
兔老大的系统设计(六)报表系统
写在前面,我认为能看到这个系列后面的,都是交易行业相关的人,所以我不再追求解释每个细节,我会用尽量精炼和准确的语言描述出交易系统的重点、难点和需要特别注意的坑。
写在前面,我认为能看到这个系列后面的,都是交易行业相关的人,所以我不再追求解释每个细节,我会用尽量精炼和准确的语言描述出交易系统的重点、难点和需要特别注意的坑。
本篇提醒,写报表类服务会和mysql息息相关,因为要处理大量数据,这很显然是一个IO及其密集,CPU不那么密集的服务,所以看这个文章不只是学会如何写报表,你也要学习到很多mysql性能相关知识
一、背景
如果你的交易系统开发大概完成,准备上线,那么你一定需要向监管机构、交易所、合作上游等地提交报表,用来描述你的用户动作,你的系统动作,你的上游动作,在美股,如果你不这么做,就不能上线你的系统。
这些报表种类繁多,目的各不相同,如果不在初期就统一设计并维护,未来很可能非常难管理,性能、代码交接、正确性、可用性得不到保障。
这些报表主要是为了确保市场透明度、合规性、以及监管机构能够追踪交易行为。以下是这类报表和报告类型的举例:
1. 订单审计跟踪报告(OATS)
- OATS(Order Audit Trail System)是FINRA要求券商提交的一个系统,旨在记录和报告所有客户订单、修改、取消等交易活动。
- 目的是确保交易活动的透明度,便于监管机构进行市场监控。
- 具体内容包括:订单发起、订单修改、订单取消、执行、成交等每个环节的信息。
- 每笔交易都需要记录详细的时间戳、订单详情、交易对手、委托价格等信息。
- 提交频率:通常要求每笔交易执行后立即报告。
2. 合并审计跟踪(CAT)
- CAT(Consolidated Audit Trail)是SEC和FINRA为监控所有市场活动而创建的系统,旨在追踪所有证券市场的交易数据。
- CAT系统旨在将所有市场交易活动整合在一个中央数据库中,便于对所有交易行为进行跟踪和审查。
- 通过CAT系统,监管机构可以追踪到每一笔证券交易、每个订单的流动路径、时间戳和市场参与者等信息。
- 报告内容:涉及订单详情(如交易时间、价格、数量)、执行信息(如成交价格、数量)、交易类型等。
- 提交频率:通常要求在交易发生后T+1日内提交详细的交易数据。
3. 市场交易和结算报告
-
交易报告:券商需要定期向交易所、清算所和监管机构提交交易数据,包括订单的原始指令、执行价格、交易数量等。
- 例如,NASDAQ 和 NYSE 等交易所通常会要求券商将客户的交易信息上报,以便追踪交易的透明度和及时发现市场操纵行为。
- 具体上报内容可能包括买卖双方的身份、订单的执行情况、价格和交易量等。
-
交易清算和结算报告:向清算机构报告客户的每笔交易,确认交易是否已完成并清算。清算报表通常包括结算日期、成交价格、交易量、经纪佣金等。
4. 反洗钱(AML)交易报告
- 可疑活动报告(SAR):如果券商在客户交易过程中发现可疑行为(例如大额交易或短时间内大量资金流动),则需要向监管机构报告。
- 可疑活动报告不仅仅是反洗钱措施的一部分,还包括对涉嫌市场操控和欺诈行为的报告。
- 货币交易报告(CTR):对于超过特定金额(通常为$10,000)的现金交易,券商需要提交报告。
5. 大宗交易报告(Block Trade Reporting)
- 大宗交易报告:如果客户进行大宗交易(例如超过特定交易量或金额的交易),券商需要向交易所或监管机构报告这些交易。
- 这些交易通常会在不同时间框架内进行汇总并报告。
6、TRF(Trade Reporting Facility)
TRF 是 FINRA 与交易所(如 NASDAQ、NYSE)合作运营的交易报告工具,用于上报场外交易(OTC)或非交易所执行的交易。对于碎股交易,虽然是券商内部撮合的结果,仍需通过 TRF 向监管机构和市场报告,以便:
- 记录碎股交易数据;
- 纳入市场交易透明度的统计;
- 确保市场操纵行为的防范。
总结
以上这些报表主要是针对券商与客户交易行为的记录、监管审查以及防范市场操控、洗钱等风险。这些报告需要通过如OATS、CAT等系统进行上传,并且需要包括交易的详细数据,如订单、执行、修改、取消等操作的记录,确保市场监管和透明度。
二、需求分析
按照行业标准(美股),你需要提交好多种报表,它们的某些上报字段大同小异(主要是FIX标准协议的字段),但是在实时性、上报维度等方面要求差别很大。
如实时性:有实时上报的、每小时上报的、每天上报的、年度上报的等。
如上报维度:有单个消息维度的、单用户请求维度的、订单维度的。
如具体信息:一般要求用户的下改撤单动作和我们交易系统的回应、我们交易系统发给上游的下改撤单动作和上游的回应、我们系统内部的消息等。
为了完成这些报表的上报工作,首要任务是深入了解并从各核心系统的数据库中提取相关数据。
这些系统包括但不限于:
订单管理系统(OMS),负责记录客户的订单信息;
路由系统,用于跟踪订单的分发路径和执行指令;
Inbound系统,用来接收客户的交易请求;
Outbound系统,负责将交易指令发送至外部市场;
内部撮合系统,处理碎股交易和自撮合逻辑;
发货系统,负责交易清算和交割的相关流程。
通过整合这些系统的数据,可以确保所有交易细节的完整性和准确性,为实时上报或当天上报奠定基础。
三、目标明确
需要从系统安全性、性能、可用性和运维友好性四个方面优化设计,以满足当前和未来业务需求:
系统安全性
- 报表生成需尽量独立于交易链路,避免影响核心逻辑、性能和可用性。
性能达标
- 盘后报表:如每日盘后需上报的报表,需在交易结束数小时内完成,避免监管问责。
- 实时报表:任何漏报或错报可能触发警告甚至暂停交易权限,需确保数据处理和上报流程高效准确。
高可用性
- 通过容错设计、冗余架构和实时监控,保障系统运行稳定,快速应对故障。
- 按优先级队列处理报表,确保关键任务优先完成。
运维友好性
- 模块化设计:简化新报表的扩展,避免影响现有功能。
- 自动化运维:支持一键部署、实时监控,降低维护成本。
- 动态配置:灵活调整字段、时间窗口和上报目标,适应监管变化。
四、系统设计重点
一个普通的报表大概是怎么写出来的?
