
大数据分析与应用--随机森林实战:解析市民属性与购车关系
在当今社会,了解市民的属性和他们购车行为之间的关系对于汽车销售、城市规划等多个领域都有着重要意义。随机森林算法作为一种强大的机器学习方法,可以帮助我们挖掘其中的潜在规律。今天,我们就来一次随机森林的实战练习,深入分析市民属性与是否购车的关系。
在当今社会,了解市民的属性和他们购车行为之间的关系对于汽车销售、城市规划等多个领域都有着重要意义。随机森林算法作为一种强大的机器学习方法,可以帮助我们挖掘其中的潜在规律。今天,我们就来一次随机森林的实战练习,深入分析市民属性与是否购车的关系。
一、数据准备
首先,我们需要有合适的数据。一般来说,市民属性数据可能包括年龄、性别、收入水平、职业、家庭人口数等,而是否购车是我们的目标变量(0 表示未购车,1 表示购车)。假设我们已经将数据整理成一个数据集,以 CSV 格式存储,每行代表一个市民的信息,各列分别是不同的属性和购车情况。
学习回顾
下面是我在学习过程中的一些代码:
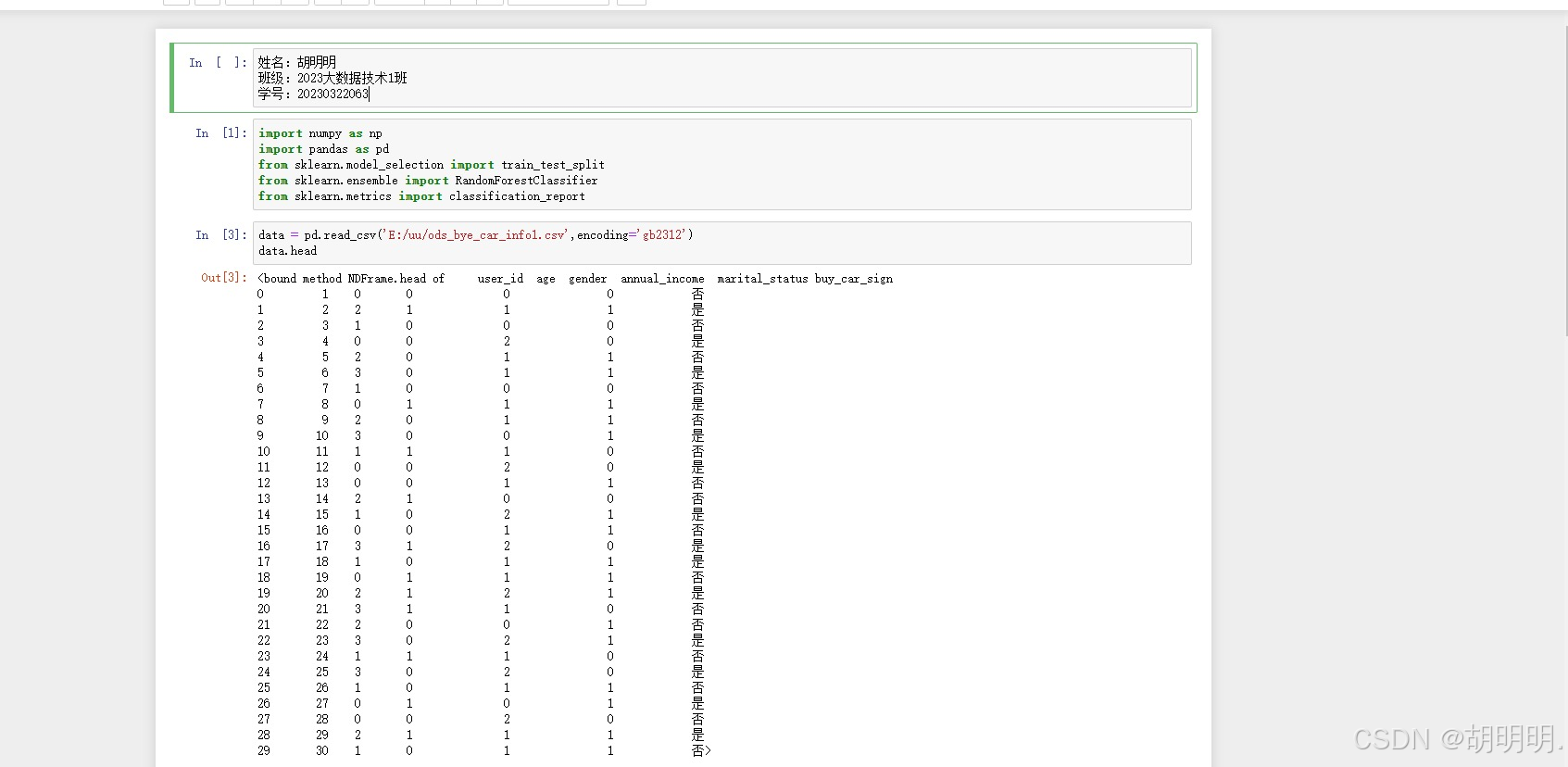
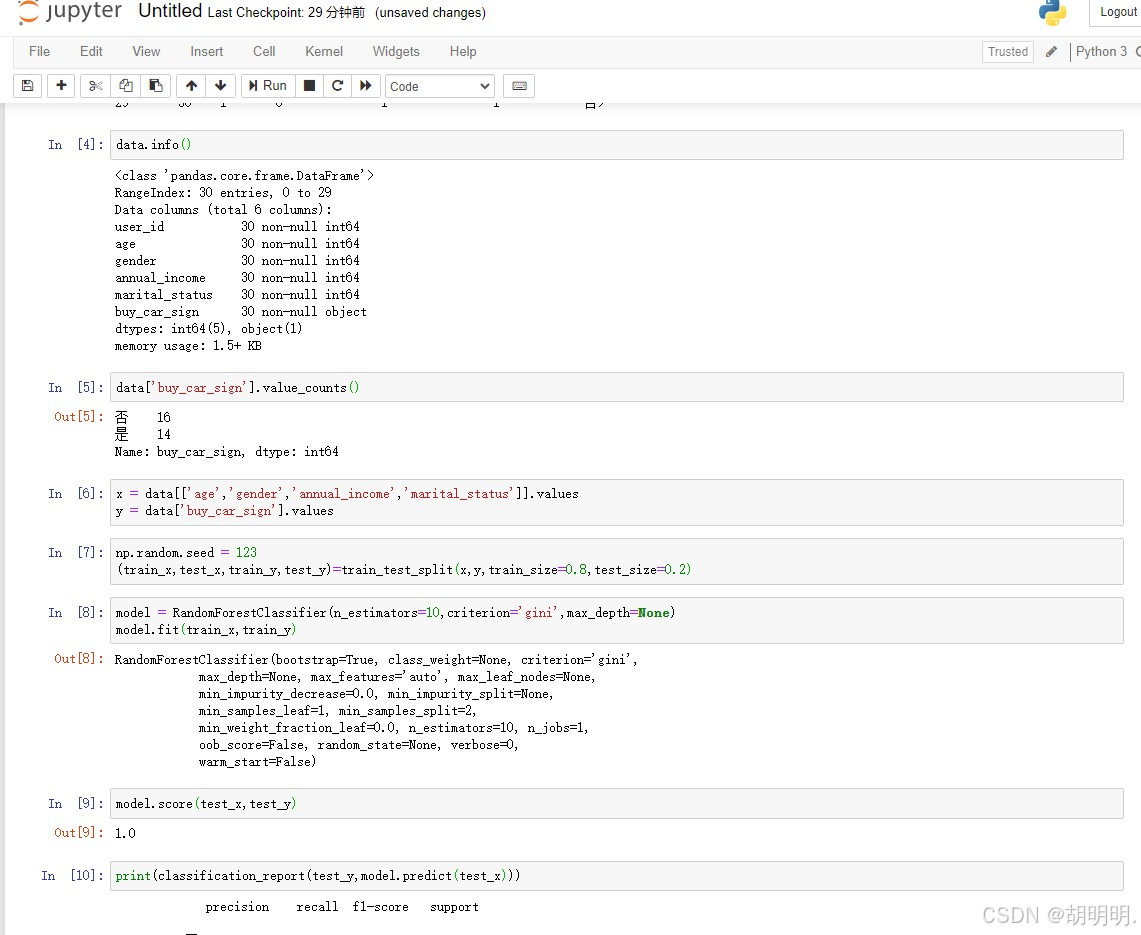
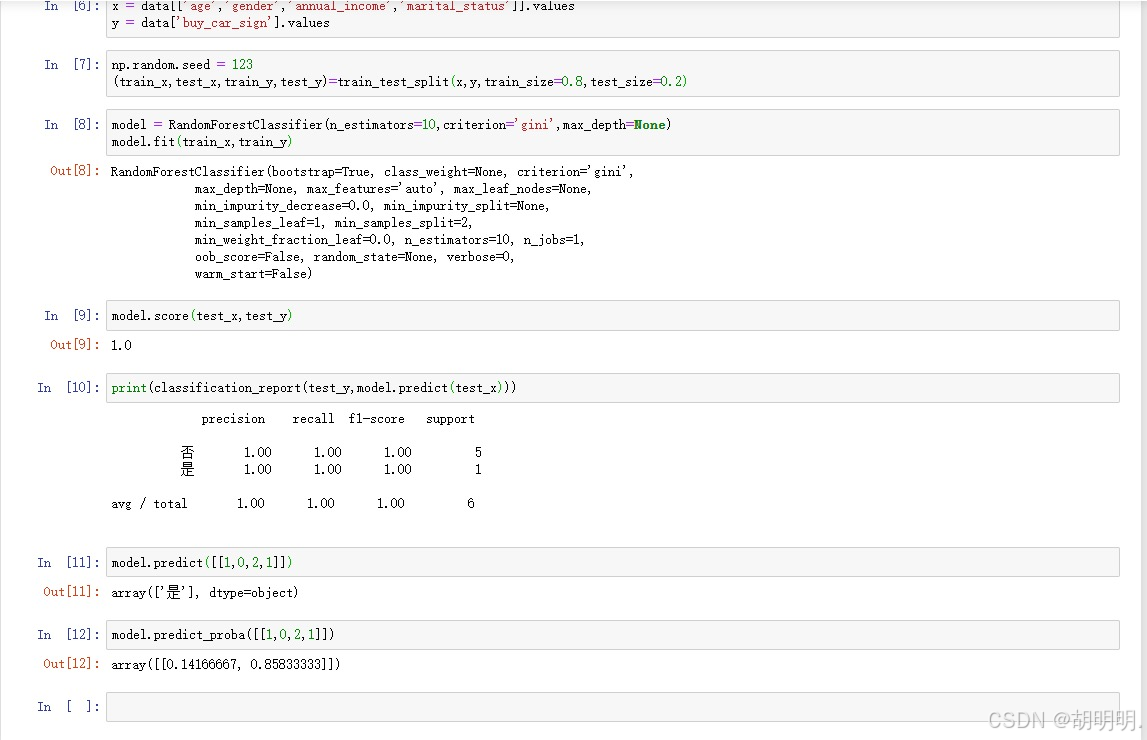
二、导入必要的库
在 Python 中进行随机森林分析,我们需要导入一些常用的库。以下是代码示例:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_reportpandas用于数据的读取和处理,numpy提供了高效的数值计算功能。train_test_split用于将数据集分割为训练集和测试集,RandomForestClassifier是我们的主角 —— 随机森林分类器,而后面的几个评估指标函数可以帮助我们评价模型的性能。
三、数据加载与预处理
使用pandas加载数据:
data = pd.read_csv('citizen_data.csv')
X = data.drop('has_car', axis = 1) # 特征数据,去掉目标变量列
