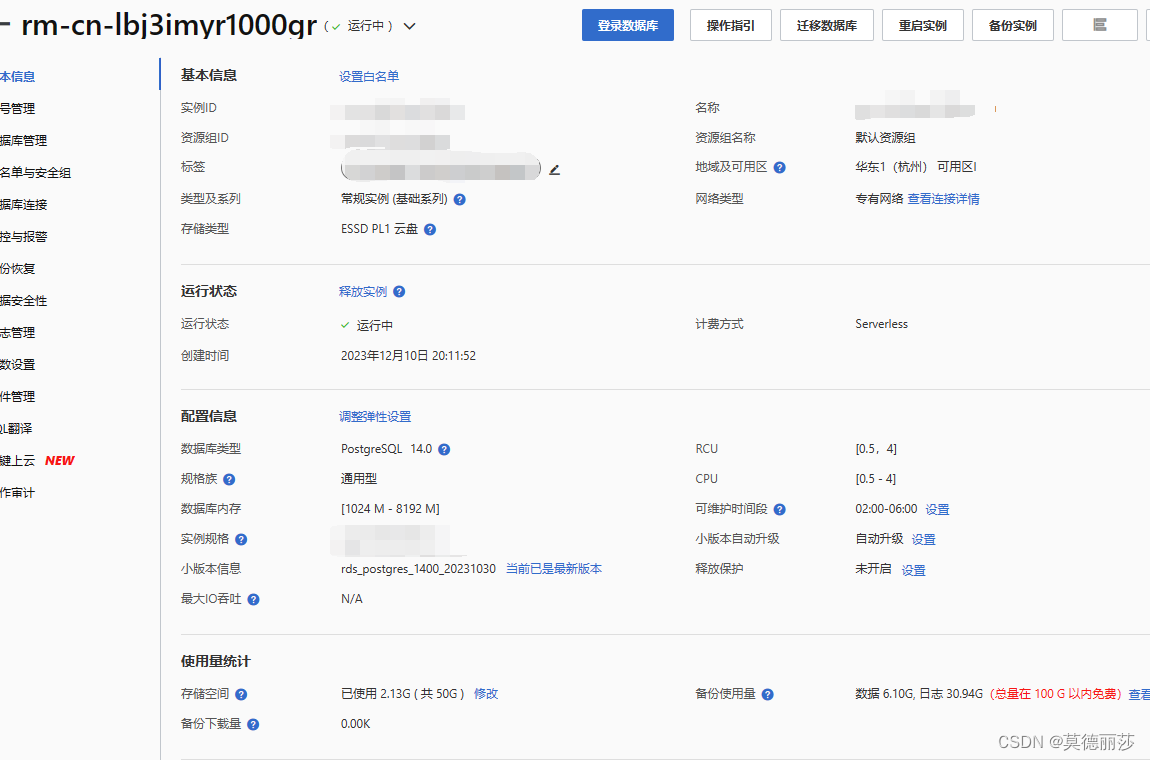
接下来创建一个高权限账号
设置你的名称和密码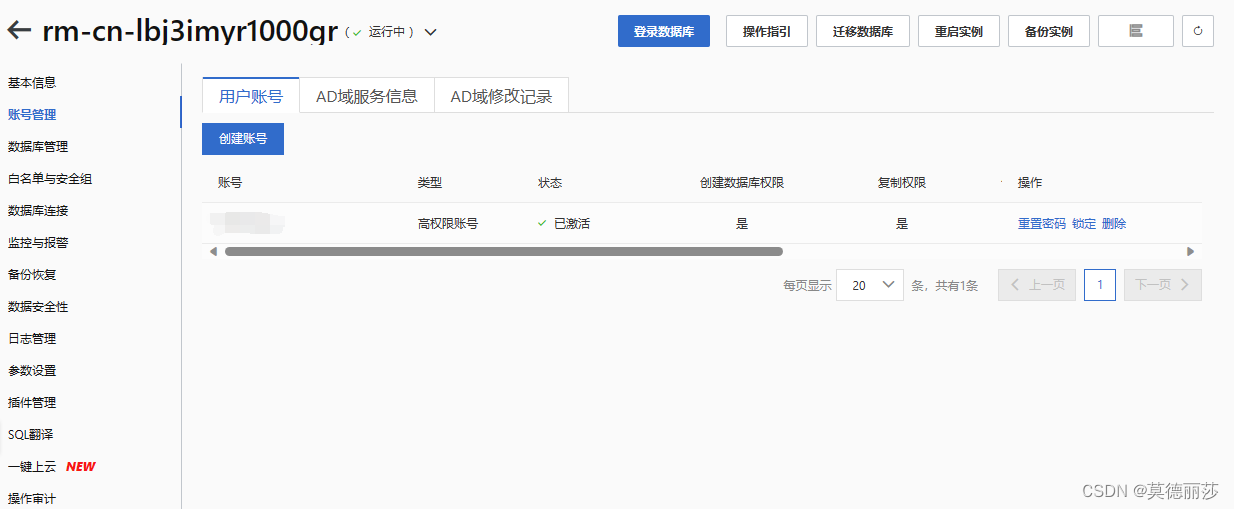
但是连接之前还有一步,就是要将ip加入白名单,直接设置为0.0.