数据挖掘竞赛-员工离职预测训练赛
员工离职预测简介比较基础的分类问题核心思路为属性构造+逻辑回归过程数据获取报名这个比赛即可获取到这个数据点击获取数据探索无关项EmployeeNumber为编号,对建模是干扰项,删除即可。StandardHours和Over18全数据集固定值,没有意义,删除。相关性高相关图发现有两项相关性极高,删除其中一个JobLevel数据预处理...
·
员工离职预测
- 简介
- 比较基础的分类问题
- 核心思路为属性构造+逻辑回归
- 过程
- 数据获取
- 报名这个比赛即可获取到这个数据点击获取
- 数据探索
- 无关项
- EmployeeNumber为编号,对建模是干扰项,删除即可。
- StandardHours和Over18全数据集固定值,没有意义,删除。
- 相关性高
- 相关图
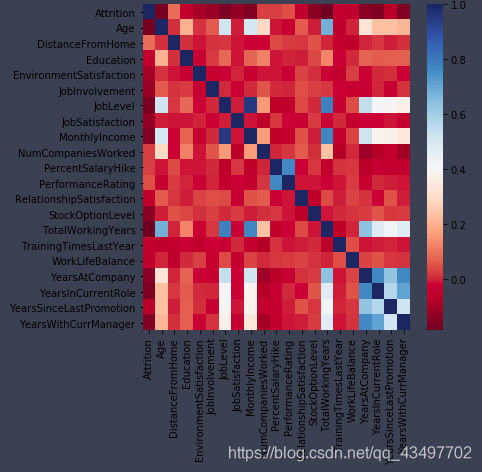
发现有两项相关性极高,删除其中一个JobLevel
- 相关图
- 无关项
- 数据预处理
- 属性构造
- 个人凭感觉制造了几个新特征
-one-hot编码 - 对几个字符串类型的属性,进行了one-hot编码
- 个人凭感觉制造了几个新特征
- 数据挖掘建模
- 我们看出有的特征的数字大,有的特征的数字小,进行标准化处理。
- 采用多模型交叉验证选择较好的模型,在进一步调参
- 代码
# 多模型交叉验证 import warnings warnings.filterwarnings('ignore') from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import cross_val_score models ={ 'LR':LogisticRegression(solver='liblinear'), 'SVM':SVC(), 'RF':RandomForestClassifier(n_estimators=150), } for k,clf in models.items(): print('the model is %s'%k) scores = cross_val_score(clf,train.iloc[:,1:],train['Attrition']) print('Mean accuracy is {}'.format(np.mean(scores))) print('-'*20) - 对LR进行网格搜索进行调参
# 数据分割 加网格搜索 from sklearn.model_selection import train_test_split from sklearn.model_selection import GridSearchCV x_train,x_test,y_train,y_test = train_test_split( df_train.iloc[:,1:],df_train['Attrition'],random_state=22) params={ 'penalty':['l1', 'l2'], 'C':np.arange(1,4.1,0.2), } estimator = LogisticRegression(solver='liblinear') grid = GridSearchCV(estimator,param_grid=params,cv=10) grid.fit(x_train,y_train) print('最好的参数',grid.best_params_) score = grid.score(x_test,y_test) print('在测试集的得分',score) ```
- 属性构造
- 数据获取
- 补充说明
- 具体数据集和代码可以在我的Github中找到,1-pred即为提交文件。
- 最终分数在0.90以上,但是对于新人的我已经很满意了
- https://github.com/qq2471001205/My-repository/tree/master/ ----- 备用Github链接
参考文章

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)