
大数据分析逻辑回归
在当今信息爆炸的时代,大数据已经成为推动社会进步和商业创新的重要驱动力。它涉及到从海量数据中提取有价值的信息,以支持决策制定、优化业务流程、提高运营效率和创造新的商业机会。大数据的应用领域非常广泛,包括但不限于金融、医疗、教育、交通、零售、政府治理等。
引言
在当今信息爆炸的时代,大数据已经成为推动社会进步和商业创新的重要驱动力。它涉及到从海量数据中提取有价值的信息,以支持决策制定、优化业务流程、提高运营效率和创造新的商业机会。大数据的应用领域非常广泛,包括但不限于金融、医疗、教育、交通、零售、政府治理等。
大数据的重要性
- 决策支持:大数据提供了丰富的信息,帮助企业和组织做出更加科学和精准的决策。
- 市场洞察:通过分析消费者行为和市场趋势,企业可以更好地理解客户需求,开发新产品或服务。
- 风险管理:在金融领域,大数据分析有助于识别和预防欺诈行为,评估信用风险。
- 运营优化:通过分析生产和供应链数据,企业可以优化资源配置,提高效率。
- 个性化服务:在零售和电子商务领域,大数据帮助企业实现个性化推荐,提升客户体验。
逻辑回归及其在数据分析中的作用
逻辑回归是一种广泛使用的统计方法,属于监督学习中的分类算法。它用于预测一个二元结果(如是/否,成功/失败,1/0等)的概率。逻辑回归的核心思想是使用一个或多个预测变量(特征)来估计一个事件发生的可能性。
在数据分析中,逻辑回归扮演着重要的角色:
- 预测分析:逻辑回归可以预测特定事件的发生概率,如预测客户是否会购买产品,或者预测疾病是否会发生。
- 风险评估:在金融领域,逻辑回归常用于信用评分,评估贷款申请者的违约风险。
- 分类问题:逻辑回归是解决二分类问题的基本工具,它通过学习输入特征和输出标签之间的关系,对新的数据点进行分类。
- 特征关系分析:逻辑回归模型可以揭示不同特征与目标变量之间的关系,为进一步的分析提供洞见。
一、逻辑回归的概念
逻辑回归又称逻辑回归分析,是一种广义的线性回归分析模型,自变量可以包括很多因素,因变量常为二分类结果 。常用于数据挖掘、疾病自动诊断、经济预测等领域,例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。
逻辑回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的都差不多 。因此,这两类回归可以归于广义线性模型。如果是连续的,就是多重线性回归;如果是二项分布,就是逻辑回归;如果是泊松分布,就是泊松回归;如果是负二项分布,就是负二项回归。
二、逻辑回归原理
逻辑回归虽然名字里带“回归”,但是实际上它是一种分类方法,主要用于二分类问题,所以需要使用logistic函数(或称为sigmoid函数),函数形式为:
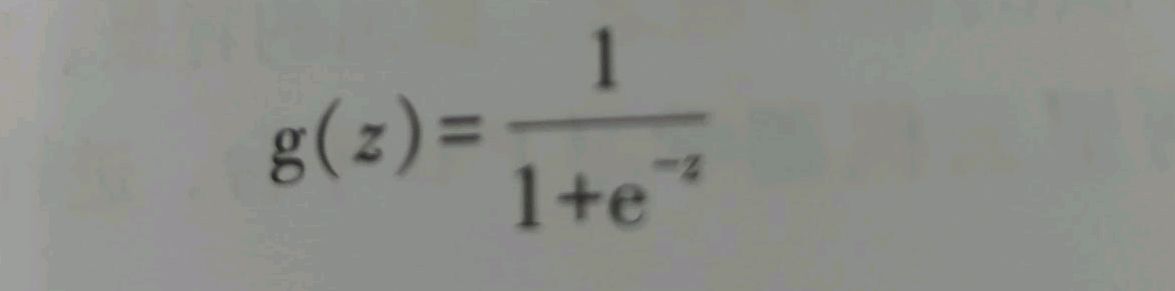
逻辑回归首先把样本映射到[0,1]之间的数值,这就归功于sigmoid函数,可以把任何连续的值映射到[0,1]之间,数越大越趋向于0,越小越趋近于1。在逻辑回归中还有一个非常重要的步骤是选定阈值,意思是确定一个值作为阈值,如选定闹值为0.5,那么小于0.5的预测为负例,哪怕结果是0.49,也将这个样本预测为负例,反之则为正例。但由于只是根据阈值进行预测,误差都是存在的,所以选定阈值时需要选择可以接受误差的程度。
三、实战案例市民属性与早餐饮品的关系分析
逻辑回归在分类的时候,计算量仅仅只和特征的数目相关,简单易理解,模型的可解释性非常好,从特征的权重可以看到不同的特征对最后结果的影响。本节通过一个具体的实例,使读者能够加深对逻辑回归模型的理解,掌握如何使用Python编程语言及阿里云机器学习 PAI平台,进行基于逻辑回归算法的数据分析。
