数据挖掘-Task5:模型融合
目录前言一、二、1.2.总结前言一、二、1.2.总结
·
前言
一、模型融合的方式
1.1 简单加权融合
- 回归(分类概论):算术平均融合( A r i t h m e t i c Arithmetic Arithmetic m e a n mean mean),几何平均融合( G e o m e t r i c Geometric Geometric m e a n mean mean);
- 分类:投票( V o t i n g Voting Voting);
- 综合:排序融合( R a n k Rank Rank a v e r a g i n g averaging averaging), l o g log log 融合。
1.2 s t a c k i n g stacking stacking / / / b l e n d i n g blending blending
- 构建多层模型,并利用预测结果再拟合预测。
1.3 b o o s t i n g boosting boosting / / / b a g g i n g bagging bagging
- 多树提升方法
二、代码示例
2.1 回归/分类概率-融合
2.1.1 简单加权平均,结果直接融合
# In[1]: 简单加权平均,结果直接融合
import numpy as np
import pandas as pd
from sklearn import metrics
## 生成一些简单的样本数据,test_prei 代表 第i个模型的预测值
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
## y_test_true 代表第i个模型的真实值
y_test_true = [1, 3, 2, 6]
## 定义结果的加权平均函数
def Weighted_method(test_pre1,test_pre2,test_pre3,w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pre1)+w[1]*pd.Series(test_pre2)+w[2]*pd.Series(test_pre3)
return Weighted_result
# 各模型的预测结果计算 MAE
print('Pred1 MAE:',metrics.mean_absolute_error(y_test_true, test_pre1))
print('Pred2 MAE:',metrics.mean_absolute_error(y_test_true, test_pre2))
print('Pred3 MAE:',metrics.mean_absolute_error(y_test_true, test_pre3))
## 根据加权计算MAE
w = [0.3,0.4,0.3] # 定义比重权值
Weighted_pre = Weighted_method(test_pre1,test_pre2,test_pre3,w)
print('Weighted_pre MAE:',metrics.mean_absolute_error(y_test_true, Weighted_pre))
# 可以发现加权结果相对于之前的结果是有提升的,这种我们称其为简单的加权平均
可以发现加权结果相对于之前的结果是有提升的,这种称其为简单的加权平均
还有一些特殊的形式,比如 m e a n mean mean 平均, m e d i a n median median 平均:
# In[2]: 特殊的形式,比如 mean平均,median 平均
## 定义结果的加权平均函数
def Mean_method(test_pre1,test_pre2,test_pre3):
Mean_result = pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).mean(axis=1)
return Mean_result
Mean_pre = Mean_method(test_pre1,test_pre2,test_pre3)
print('Mean_pre MAE:',metrics.mean_absolute_error(y_test_true, Mean_pre))
## 定义结果的加权平均函数
def Median_method(test_pre1,test_pre2,test_pre3):
Median_result = pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).median(axis=1)
