数据挖掘---支持向量机(SVM)
•1.SVM的基本思想:•SVM把分类问题转换成寻求分类平面的问题,并通过最大化分类边界点到分类平面的距离来实现分类。通俗的讲支持向量机的解决的问题是找到最好的分类超平面。支持向量机(Supportvector machine)通常用来解决二分类问题2.构造目标函数类似于点到直线的距离,可以得到点到超平面的距离为•在Logisti...
•1.SVM 的基本思想:
•SVM把分类问题转换成寻求分类平面的问题,并通过最大化分类边界点到分类平面的距离来实现分类。通俗的讲支持向量机的解决的问题是找到最好的分类超平面。支持向量机(Support vector machine)通常用来解决二分类问题
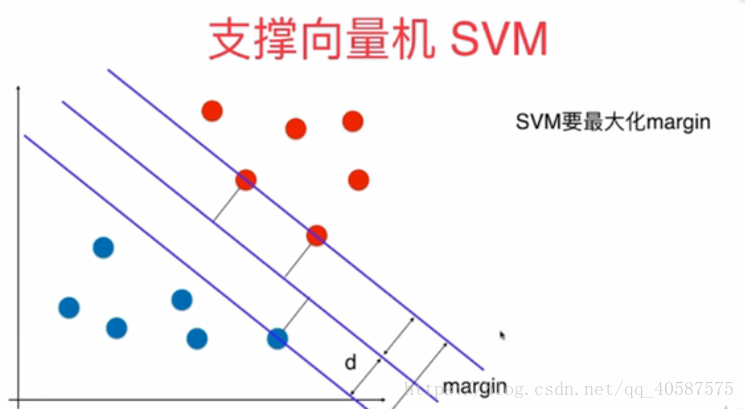
2.构造目标函数
类似于点到直线的距离,可以得到点到超平面的距离为

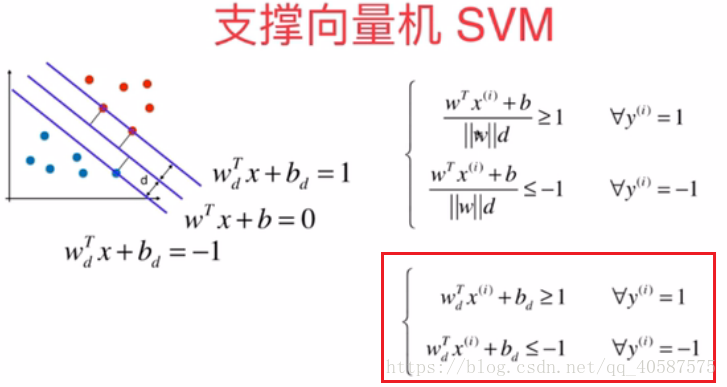
•在Logistic回归算法,我们是把数据分成0类和 1 类,而同样为了推导式子的方便性,采用-1 和 1 两类。
可以将红色框的式子转换成:

•目标方程:

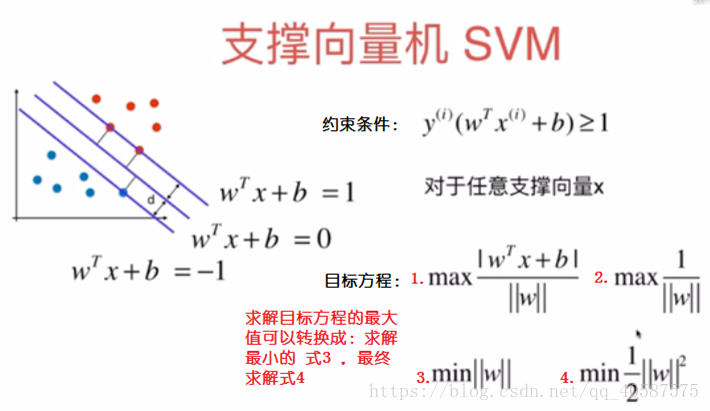
我们需要求的是:两数据集中几个数据最近的点的最大的距离。
在满足约束条件(即样本点为支持向量)下,最大的几何间隔中取最小的值。max L(w,b,a) 是得到支持向量的样本点,然后再这些样本点中找到min 1/2 || w ||2 的最小值(最大间隔)。
•可以得到有条件约束的最优化问题,通常引入拉格朗日函数简化上述问题,称此类问题为对偶问题(The wolfe dualproblem)。
•使用拉格朗日乘数法用来解决等式约束下的最优化问题:

