数据挖掘之关联分析Apriori算法
文章目录一、理论知识1.1、定义1.2、关联规则1.3、频繁项集的产生二、python实战一、理论知识许多商业企业在运营中积累了大量的数据。例如:普通超市的收银台每天都会收集到大量的用户购物数据。下表给出一个这样的例子,通常称为购物篮事务。每一行代表一个事务,包含唯一标识id和顾客购买的商品的集合。零售商对分析这些数据会感兴趣,因为这样可以了解到用户的购物行为,可以使用这种有价值的信息来支持各种商
·
一、理论知识
许多商业企业在运营中积累了大量的数据。例如:普通超市的收银台每天都会收集到大量的用户购物数据。下表给出一个这样的例子,通常称为购物篮事务。每一行代表一个事务,包含唯一标识id和顾客购买的商品的集合。零售商对分析这些数据会感兴趣,因为这样可以了解到用户的购物行为,可以使用这种有价值的信息来支持各种商务应用,如市场促销,库存管理等。
| TID | 项集 |
|---|---|
| 1 | {黄油 ,苹果,香蕉} |
| 2 | {面包,牛奶,苹果} |
| 3 | {面包,黄油,苹果} |
| 4 | {黄油,苹果,香蕉} |
| 5 | {牛奶,香蕉} |
这篇博客主要讲解关联分析的方法。用于发现隐藏在大型数据集中的有意义的联系。发现的联系可以利用关联规则或频繁项集的形式表示。例如,从上表中可以提取出如下规则:{面包}->{苹果},这个规则表示买了面包的人同时也买了苹果,继而可以发现新的交叉销售商机。
1.1、定义
- 二元表示:
购物篮数据可以用下表的二元形式来表示,每行表示一个事务,每一列表示一个项集。项可以用二元值表示,若项在事务中出现,则表示为1,否则为0。
| 牛奶 | 苹果 | 面包 | 香蕉 | 黄油 | |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 1 | 1 |
| 2 | 1 | 1 | 1 | 0 | 0 |
| 3 | 0 | 1 | 1 | 0 | 1 |
| 4 | 0 | 1 | 0 | 1 | 1 |
| 5 | 1 | 0 | 0 | 1 | 0 |
- 项集:关联分析中,包含0个或多个项的集合被称为项集。如果一个项集中包含k个项,则称其为k项集。例如:{苹果,面包,牛奶}是一个3项集。
- 支持度计数:项集在事务中出现的次数即为支持度计数。例如:上面的二元表中,项集{面包,苹果}在5个事务中出现了2次,所以它的支持度计数就为2。
1.2、关联规则
- 关联规则是形如X->Y的蕴含表达式,其中X和Y是不相交的项集,即它们的交集为空。关联规则的强度可以利用支持度和置信度度量。支持度确定给定数据集的频繁程度,而置信度确定Y在包含X的事务中出现的频繁程度。
- 支持度(support)和置信度(confidence)的定义如下:N表示事务数量,N()表示项集在事务中出现的次数
s ( X → Y ) = N ( X U Y ) N , c ( X → Y ) = N ( X U Y ) N ( X ) s(X→Y)=\frac{N(XUY)}{N},c(X→Y)=\frac{N(XUY)}{N(X)} s(X→Y)=NN(XUY),c(X→Y)=N(X)N(XUY) - 提升度(lift):
l
i
f
t
(
X
→
Y
)
=
c
(
X
→
Y
)
s
(
Y
)
=
N
(
X
U
Y
)
/
N
(
X
)
N
(
Y
)
/
N
lift(X→Y)=\frac{c(X→Y)}{s(Y)}=\frac{{N(XUY)}/{N(X)}}{N(Y)/N}
lift(X→Y)=s(Y)c(X→Y)=N(Y)/NN(XUY)/N(X),如果
l
i
f
t
=
1
lift=1
lift=1说明X和Y没有任何关联,如果
l
i
f
t
<
1
lift<1
lift<1,说明X和Y是排斥的,如果
l
i
f
t
>
1
lift>1
lift>1,我们认为X和Y是有关联的。
例如:上面的例子中:牛奶出现在2个事务中,那么{牛奶}的支持度就是2/5=0.4;苹果出现在包含牛奶的事务中出现了1次,那么规则{牛奶}→{苹果}的置信度为1/2=0.5,规则{牛奶}→{苹果}的提升度为0.5/(4/5)=0.625。 - 给定事务的集合T,关联规则发现是指找出支持度大于等于minsup且置信度大于等于minconf的所有规则,其中minsup和minconf是对应的支持度和置信度的阈值即设置的最小支持度和最小置信度。
- 为什么使用支持度和置信度呢?