0.0/0意味着对公网开放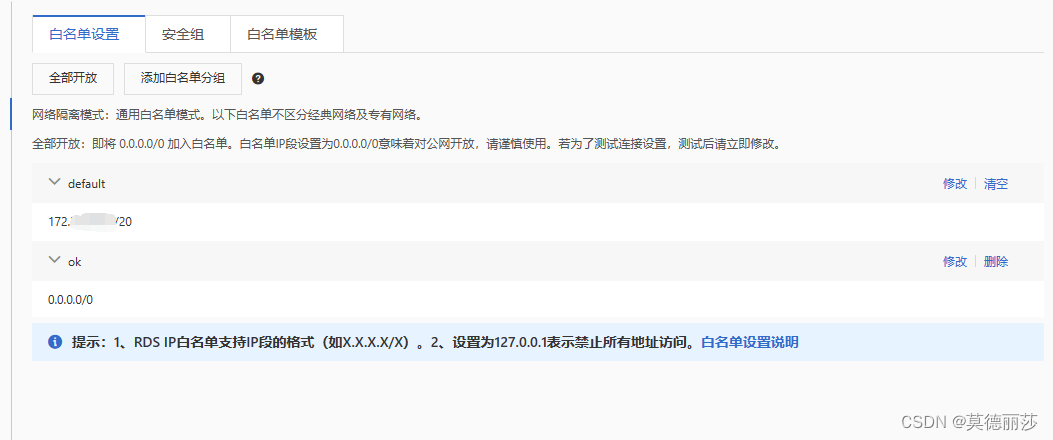
接下来就可以在navicat等软件上与postgre数据库进行连接了
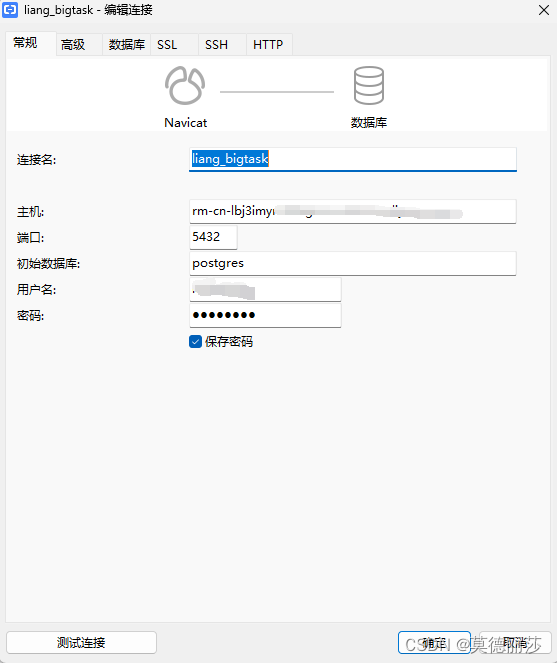
创建成功!
