数据挖掘之特征工程
人们观测或者收集到的数据样本是高维的,但与学习任务密切相关的也许仅仅是某个低维分布,即高维空间中的一个低维“嵌入”。且在高维情形下出现的数据样本稀疏、距离计算困难等问题是所有机器学习方法共同面临的严重障碍,因此特征工程的目的是最大限度地从原始数据中提取特征以供算法和模型使用。不仅减少过拟合、减少特征数量(降维)、提高模型泛化能力,而且还可以使模型获得更好的解释性,增强对特征和特征值之间的理解,加快
-
人们观测或者收集到的数据样本是高维的,但与学习任务密切相关的也许仅仅是某个低维分布,即高维空间中的一个低维“嵌入”。且在高维情形下出现的数据样本稀疏、距离计算困难等问题是所有机器学习方法共同面临的严重障碍,因此特征工程的目的是最大限度地从原始数据中提取特征以供算法和模型使用。不仅减少过拟合、减少特征数量(降维)、提高模型泛化能力,而且还可以使模型获得更好的解释性,增强对特征和特征值之间的理解,加快模型的训练速度,还会获得更好的性能。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限,因此工程的质量为模型的成败奠定了基石。
-
我们在用逻辑回归、决策树等模型方法构建分类模型时,经常需要对自变量进行筛选。比如我们有200个候选自变量,通常情况下,不会直接把200个变量直接放到模型中去进行拟合训练,而是会用一些方法,从这200个自变量中挑选一些出来,放进模型,形成入模变量列表。那么我们怎么去挑选入模变量呢?
挑选入模变量过程是个比较复杂的过程,需要考虑的因素很多,比如:变量的预测能力,变量之间的相关性,变量的简单性(容易生成和使用),变量的强壮性(不容易被绕过),变量在业务上的可解释性(被挑战时可以解释的通)等等。但是,其中最主要和最直接的衡量标准是变量的预测能力。
常用的特征工程方法有:信息熵、条件熵、信息增益、信息增益比、Gini系数、Iv值、 PCA变换等。
- 信息熵
- 条件熵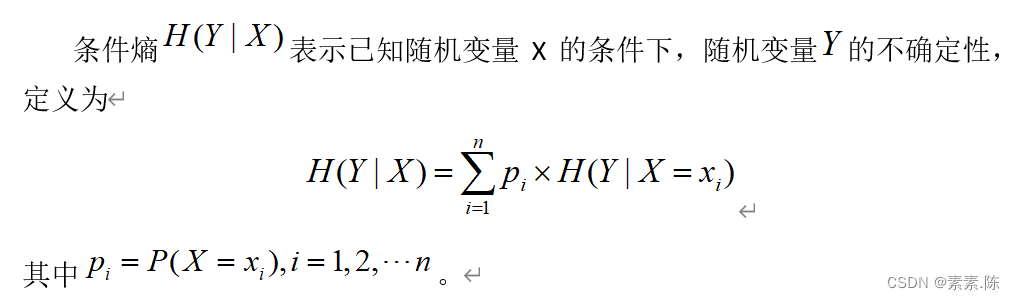
- 信息增益
-
信息增益比

-
Gini系数

-
Iv值
从直观逻辑上大体可以这样理解“用IV去衡量变量预测能力”这件事情:我们假设在一个分类问题中,目标变量的类别有两类:Y1,Y2。对于一个待预测的个体A,要判断A属于Y1还是Y2,我们是需要一定的信息的,假设这个信息总量是I,而这些所需要的信息,就蕴含在所有的自变量C1,C2,C3,……,Cn中,那么,对于其中的一个变量Ci来说,其蕴含的信息越多,那么它对于判断A属于Y1还是Y2的贡献就越大,Ci的信息价值就越大,Ci的IV就越大,它就越应该进入到入模变量列表中。为了介绍IV的计算方法,我们首先需要认识和理解另一个概念——WOE,因为IV的计算是以WOE为基础的。
WOE是对原始自变量的一种编码形式。要对一个变量进行WOE编码,需要首先把这个变量进行分组处理(也叫离散化、分箱等等,说的都是一个意思)。分组后,对于第i组,WOE的计算公式如下:
变换以后我们可以看出,WOE也可以这么理解,他表示的是当前这个组中响应的客户和未响应客户的比值,和所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小。
-
PCA变换

