#第32篇分享:一个评分卡的数据挖掘(python语言:sklearn 逻辑回归)(8)
⑤.逻辑回归:111①算法概念Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。②.算法思路:③Logistic回归优缺点:优点:实现简单;分类时计算量非常小,速度很快,存储资源低;缺
·
#逻辑回归虽然叫回归,但他是一个二分类的算法,他的优势就是可以返回概率值,用来做银行信贷的评分卡很有好处:
'''
逻辑回归:一个二分类的算法;
对线性关系拟合的非常好;
计算非常快;
逻辑回归返回的是类概率的数字;
模型的评估指标:
混淆矩阵:metrics.confusion_matrix
roc曲线:metrics.roc_auc_score ROC曲线,横坐标:假正率,纵坐标:召回率;
精确性:metrics.accuracy_score 精确性
模型要求:损失函数最小,西塔的取值,正则化来控制过拟合的发生;
正则化:L1及 L2正则化;C是用来控制正则化的参数;默认L2
'''
1.逻辑回归:
111
①算法概念
Logistic Regression 虽然被称为回归,但其实际上是分类模型,并常用于二分类。Logistic Regression 因其简单、可并行化、可解释强深受工业界喜爱。
Logistic 回归的本质是:假设数据服从这个分布,然后使用极大似然估计做参数的估计。
②.算法思路:
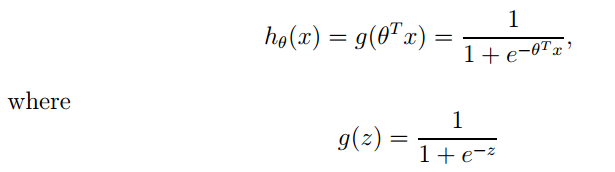

③Logistic回归优缺点:
优点:实现简单;分类时计算量非常小,速度很快,存储资源低;
缺点:
容易欠拟合,一般准确度不太高;只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分。
④.代码实例1(预测是否患上了癌症):
数据:癌症预测数据
#coding=gb2312
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import mean_squared_error,classification_report
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
def mylogis():
'''
逻辑回归:预测癌症病人的数目;主要考虑召回率。
:return: None
'''
#1.获取数据:
column = ["Sample code number","Clump Thickness"," Uniformity of Cell Size","Uniformity of Cell Shape",
"Marginal Adhesion","Single Epithelial Cell Size","Bare Nuclei","Bland Chromatin","Normal Nucleoli","Mitoses","Class"]
data = pd.read_csv("./breast-cancer-wisconsin.data",names=column)
print(data)
#对缺失值进行处理:
data = data.replace(to_replace="?",value=np.nan)
data = data.dropna()
#进行数据分割:
x_train,x_test,y_train,y_test = train_test_split(data[column[1:10]],data[column[10]],test_size=0.25)
#进行标准化处理:
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#逻辑回归预测:
#C是调整正则化强度的倒数,1是默认值,认为正则项与损失函数的比值1:1,C越小就是对损失函数的惩罚越大;
#penalty 调整正则项是l1/l2
#max_iter梯度下降求解最优解的步长
lg = LogisticRegression(C=1.0,,penalty="l2",max_iter=100)
lg.fit(x_train,y_train)
print(lg.coef_)
y_predict = lg.predict(x_test)
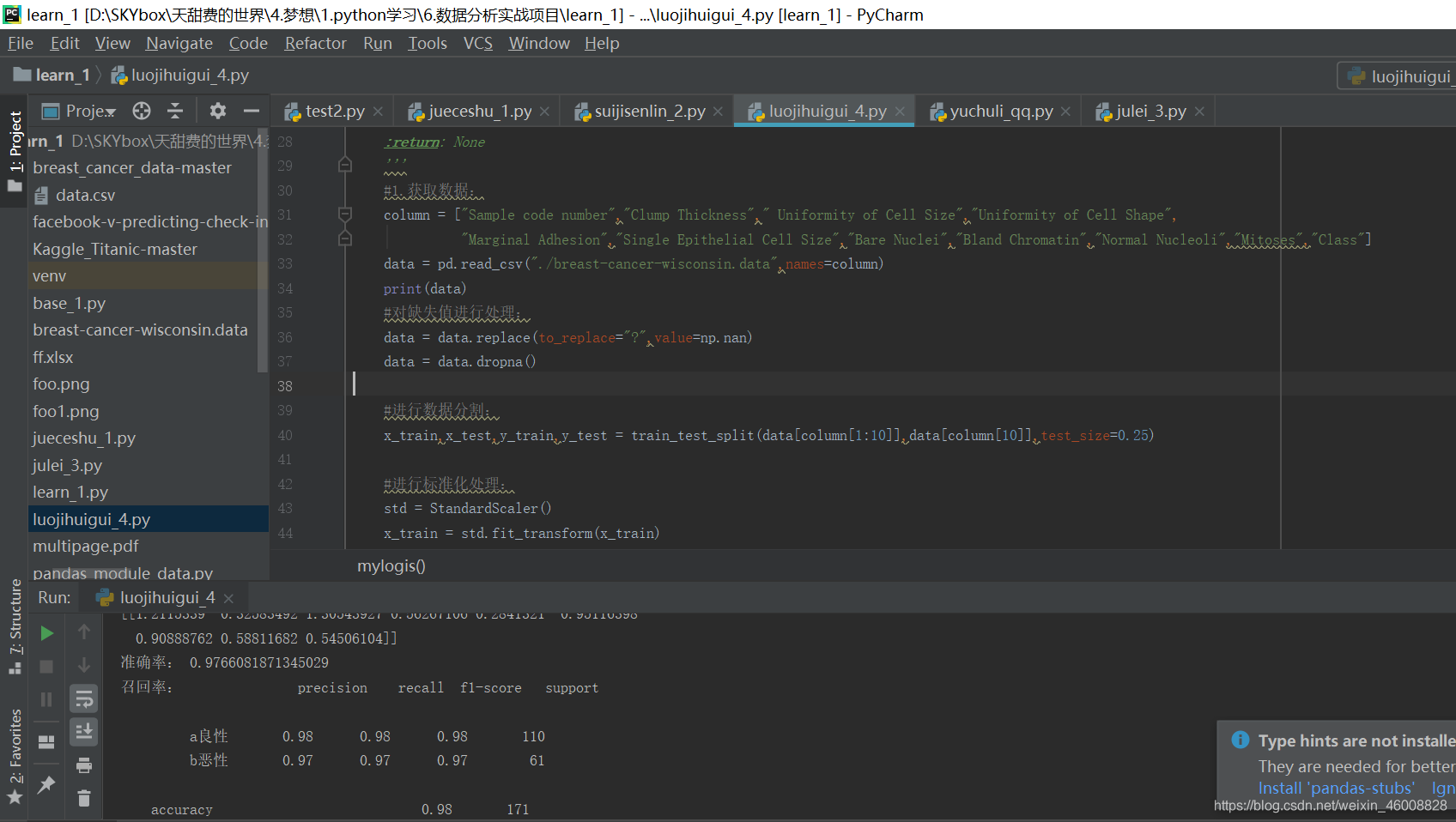
print("准确率:",lg.score(x_test,y_test))
#召回率:
print("召回率:",classification_report(y_test,y_predict,labels=[2,4],target_names=["a良性","b恶性"]))
if __name__ =="__main__":
mylogis()
结果:准确率及召回率都很高,但有时候还是要取舍,保证召回率100%:
代码实例2(银行评分卡):
拿别人的占个位置,有空自己写吧
持续更新,,,

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)