return Median_result
Median_pre = Median_method(test_pre1,test_pre2,test_pre3)
print('Median_pre MAE:',metrics.mean_absolute_error(y_test_true, Median_pre))
2.1.2 S t a c k i n g Stacking Stacking 融合(回归)
# In[3]: Stacking 融合(回归)
from sklearn import linear_model
def Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,test_pre1,test_pre2,test_pre3,model_L2= linear_model.LinearRegression()):
model_L2.fit(pd.concat([pd.Series(train_reg1),pd.Series(train_reg2),pd.Series(train_reg3)],axis=1).values,y_train_true)
Stacking_result = model_L2.predict(pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).values)
return Stacking_result
## 生成一些简单的样本数据,test_prei 代表第i个模型的预测值
train_reg1 = [3.2, 8.2, 9.1, 5.2]
train_reg2 = [2.9, 8.1, 9.0, 4.9]
train_reg3 = [3.1, 7.9, 9.2, 5.0]
# y_test_true 代表第模型的真实值
y_train_true = [3, 8, 9, 5]
test_pre1 = [1.2, 3.2, 2.1, 6.2]
test_pre2 = [0.9, 3.1, 2.0, 5.9]
test_pre3 = [1.1, 2.9, 2.2, 6.0]
# y_test_true 代表第模型的真实值
y_test_true = [1, 3, 2, 6]
model_L2= linear_model.LinearRegression()
Stacking_pre = Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,
test_pre1,test_pre2,test_pre3,model_L2)
print('Stacking_pre MAE:',metrics.mean_absolute_error(y_test_true, Stacking_pre))
2.2 分类模型融合
# In[4]: 导包
import numpy as np
import lightgbm as lgb
from sklearn.datasets import make_blobs
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
from sklearn.metrics import accuracy_score,roc_auc_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
2.2.1 V o t i n g Voting Voting 投票机制
V o t i n g Voting Voting 即投票机制,分为软投票和硬投票两种,其原理采用少数服从多数的思想。
# In[5]: Voting 投票机制
'''
硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类。
'''
iris = datasets.load_iris()
x=iris.data
y=iris.target
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.3)
clf1 = lgb.LGBMClassifier(learning_rate=0.1, n_estimators=150, max_depth=3, min_child_weight=2, subsample=0.7,
colsample_bytree=0.6, objective='binary:logistic')
clf2 = RandomForestClassifier(n_estimators=200, max_depth=10, min_samples_split=10,
