
数据挖掘——PageRank算法
PageRank算法:计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。
源代码:数据挖掘——PageRank算法Java-CSDN博客
一、背景介绍
PageRank算法:计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。
二、实验内容
实验原理
PageRank算法的基本想法是在有向图上定义一个随机游走模型,即一阶马尔可夫链,描述随机游走者沿着有向图随机访问各个结点的行为。在一定条件下,极限情况访问每个结点的概率收敛到平稳分布,各结点的平稳概率值就是其PageRank值,表示结点的重要度。
PageRank算法的核心部分可以从一个有向图开始。最典型的方法是根据有向图构造邻接矩阵来进行处理。邻接矩阵A=(a[i,j])中的元素ai,j表示从页面j指向页面i的概率。
基本的PageRank算法在计算等级值时,每个页面都将自己的等级值平均地分配给其引用的页面节点。假设页面的等级值为1,该页面上共有n个超链接,分配给每个超链接页面的等级值就是1/n,那么就可以理解为该页面以1/n的概率跳转到任意一个其所引用的页面上。
一般地,把邻接矩阵A转换成所谓的转移概率矩阵M来实现PageRank算法:
M=(1-d)Q+dA
其中,Q是一个常量矩阵,最常用的是Q=(q[i,j]),q[i,j]=1/n。
转移概率矩阵M可以作为一个向量变换矩阵来帮助完成页面等级值向量R的迭代计算:
R[i+1]=M*R[i]
页面之间的超链接分析通常基于以下假设:
(1)若页面A上存在指向页面B的超链接,就认为页面A对页面B进行了一次参考引用;
(2)一个页面被越多的其他页面指向,越能说明这个页面等级越高;
(3)每个页面都有一个衡量其重要性的参数值(等级值),并且会将这一参数值平均地分配给它指向的全部页面。
流程图:

算法:

步骤:
(1)初始化每个网页的权重值,可以将它们的权重值都设置为1。
(2)根据每个网页的入链和出链,计算每个网页的权重值。具体地,将每个网页的权重值按照出链的数量平均分配给它所指向的网页。
(3)循环迭代上述步骤,直到每个网页的权重值收敛,即不再发生变化。
(4)根据每个网页的权重值进行排序,得到网页的排名。
关键源代码:
①计算两个向量之间的距离
public static double calDistance(List<Double> q1, List<Double> q2) {
double sum = 0;
if (q1.size() != q2.size()) {
return -1;
}
for (int i = 0; i < q1.size(); i++) {
sum += Math.abs(q1.get(i).doubleValue() - q2.get(i).doubleValue());
}
return sum;
}
②计算获得初始的G矩阵
public static List<List<Double>> getG(double a) {
int n = getS().size();
List<List<Double>> aS = numberMulMatrix(getS(), a);
List<List<Double>> nU = numberMulMatrix(getU(), (1 - a) / n);
List<List<Double>> g = addMatrix(aS, nU);
return g;
}
③计算一个矩阵乘以一个向量
public static List<Double> vectorMulMatrix(List<List<Double>> m, List<Double> v) {
if (m == null || v == null || m.size() <= 0 || m.get(0).size() != v.size()) {
return null;
}
List<Double> list = new ArrayList<Double>();
for (int i = 0; i < m.size(); i++) {
double sum = 0;
for (int j = 0; j < m.get(i).size(); j++) {
double temp = m.get(i).get(j).doubleValue() * v.get(j).doubleValue();
sum += temp;
}
list.add(sum);
}
return list;
}
④计算两个矩阵的和
public static List<List<Double>> addMatrix(List<List<Double>> list1, List<List<Double>> list2) {
List<List<Double>> list = new ArrayList<List<Double>>();
if (list1.size() != list2.size() || list1.size() <= 0 || list2.size() <= 0) {
return null;
}
for (int i = 0; i < list1.size(); i++) {
list.add(new ArrayList<Double>());
for (int j = 0; j < list1.get(i).size(); j++) {
double temp = list1.get(i).get(j).doubleValue() + list2.get(i).get(j).doubleValue();
list.get(i).add(new Double(temp));}
}
return list;
}⑤计算一个数乘以矩阵
public static List<List<Double>> numberMulMatrix(List<List<Double>> s, double a) {
List<List<Double>> list = new ArrayList<List<Double>>();
for (int i = 0; i < s.size(); i++) {
list.add(new ArrayList<Double>());
for (int j = 0; j < s.get(i).size(); j++) {
double temp = a * s.get(i).get(j).doubleValue();
list.get(i).add(new Double(temp));}
}
return list;
}⑥对网页的重要性进行排序
public static void sortPageRank(List<String> webPages, List<Double> pageRank) {
Map<String, Double> pageRankMap = new HashMap<>();
for (int i = 0; i < webPages.size(); i++) {
pageRankMap.put(webPages.get(i), pageRank.get(i));
}
List<Map.Entry<String, Double>> list = new ArrayList<>(pageRankMap.entrySet());
list.sort(Map.Entry.comparingByValue(Comparator.reverseOrder()));
System.out.println("网页重要性排序:");
for (Map.Entry<String, Double> entry : list) {
System.out.println("网页 " + entry.getKey() + " "+entry.getValue());
}
}三、实验结果与分析