可能是这样:你领到了一个报表开发任务,这时可能你的三个同事也各自领到了一个,最简单直接的想法可能是:第一,想办法读到所有服务的数据(相信我,如果不这么做,一般不会拿到报表需要的所有数据),第二,根据报表的上报细节拼接各个服务的数据,最后生成要求维度的,一条一条的报表记录。
那么,这个服务会有哪些问题,或者有哪些需要注意的点呢?(请对应第三章看)
- 安全出发,为了不影响交易系统,你获取数据的方法一定要注意,不能直接读主库,我给你三种选择:读从库、服务写MQ给你消费、DTS方案。
- 性能出发,因为要在交易结束后数个小时完成上报,等交易i结束开始生成报表肯定是不够,建议搞分时间批运行、一致性哈希、性能分析、多倍流量的测试等。
- 可用性出发,要搞压测、非常多的细节测试、主备切换等
- 运维出发,为了降低代码维护成本和db负载等,要搞代码分级处理、日志分级治理、完整技术文档、正规发布流程等,并且建议最好求同存异,提炼出大部分报表的相同点,然后根据各自的需求再定制。
基于这些考虑,我们的大概流程应该是:
-
数据同步
- 从生产库和表中同步最新的交易数据至报表专用的数据库,确保数据完整性和实时性。
-
数据聚合
- 将多源数据(如订单系统、路由系统等)汇总到统一的数据仓库,为后续加工提供基础。
-
单消息维度的聚合处理
- 按时间段对单条消息进行聚合,关联各服务中的相关数据,确保每条消息完整反映其所需的上下文。
-
会话维度的数据补全
- 基于时间段,按照交易会话流程补全数据。例如,对一个下单请求,追踪其后续的所有关联事件(如部分成交、撤单、修正、完全成交等),生成完整的会话链路信息。部分报表需要依赖完整的历史链路计算数据。
-
订单维度的生命周期补全
- 按时间段聚合订单的完整生命周期数据,包括从创建、修改到完成的所有状态变化,为报表生成提供订单级别的全景视图。
-
报表生成
- 基于已准备好的会话和订单维度数据,按报表需求生成对应的报表,并保证实时性或批量处理的时效要求。
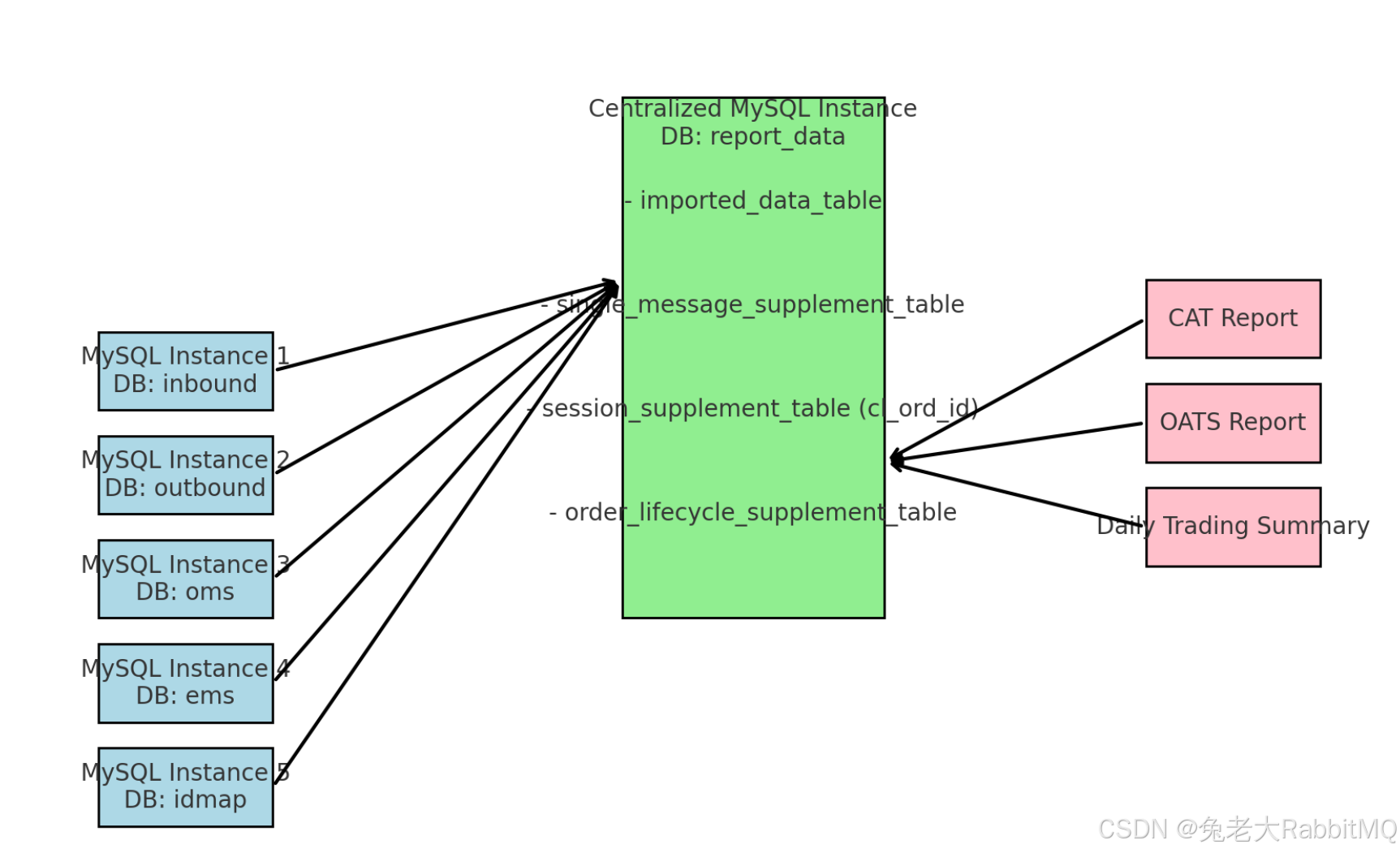
左侧数据库(数据来源):
- inbound:入站请求数据库,存储客户订单请求数据。
- outbound:出站请求数据库,记录订单被发送到上游市场的状态。
- oms:订单管理系统,跟踪订单生命周期数据。
- ems:执行管理系统,记录订单执行的细节。
- idmap:ID映射表,处理订单与外部标识的对应关系。
右侧中央数据库(补充表结构):
- imported_data_table:存储从源数据库导入的原始数据。
- single_message_supplement_table:基于单条消息补充的表,记录从各系统中获取的具体消息级信息。
- session_supplement_table (cl_ord_id):按会话(同一 cl_ord_id)维度补全数据,反映同一订单的相关链路和状态变化。
- order_lifecycle_supplement_table:按订单生命周期维度补全的表,整合整个订单的生命周期信息,供最终报表读取使用。
右侧生成的报表:
- CAT Report:Consolidated Audit Trail 报表,跟踪订单的详细生命周期。
- OATS Report:Order Audit Trail System 报表,记录订单的流转过程(现多被 CAT 替代)。
- Daily Trading Summary:每日交易总结报表,汇总交易的核心数据。
箭头表示:
- 数据流向:左侧数据库的数据被导入中央数据库并存储在各补充表中。
- 报表生成:所有报表读取
order_lifecycle_supplement_table,整合数据生成最终文件。
五、第一阶段方案
5.1 选择读数据的方式
报表数据比较关注⼀个订单的整个⽣命周期,但是因为系统⾥的数据是散落在各个系统的DB内,在报表⽣成的时候,需要做⼤量的跨库查询来进行数据补⻬拼接,效率低,且对查询的库也会造成一定压力。
因此需要搬迁散落在系统各DB的原始数据,然后再进行加工整合,从而生成报表。
刚才提到三种选择:读从库、服务写MQ给你消费、DTS方案。
| 方案 | 实现难度 | 对交易系统入侵 | 是否引入新组件 | 实时性 |
| 读从库 | 较低 | 较低 | NO | 较低 |
| 消费MQ | 中等 | 较高 | YES | 较高 |
| DTS | 较低 | 较低 | YES | 中等 |
适用场景比较
MQ就不说了,主要是我无法忍受侵入交易系统逻辑
-
使用DTS的场景
- 需要快速启动任务,且数据库类型多样或数据规模大。
- 关注数据同步的实时性、容错性和运维便捷性。
- 复杂场景如跨地域复制、异地灾备、多活架构等。
-
自定义读取写入的场景
- 数据处理逻辑复杂且需要深度定制。
- 数据量小且实时性要求不高,能够接受周期性批量同步。
- 项目预算有限,不想支付托管服务费用。
我建议实时性要求比较高的报表可以考虑MQ或者DTS,小时级别和日级别、年级别的报表可以采用读从库,因为大部分创业者或者紧急需求不太喜欢DTS,所以下面我介绍大部分报表的方案。
5.2 创建影子DB
即在备份DB创建多个库的影子库(精确到月),以及里面的表(精确到天)。
5.3 dump同步数据
dump生产数据,使用create_time对数据进行筛选。然后再备份库里面重放。
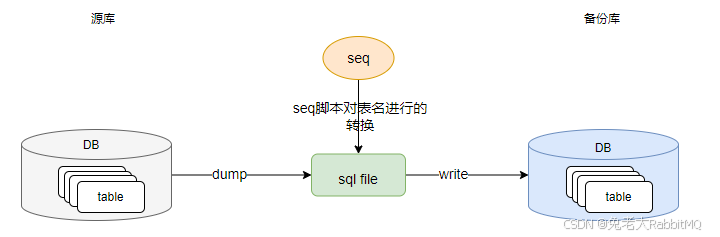
5.4 diff 核对数据
核对源库和1.2 脚本dump的备份库的数据。
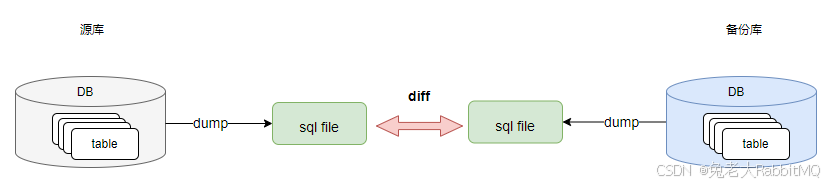
- 源库和备份库都执行dump(相同的时间区间)。
- 使用diff校验2个sql文件是否相同。
六、第二阶段方案
我们拿到的数据:各个服务的库表信息
我们这阶段要生成的数据:单消息维度的完整数据
我解释一下,什么是单消息维度,如某条消息,它被存在某个服务的三张表,你需要对三张表写复杂的sql来拼接,甚至有的消息所需所有信息不在同一个服务。我们要做的就是本阶段完成后,每条消息都是完整的。
这里的结果已经有简单报表需要了
6.1 创建汇聚库
- 汇聚库,库名固定为data_for_report_date_v3