•对偶问题的求解:
•步骤1 :固定 α ,然后L(ω, b, α)对 ω 、b 求偏导,令其偏导数等于0。

•把上述2式带入到L(ω, b, α)当中:

•步骤2 :对 α 求极大,通过步骤1 已经把变量 ω 、b 消去,函数只有 α。
•在式子前面加个 - 负号,是求极大值转换成求极小值:
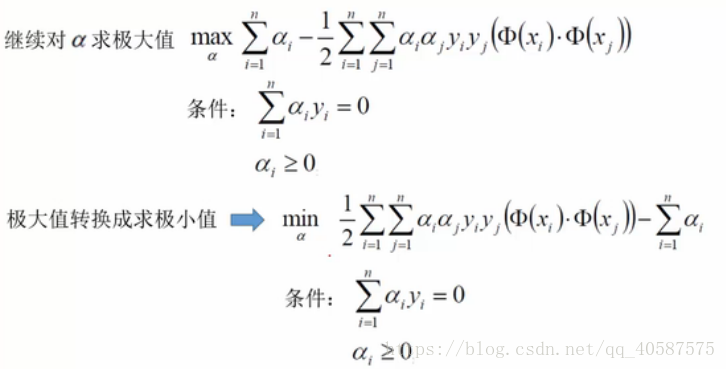
线性可分SVM算法过程:
输入是线性可分的m个样本 其中 x 为 n 维特征向量。y 为二元输出,值为 1,或者 -1。
其中 x 为 n 维特征向量。y 为二元输出,值为 1,或者 -1。
输出是分离超平面的参数 ,
,  和分类决策函数。
和分类决策函数。
算法过程如下:
1)构造约束优化问题:



结合:
2)用SMO算法求出上式最小时对应的α 向量的值α∗ 向量.
3) 计算 
4) 找出所有的S个支持向量,即满足 对应的样本(
对应的样本( ), 通过
), 通过 计算出每个支持向量 对应的
计算出每个支持向量 对应的 ,计算出这些
,计算出这些 ,
,
所有的 对应的平均值即为最终的 
但是,线性可分SVM的学习方法对于非线性的数据集是无法使用的。
from:刘建平blog
3.软间隔
如果存在噪声的话,会影响模型的泛化能力。
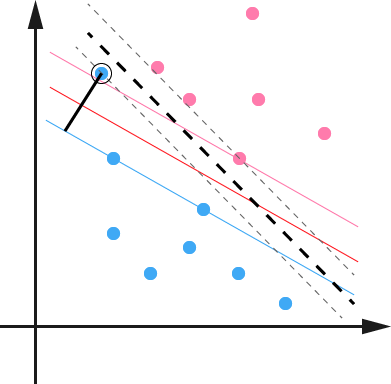
•实际遇到的问题数据总是有噪音的,也就是说可能存在一两个可忽略的特殊点使margin大大减小,也可能有一两个特殊点导致集合线性不可分(如下图),所以我们需要允许模型犯一定的错误来过滤掉噪音,即允许间隔的调整称为软间隔。

这里,C>0 为惩罚参数,可以理解为我们一般回归和分类问题正则化时候的参数。C越大,对误分类的惩罚越大,C 越小,对误分类的惩罚越小。C 是协调两者关系的正则化惩罚系数。在实际应用中,需要调参来选择。

这个式子和我们线性可分SVM相同,唯一不同的是约束条件。我们依然可以通过SMO算法来求上式极小化时对应的α 向量就可以求出 w 和 b 。

对于SVM线性不可分的低维特征数据,我们可以将其映射到高维,就能线性可分
•4.核函数kernel
(多项式核函数)(高斯核函数计算花销大:gamma越大会形成过拟合,越小则会欠拟合)(升维)
•设χ是输入空间(欧氏空间或离散集合),Η为特征空间(希尔伯特空间),如果存在一个从χ到Η的映射
•φ(x):χ→Η
那么如果存在函数  ,对于任意
,对于任意  ,都有:
,都有:

则称 为核函数,φ(x)为映射函数,φ(x)∙φ(z)为x,z映射到特征空间上的内积。
我们遇到线性不可分的样例时,常用做法是把样例特征映射到高维空间中去, 但是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到令人恐怖的。此时,核函数就体现出它的价值了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数好在它在低维上进行计算,而将实质上的分类效果(利用了内积)表现在了高维上,这样避免了直接在高维空间中的复杂计算,真正解决了SVM线性不可分的问题。

scikit-learn中默认可选的就是下面几个核函数:
1.线性核函数(Linear Kernel )
2.多项式核函数(Polynomial Kernel)是线性不可分SVM常用的核函数之一,表达式为:

其中  都是要调参的
都是要调参的
3. 高斯核函数(Gaussian Kernel),在SVM中也称为径向基核函数(Radial Basis Function,RBF),它是非线性分类SVM最主流的核函数。libsvm默认的核函数就是它。表达式为:

其中  需要调参
需要调参
4.Sigmoid核函数(Sigmoid Kernel)也是线性不可分SVM常用的核函数之一,表达式为:
其中  需要调参
需要调参
结合软间隔和核函数 , 所以算法第一步应该为:
1)选择适当的核函数 和一个惩罚系数C>0 , 构造约束优化问题


2)用SMO算法求出上式最小时对应的α 向量的值α∗ 向量.

5.SMO(Sequential Minimal Optimization, 序列最小优化)算法解析:
SVM,有许多种实现方式,SMO算法实现是一种。
1998年,由Platt提出的序列最小最优化算法(SMO)可以高效的求解上述SVM问题,它把原始求解N个参数二次规划问题分解成很多个子二次规划问题分别求解,每个子问题只需要求解2个参数,方法类似于坐标上升,节省时间成本和降低了内存需求。每次启发式选择两个变量进行优化,不断循环,直到达到函数最优值。

6.支持向量机的参数解析,SVC
from sklearn.svm import SVC
SVC(C, kernel, degree, gamma, coef0, shrinking, probability, tol, cache_size, class_weight, verbose,
max_iter, decision_function_shape, random_state)
- C : 错误项的惩罚系数,C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,易于过拟合
kernel: str参数 默认为‘rbf’
算法中采用的核函数类型,可选参数有:
‘linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:径向核函数/高斯核
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵
degree: int型参数 默认为3, 这个参数只对多项式核函数 ' poly ' 有用
gamma:float参数 默认为auto, 核函数系数,只对‘rbf’,‘poly’,‘sigmod’有效。如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features. 高斯核函数中,gamma越大,高斯分布越窄,相当于gamma=1/2 方差 ;原高斯分布 方差越大,越宽,与之相反。当gamma越大时,模型复杂度越大,倾向于过拟合;当gamma越小时,模型复杂度越小,倾向于欠拟合
coef0 : float参数 默认为0.0, 核函数中的独立项,只有对‘poly’和‘sigmod’核函数有用,是指其中的参数 c
probability:bool参数 默认为False, 是否启用概率估计。 这必须在调用fit()之前启用,并且会fit()方法速度变慢。
shrinking:bool参数 默认为True,是否采用启发式收缩方式
tol: float参数 默认为1e^-3, svm停止训练的误差精度
cache_size:float参数 默认为200,指定训练所需要的内存,以MB为单位,默认为200MB。
class_weight:字典类型或者‘balance’字符串。默认为None
给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C.
如果给定参数‘balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重。
verbose :bool参数 默认为False
是否启用详细输出。 此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它
max_iter :int参数 默认为-1
最大迭代次数,如果为-1,表示不限制
SVC 中的属性:
svc.n_support_:各类各有多少个支持向量
svc.support_:各类的支持向量在训练样本中的索引
svc.support_vectors_:各类所有的支持向量
参考:刘建平的blog

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 2
2 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)