min_samples_leaf=63,oob_score=True)
clf3 = SVC(C=0.1)
# 硬投票
eclf = VotingClassifier(estimators=[('lgb', clf1), ('rf', clf2), ('svc', clf3)], voting='hard')
for clf, label in zip([clf1, clf2, clf3, eclf], ['LGB', 'Random Forest', 'SVM', 'Ensemble']):
scores = cross_val_score(clf, x, y, cv=5, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
2.2.2 分类的 S t a c k i n g Stacking Stacking / / / B l e n d i n g Blending Blending 融合
# In[6]: 分类的Stacking/Blending融合
'''
5-Fold Stacking
'''
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier,GradientBoostingClassifier
import pandas as pd
#创建训练的数据集
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(solver='lbfgs'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=2020)
dataset_blend_train = np.zeros((X.shape[0], len(clfs)))
dataset_blend_test = np.zeros((X_predict.shape[0], len(clfs)))
#5折stacking
n_splits = 5
skf = StratifiedKFold(n_splits)
skf = skf.split(X, y)
for j, clf in enumerate(clfs):
#依次训练各个单模型
dataset_blend_test_j = np.zeros((X_predict.shape[0], 5))
for i, (train, test) in enumerate(skf):
#5-Fold交叉训练,使用第i个部分作为预测,剩余的部分来训练模型,获得其预测的输出作为第i部分的新特征。
X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(X_train, y_train)
y_submission = clf.predict_proba(X_test)[:, 1]
dataset_blend_train[test, j] = y_submission
dataset_blend_test_j[:, i] = clf.predict_proba(X_predict)[:, 1]
#对于测试集,直接用这k个模型的预测值均值作为新的特征。
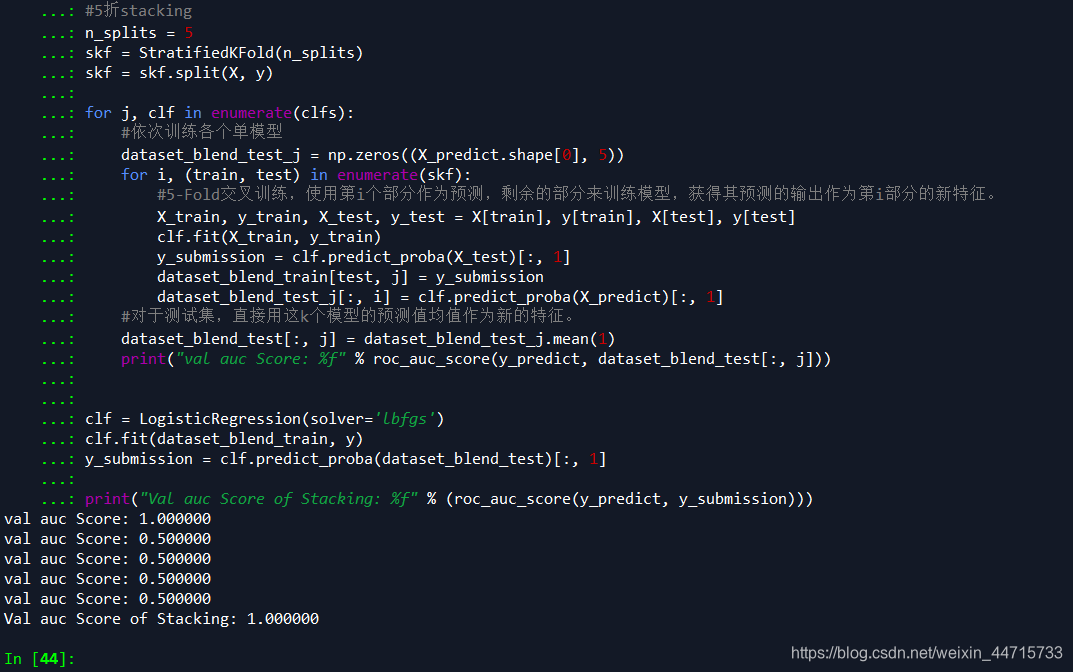
dataset_blend_test[:, j] = dataset_blend_test_j.mean(1)
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_blend_test[:, j]))
clf = LogisticRegression(solver='lbfgs')
clf.fit(dataset_blend_train, y)
y_submission = clf.predict_proba(dataset_blend_test)[:, 1]
print("Val auc Score of Stacking: %f" % (roc_auc_score(y_predict, y_submission)))
# In[7]: 分类的 Stacking\Blending 融合:
'''
Blending
'''
#创建训练的数据集
#创建训练的数据集
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(solver='lbfgs'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
#ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
#切分一部分数据作为测试集