- 库里面会创建多张表,根据你的需要来,我建议统一起来,只有消息表,以及可以连接消息的idmap
6.2 汇聚数据
把结构/取值不同的记录统一格式存入报表db,以便后续的操作。
-
提取目标记录
- 根据不同服务的规则(如 inbound、outbound、oms 等),从对应的表中提取需要的记录。
- 确保筛选条件准确,避免遗漏或冗余数据。
-
解析记录
- 从提取的记录中解析出报表所需的信息,包括:
- 原始记录的重要字段:如订单号、账户号等核心字段。
- FIX消息中的字段:解析交易指令和响应中的标准化字段。
- 消息结构体中的字段:提取特定服务的自定义字段,补充业务信息。
- 从提取的记录中解析出报表所需的信息,包括:
-
格式转化与统一
- 对取出的字段进行初步转化,统一字段名称、数据类型和取值规则,确保所有数据符合统一规范。
- 处理特定值的映射(如状态码、日期格式等),以简化后续的操作和查询。
-
写入汇聚表(flow表)
- 将所有解析并格式化的数据集中写入一张汇聚表(flow表),确保所有需要上报的消息均存储在统一的表中。
- 该表作为报表生成的核心数据来源,为后续处理和报表生成提供标准化的数据支撑。
对于第三步,转化的信息以消息类型为例:
报表根据需要规定了六种消息类型,这六种类型基本符合fix标准的六种消息。
|
值 |
类型 |
req/rsp |
具体解释 |
|
0 |
order_new |
req |
下单请求 |
|
1 |
order_replace |
req |
改单请求 |
|
2 |
order_cancel |
req |
撤单请求 |
|
3 |
exec_report |
rsp |
执行报告(包含下单拒绝) |
|
4 |
cxl-rej |
rsp |
拒绝报告(包含其他拒绝) |
|
5 |
rej |
rsp |
系统级别拒绝(如fix格式不对) |
我们要做到屏蔽服务间的、不同下游的、不同上游的、报表间的差异,做到统一格式数据,把需要的信息统统拿出来按照规定的数据结构放好。
七、第三阶段方案
我们拿到的数据:单消息维度的完整数据
我们这阶段要生成的数据:会话维度、订单维度、业务维度的完整数据
对每条记录,查找所有补填字段需要的信息:
1)获取所有的id_map,用于连接各个记录
2)获取所有相关的记录,查找条件很简单,订单号一样的拿出来:where order_id in ('%s') order by create_time
把相关记录分类,方便使用,目前根据所有的报表的需求定义了十种记录,详细介绍如下:
|
类型 |
含义 |
|
in_new_req |
inbound侧下单请求 |
|
in_req |
inbound侧请求 |
|
in_recent_er |
inbound侧最近的exec_report |
|
out_recent_er |
outbound侧最近exec_report |
|
out_req |
outbound侧请求 |
|
out_rsp |
outbound的回包 |
|
out_new_rej_er |
outbound侧下单拒绝报告 |
|
out_cxj_rej |
outbound侧cxj_rej回包 |
|
out_rej |
outbound侧的reject回包 |
|
out_new_req |
outbound侧的下单请求 |
|
ended_record |
生命周期结束的记录 |
对每条记录,补填需要的字段很多,各个报表需要的不同,这里没有很多的技术难点,我分四大块内容列举一下可能很重要的补填逻辑:
7.1 所有类型记录的通用逻辑
-
通用字段补全
- 如果本记录对应一个 in_new_req(Inbound New Request),则需从该记录中提取并填写以下重要字段:
- account_num:关联客户账户编号。
- corr:关联标识符,用于关联订单流转中的上下文。
- root_cl_ord_id:客户订单的全局唯一标识。
- security_type:证券类型(如股票、债券等)。
- ord_type:订单类型(如市价单、限价单等)。
- side:
- 如果本记录对应一个 in_new_req(Inbound New Request),则需从该记录中提取并填写以下重要字段:
-
入站请求字段补全
- 如果本记录对应一个 in_req_ot(Inbound Request Other Type,例如改单请求),则需补充以下字段:
- recv_time:订单接收到系统的时间戳,用于记录时间链路中的起点。
- sid_in:系统内订单的入站流水号,用于追踪订单处理链路。
- 如果本记录对应一个 in_req_ot(Inbound Request Other Type,例如改单请求),则需补充以下字段:
-
出站请求字段补全
- 如果本记录对应一个 out_new_req_ot(Outbound New Request Other Type),则需补充以下字段:
- sid_out:
- to_up:
- 如果本记录对应一个 out_new_req_ot(Outbound New Request Other Type),则需补充以下字段:
我只是随便列举一些,仅供参考,这里通过关联入站下单请求(in_new_req)、入站请求(in_req_ot)和出站下单请求(out_new_req_ot)等,全面补充每条记录的关键字段,如账户信息、订单类型、状态变更等。这一阶段确保每条记录都具备完整的上下游链路和逻辑关联,无需后续补充额外字段。
......
7.2 专门为某个大型变动写的业务逻辑
在报表生成过程中,需要针对以下特殊业务场景进行定制化处理,以确保逻辑完整性和数据准确性:
Reroute订单处理
- 对于因上游故障等原因而被重新路由到其他上游的订单,需识别并标记为Reroute订单。
- 报表生成时需要特殊逻辑处理,关联原始路由信息,确保上报数据能够完整反映订单的流转过程。
多腿订单处理
- 多腿订单(例如跨市场、跨资产类别的复杂订单)涉及多个子订单,每个子订单可能对应不同的执行逻辑和字段。
