
转录组数据挖掘、生存分析、机器模型
自己领域顶刊的文献;借鉴其他领域的若数据库里面没有,可以让老师帮你挑几个通路数据集,做后续的数据挖掘nucleic acids research收录了许多GEO挖掘出的特殊通路的数据库genecards有各种各样基因的详细记录如GSVA评分不仅在转录组可以评,单细胞也可以多种聚类算法模型的作用是为了筛选基因。如图展示的流程:我们希望在TCGA里构建模型,并在其他GEO数据集中验证。为了不遇到TCG
1.前沿方向
自己领域顶刊的文献;借鉴其他领域的
若数据库里面没有,可以让老师帮你挑几个通路数据集,做后续的数据挖掘
nucleic acids research收录了许多GEO挖掘出的特殊通路的数据库
genecards有各种各样基因的详细记录

如GSVA评分不仅在转录组可以评,单细胞也可以
多种聚类算法多组学、多算法聚类神器-MOVICS - 简书
模型的作用是为了筛选基因。如图展示的流程:
我们希望在TCGA里构建模型,并在其他GEO数据集中验证。为了不遇到TCGA得出的基因在GEO中没有,就提前将训练集、验证集的数据整理。
单细胞数据评分
1.addmodulescore--seurat函数
2.AUCELL评分