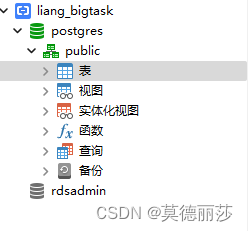
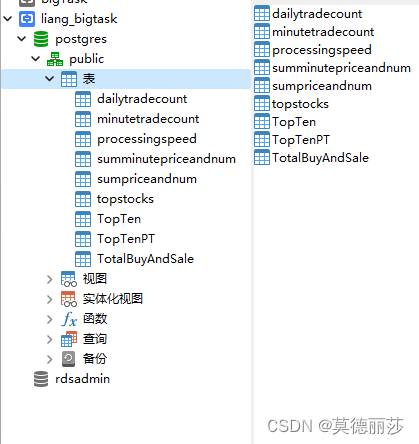
这里是需要使用的Table
Topology文件,负责制定storm的拓扑结构
package topology;
import bolt.*;
import spout.spout_dataGetting;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
public class topology {
public static void main(String[] args) throws Exception {
// 创建一个拓扑构建器
TopologyBuilder builder = new TopologyBuilder();
// 设置Spout
builder.setSpout("stock-data-spout", new spout_dataGetting(), 1);
// 设置第一个Bolt:累积总价和总量
builder.setBolt("sum-bolt", new bolt_sumPriceAndNum(), 1)
.fieldsGrouping("stock-data-spout", new Fields("price", "trade_volume"));
// 设置第二个Bolt:统计近1分钟和当天累计的交易数据
builder.setBolt("trade-stats-bolt", new bolt_summinutePriceAndNum(), 1)
.fieldsGrouping("stock-data-spout", new Fields("trade_timestamp", "price", "trade_volume"));
// 设置第三个Bolt:统计每分钟买入和卖出交易的数量
builder.setBolt("trade-minute-count-bolt", new bolt_minutetradeCount(), 1)
.fieldsGrouping("stock-data-spout", new Fields("trade_type"));
// 新增:设置第四个Bolt,用于计算每秒处理的元组数量
builder.setBolt("processing-speed-bolt", new bolt_processingSpeed(), 1)
.shuffleGrouping("stock-data-spout");
// 新增:设置第五个Bolt,统计每天买入和卖出交易的数量
builder.setBolt("processing-daily-speed-bolt", new bolt_tradeCount(), 1)
.shuffleGrouping("stock-data-spout");
// 新增:设置第六个Bolt,统计近 1 分钟与当天累计的交易金额排名前 10 的股票信息
builder.setBolt("processing-list10-bolt", new bolt_StockTradeStats(), 1)
.shuffleGrouping("stock-data-spout");
// 创建拓扑配置
Config conf = new Config();
conf.setDebug(true);
// 运行拓扑