- 报表需支持逐腿记录和汇总,处理如父子订单关系、各腿的状态同步等特殊逻辑,确保多腿订单的完整性和一致性。
碎股订单处理
- 碎股(Fractional Shares)订单涉及非整数股的买卖,是特殊的业务场景。
- 报表生成时需聚焦于小数股的撮合结果、盈亏计算和后续结算过程,确保所有相关数据准确记录,并符合监管要求。
24小时交易订单处理
- 自建24小时交易系统与普通交易时段订单处理逻辑不同,需要支持全天候的订单追踪和状态管理。
- 报表需针对不同时间段的订单进行分段统计,覆盖跨天交易的特殊场景,同时满足全天候系统的稳定性和实时性需求。
最后写入order_trail_flow_info_date_v3_new表。
为什么不是更新flow表而是写入new表?是因为这种方式在性能和操作效率上更具优势。
在这种场景下,每条记录的大部分字段都需要修改,而数据库的 UPDATE 操作通常比 INSERT 操作耗时更长,尤其当修改涉及多个字段时,更新操作会触发更多的索引维护、锁机制和日志写入。
此外,写入新表还能保持原始数据的完整性,方便后续审计和回滚操作,从而提升系统的稳定性和可维护性。
7.3 订单生命周期
背景是,不同报表对上报的信息范围有不同的要求,需要对每一条记录的状态进行分类,以便各个报表使用。
以下场景是虚构的,大家理解我们的归纳过程就OK。
我们首先和产品经理确认所有的场景,确认到底报不报。
|
场景 |
场景介绍 |
是否上报 |
|
inbound直接拒绝 |
可能是字段错误等问题 |
No |
|
inbound内被风控拒绝 |
Yes |
|
|
未请求到outbound |
此时inbound、风控没问题,可能的原因是没找到路由outbound、没在交易时间等 |
No |
|
outbound直接拒绝 |
此时inbound、风控没问题,outbound校验失败 |
No |
|
未收到上游回包(可能outbound没请求) |
此时inbound、风控、outbound没问题 |
Yes |
|
被上游拒绝 |
此时inbound、风控、outbound没问题 |
Yes |
|
生命周期结束后的记录 |
结束后的记录不报 |
No |
根据产品的填写,结合报表实际情况,设计出事件状态的定义如下:
|
值 |
状态名 |
含义 |
是否上报 |
|
0 |
NORMAL |
正常 |
yes |
|
1 |
OUTBOUND_NOT_SEND_FIX_REQ |
针对inbound侧请求查询outbound侧无对应的fix请求发出 |
no |
|
2 |
OUTBOUND_NOT_RECV_FIX_RSP |
未收到上游回包 |
yes |
|
3 |
REJ_BY_UPSTREAM |
被上游拒绝 |
yes |
|
4 |
INVALID_REQ |
请求非法 |
no |
|
5 |
EVENT_STATUS_ENDED |
生命周期结束后的记录 |
no |
|
6 |
REJ_BY_RMS |
被风控系统拒绝 |
yes |
|
7 |
HOLD_BY_RMS |
表示被风控系统hold住 |
yes |
这时,我们可以写出状态机表格:
| 当前状态 | 可能转移到的状态 | 触发条件 | 是否终态 |
|---|---|---|---|
| NORMAL | OUTBOUND_NOT_SEND_FIX_REQ | 入站请求未找到对应的出站请求 | 否 |
| OUTBOUND_NOT_RECV_FIX_RSP | 出站请求发送成功但未收到回包 | 否 | |
| OUTBOUND_NOT_SEND_FIX_REQ | NORMAL | 后续时间段找到补充的出站请求 | 否 |
| OUTBOUND_NOT_RECV_FIX_RSP | 补充出站请求后仍未收到回包 | 否 | |
| OUTBOUND_NOT_RECV_FIX_RSP | NORMAL | 后续时间段收到上游回包 | 否 |
| HOLD_BY_RMS | NORMAL | 风控系统解冻订单 | 否 |
| REJ_BY_RMS | 风控系统最终拒绝订单 | 否 | |
| REJ_BY_UPSTREAM | 无 | 被上游拒绝,终态状态,不会发生进一步转换 | 是 |
| INVALID_REQ | 无 | 请求非法,终态状态,不会发生进一步转换 | 是 |
| EVENT_STATUS_ENDED | 无 | 生命周期结束,终态状态,不会发生进一步转换 | 是 |
| REJ_BY_RMS | 无 | 风控系统拒绝订单,终态状态,不会发生进一步转换 | 是 |
在处理 order_trail_flow_info_date_v3_new 表记录的生命周期时,执行以下流程:
筛选目标记录
- 查询条件:
WHERE event_status=2 AND msg_type IN (0, 1, 2)。 - 解释:
event_status=2:筛选当前状态为 2 的记录,表示未收到上游回包的订单。msg_type IN (0, 1, 2):筛选指定的消息类型,确保处理范围明确。
分析具体原因
- 根据查询结果中的
cl_ord_id字段,关联其他表或上下文数据,分析每条记录的具体异常原因。
更新状态
- 将符合条件的记录的
event_status从当前值(0 到 2)更新为新状态(3 到 7):- 更新逻辑:根据分析的具体原因和业务规则,精确映射新状态值,避免无意义或错误更新。
- 映射关系示例:
0 → 3: 正常流转的记录更新为“被上游拒绝”。1 → 6: 缺少出站请求的记录更新为“被风控系统拒绝”。2 → 7: 未收到回包的记录更新为“被风控系统冻结”。
执行更新
- 对符合条件的记录执行批量更新操作,确保操作高效且原子性。
- 更新语句示例:
UPDATE order_trail_flow_info_date_v3_new SET event_status = CASE WHEN event_status = 0 THEN 3 WHEN event_status = 1 THEN 6 WHEN event_status = 2 THEN 7 END WHERE event_status=2 AND msg_type IN (0, 1, 2);
