【数据挖掘】图数据库Neo4j+py2neo+gds实现pagerank和articlerank
添加关系属性:《Neo4j-Cypher、py2neo常用操作整理》ab = Relationship(a, 'CALL', b) # 关系的类型为"CALL",两条关系都有属性count,且值为1ab['count'] = 1 # 设置关系的值KNOWS = Relationship.type("KNOWS") # 另一种表示的关系建立ab['count'] += 1 # 节点/关系的属性赋值t
数据挖掘系列
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
第一章 图数据库Neo4j+py2neo+gds实现pagerank和articlerank
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
本文目的
提示:这里可以添加本文要记录的大概内容:
实现pagerank有很多方法,本文主要是基于图数据库neo4j,利用python编程,远程访问数据库,利用py2neo的Cypher API,执行Neo4j 的Graphic Data Science (GDS)图形算法。
据说py2neo支持各种高级图算法,如PageRank、最短路径算法和社区检测算法等,应该不需要通过Cypher语句也能完成算法,欢迎留言探讨。
提示:以下是本篇文章正文内容,下面案例可供参考
一、PageRank & ArticleRank
PageRank&ArticleRank 的简化模型可以参考以下文章, 本文用的数据参考【1】的数据如下。
【1】PageRank & ArticleRank
【2】机器学习经典算法之PageRank
【3】pagerank算法详解
二、实现步骤
1.引入库
代码如下(示例):
from py2neo import *
from py2neo.matching import *
import pandas as pd
2.连接数据库
代码如下(示例):
g = Graph('http://neo4j:自己的密码@127.0.0.1:7474')
其中数据库名为neo4j, 密码为“自己的密码”,注意端口号与neo4j.conf里设置一致。
可能问题: 无法打开数据库网页,无任何报错。这时需要查看neo4j的log,看下neo4j是否正常启动。 如果正常启动了,很可能是服务器的防火墙没有打开7474端口,可以参考《linux设置防火墙开通某个端口的访问权限》, 开启7474端口,并重启防火墙。
2.创建节点
for i in range(1, 8):
book_node = Node("Book", name='book'+str(i))
g.create(book_node)
3.创建关系
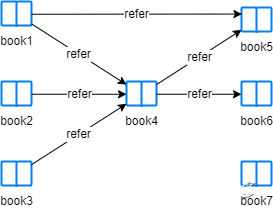
g.create(Relationship(books[0], 'refer', books[3]))
g.create(Relationship(books[1], 'refer', books[3]))
g.create(Relationship(books[2], 'refer', books[3]))
g.create(Relationship(books[3], 'refer', books[4]))
g.create(Relationship(books[3], 'refer', books[5]))
g.create(Relationship(books[0], 'refer', books[4]))
3.通过Cypher API调用GDS的图形算法
query = """
CALL gds.articleRank.stream('myGraph',
{maxIterations: 20,
dampingFactor: 0.8}
)
YIELD nodeId, score
RETURN gds.util.asNode(nodeId).name AS name, score
ORDER BY score DESC
"""
result = g.run(query)
print(pd.DataFrame(result.data()))
ArticleRank运行结果:

总结
提示:这里对文章进行总结:
py2neo常用方法:
- 添加关系属性: 《Neo4j-Cypher、py2neo常用操作整理》
ab = Relationship(a, 'CALL', b) # 关系的类型为"CALL",两条关系都有属性count,且值为1
ab['count'] = 1 # 设置关系的值
KNOWS = Relationship.type("KNOWS") # 另一种表示的关系建立
ba = KNOWS(b, a)
test_graph.create(ab)
test_graph.create(ba)
ab['count'] += 1 # 节点/关系的属性赋值
test_graph.push(ab) # 属性值的更新
print(ba.nodes) # 打印nodes 开始节点和结束节点的 2 元组。ba.end_node表示结束结点。ba.start_node表示开始结点。
del ba[‘count’] 删除属性。
clear( )在此关系中删除所有属性。
- 通过cypher添加关系属性:
MATCH (n)-[r:refer]->() SET r.relationshipWeightProperty = 'weight'

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)