数学建模之python-数据挖掘与预处理
前言明早把z-score和01实战一下然后pandas读取文件学一学3.判断列有无缺失值4.判断每一行的缺失值5.缺失值定位到每一行6.各变量缺失的值7.直接删除空值对应所在行8.定义缺失值为0ps:fillna填充好文:https://blog.csdn.net/qq_21840201/article/details/81008566?ops_request_misc=&request_
前言
调库的列名都变了 推荐手写版
修改列名的方法:

0.5 pandas读取文件
1.header=0 加不加都一样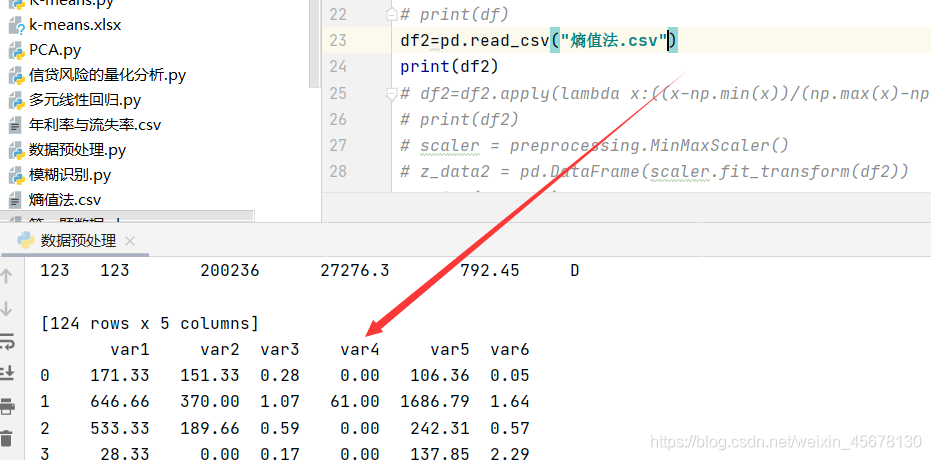
2.但如果加了header=None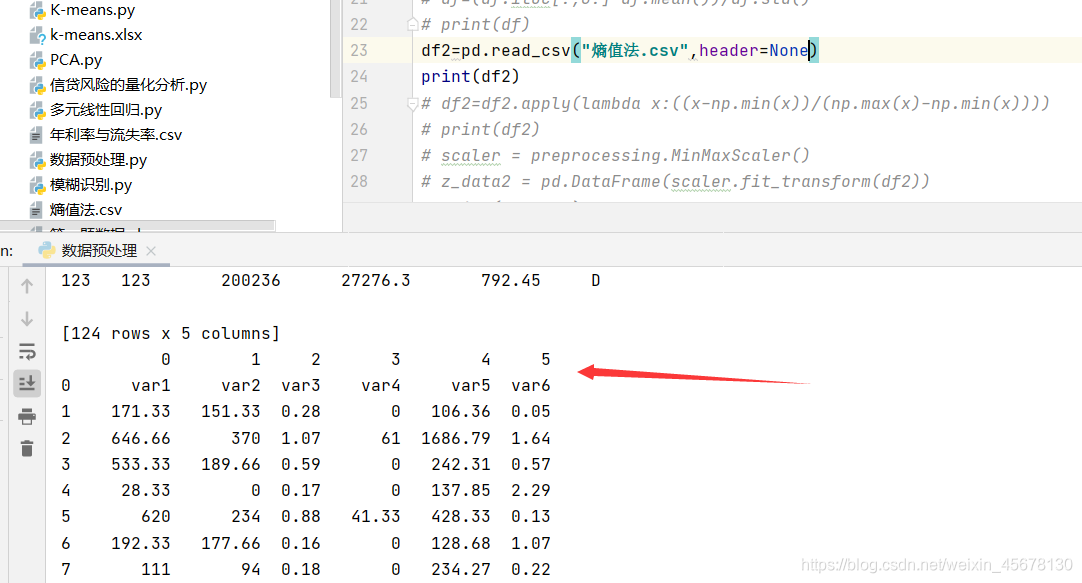
3. 如果数据本来有列名,则忽略header这个参数即可,如果本身没有列名,或者有但是想替换,用names替换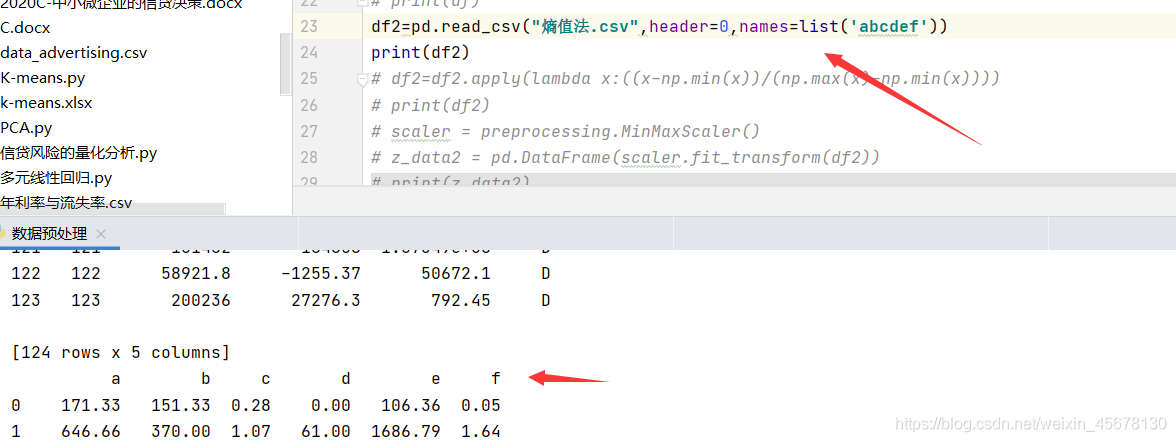
4.很关键 关于将第一列作为行索引(不然 还会多出来一列):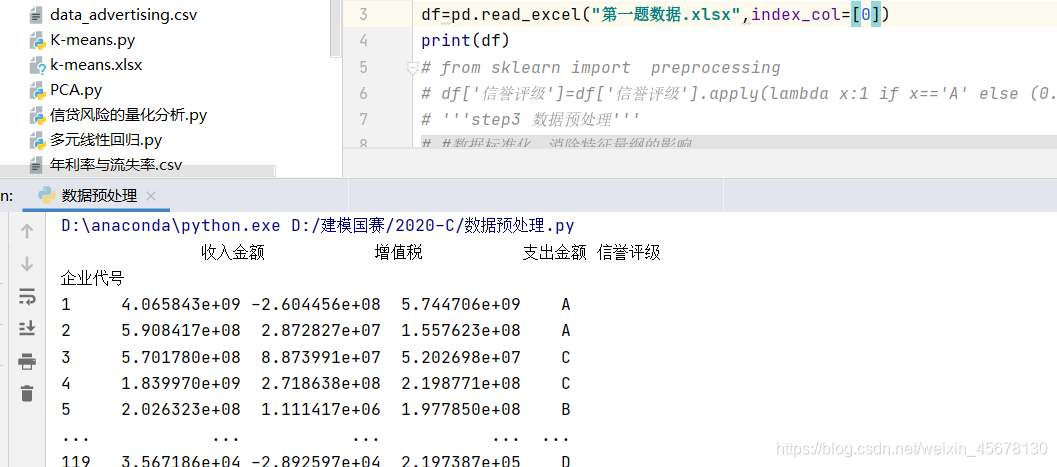
5.保存文件时 columns可以指定存入的子集,index=False和header=False,是指不存入行索引和列索引
df=pd.read_excel("第一题数据.xlsx",index_col=[0])
print(df)
from sklearn import preprocessing
df['信誉评级']=df['信誉评级'].apply(lambda x:1 if x=='A' else (0.75 if x=='B' else(0.5 if x=='C' else 0.25)) )
# '''step3 数据预处理'''
# #数据标准化,消除特征量纲的影响
# #将属性缩放到一个指定范围,即(x-min)/(max-min)
# # print(df)
scaler = preprocessing.MinMaxScaler()