X, X_predict, y, y_predict = train_test_split(data, target, test_size=0.3, random_state=2020)
#切分训练数据集为d1,d2两部分
X_d1, X_d2, y_d1, y_d2 = train_test_split(X, y, test_size=0.5, random_state=2020)
dataset_d1 = np.zeros((X_d2.shape[0], len(clfs)))
dataset_d2 = np.zeros((X_predict.shape[0], len(clfs)))
for j, clf in enumerate(clfs):
#依次训练各个单模型
clf.fit(X_d1, y_d1)
y_submission = clf.predict_proba(X_d2)[:, 1]
dataset_d1[:, j] = y_submission
#对于测试集,直接用这k个模型的预测值作为新的特征。
dataset_d2[:, j] = clf.predict_proba(X_predict)[:, 1]
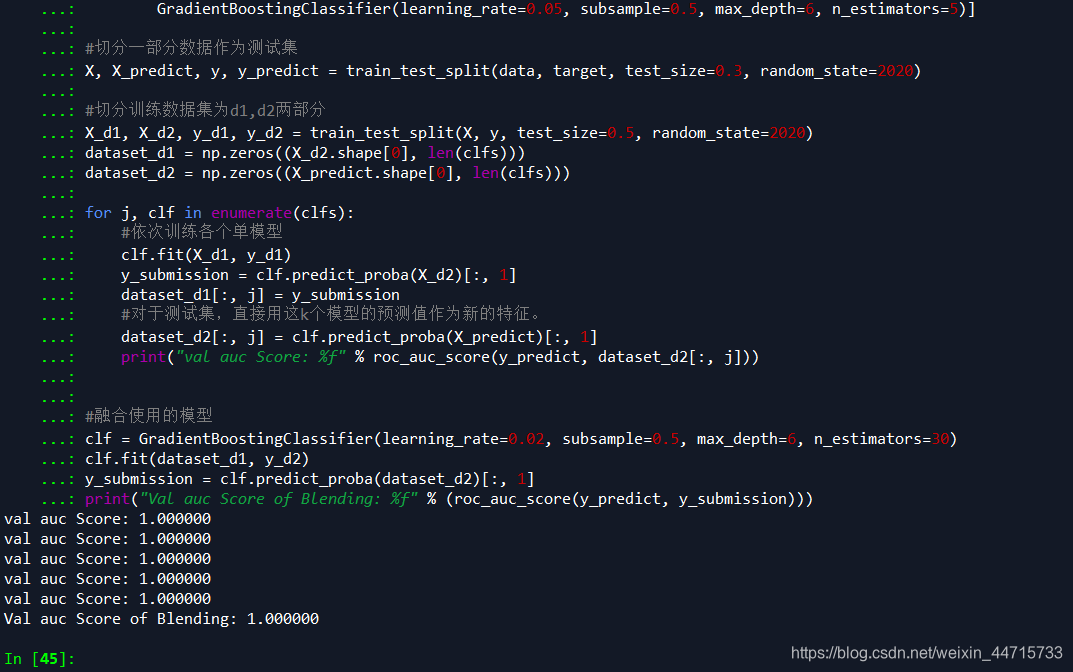
print("val auc Score: %f" % roc_auc_score(y_predict, dataset_d2[:, j]))
#融合使用的模型
clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(dataset_d1, y_d2)
y_submission = clf.predict_proba(dataset_d2)[:, 1]
print("Val auc Score of Blending: %f" % (roc_auc_score(y_predict, y_submission)))
一些其它的方法:
# In[8]: 其他的方法
def Ensemble_add_feature(train,test,target,clfs):
# n_flods = 5
# skf = list(StratifiedKFold(y, n_folds=n_flods))
train_ = np.zeros((train.shape[0],len(clfs*2)))
test_ = np.zeros((test.shape[0],len(clfs*2)))
for j,clf in enumerate(clfs):
'''依次训练各个单模型'''
# print(j, clf)
'''使用第1个部分作为预测,第2部分来训练模型,获得其预测的输出作为第2部分的新特征。'''
# X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(train,target)
y_train = clf.predict(train)
y_test = clf.predict(test)
## 新特征生成
train_[:,j*2] = y_train**2
test_[:,j*2] = y_test**2
train_[:, j+1] = np.exp(y_train)
test_[:, j+1] = np.exp(y_test)
# print("val auc Score: %f" % r2_score(y_predict, dataset_d2[:, j]))
print('Method ',j)
train_ = pd.DataFrame(train_)
test_ = pd.DataFrame(test_)
return train_,test_
# In[9]:
from sklearn.model_selection import cross_val_score, train_test_split
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
data_0 = iris.data
data = data_0[:100,:]
target_0 = iris.target
target = target_0[:100]
x_train,x_test,y_train,y_test=train_test_split(data,target,test_size=0.3)
x_train = pd.DataFrame(x_train) ; x_test = pd.DataFrame(x_test)
#模型融合中使用到的各个单模型
clfs = [LogisticRegression(),
RandomForestClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='gini'),
ExtraTreesClassifier(n_estimators=5, n_jobs=-1, criterion='entropy'),
GradientBoostingClassifier(learning_rate=0.05, subsample=0.5, max_depth=6, n_estimators=5)]
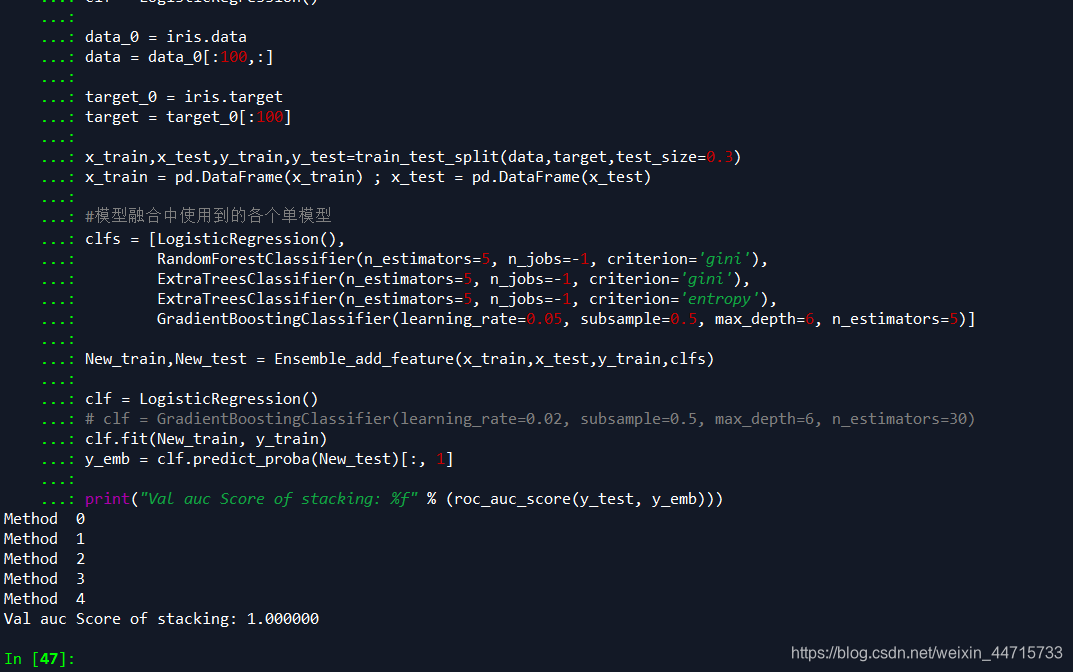
New_train,New_test = Ensemble_add_feature(x_train,x_test,y_train,clfs)
clf = LogisticRegression()
# clf = GradientBoostingClassifier(learning_rate=0.02, subsample=0.5, max_depth=6, n_estimators=30)
clf.fit(New_train, y_train)
y_emb = clf.predict_proba(New_test)[:, 1]
print("Val auc Score of stacking: %f" % (roc_auc_score(y_test, y_emb)))
三、心跳预测赛题示例
3.1 准备工作
- 导入数据集并进行简单的预处理
- 将数据集划分成训练集和验证集
- 构建单模: R a n d o m Random Random F o r e s t Forest Forest, L G B LGB LGB, N N NN NN
- 读取并演示如何利用融合模型生成可提交预测数据
# In[1]:导包
import pandas as pd
import numpy as np
import warnings
#import matplotlib
#import matplotlib.pyplot as plt
#import seaborn as sns
warnings.filterwarnings('ignore')
#%matplotlib inline
#import itertools
#import matplotlib.gridspec as gridspec
#from sklearn import datasets
#from sklearn.linear_model import LogisticRegression
#from sklearn.neighbors import KNeighborsClassifier
#from sklearn.naive_bayes import GaussianNB
#from sklearn.ensemble import RandomForestClassifier,RandomForestRegressor
# from mlxtend.classifier import StackingClassifier
#from sklearn.model_selection import cross_val_score, train_test_split
# from mlxtend.plotting import plot_learning_curves
# from mlxtend.plotting import plot_decision_regions
#from sklearn.model_selection import StratifiedKFold
#from sklearn.model_selection import train_test_split
#from sklearn.model_selection import StratifiedKFold
#from sklearn.model_selection import train_test_split
import lightgbm as lgb
#from sklearn.neural_network import MLPClassifier,MLPRegressor
#from sklearn.metrics import mean_squared_error, mean_absolute_error
引入一个降内存的函数:
# In[2]: 这里引入一个降内存的函数
def reduce_mem_usage(df):
start_mem = df.memory_usage().sum() / 1024**2
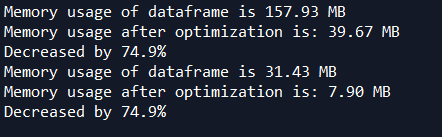