2.机器学习
简单分为:分类/诊断模型,预后模型
分类的意义:你所要预测的结果,只有两个选项或几个选项,而不是一个连续的值。
预后模型预测的是病人的风险分数
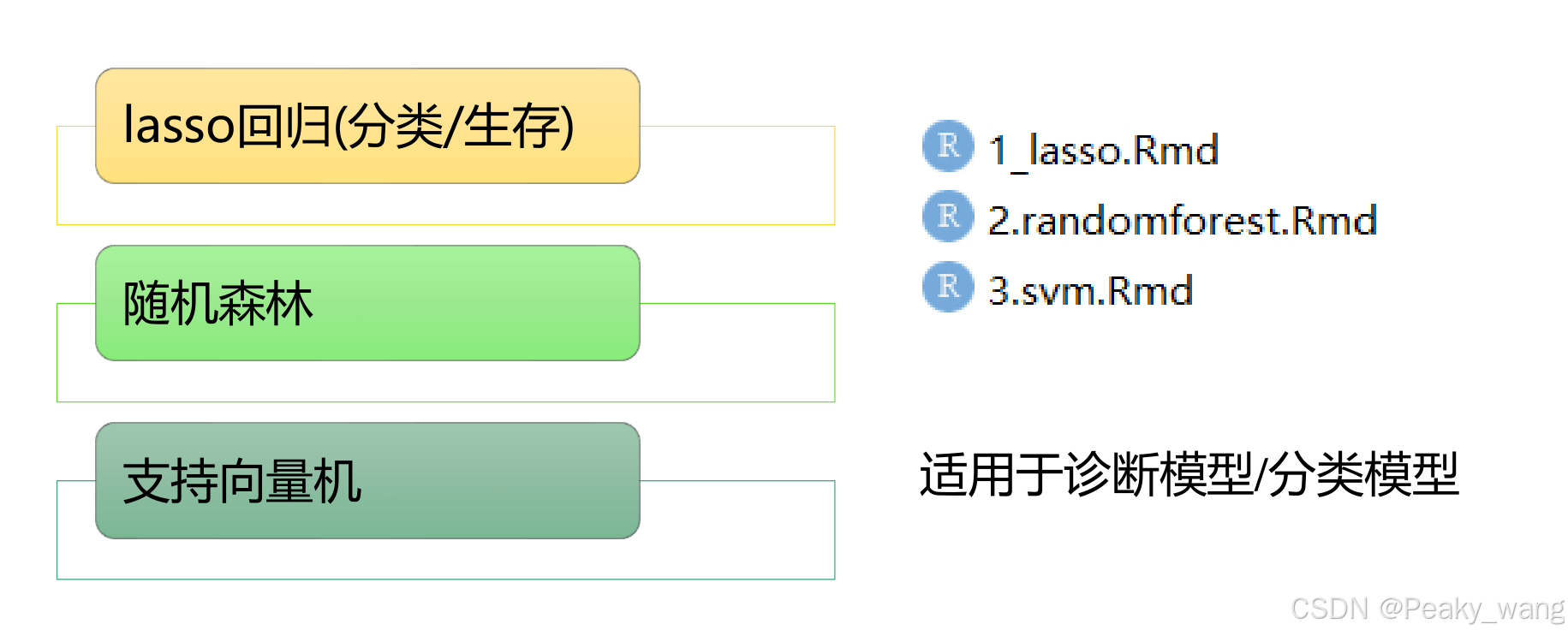
lasso回归也可以用作分类模型。回归与分类的差别之一,分类只有几个结果,而回归是你要预测的是一个连续性的值。分类模型容易得到一个好的结果,但预后模型所需的样本量很大。lasso回归可以选择特征,特征即为一条条基因。可以给重要的基因和不重要的基因分配系数,不重要的基因,其系数直接缩小为0。
训练集&测试集的划分
不能叫验证集!数据来源:可以一份数据拆分成两部分也可以两个独立的数据集
希望0,1的比例相同

lasso回归λ参数的选择
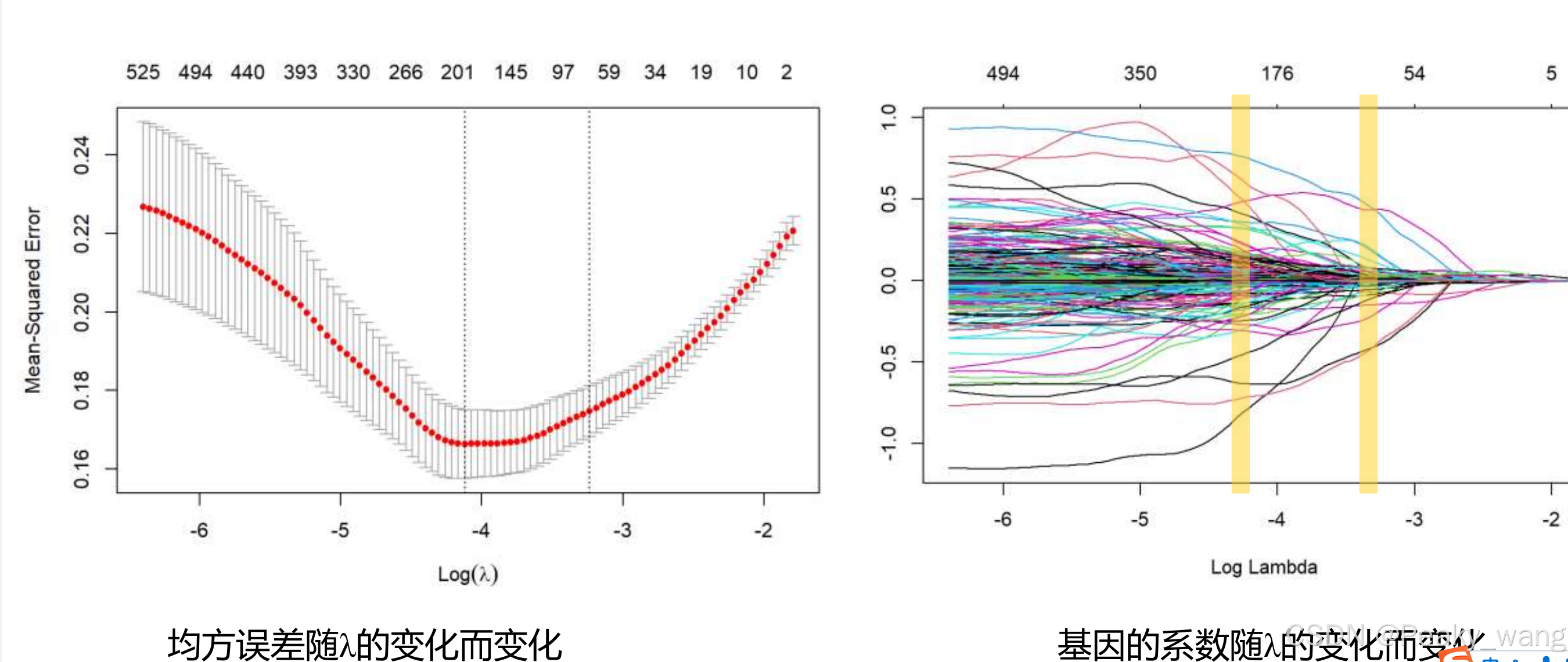
一般直接选择均方误差最小的λ。上面的数字指的是模型选择的基因数
模型好坏评价
1. predict函数检验其预测值
2. ROC曲线下面积,AUC越接近1越好

随机森林的特点
不同于lasso回归会给某些基因附0的系数,随机森林不放弃任何基因,因此可能导致过拟合。如果要筛选基因,可以根据其重要性评分,选取前30.