z_data = pd.DataFrame(scaler.fit_transform(df))
print(z_data)
z_data.columns=[list('abcd')]
z_data.to_csv('data1.csv', encoding='gbk',index=False)
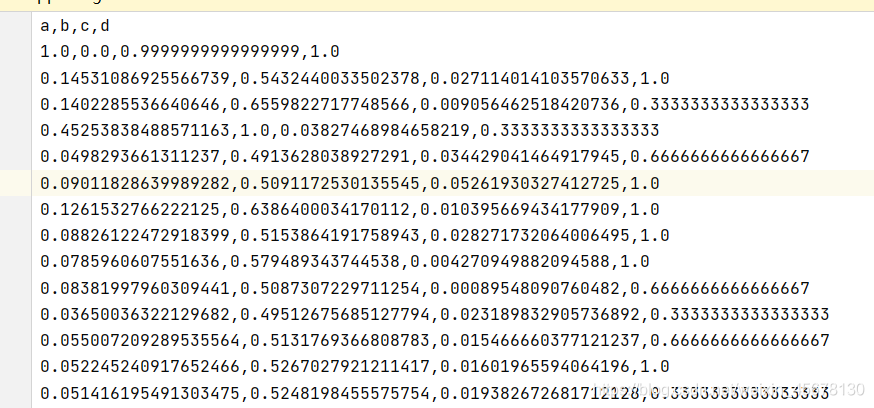
1 z-score和01标准化的代码如下:
01标准化调库代码(最好用-df就是用pandas读取的文件):
scaler = preprocessing.MinMaxScaler()
z_data = pd.DataFrame(scaler.fit_transform(df))
print(z_data)
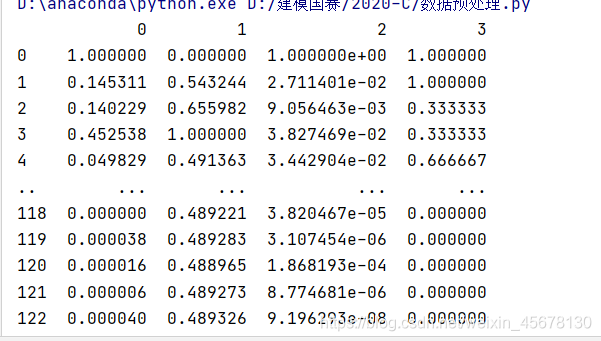
01标准化手写代码(跟调库一样好用 没区别)
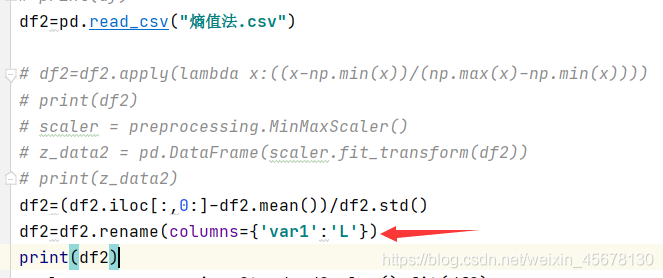
df2=pd.read_csv("熵值法.csv")
df2=df2.apply(lambda x:((x-np.min(x))/(np.max(x)-np.min(x))))
z-score调库代码:
scaler =preprocessing.StandardScaler().fit(df2)
df2=scaler.transform(df2)
z_data2 = pd.DataFrame(df2)
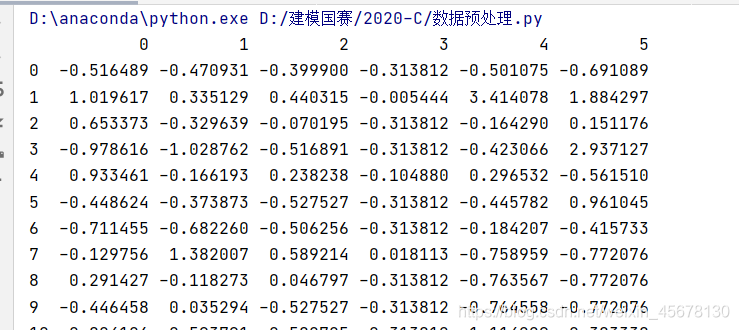
z-score标准化手写代码(列名没变 调库的列名都变成1234了):
df2=(df2.iloc[:,0:]-df2.mean())/df2.std()
print(df2)
z-score单列标准化
from sklearn.preprocessing import scale
df['增值税']=scale(df['增值税'].values.reshape(-1,1))
2.多文件合并

3.查看数据
4.判断列有无缺失值
axis好文:
https://blog.csdn.net/leilei7407/article/details/104461215?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162987388116780366539508%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162987388116780366539508&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-104461215.first_rank_v2_pc_rank_v29&utm_term=axis%3D0&spm=1018.2226.3001.4187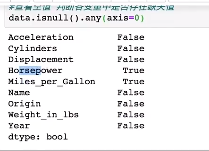
判断每一行的缺失值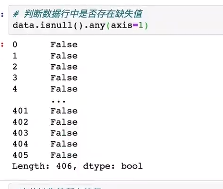
缺失值定位到每一行
各变量缺失的值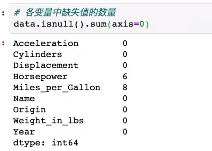
直接删除空值对应所在行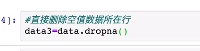
定义缺失值为0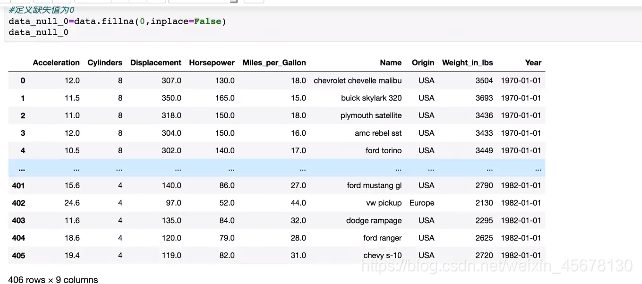
ps:fillna填充好文:
https://blog.csdn.net/qq_21840201/article/details/81008566?ops_request_misc=&request_id=&biz_id=102&utm_term=fillna%E4%B8%ADinplace=false&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-5-.first_rank_v2_pc_rank_v29&spm=1018.2226.3001.4187
ps:关于inplace的好文:
https://blog.csdn.net/songyunli1111/article/details/82937954?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162843431116780274199115%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162843431116780274199115&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allbaidu_landing_v2~default-1-82937954.first_rank_v2_pc_rank_v29&utm_term=pandas%E4%B8%ADinplace%3Dfalse&spm=1018.2226.3001.4187
多种方式填充缺失值:
增加索引
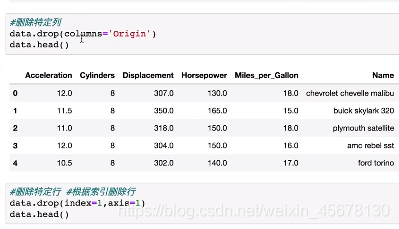
5.删除特定的行或列
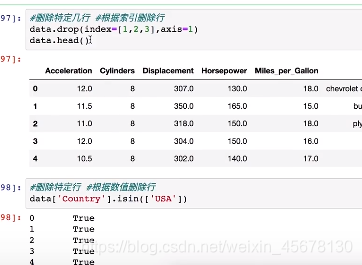
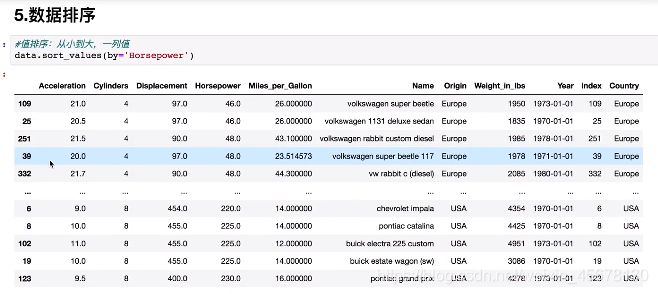
6.数据排序:



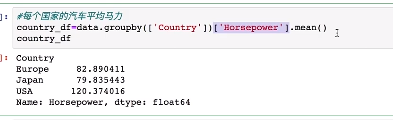
7.数据汇总
重新以列表的情况输出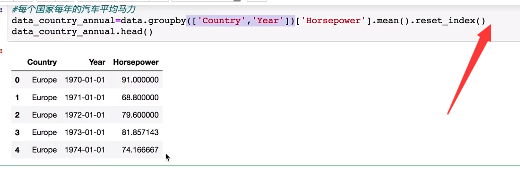
8.两表筛选:
df1=pd.read_excel("会员消费明细表.xlsx")
df2=pd.read_excel("会员信息表.xlsx")
df1_=df1[df1['kh'].isin(df2["kh"])]
print("筛选后的消费信息表:\n",df1_.head(5),"\n 大小:",df1_.size)
print("\n原始的:\n",df1.head(5),"\n 大小:",df1.size)

9.将日期转化格式:
df['dtime']=pd.to_datetime(df['dtime'])
print(df)
#删除指定行
df=df.drop(df.index[(df['dtime']<'2017-01-03 21:27:28.686000')])

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)