if (args != null && args.length > 0) {
conf.setNumWorkers(3);
StormSubmitter.submitTopology(args[0], conf, builder.createTopology());
} else {
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("stock-data-topology", conf, builder.createTopology());
Thread.sleep(10000);
cluster.shutdown();
}
}
}
spout文件,负责对csv文件中的tuple进行切分和传播
package spout;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import java.io.*;
import java.nio.charset.Charset;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
public class spout_dataGetting extends BaseRichSpout {
private SpoutOutputCollector collector;
private BufferedReader reader;
private boolean completed = false;
private boolean isFirstLine = true; // 用于跳过第一行的标志
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
this.collector = collector;
try {
this.reader = new BufferedReader(new InputStreamReader(
new FileInputStream("股票数据1.csv"),
Charset.forName("GBK")));
} catch (Exception e) {
throw new RuntimeException("Error reading file [股票数据1.csv]", e);
}
}
@Override
public void nextTuple() {
if (completed) {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// 处理中断异常
}
return;
}
String line;
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm");
try {
while ((line = reader.readLine()) != null) {
if (isFirstLine) {
isFirstLine = false;
continue; // 跳过第一行
}
String[] fields = line.split(",");
try {
String stockCode = fields[1];
Date tradeDate = dateFormat.parse(fields[0]);
long tradeTimestamp = tradeDate.getTime();
double price = Double.parseDouble(fields[3]);