支持向量机的特点
predict后给出的是混淆矩阵而不是概率,因此不能画ROC曲线

3.生存分析
km plot

OS 总生存期
• 横坐标time:
• 活着的人:随访开始到最后一次随访时间
• 死了的人:随访开始到死亡时间
+表示病人到达随访时间,下降表示病人死亡,只要有分组就能画,可以是分期,可以使基因表达量。
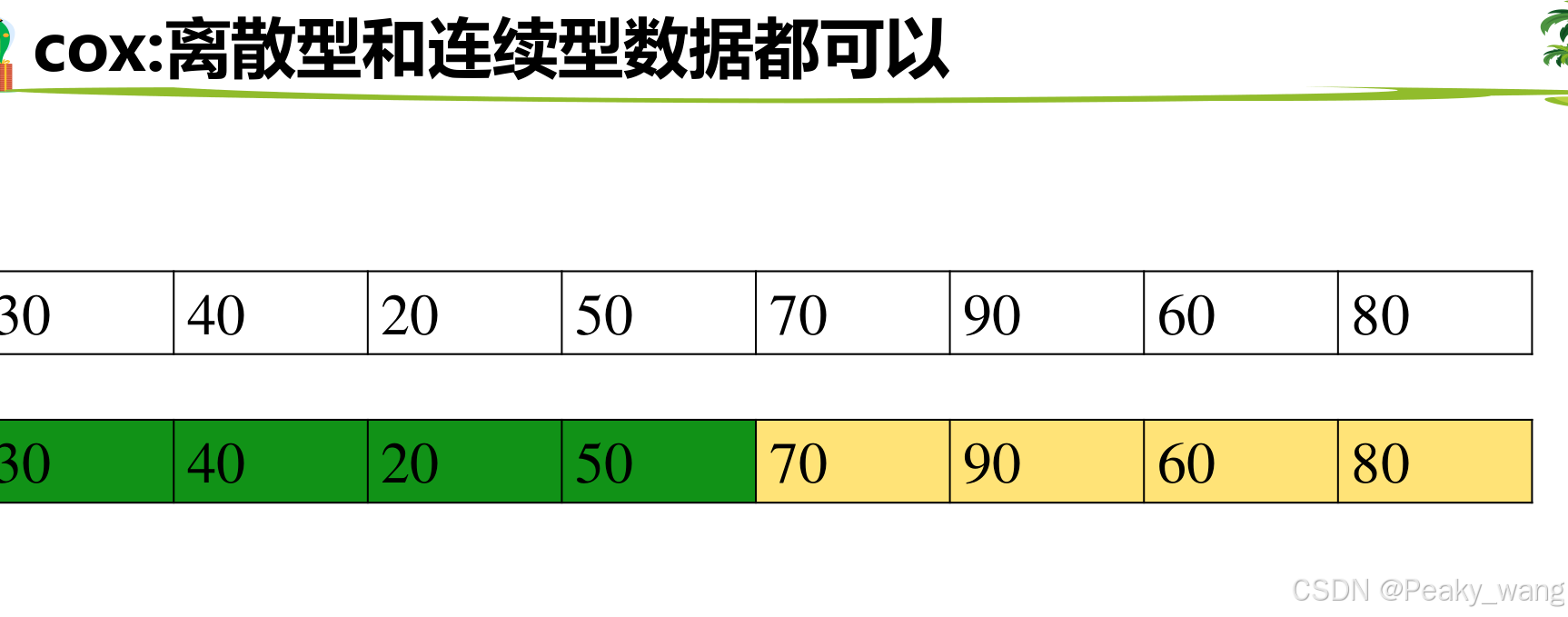
数据要求:
• 离散型的临床信息
• 连续型的临床信息-离散化(年龄)
• 基因表达量-离散化(分成高表达组,低表达组)
• Risk score –离散化(高风险组,低风险组)
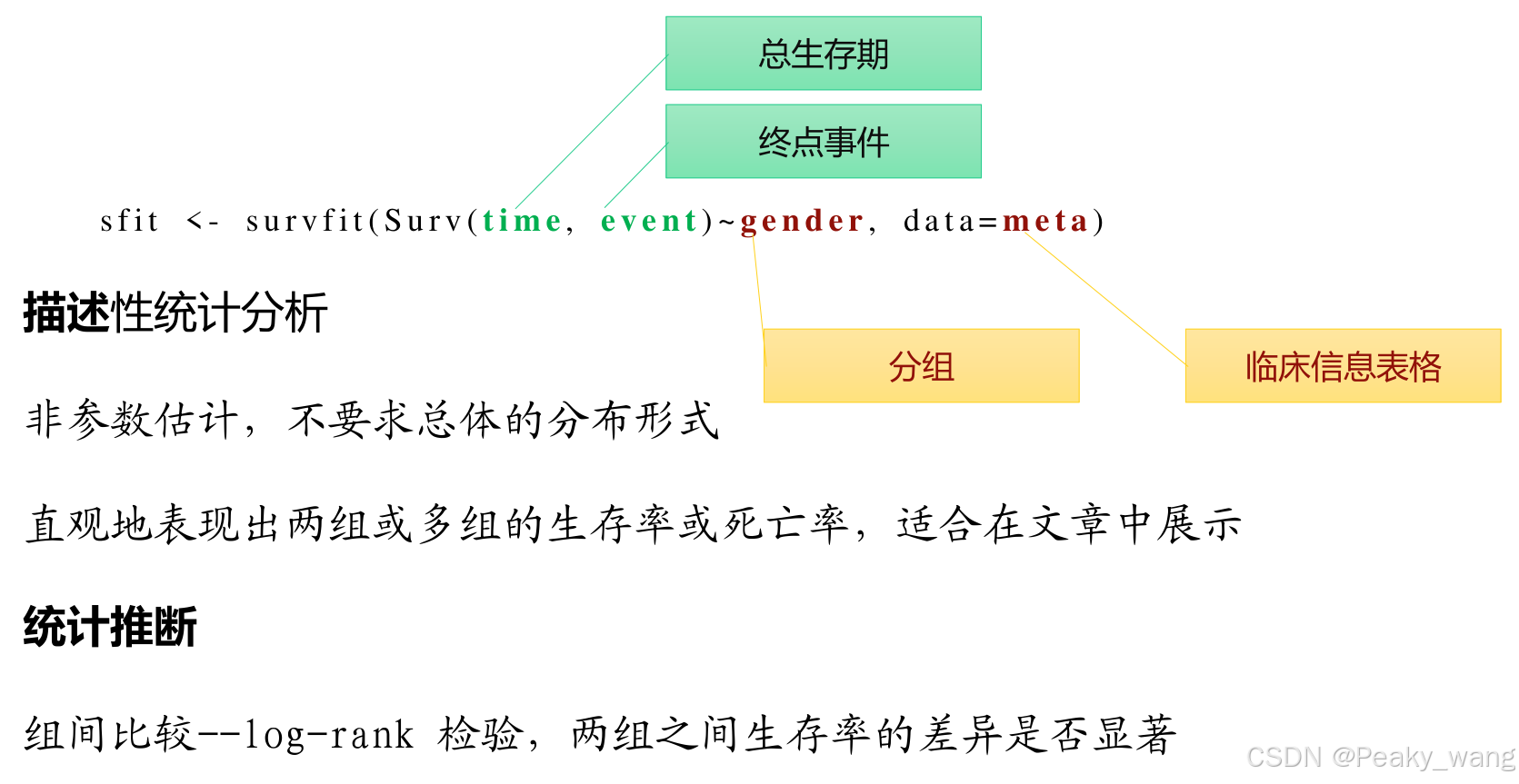