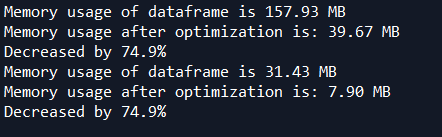
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum() / 1024**2
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
读取数据及数据预处理:
# In[3]:
train = pd.read_csv('D:/Cadabra_tools002/tianqi_file/train.csv')
test = pd.read_csv('D:/Cadabra_tools002/tianqi_file/testA.csv')
# 简单预处理
train_list = []
for items in train.values:
train_list.append([items[0]] + [float(i) for i in items[1].split(',')] + [items[2]])
test_list = []
for items in test.values:
test_list.append([items[0]] + [float(i) for i in items[1].split(',')])
train = pd.DataFrame(np.array(train_list))
test = pd.DataFrame(np.array(test_list))
# id列不算入特征
features = ['s_'+str(i) for i in range(len(train_list[0])-2)]
train.columns = ['id'] + features + ['label']
test.columns = ['id'] + features
train = reduce_mem_usage(train)
test = reduce_mem_usage(test)
# In[4]:
# 根据8:2划分训练集和校验集
X_train = train.drop(['id','label'], axis=1)
y_train = train['label']
# 测试集
X_test = test.drop(['id'], axis=1)
# 第一次运行可以先用一个subdata,这样速度会快些
X_train = X_train.iloc[:50000,:20]
y_train = y_train.iloc[:50000]
X_test = X_test.iloc[:,:20]
# 划分训练集和测试集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2)
# In[5]:
# 单模函数
def build_model_rf(X_train,y_train):
model = RandomForestRegressor(n_estimators = 100)
model.fit(X_train, y_train)
return model
def build_model_lgb(X_train,y_train):
model = lgb.LGBMRegressor(num_leaves=63,learning_rate = 0.1,n_estimators = 100)
model.fit(X_train, y_train)
return model
def build_model_nn(X_train,y_train):
model = MLPRegressor(alpha=1e-05, hidden_layer_sizes=(5, 2), random_state=1,solver='lbfgs')
model.fit(X_train, y_train)
return model
# In[6]:
# 这里针对三个单模进行训练,其中subA_rf/lgb/nn都是可以提交的模型
# 单模没有进行调参,因此是弱分类器,效果可能不是很好。
print('predict rf...')
model_rf = build_model_rf(X_train,y_train)
val_rf = model_rf.predict(X_val)
subA_rf = model_rf.predict(X_test)
print('predict lgb...')
model_lgb = build_model_lgb(X_train,y_train)
val_lgb = model_lgb.predict(X_val)
subA_lgb = model_rf.predict(X_test)
print('predict NN...')