long tradeVolume = Long.parseLong(fields[4]);
String tradeType = fields[5];
String tradePlace = fields[6];
String tradePlatform = fields[7];
this.collector.emit(new Values(stockCode, tradeTimestamp, price, tradeVolume, tradeType, tradePlace, tradePlatform));
} catch (NumberFormatException e) {
System.err.println("解析错误: " + e.getMessage());
}
}
} catch (Exception e) {
throw new RuntimeException("Error reading tuple", e);
} finally {
completed = true;
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("stock_code", "trade_timestamp", "price", "trade_volume", "trade_type", "trade_place", "trade_platform"));
}
@Override
public void close() {
try {
reader.close();
} catch (IOException e) {
// 处理关闭文件时的异常
}
}
}
Bolt文件, 负责执行基本操作,这里使用计算总交易量和交易金额的bolt距离,代码如下:
package bolt;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.BasicOutputCollector;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.util.Map;
public class bolt_sumPriceAndNum extends BaseBasicBolt {
private double totalPrice = 0;
private long totalVolume = 0;
private transient Connection connection;
private int tupleCount = 0; // 新增计数器
@Override
public void prepare(Map stormConf, TopologyContext context) {
totalPrice = 0;
totalVolume = 0;
try {
// 根据您的数据库信息更改这些参数
String url = "数据库url";
String user = "用户名";
String password = "密码";
// 连接到数据库
this.connection = DriverManager.getConnection(url, user, password);
} catch (Exception e) {
throw new RuntimeException("Error connecting to the database", e);
}
}
@Override