time event gender 为数据框列名
离散方法:
• 1.根据中位数截断
• 2.根据某个具体的数值截断
• 3.最佳截断值(以结果为导向)

建议对所有基因进行批量的kmplot计算

4.TCGA数据整理
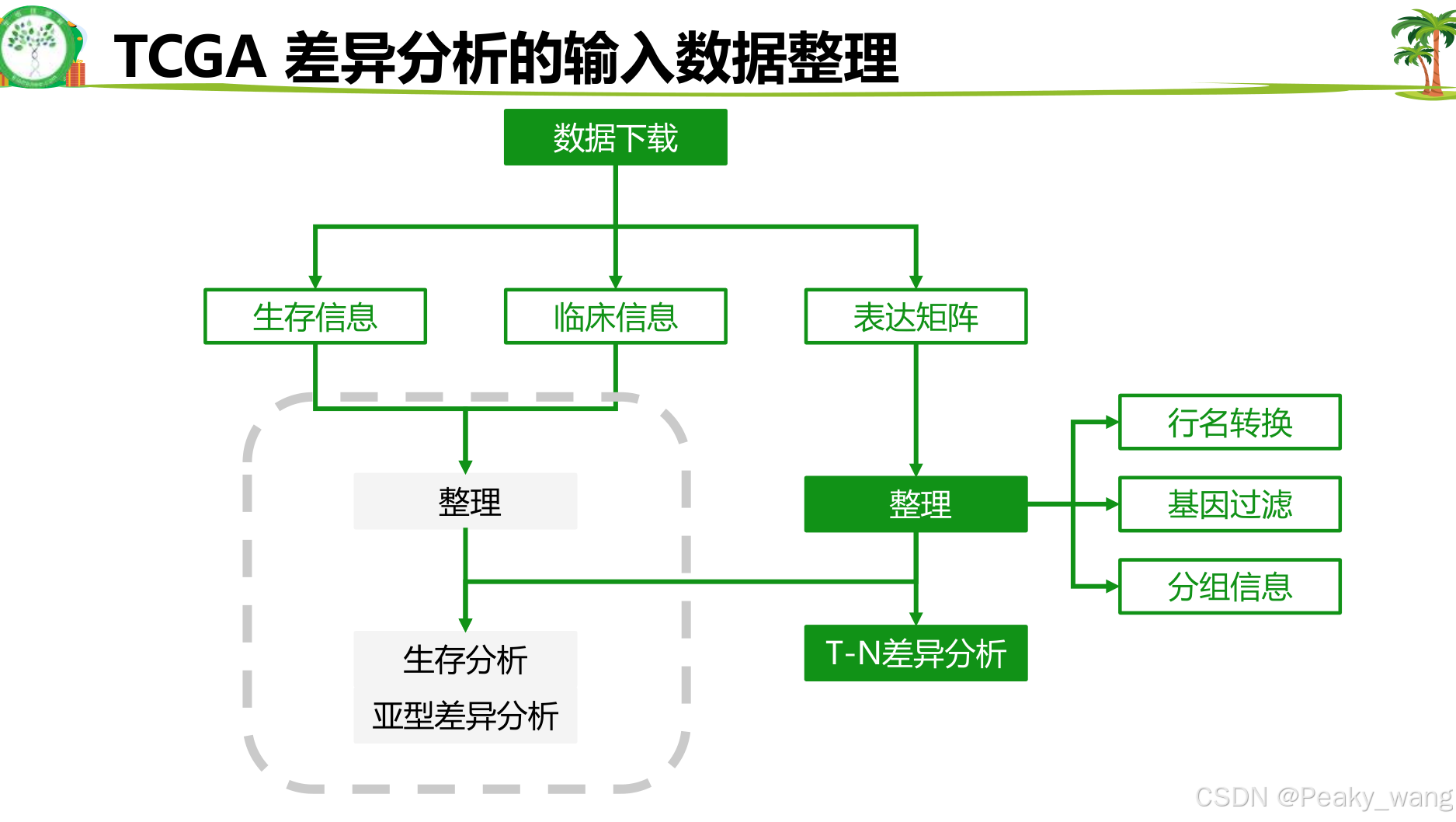