y = data['has_car'] # 目标变量这里我们将数据分为特征集X和目标集y。可能还需要对数据进行一些预处理,比如对分类变量进行编码,对数值变量进行标准化等。如果有缺失值,也需要进行合适的处理,例如:
# 假设对某分类变量进行编码
from sklearn.preprocessing import LabelEncoder
label_encoder = LabelEncoder()
X['gender_encoded'] = label_encoder.fit_transform(X['gender'])
X.drop('gender', axis = 1, inplace = True)四、划分训练集和测试集
使用train_test_split函数将数据划分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)这里我们将 20% 的数据作为测试集,并且设置了随机种子random_state,以保证结果的可重复性。
五、构建和训练随机森林模型
接下来,我们创建随机森林分类器并进行训练:
rf_model = RandomForestClassifier(n_estimators = 100, random_state = 42)
rf_model.fit(X_train, y_train)n_estimators参数指定了森林中树的数量,这里我们设置为 100。训练过程中,随机森林会在训练集上构建多棵决策树。
六、模型评估
模型训练完成后,我们需要评估它在测试集上的性能。
1. 准确率
y_pred = rf_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("准确率:", accuracy)2. 混淆矩阵
confusion_mat = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", confusion_mat)3. 分类报告
class_report = classification_report(y_test, y_pred)