public void execute(Tuple tuple, BasicOutputCollector collector) {
double price = tuple.getDoubleByField("price");
long volume = tuple.getLongByField("trade_volume");
totalPrice += price * volume;
totalVolume += volume;
tupleCount++; // 增加计数器
// 检查计数器是否达到50
if (tupleCount >= 50) {
writeToDatabase(); // 调用数据库写入方法
tupleCount = 0; // 重置计数器
}
}
private void writeToDatabase() {
try {
// 清空表
String deleteSql = "DELETE FROM sumpriceandnum";
try (PreparedStatement deleteStmt = connection.prepareStatement(deleteSql)) {
deleteStmt.executeUpdate();
}
// 插入新数据
String insertSql = "INSERT INTO sumpriceandnum (sum_price, sum_num) VALUES (?, ?)";
try (PreparedStatement insertStmt = connection.prepareStatement(insertSql)) {
insertStmt.setDouble(1, totalPrice);
insertStmt.setLong(2, totalVolume);
// 执行SQL语句
insertStmt.executeUpdate();
}
} catch (Exception e) {
// 处理异常
System.err.println("Error writing to database: " + e.getMessage());
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
// 这个Bolt不发射任何新的流,所以这里不声明输出字段
}
@Override
public void cleanup() {
// 关闭数据库连接
if (this.connection != null) {
try {
this.connection.close();
} catch (Exception e) {
// 处理异常
}
}
}
}
这里使用了计数器控制插入数据库的次数, 每执行五十次向数据库插入一次数据, 每次执行excute都更新一次效率太低了,运行速度只有10来条每秒, 更改之后可以到几百条几千条每秒,取决于电脑的内存大小,CPU线程个数等
运行程序
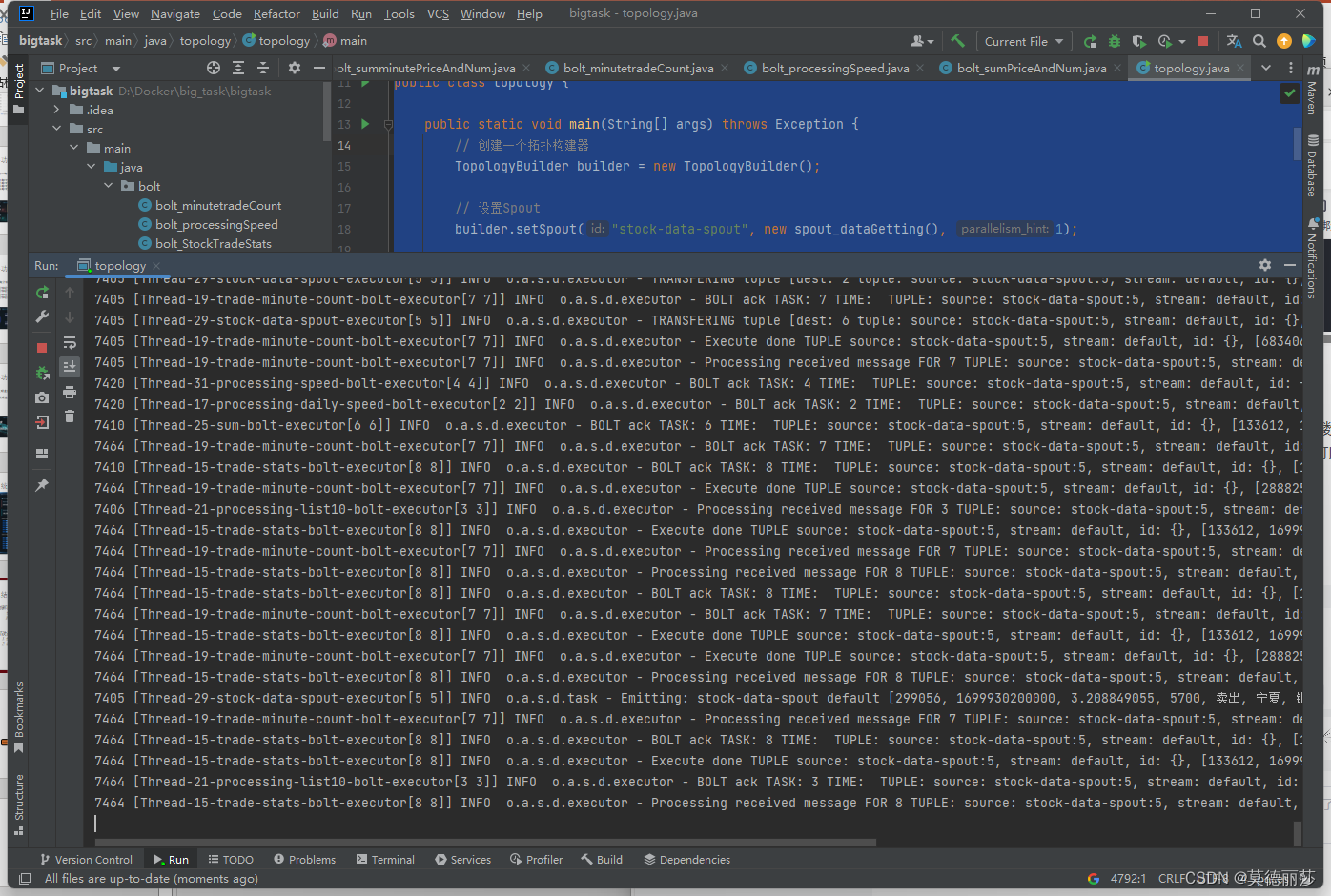
这里可以看到正在运行程序,在从文件里读取数据
最后设计一个datav界面,连接你申请的阿里云数据库,就实现了动态展示
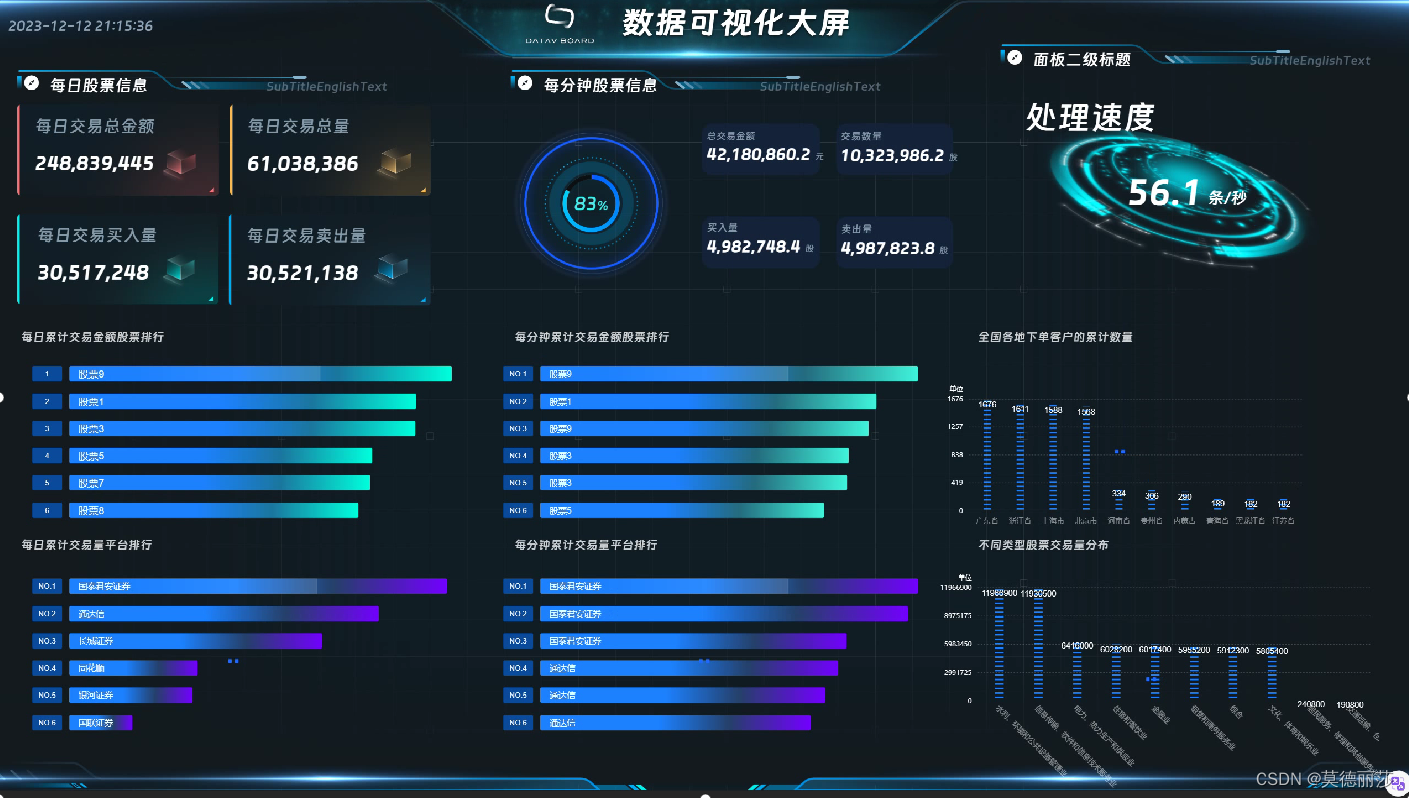
具体datav的设计可以看我的另一个帖子

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)