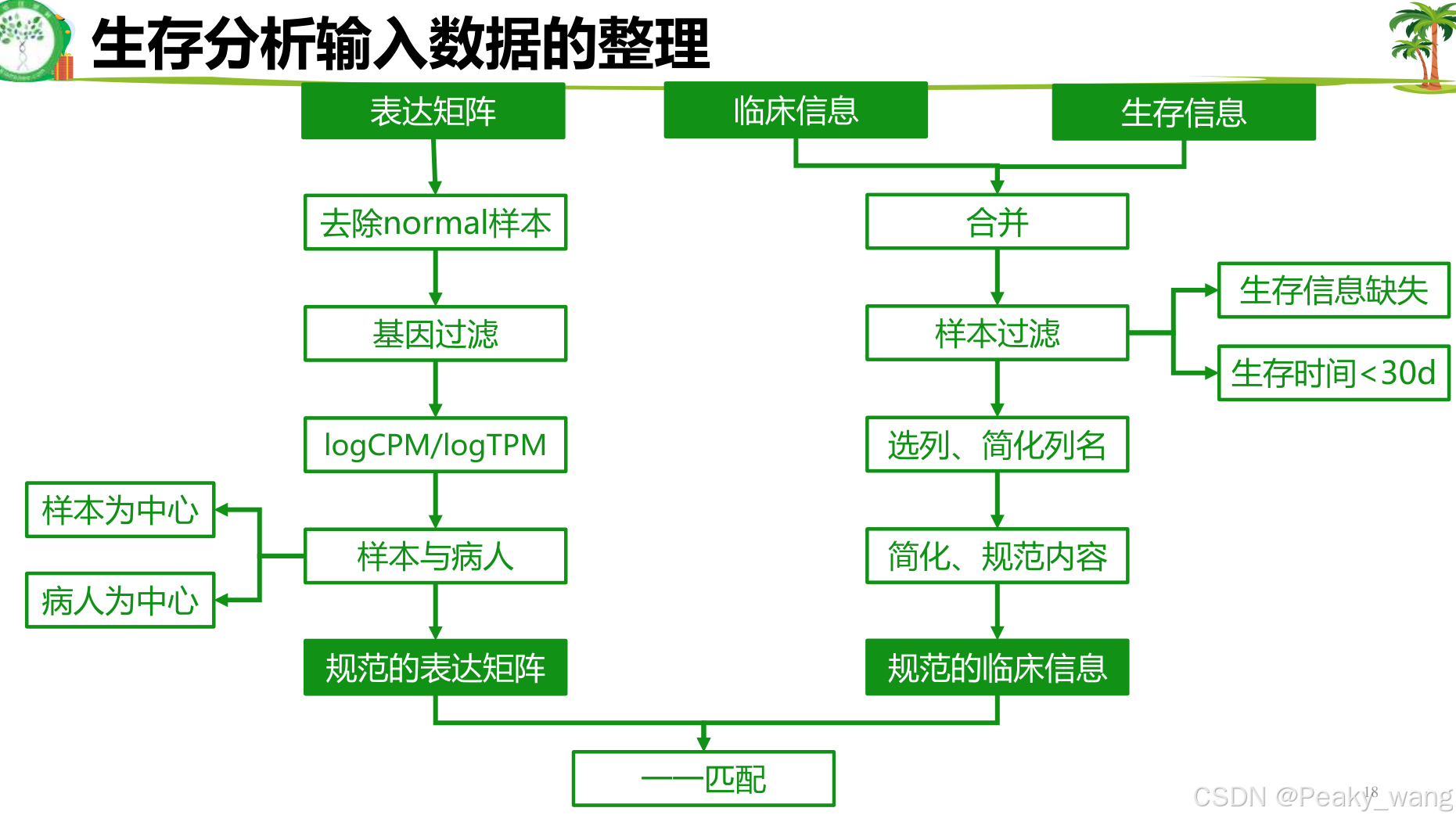
5.单因素cox回归

结果:
通过p值筛选基因,通过HR及HRCILL和HRCIUL即上下置信区间来解释基因是保护性还是危险性因素。
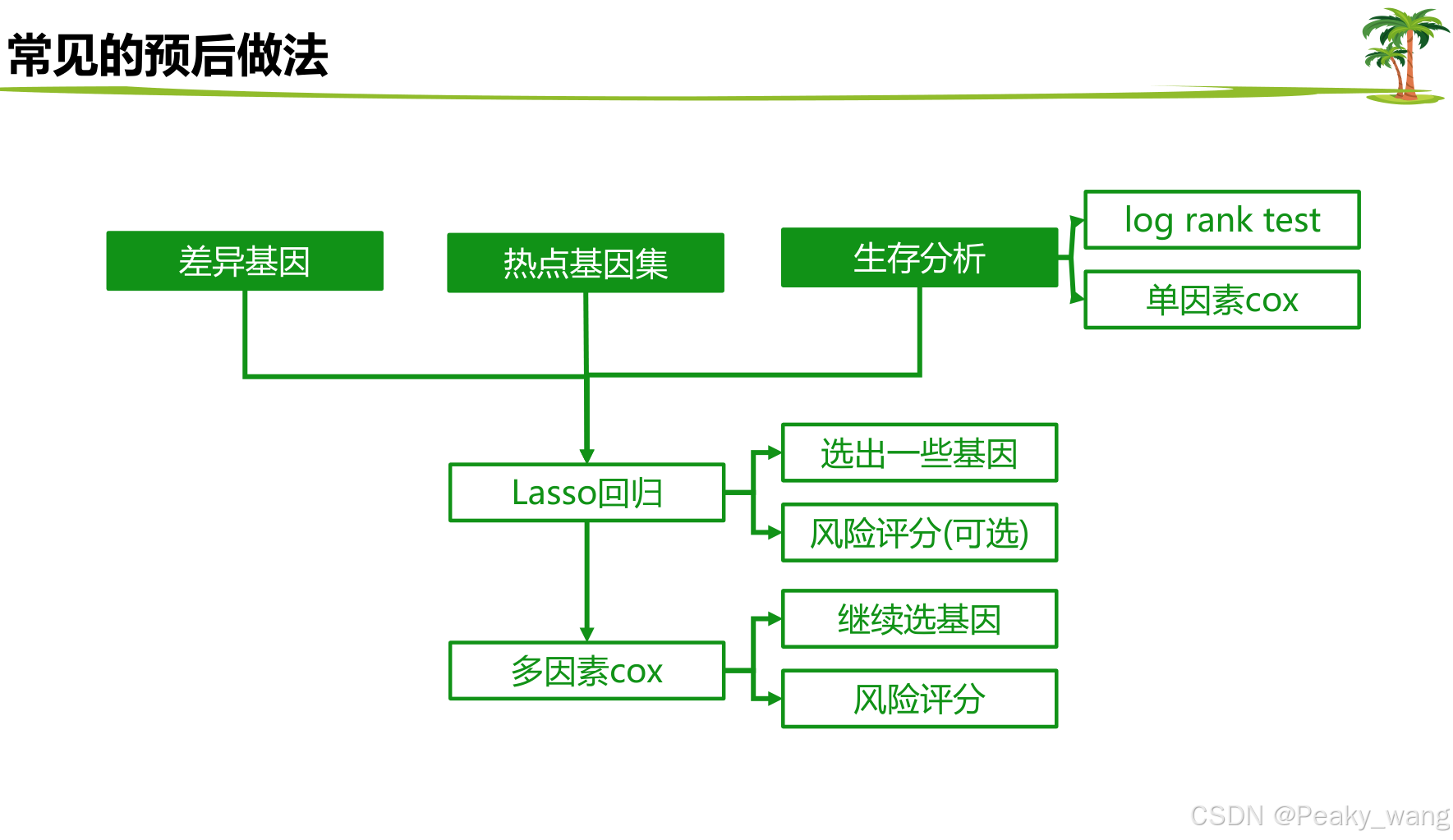