验证和记录
- 在更新完成后,对数据进行验证,确保所有更新符合预期:
- 数据检查:确认更新后的状态分布是否与业务规则匹配。
- 日志记录:记录处理的
cl_ord_id和对应的状态变更,方便后续审计和排查。
根据以上虚构的上报场景我们可以发现,报表的上报规则是:
1、没发给上游,不报。
2、发给上游了,要上报。
这也很合理,毕竟上游没收到的订单,不用报也是正常。
如果用户数较多,特殊场景也会出现,这时你最好按我第一篇设计文章提到的方法,设计状态机表格并写出代码,这里由于知识产权原因我就不列举了。
7.4 生成报表
你可能要做如下操作:
校验输入日期是不是当天交易日
对每条记录进行很多信息处理、字段转换等,这里做几个重要字段的说明:
- 区分下游:很多字段都是不同下游有不同转换规则
- 区分上游:很多字段对不同上游也有不同转换规则
- 特殊业务逻辑的字段
- 事件类型:EventType,这是对上文定义过的报告类型做了进一步的细分,不同事件类型的处理也会有区别。
按下游分别生成报表文件
八、运维
8.1 环境构成
上文提到,多个报表很容易变得难以维护,必须定下很多标准,我给个参考:
开发环境除外,建议还有三个环境:
gamma:此环境负责测试,包括新需求发布验证、压测、对比测试、产品体验等
prod2:此环境负责兜底,如果prod1出现问题,prod2要切上去,负责上报。
prod1:正式环境
8.2 开发调试参考步骤
- 在个人分支开发后,push
- 确定部署环境(寻找目前无人使用的机器)
- 确定数据来源(具体db)
- 检查数据正确性
- 确认数据是否完整,主要体现在⼀个订单的整个⽣命周期是否正常。
- 确认数据有自己修改的特性
- 提单部署
- 运行
- 查看日志和生成的报表是否正常
8.3 发布参考步骤
- 在个人分支开发后,先在UAT环境测试新增特性
- 提MR将个人分支合入test分支
- 提单将test分支代码合入master,填写《checklist》、《发布审核》
- 将master版本,部署到gamma环境。
- 对比prod和gamma环境flow_new表的数据总数。
- 检查两环境各个报表的md5是否相同
- 按照验证计划开始验证prodtest
- 检查发布特性
- 对比生产环境、重放环境生成的文件
- 对比生成耗时,prod、gamma对比
- 同步填写《交易报表prod和gamma数据准确性报告》
- 将master版本,部署到prod环境。
- 按照验证计划开始验证prod
十、性能
随着业务规模的不断增长,数据库实例和表的数量也逐渐增加,串行 dump 方法因逐条顺序执行,效率低下,无法满足业务对数据备份和导出的时效性要求。
因此,我们必须开发一个支持并发控制的脚本,通过限制最大并发任务数,在提升执行效率的同时,确保资源的合理利用和系统的稳定。
并发控制
- 存储计数器:在 Redis 或 MySQL 中维护一个计数器,用来记录当前正在运行的
dump脚本数量。 - 并发控制逻辑:
- 每个脚本启动时,检查计数器是否小于允许的最大并发数。
- 如果小于,增加计数并继续执行脚本。
- 如果达到上限,脚本等待或直接退出。
- 计数清理:在脚本完成后,减少计数器,释放占用的并发槽位。
需要注意的点:
关键点说明
-
Redis 计数器
- 使用
redis.incr和redis.decr操作维护当前正在执行任务的计数。 - 可以通过
redis.get(redis_key)随时查看当前计数。
- 使用
-
并发限制
- 在
acquire_lock中检查计数是否小于MAX_CONCURRENT_TASKS,满足条件时增加计数。 - 如果达到限制,可以选择等待或直接跳过(可扩展为重试机制)。
- 在
-
脚本结束
- 无论执行成功还是失败,都在
finally块中调用release_lock,确保计数器准确。
- 无论执行成功还是失败,都在
-
并发安全性
- Redis 操作是原子性的,确保多个脚本同时运行时,计数器不会出现竞争问题。
我提供一个实例代码,当然,你需要了解原理后自己写一个定制化功能
import redis
import time
import subprocess
# 配置 Redis
redis_key = "dump_task_count"
MAX_CONCURRENT_TASKS = 5
TIMEOUT_THRESHOLD = 300 # 超时时间(秒)
# 初始化 Redis 客户端
redis_client = redis.StrictRedis(decode_responses=True)
def acquire_lock():
"""尝试获取执行权限并记录开始时间"""
task_data = redis_client.get(redis_key)
if task_data:
current_count, start_time = map(int, task_data.split(":"))
else:
current_count, start_time = 0, 0
if current_count < MAX_CONCURRENT_TASKS:
# 更新计数器和开始时间
redis_client.set(redis_key, f"{current_count + 1}:{int(time.time())}")
return True
return False
def release_lock():
"""释放执行权限并检查是否超时"""
task_data = redis_client.get(redis_key)
if not task_data:
return # 没有记录,无需释放
current_count, start_time = map(int, task_data.split(":"))
current_time = int(time.time())
if current_count > 0:
redis_client.set(redis_key, f"{current_count - 1}:{start_time}")
# 检查是否超时
if current_time - start_time > TIMEOUT_THRESHOLD:
print(f"ALERT: Task exceeded timeout threshold! Execution time: {current_time - start_time} seconds.")
def run_dump_command(command):
"""执行 dump 脚本并控制并发"""
if not acquire_lock():
print(f"Max concurrent tasks reached. Skipping: {command}")
return False
try:
print(f"Executing: {command}")
subprocess.run(command, shell=True, check=True)
print(f"Completed: {command}")
except subprocess.CalledProcessError as e:
print(f"Error occurred: {e}")
finally:
release_lock() # 无论成功或失败都释放锁
return True
# 示例 dump 命令
dump_commands = [
"mysqldump -h host1 -u user -p'password' db1 > dump1.sql",
"mysqldump -h host2 -u user -p'password' db2 > dump2.sql",
"mysqldump -h host3 -u user -p'password' db3 > dump3.sql",
"mysqldump -h host4 -u user -p'password' db4 > dump4.sql",
"mysqldump -h host5 -u user -p'password' db5 > dump5.sql",
"mysqldump -h host6 -u user -p'password' db6 > dump6.sql"
]
# 执行 dump 脚本
for command in dump_commands:
run_dump_command(command)
在第一二阶段时,并发控制可以显著提高效率,但是请你注意DB配置,如果并发太高,DB很可能扛不住挂掉,上线前请做压测。
但是在三阶段方案,只有控制并发就不够了,因为这个阶段需要处理所有订单,每个服务实例必须知道自己需要处理哪部分订单
订单分配
一致性哈希不想过多介绍,可以处理这种场景,还可以载流量徒增的时候动态调整。
在本问题中:
- 数据分布:通过一致性哈希,将订单按照
order_id分配到不同的处理节点(机器)。 - 并发处理:每个节点负责处理自己分配的订单,独立完成补填并写入新表,减少单点压力。
示例代码:
import hashlib
from collections import defaultdict
# 模拟节点列表
nodes = ["Machine-1", "Machine-2", "Machine-3", "Machine-4"]
# 模拟数据表中订单ID
orders = [1001, 1002, 1003, 1004, 2001, 2002, 2003, 3001, 4001, 5001]
def consistent_hash(key, node_list):
"""基于一致性哈希将key分配到某个节点"""
hash_value = int(hashlib.md5(str(key).encode()).hexdigest(), 16)
index = hash_value % len(node_list)
return node_list[index]
# 将订单分配到节点
node_to_orders = defaultdict(list)
for order_id in orders:
assigned_node = consistent_hash(order_id, nodes)
node_to_orders[assigned_node].append(order_id)
# 输出分配结果
for node, assigned_orders in node_to_orders.items():
print(f"{node} handles orders: {assigned_orders}")
懒人版本
当然,这种方法稍微有些复杂,有些同学比较笨或懒,也不要求动态配置,那再写个简单版本,读配置获知自己的机器需要处理0-9结尾的哪些订单,然后处理
# 配置:当前机器负责的订单尾号
MY_TAILS = {0, 1, 2} # 假设当前机器负责尾号为0, 1, 2的订单
# 模拟数据表中的订单ID
orders = [1001, 1002, 1003, 1004, 2001, 2002, 2003, 3001, 4001, 5001]
def filter_orders_by_tail(orders, tails):
"""根据尾号筛选属于当前机器的订单"""
return [order for order in orders if order % 10 in tails]
def process_order(order_id):
"""处理订单逻辑"""
print(f"Processing order: {order_id}")
# 筛选当前机器需要处理的订单
my_orders = filter_orders_by_tail(orders, MY_TAILS)
# 处理订单
for order in my_orders:
process_order(order)
十一、正确性的保证
性能问题解决后,上报的数据有没有漏报错报也非常重要,关系着交易链路权限是否会被收回。
1. 字段完整性与格式校验
- 字段完整性:
- 检查所有必填字段是否有值,例如
ORDER_ID、SOURCE_ORDER_ID、TRADE_ID等关键字段。
- 检查所有必填字段是否有值,例如
- 字段格式:
- 校验字段格式是否正确,例如:
ORDER_ID:符合指定长度与字符规则。- 日期字段:格式应为