model_nn = build_model_nn(X_train,y_train)
val_nn = model_nn.predict(X_val)
subA_nn = model_rf.predict(X_test)
3.2 加权融合
# In[7]: 加权融合
# 加权融合模型,如果w没有变,就是均值融合
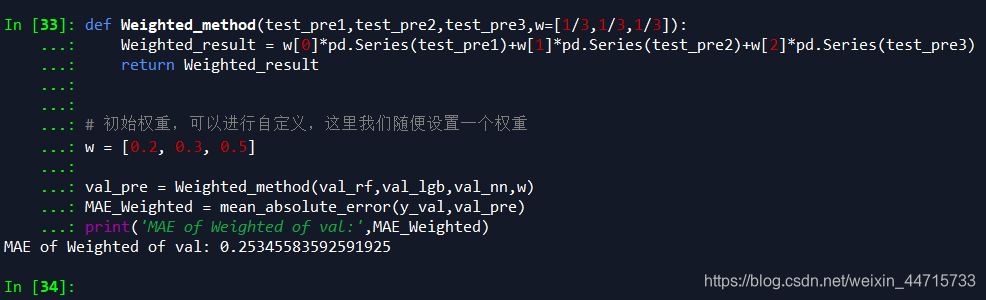
def Weighted_method(test_pre1,test_pre2,test_pre3,w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pre1)+w[1]*pd.Series(test_pre2)+w[2]*pd.Series(test_pre3)
return Weighted_result
# 初始权重,可以进行自定义,这里我们随便设置一个权重
w = [0.2, 0.3, 0.5]
val_pre = Weighted_method(val_rf,val_lgb,val_nn,w)
MAE_Weighted = mean_absolute_error(y_val,val_pre)
print('MAE of Weighted of val:',MAE_Weighted)
# In[8]: Stacking融合
## 预测数据部分
subA = Weighted_method(subA_rf,subA_lgb,subA_nn,w)
## 生成提交文件
sub = pd.DataFrame()
sub['SaleID'] = X_test.index
sub['price'] = subA
sub.to_csv('D:/Cadabra_tools002/tianqi_file/sub_Weighted.csv',index=False)

# In[9]:
## Stacking
## 第一层
train_rf_pred = model_rf.predict(X_train)
train_lgb_pred = model_lgb.predict(X_train)
train_nn_pred = model_nn.predict(X_train)
stacking_X_train = pd.DataFrame()
stacking_X_train['Method_1'] = train_rf_pred
stacking_X_train['Method_2'] = train_lgb_pred
stacking_X_train['Method_3'] = train_nn_pred
stacking_X_val = pd.DataFrame()
stacking_X_val['Method_1'] = val_rf
stacking_X_val['Method_2'] = val_lgb
stacking_X_val['Method_3'] = val_nn
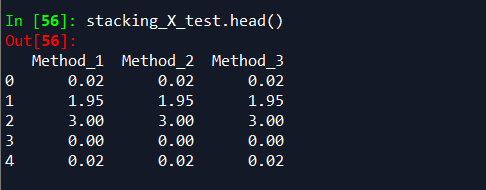
stacking_X_test = pd.DataFrame()
stacking_X_test['Method_1'] = subA_rf
stacking_X_test['Method_2'] = subA_lgb
stacking_X_test['Method_3'] = subA_nn
# In[9-1]: 查看前五行的数据
stacking_X_test.head()
# In[10]:
# 第二层是用random forest
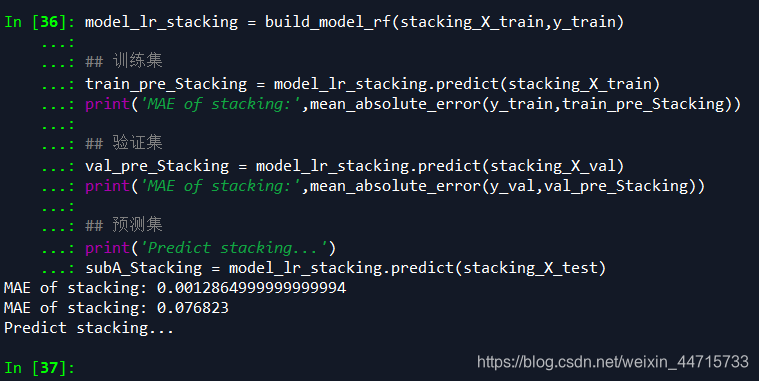
model_lr_stacking = build_model_rf(stacking_X_train,y_train)
## 训练集
train_pre_Stacking = model_lr_stacking.predict(stacking_X_train)
print('MAE of stacking:',mean_absolute_error(y_train,train_pre_Stacking))
## 验证集
val_pre_Stacking = model_lr_stacking.predict(stacking_X_val)
print('MAE of stacking:',mean_absolute_error(y_val,val_pre_Stacking))
## 预测集
print('Predict stacking...')
subA_Stacking = model_lr_stacking.predict(stacking_X_test)
附录


永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)