1.数据分析任务
本节实例提供某卫生组织收集的人群类型属性及早餐饮品数据,需要分析不同类型的人群与早餐饮品间的关系,要求通过逻辑回归算法,建立人群与早餐饮品间的逻辑关系,以达成通过人群属性预测早餐饮品的目标。其中数据文件为ods_breakfast_info.csv 。
2.基于 Python 编程语言实现
①开发前准备工作:确保本机已安装Anaconda3-5.1.0及以关系分析市民属性与早餐饮品的上版本,准备本地数据文件ods_breakfast_info.csv,运行Jupyter Notebook 程序,在Web浏览器中新建Python3 文件。
②导入所需的Python 模块。
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report③加载CSV数据文件,并对数据进行必要的观察和探索。
#读取数据
dataset=pd.read_csv("D:/lhr/ods_breakfast_info.csv",encoding="gb2312")
#查看数据:查看数据的前几条记录
dataset.head()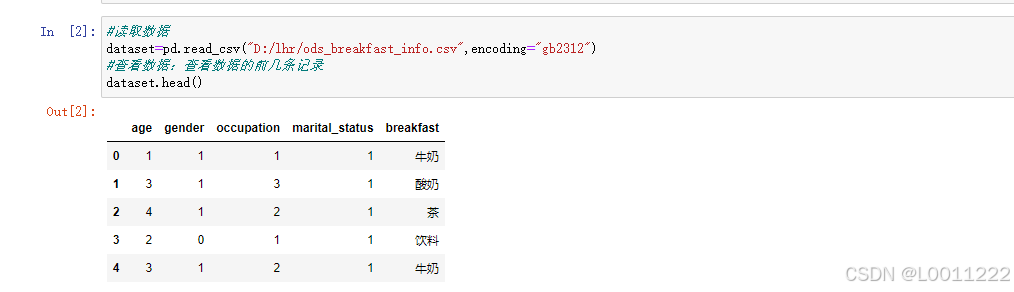
dataset.info()
dataset.describe()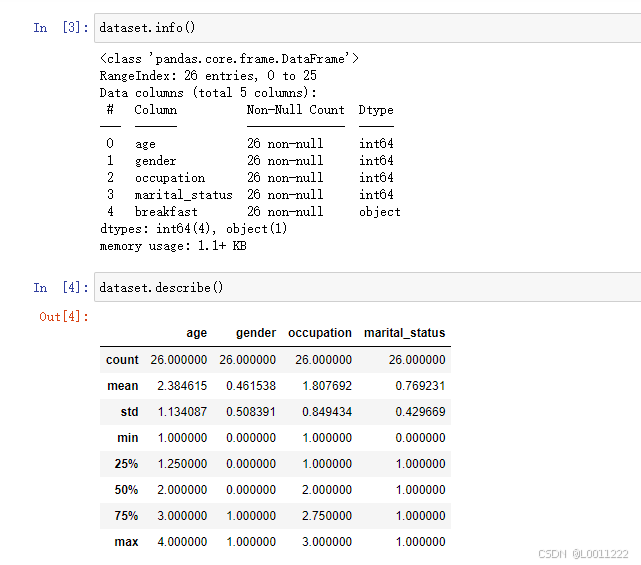
④区分输入及输出数据,其中输人数据为人群属性,输出数据为早餐饮品
#查看各类别计数
dataset["breakfast"].value_counts()
#区分特征及标签数据
x=dataset[["age","gender","occupation","marital_status"]].values
y=dataset["breakfast"].values
dataset["breakfast"].values
⑤设置随机数种子,确保结果可重现,并按比例随机拆分训练样本和测试样本
#设置随机数种子
np.random.seed=123
#拆分样本
(train_x,test_x,train_y,test_y)=train_test_split(x,y,train_size=0.8,test_size=0.2)
⑥使用多分类函数 multinomial构建逻辑回归模型,并通过样本集对模型进行训练
model=LogisticRegression(multi_class="multinomial",solver="newton-cg")
model.fit(train_x,train_y)

⑦使用精准率 Precision、召回率Recall、FI-score等指标对模型进行评价
print("模型评分:",model.score(test_x,test_y))
print(classification_report(test_y,model.predict(test_x)))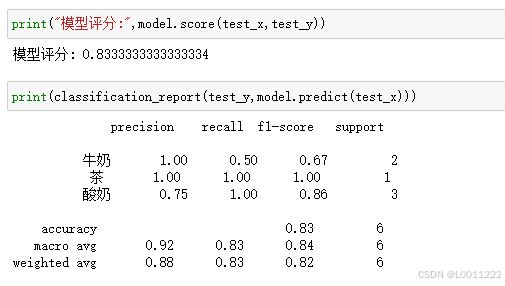
⑧利用模型预测新的数据
print(model.predict([[4,0,1,1]]))
print("概率:",model.predict_proba([[4,0,1,1]]).max())
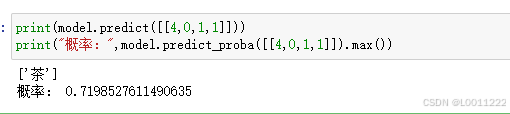
通过比较测试集中的属性“breakfast”和预测得到的结果,可以得出预测正确的概率为0.7198,说明使用逻辑回归建立的模型预测效果较好,在分类问题上可以选择使用逻辑回归算法进行建模和预测。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)