YYYY-MM-DD HH:MM:SS。 - 数值字段:是否为正数,且精度符合预期(如价格精确到小数点后两位)。
- 校验字段格式是否正确,例如:
2. 同一订单的多条记录先后关系校验
多条记录的时间先后关系是必检内容,需确保满足以下逻辑:
- O.RO 依赖 O.NO:
- 报单响应(
O.RO)必须在报单创建(O.NO)之后。
- 报单响应(
- T 依赖 O.RO:
- 成交(
T)必须在报单响应(O.RO)之后。
- 成交(
- A.RJ 依赖 O.NO:
- 拒绝操作(
A.RJ)必须在报单创建(O.NO)之后。
- 拒绝操作(
- A.C 依赖 O.NO:
- 取消操作(
A.C)必须在报单创建(O.NO)之后。
- 取消操作(
- M 依赖 T:
- 成交修改(
M)必须发生在成交(T)之后。
- 成交修改(
实现方式:
- 按
ORDER_ID对记录排序,并逐条检查时间戳是否符合上述规则。 - 标记不满足时间顺序的记录,供进一步分析。
3. SOURCE_ORDER_ID 校验
- 有效性校验:
SOURCE_ORDER_ID必须存在并有效,关联的上游订单必须能够在系统中找到。
- 正确性校验:
- 确认
SOURCE_ORDER_ID对应的订单状态是否合理,如订单被取消或已完成的情况下不应再出现新的成交记录。
- 确认
4. Overfill(超量成交)校验
- 定义:
- 单个订单的成交量总和不应超过订单的委托量。
- 校验方式:
- 对每个
ORDER_ID汇总成交量,检查是否超出ORDER_QTY(委托量)。
- 对每个
SELECT ORDER_ID, SUM(TRADE_QTY) AS TOTAL_QTY, ORDER_QTY
FROM trade_table
GROUP BY ORDER_ID HAVING TOTAL_QTY > ORDER_QTY;5. 数据统计与汇总校验
对报表的核心统计数据进行汇总校验,确保整体一致性:
- 总成交额:
- 计算所有成交记录的总成交金额(
SUM(TRADE_QTY * TRADE_PRICE)),与外部对账系统的数据对比。
- 计算所有成交记录的总成交金额(
- 总成交股数:
- 汇总所有成交记录的股数(
SUM(TRADE_QTY))。
- 汇总所有成交记录的股数(
- 总成交笔数:
- 统计成交记录的总条数。
- 总订单数量:
- 统计订单记录的总条数,与委托数量对比,确保订单未丢失。
6. 数据关联性校验
- 跨表校验:
- 确保订单、成交、修改记录间的关联关系正确。例如:
TRADE_ID必须关联到有效的ORDER_ID。- 修改记录的
PARENT_ID必须能匹配到上游订单或成交记录。
- 确保订单、成交、修改记录间的关联关系正确。例如:
- 引用关系检查:
- 确认所有引用的 ID(如
PARENT_ORDER_ID)是否存在并有效。
- 确认所有引用的 ID(如
7. 状态流转校验
- 状态变化合理性:
- 确保订单状态的流转符合业务逻辑。例如:
NEW -> PARTIAL_FILL -> FILLED -> COMPLETED- 状态不能逆流(如
FILLED后又变为PARTIAL_FILL)。
- 确保订单状态的流转符合业务逻辑。例如:
- 最终状态检查:
- 确认所有订单的状态都能流转到合理的终态(如
COMPLETED或CANCELED)。
- 确认所有订单的状态都能流转到合理的终态(如
8. 重复数据校验
- 订单重复:
- 检查
ORDER_ID是否重复,确保同一订单号不出现多条重复的报单记录。
- 检查
- 成交重复:
- 检查
TRADE_ID是否重复,避免同一成交记录被多次写入。
- 检查
9. 数据异常校验
- 空值校验:
- 确保关键字段无空值,例如
ORDER_ID、TRADE_ID、TRADE_QTY等。
- 确保关键字段无空值,例如
- 异常值校验:
- 确保成交量、成交金额为正值,不存在负数或异常数据。
- 逻辑校验:
- 确保成交量与价格的乘积等于成交金额(精度误差除外)。
10. 对账结果记录
- 生成对账报告:
- 将所有校验结果记录在对账报告中,包括:
- 每项校验的通过与失败情况。
- 错误记录的详细信息(如订单号、错误类型、字段值)。
- 将所有校验结果记录在对账报告中,包括:
- 自动告警:
- 对严重错误(如漏报、错报)触发告警,通知相关人员及时处理。
通过以上对账逻辑,可以有效发现报表生成中的数据异常和业务逻辑问题,确保数据的完整性和准确性。当然,这些也就是我的一家之言,还有很多不完善的地方,请你根据自己的业务来增删改查规则。
十二、Q&A
我还是不知道分段是怎么分的,文章在这一块提的不多。
# 调用主脚本,每30分钟运行一次,覆盖盘前、盘中、盘后
0 9-23 * * * python3 report_pipeline.py --start_time "$(date -d '30 minutes ago' '+%Y-%m-%d %H:%M:00')" --end_time "$(date '+%Y-%m-%d %H:%M:00')"
30 9-22 * * * python3 report_pipeline.py --start_time "$(date -d '30 minutes ago' '+%Y-%m-%d %H:%M:00')" --end_time "$(date '+%Y-%m-%d %H:%M:00')"假设 report_pipeline.py 包含以下功能:
- 数据 dump:从数据库中按时间段导出原始数据。
- 数据汇聚:处理数据,按订单维度补充信息。
- 报表生成:从汇聚表中读取数据并生成报表文件。
每次调用脚本时,将基于 --start_time 和 --end_time 参数处理对应时间段的数据。
脚本运行时间表(UTC)
| 时间点 | 说明 |
|---|---|
| 09:00 | 处理盘前的第一段数据 |
| 09:30 | 处理盘前的下一段数据 |
| ... | |
| 14:30 | 开始处理盘中数据 |
| 21:00 | 开始处理盘后数据 |
| 23:30 | 处理最后一段盘后数据 |
我按你说的写完了,并发和订单分配也实现了,但还是觉得慢?