- 支持度是一种重要度量值,因为支持度很低的规则可能知识偶尔出现,从商务角度看,低支持度的规则多半是无意义的,因为对顾客很少同时购买的商品进行促销活动并无益处。因此支持度,通常是删掉那些无意义的规则。
- 置信度度量通过规则推理具有可靠性。对于给定的规则X→Y,置信度越高,说明Y在包含X的事务中出现的可能性就越大。置信度也可以估计Y在条件X下的条件概率。
- 提升度存在的意义:
置信度用于评估规则的可信程度,但是该度量有一个缺点,没有考虑规则后件的支持度问题,例如在下表中:
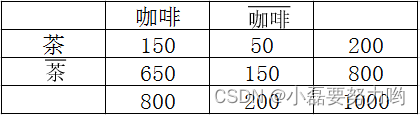
规则{茶} → \rightarrow →{咖啡}的支持度为150/1000=15%,置信度为150/200=75%,先不考虑支持度,只看置信度会觉得比较高,因为可能会认为爱喝茶的人一般也爱喝咖啡。我们再来看一下喝咖啡的人的支持度,达到800/1000=80%,比规则{茶} → \rightarrow →{咖啡}的置信度75%高,这说明什么问题?并不是爱喝茶的人一般爱喝咖啡,从而使得规则置信度高,而是爱喝咖啡的人本身就很多,所以这条规则是一个误导。由于置信度存在的缺陷,人们又提出了称作提升度的度量。 - 强关联规则:
- 对于给定的规则X→Y,如果规则同时满足 s u p p o r t ( X → Y ) > = m i n s u p support(X→Y)>=minsup support(X→Y)>=minsup和 c o n f i d e n c e ( X → Y ) > = m i n c o n f confidence(X→Y)>=minconf confidence(X→Y)>=minconf,那么称规则X→Y为强关联规则,否则为弱关联规则。
1.3、频繁项集的产生
- 先验原理:如果一个项集是频繁的,那么该项集的所有子集一定也是频繁的。
- Apriori算法是第一个关联挖掘算法,使用基于支持度的剪枝技术。对于例子来说,假定支持度阈值为60%,相当于最小支持度计数为3。
- 如图:初始将每个项作为一个候选1-项集,对他们的支持度计数之后,候选项集{牛奶}和{面包}被丢弃,因为它们的计数均小于3;第二次迭代,仅使用频繁集1-项集来产生2-项集,因为先验原理保证2-项集的所有子集均属于频繁集,因为只有3个频繁1-项集,所以从3个中选择两个产生2-项集,2项集数目为
C
3
2
=
3
C^2_3=3
C32=3,计算它们在所有事务中的支持度,发现2-项集中频繁项集只有一个{苹果,黄油};最终的频繁项集就是{苹果,黄油}。

二、python实战
import numpy as np
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules #关联规则
data = pd.read_csv('GoodsOrder.csv',sep=',',index_col=0,encoding='gbk')
df = pd.crosstab(index=data.index,columns=data.goods)
df
goods 牛奶 苹果 面包 香蕉 黄油
row_0
1 0 1 0 1 1
2 1 1 1 0 0
3 0 1 1 0 1
4 0 1 0 1 1
5 1 0 0 1 0
frequent=apriori(df,min_support=0.3,use_colnames=True) #设置最小支持度为0.3,求频繁项集,显示列标签名
rules=association_rules(frequent,metric='confidence',min_threshold=0) #置信度大于0.5,求关联规则
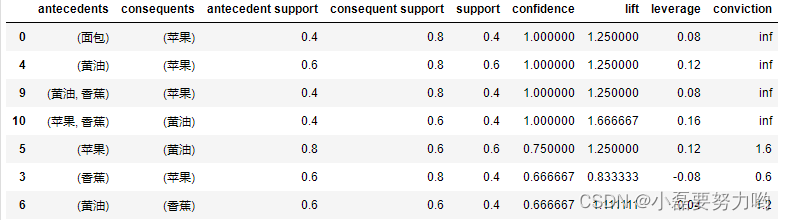