6.预后分析的常见做法
#将分类数据转换为1234;数值型和数值型放在一起,字符型和字符型放在一起,构建的模型才好

7.多因素cox的常见方法
风险森林图:

Lasso回归和多因素cox的衔接
1.lasso筛选的基因拿到cox建模继续筛选
2.lasso回归计算出风险分数,分数拿到cox和临床信息一起建模

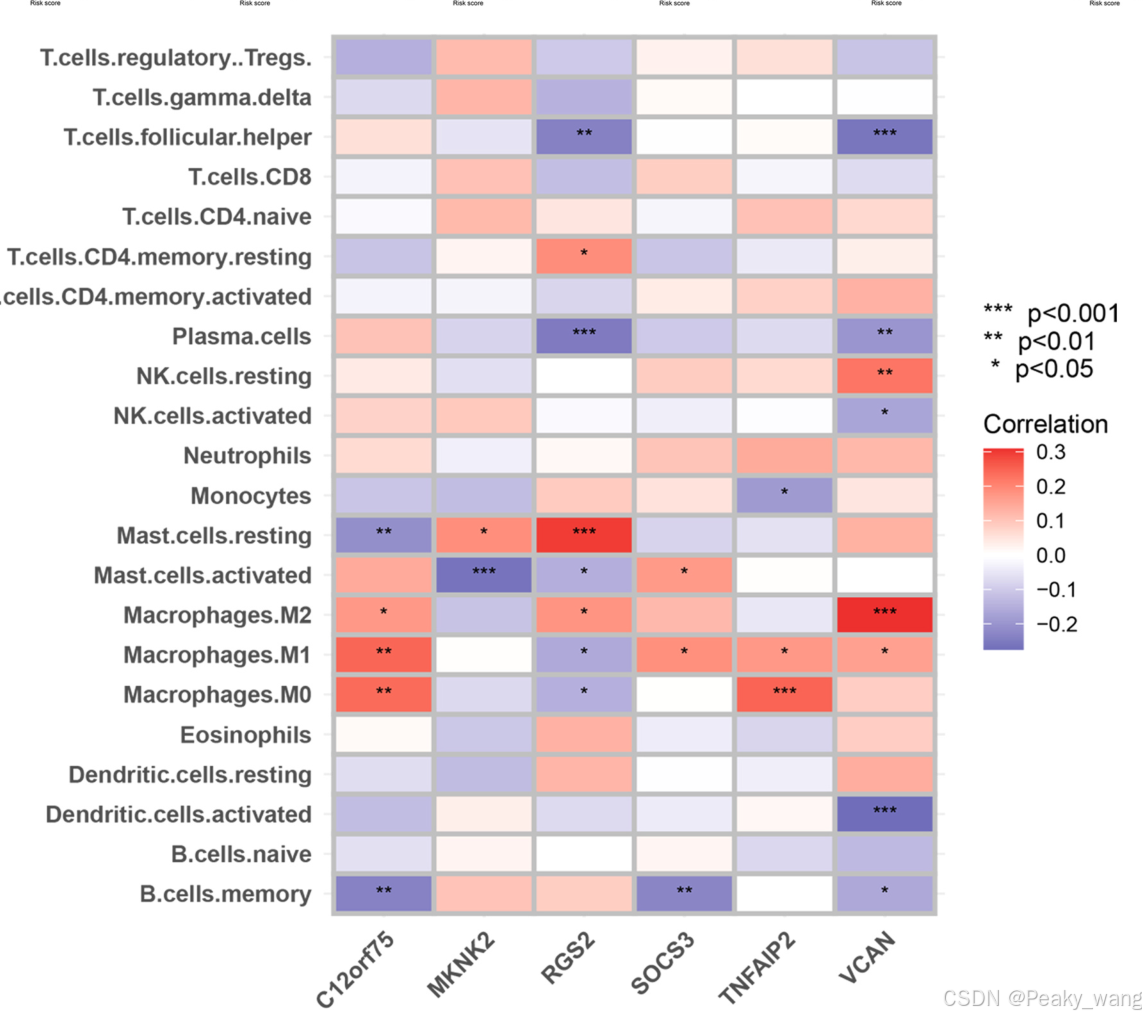
8.免疫浸润
常用CIBERSORT,根据转录组基因表达情况倒推样本的免疫细胞比例
另一常用方法ssGSEA,得到热图:

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)