如果一个网页有k条出链,那么跳转到任意一个出链上的概率是1/k,一般用转移矩阵来表示页面间的跳转概率,如果用n表示网页的数目,则转移矩阵M是一个n*n的方阵;如果页面j有k个出链,那么对每一个出链指向的页面i,有Mi=1/k,而其他网页的Mi=0;该实验的转移矩阵:
初始时,假设上网者在每个页面的概率都是相等的,即1/n,于是初始的概率分布就是一个所有值都为1/n的n维列向量,用去右乘转移矩阵,就得到了第一步之后上网者的概率分布向量,依旧得到一个的矩阵。下面是计算过程: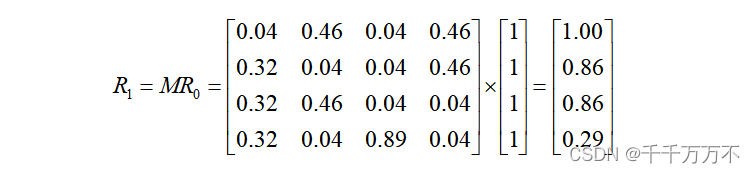

得到了R1后,再用R1去右乘M得到R2,一直下去,直到 。
。
一个网页,如果指向该网页的PageRank值越高,随机跳转到该网页的概率也就越高,该网页的PageRank值就越高,这个网页也就越重要。在该实验中收敛于第5次迭代,根据网页的PageRank值对它的重要性进行排序,在该实验中排序为:D>A>B>C。
四、小结与心得体会
如果一个页面,入链比较多,也就是跳转过去的概率比较大的时候,这个页面往往就比较重要,影响力高一些;如果某个页面本身的影响力很大,那么也会相应的增加它出链指向的页面影响力。
阻尼系数d的作用是让PageRank的计算更加准确。使用了阻尼系数来控制PageRank值的收敛速度。阻尼系数通常取0.85,表示网页跳转时有15%的概率随机跳转到其他网页。如果没有阻尼系数,假设有一个小网站仅包含一个页面,那么这个页面将获得所有其他页面的投票,其PageRank值会极高,显然这是不合理的。而阻尼系数在一定程度上限制了这种情况的发生,使得大网站和小网站之间的PageRank差距更加明显。
PageRank比较简单,但是可能会存在等级泄露和等级沉没两个问题:
等级泄露:如果一个网页没有出链,就像是一个黑洞一样,吸收了其他网页的影响力而不释放,最终会导致其他网页的PR值为0。
等级沉没:如果一个网页只有出链,没有入链计算的过程迭代下来,会导致这个网页的PR值为0(也就是不存在公式中的V)。
优点:是一个与查询无关的静态算法,全部网页的PageRank值通过离线计算获得;有效降低在线查询时的计算量,极大降低了查询响应时间。
缺点:人们的查询具有主题特征,PageRank忽略了主题相关性,导致结果的相关性和主题性减少;旧的页面等级会比新页面高。由于即使是非常好的新页面也不会有非常多上游链接,除非它是某个网站的子网站。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 25
25 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)