
介绍 Apache Spark 的基本概念和在大数据分析中的应用。
1.**RDD(ResilientDistributedDataset)**:Spark的核心抽象概念,是一个只读的、容错的、分布式的数据集合,它由一系列的分区(Partitions)组成。2.**算子(Operations)**:Spark提供了多种操作,可以将RDD转换成新的RDD(如map,filter等),或者执行动作(如reduce,collect等),将计算结果返回给驱动器程序。4.*
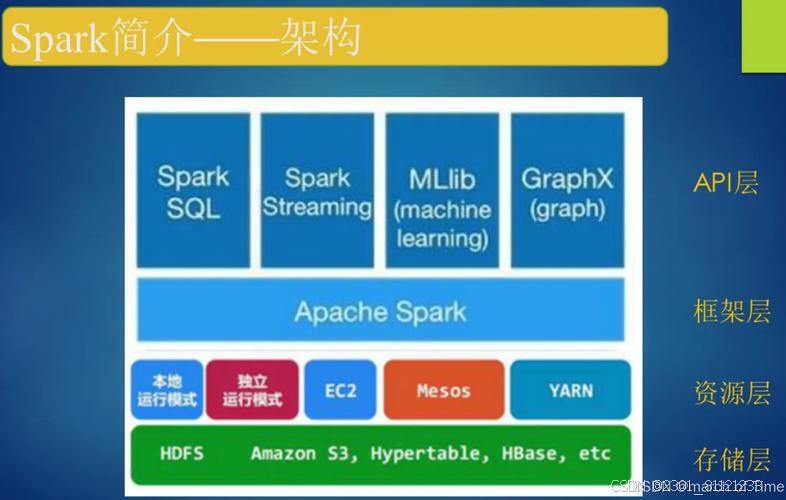
Apache Spark是一个快速、通用的大数据处理引擎。它提供了一个集群计算框架,可以高效地处理大规模数据集。Spark支持分布式数据处理,并且提供了丰富的API,可以使用多种编程语言进行开发,如Scala、Java、Python和R。
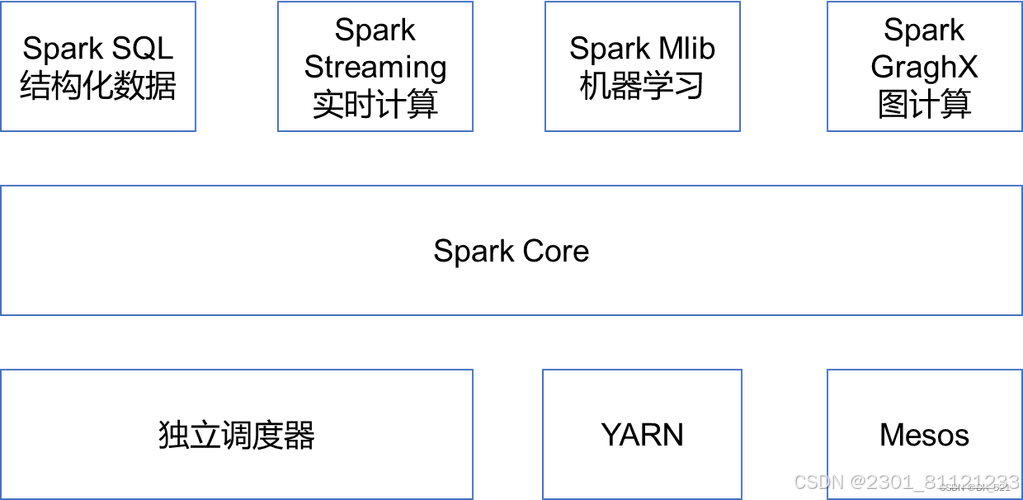
Spark的核心概念包括RDD(弹性分布式数据集)、数据流处理、机器学习库和图处理库。RDD是Spark的基本抽象,它是一个可分区和并行处理的数据集合。RDD可以被创建、转换和缓存,使得Spark可以在内存中高效地处理数据。数据流处理是Spark Streaming提供的功能,它允许实时处理流数据。Spark的机器学习库提供了一系列的算法和工具,方便用户进行机器学习模型的训练和预测。而Spark的图处理库则提供了一组用于图计算和图分析的算法。
在大数据分析中,Spark具有广泛的应用场景。首先,Spark可以处理大规模的数据集,因此在处理大数据时非常有用。其次,Spark的内存计算能力使得它比传统的批处理框架更高效。Spark还提供了丰富的数据处理和转换功能,可以通过编写简洁的代码来实现复杂的数据分析任务。此外,Spark的机器学习和图处理库也使得它在机器学习和图分析领域有强大的应用能力。
ApacheSpark是一个开源的集群计算系统,它为大规模数据处理提供了快速、与容错性强的计算能力。由加州大学伯克利分校AMP实验室开发,Spark于2010年首次发布,此后成为大数据分析领域的一个重要工具。
基本概念:
1.**RDD(ResilientDistributedDataset)**:Spark的核心抽象概念,是一个只读的、容错的、分布式的数据集合,它由一系列的分区(Partitions)组成。RDD可以分布在集群的多个节点上,并支持并行操作。
2.**算子(Operations)**:Spark提供了多种操作,可以将RDD转换成新的RDD(如map,filter等),或者执行动作(如reduce,collect等),将计算结果返回给驱动器程序。
3.**DAG(DirectedAcyclicGraph)调度器**:SparkDAG调度器可以将复杂的运算转换为有向无环图,然后分布式地执行这些运算。
4.**内存计算**:Spark的一个重要特性是它的内存计算能力,它能够在不加载整个数据集的情况下,高效地处理数据。
5.**SparkSQL**:Spark的一个模块,提供了在RDD上操作结构化数据的API,比如SQL查询。
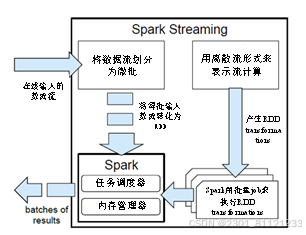
6.**SparkStreaming**:Spark的一个模块,允许用户对实时数据流进行转换和持久化。
7.**MLlib**:Spark的机器学习库,提供了一组用于机器学习的数据挖掘算法和工具。
8.**GraphX**:Spark的图形处理库,用于在图形上进行分布式计算。
在大数据分析中的应用:
1.**数据清洗与转换**:Spark可以快速完成数据的清洗、转换等预处理工作,为后续的数据分析和挖掘做准备。
2.**批量数据处理**:Spark的批处理能力非常强大,可以处理大规模数据集,如历史交易数据、用户行为日志等。
3.**实时数据分析**:SparkStreaming模块可以处理实时数据流,如社交媒体数据、金融交易数据等,并提供实时的数据分析和处理能力。
4.**机器学习与数据挖掘**:MLlib提供了丰富的机器学习算法,如分类、聚类、回归等,可以应用于推荐系统、异常检测等领域。
5.**图形分析**:GraphX可以处理大规模图形数据,如社交网络、交通网络等,进行图算法的计算。
6.**交互式数据探索**:Spark支持交互式数据探索,如通过SparkSQL进行SQL查询,快速探索数据。
Spark的这些特点和应用使其在大数据分析领域得到了广泛的应用,成为了数据科学家和工程师处理大规模数据的强大工具。
总而言之,Apache Spark是一个强大的大数据处理引擎,它提供了高效的数据处理和计算能力,并且在大数据分析中具有广泛的应用。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)