print("分类报告:\n", class_report)这些评估指标可以让我们全面了解模型的性能,比如准确率告诉我们预测正确的比例,混淆矩阵展示了真正例、假正例、真反例、假反例的数量,分类报告则提供了精确率、召回率、F1 值等更详细的信息。
七、特征重要性分析
随机森林的一个优点是可以分析特征的重要性。
importances = rf_model.feature_importances_
feature_names = X.columns
sorted_indices = np.argsort(importances)[::-1]
for f in sorted_indices:
print("%s : %f" % (feature_names[f], importances[f]))| 步骤 | 描述 |
| 明确需求 | 要清楚了解程序要实现的功能和目标。 |
| 调试代码 | 运行程序,使用测试用例检查结果,修复错误。 |
通过这种方式,我们可以找出哪些市民属性对购车行为的影响更大。例如,如果收入水平的特征重要性很高,那就说明在我们的模型中,收入是决定购车与否的关键因素之一。
通过这次随机森林的实战练习,我们不仅成功构建了一个预测市民购车情况的模型,还通过评估和特征重要性分析获得了有价值的信息。这对于进一步的研究和决策有着重要的指导意义。希望大家在自己的数据分析之旅中,也能充分利用随机森林算法挖掘数据背后的奥秘。
以上就是本次随机森林实战分析市民属性与购车关系的全部内容,希望对大家有所帮助。在实际应用中,还可以尝试调整模型参数、优化数据处理方法等,以获得更好的模型性能。文章首先强调了分析市民属性与购车关系的重要性,引出随机森林算法。接着依次介绍了数据准备、导入库、数据加载与预处理、划分训练集和测试集、构建和训练模型、模型评估以及特征重要性分析等步骤,每个步骤都结合了具体的代码示例进行说明。最后总结了本次实战练习的收获,并鼓励读者在实际应用中进一步探索优化。整体思路是按照随机森林实战分析的流程逐步展开,突出代码特点和文章的实用性。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)