PCA算法分析 -
优点:使得数据更易使用,并且可以去除数据中的噪声,使得其他机器学习任务更加精确。该算法往往作为预处理步骤,在数据应用到其他算法之前清洗数据。
-
缺点:数据维度降低并不代表特征的减少,因为降维仍旧保留了较大的信息量,对结果过拟合问题并没有帮助。不能将降维算法当做解决过拟合问题方法。如果原始数据特征维度并不是很大,也并不需要进行降维。
代码:
import pandas as pd
from scipy import linalg
import numpy as np
#from entropy_tool import *
import scipy.stats as ss
import matplotlib.pyplot as plt
import seaborn as sns
## 对数据进行PCA变换处理
## data: 要进行处理的数据 ; n_compotents: 要留下的成分个数
## 定义pca变换
def chensqPca(data , n_compotents):
mean_vals = data.mean()
mid = data - mean_vals
### step01 计算协方差矩阵
cov_mat = mid.cov()
### step02: 计算协方差矩阵的特征值和特征向量
eig_vals, eig_vectors = np.linalg.eig(cov_mat)
#print(type(eig_vals))
### step03把特征值按照从小到大的顺序排列,并选取排在前面的n_components个特征值所对应的特征向量
eig_val_index = np.argsort(eig_vals)
#print(eig_val_index)
#n_compotents = 1
eig_val_index = eig_val_index[:-(n_compotents + 1): -1]
#print(eig_val_index)
eig_vectors = eig_vectors[:, eig_val_index]
# step04 将样本投影到选取的特征向量上
low_dim_mat = np.dot(mid, eig_vectors)
return low_dim_mat
## Original_data: 输入待降维的数据(全部为数值型变量),返回该数据应该保留下来的成分维度数n
def cal_n(Original_data):
mean_vals = Original_data.mean()
# 计算每列的均值
mid = Original_data - mean_vals
### step01 计算协方差矩阵
cov_mat = mid.cov()
### step02: 计算协方差矩阵的特征值和特征向量
eig_vals, eig_vectors = np.linalg.eig(cov_mat)
eig_vals = sorted(eig_vals, reverse = True)
## 把主成份含量总和 > 90%的成分留下来
sum_prop = sum(eig_vals)
n = 1
x_prop = 0
for i in range(len(eig_vals)):
x_prop += eig_vals[i]
prop = x_prop / sum_prop
if prop <= 0.95:
n += 1
else:
break
return n
import pandas as pd
import numpy as np
import math
## 计算信息熵
def getEntropy(s):
# 找到各个不同取值出现的次数
if not isinstance(s, pd.core.series.Series):
s = pd.Series(s)
prt_ary = pd.groupby(s , by = s).count().values / float(len(s))
return -(np.log2(prt_ary) * prt_ary).sum()
## 计算条件熵: 条件s1下s2的条件熵
def getCondEntropy(s1 , s2):
d = dict()
for i in list(range(len(s1))):
d[s1[i]] = d.get(s1[i] , []) + [s2[i]]
return sum([getEntropy(d[k]) * len(d[k]) / float(len(s1)) for k in d])
## 计算信息增益
def getEntropyGain(s1, s2):
return getEntropy(s2) - getCondEntropy(s1, s2)
## 计算增益率
def getEntropyGainRadio(s1, s2):
return getEntropyGain(s1, s2) / getEntropy(s2)
## 衡量离散值的相关性
import math
def getDiscreteCorr(s1, s2):
return getEntropyGain(s1,s2) / math.sqrt(getEntropy(s1) * getEntropy(s2))
# ######## 计算概率平方和
def getProbSS(s):
if not isinstance(s, pd.core.series.Series):
s = pd.Series(s)
prt_ary = pd.groupby(s, by = s).count().values / float(len(s))
return sum(prt_ary ** 2)
######## 计算基尼系数
def getGini(s1, s2):
d = dict()
for i in list(range(len(s1))):
d[s1[i]] = d.get(s1[i] , []) + [s2[i]]
return 1-sum([getProbSS(d[k]) * len(d[k]) / float(len(s1)) for k in d])
if __name__ == "__main__":
s1 = pd.Series(['X1' , 'X1' , 'X2' , 'X2' , 'X2' , 'X2'])
s2 = pd.Series(['Y1' , 'Y1' , 'Y1' , 'Y2' , 'Y2' , 'Y2'])
print('CondEntropy:',getCondEntropy(s1, s2))
print('EntropyGain:' , getEntropyGain(s1, s2))
print('EntropyGainRadio' , getEntropyGainRadio(s1 , s2))
print('Gini' , getGini(s1, s2))

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 2
2 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)