rules.sort_values(by='confidence',ascending=False)
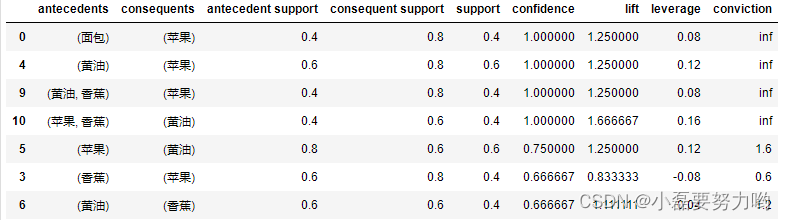
- 结果解释:三项集中置信度最高的是 ( 黄 油 , 香 蕉 ) → ( 苹 果 ) ( 黄油,香蕉 )\rightarrow(苹果) (黄油,香蕉)→(苹果)和 ( 苹 果 , 香 蕉 ) → ( 黄 油 ) ( 苹果,香蕉 )\rightarrow(黄油) (苹果,香蕉)→(黄油),项集 ( 黄 油 , 香 蕉 ) → ( 苹 果 ) ( 黄油,香蕉 )\rightarrow(苹果) (黄油,香蕉)→(苹果)说明在购买了黄油和香蕉的前提下,一定会购买苹果;且它们的提升度>1,说明有着较强的相关性。
- 列名含义:针对规则{A}->{B},总事务数为N
| 列名 | 解释 | 公式 |
|---|---|---|
| antecedents | 前件 | A |
| consequents | 后件 | B |
| antecedent support | 前件支持度 | s u p p o r t ( A ) = N ( A ) / N support(A)=N(A)/N support(A)=N(A)/N |
| consequent support | 后件支持度 | s u p p o r t ( B ) = N ( B ) / N support(B)=N(B)/N support(B)=N(B)/N |
| support | 规则支持度 | s u p p o r t ( A → B ) = N ( A , B ) / N support({A}\rightarrow{B})=N(A,B)/N support(A→B)=N(A,B)/N |
| confidence | 置信度 | c o n f i d e n c e ( A → B ) = N ( A , B ) / N ( A ) confidence({A}\rightarrow{B})=N(A,B)/N(A) confidence(A→B)=N(A,B)/N(A) |
| lift | 提升度 | l i f t ( A → B ) = c o n f i d e n c e ( A → B ) / s u p p o r t ( B ) lift({A}\rightarrow{B})=confidence({A}\rightarrow{B})/support(B) lift(A→B)=confidence(A→B)/support(B) |
| leverage | 杠杆率 | l e v e r a g e ( A → B ) = s u p p o r t ( A → B − s u p p o r t ( A ) ∗ s u p p o r t ( B ) ) leverage({A}\rightarrow{B})=support({A}\rightarrow{B}-support(A)*support(B)) leverage(A→B)=support(A→B−support(A)∗support(B)) |
| conviction | c o n v i c t i o n ( A → B ) = 1 − s u p p o r t ( B ) 1 − c o n f i d e n c e ( A → B ) conviction({A}\rightarrow{B})=\frac{1-support(B)}{1-confidence({A}\rightarrow{B})} conviction(A→B)=1−confidence(A→B)1−support(B) |
参考:
《数据挖掘导论》 范明 译

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)