那你要看看报表mysql九大优化:
1. 找出慢查询并优化
- 启用慢查询日志:
- 通过 MySQL 配置文件开启慢查询日志,记录执行时间超过阈值的 SQL 语句。
- 配置示例:
slow_query_log = 1 slow_query_log_file = /var/log/mysql/slow.log long_query_time = 1 # 设置为1秒以上的查询记录为慢查询
- 分析日志:
- 使用工具分析慢查询日志,如
mysqldumpslow或pt-query-digest,找出执行频繁或耗时长的查询语句。
- 使用工具分析慢查询日志,如
- 优化查询:
- 添加必要的索引。
- 使用覆盖索引(
EXPLAIN分析查询计划,确保查询只读索引而不访问数据行)。 - 避免 SELECT *,只查询必要的字段。
2. 使用连接池
- 问题:
- 每次查询建立和断开数据库连接都会产生较大的开销。
- 优化:
- 在应用层使用数据库连接池(如 Python 的
SQLAlchemy、Java 的 HikariCP),复用连接,减少连接建立的时间。
- 在应用层使用数据库连接池(如 Python 的
3. 减少磁盘 IO
-
优化存储引擎:
- 如果写入频繁但无需支持事务,可以选择
MyISAM,其性能在某些场景下优于InnoDB。 - 如果需要事务支持,确保
InnoDB的innodb_buffer_pool_size足够大,以减少磁盘 IO。SET GLOBAL innodb_buffer_pool_size = 1G; -- 根据内存大小调整
- 如果写入频繁但无需支持事务,可以选择
-
启用查询缓存:
- 如果相同的查询重复执行,可以启用查询缓存(适用于读多写少的场景)。
query_cache_type = 1 query_cache_size = 64M - 注意:MySQL 8.0 后已移除查询缓存,可以使用应用层缓存代替(如 Redis)。
- 如果相同的查询重复执行,可以启用查询缓存(适用于读多写少的场景)。
4. 使用分批查询
- 问题:
- 一次性处理大量数据可能导致内存溢出或阻塞。
- 优化:
- 将大查询拆分为多次小批量查询,每次处理固定数量的行。例如:
SELECT * FROM orders LIMIT 0, 1000; SELECT * FROM orders LIMIT 1000, 1000;
- 将大查询拆分为多次小批量查询,每次处理固定数量的行。例如:
5. 避免不必要的写操作
- 批量写入:
- 将多条写操作合并为一次批量插入,提高写入效率。
INSERT INTO report_table (col1, col2) VALUES (1, 'a'), (2, 'b'), (3, 'c');
- 将多条写操作合并为一次批量插入,提高写入效率。
- 延迟索引更新:
- 在大批量插入数据时,先禁用索引,插入完成后再重建索引:
ALTER TABLE table_name DISABLE KEYS; -- 批量插入 ALTER TABLE table_name ENABLE KEYS;
- 在大批量插入数据时,先禁用索引,插入完成后再重建索引:
6. 使用表分区和分表
- 问题:
- 数据量过大时,单表性能会下降。
- 优化:
- 根据时间、订单 ID 等字段将表分区或分表:
CREATE TABLE orders_2024_01 PARTITION BY RANGE (order_date) ( PARTITION p1 VALUES LESS THAN ('2024-02-01') );
- 根据时间、订单 ID 等字段将表分区或分表:
- 应用层分表:
- 在应用程序中,根据某些规则(如订单尾号)将数据分布到多个表或数据库。
7. 使用只读副本
- 问题:
- 频繁的读写竞争会导致性能下降。
- 优化:
- 设置 MySQL 主从复制,主库专注写入,从库分担读取压力。
- 主库写入,报表服务从从库读取数据。
- 使用工具如
ProxySQL或MySQL Router动态分配读写请求。
- 设置 MySQL 主从复制,主库专注写入,从库分担读取压力。
8. 定期清理和优化表
- 清理过期数据:
- 定期清理不再需要的历史数据,减少表的体积和查询开销。
DELETE FROM orders WHERE order_date < '2023-01-01';
- 定期清理不再需要的历史数据,减少表的体积和查询开销。
- 优化表结构:
- 执行
OPTIMIZE TABLE回收磁盘空间并整理表碎片:OPTIMIZE TABLE table_name;
- 执行
9. 减少锁争用
- 问题:
- 高并发写入容易引发锁争用,阻塞查询。
- 优化:
- 将大事务拆分为小事务,减少锁定范围:
BEGIN; UPDATE table_name SET col = val WHERE id = 1; COMMIT;
- 将大事务拆分为小事务,减少锁定范围:
觉得整篇看下来好像不是很难,难点在哪?
那你挺厉害的,这里主要是初始设计思路、运维、细节的把控、性能的优化、正确性的保证等。
如果你觉得都理解了,恭喜你,你的技术挺好的。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 124
124 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)