数据仓库与数据挖掘 6(上)
关联规则最早是由Agrawal等人提出的(1993)。最初提出的动机是针对购物篮分析(Basket Analysis)问题提出的,其目的是为了发现交易数据库(Transaction Database)中不同商品之间的联系规则。相信大家都听说过“啤酒和尿布”的故事,这就是关联规则挖掘知识的乐趣所在,有时候会找到一些不是日常认知的规则。关联规则的表示关联规则通常用蕴含式表示:A→BA \rightar
关联规则
最早是由Agrawal等人提出的(1993)。最初提出的动机是针对购物篮分析(Basket Analysis)问题提出的,其目的是为了发现交易数据库(Transaction Database)中不同商品之间的联系规则。
相信大家都听说过“啤酒和尿布”的故事,这就是关联规则挖掘知识的乐趣所在,有时候会找到一些不是日常认知的规则。
关联规则的表示
关联规则通常用蕴含式表示:
A → B A \rightarrow B A→B
其中A,B为事务项集,一般而言,A B没有公共项。
ps:AB不交是显然的,比如说 { 泡 面 , 火 腿 肠 } → { 泡 面 } \{泡面,火腿肠\} \rightarrow \{泡面\} {泡面,火腿肠}→{泡面} ,这,这,这不废话吗。。。
我们仔细观察这个蕴含式,回想一下蕴含式的定义
设 p,q为二命题,复合命题“如果p,则q”称作p与q的蕴涵式。
记作 p → q p\rightarrow q p→q,并称p是蕴涵式的前件,q为蕴涵式的后件。
p → q p\rightarrow q p→q的逻辑关系:p为q的充分条件,或者q 为 p 的必要条件
按照通俗的话理解就是,A为原因,B为结果;如果出现A 则大概率出现B。
这样一个通俗的方法可以帮我们解决很多日常问题:
1)如果今天出现晚霞,则明天大概率晴天,那么我们就可以在出现晚霞的时候决定明天的行程。
2)如果用户买了泡面,那么大概率买香肠,那么我们就可以捆绑销售或者促销其中一个带动消费。
等等。。。。
唉,仿佛这个算法道理很简单嘛
就是有两个问题:
怎么样的关联规则(蕴含式)是好的呢(概率怎么算)?
概率高的关联规则就一定是有用的吗?
一一解答。
关联规则的度量
我们前面也说过,这个通俗的道理是按照出现的可能性来衡量的,将可能性量化就是我们的概率。在概率学中有一个学派叫贝叶斯学派(关于贝叶斯学派的理论请自行查找),提出了著名的贝叶斯公式
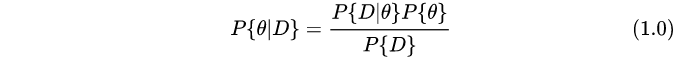
其中
P
(
θ
∣
D
)
P(\theta|D)
P(θ∣D)称为后验概率,指的是由观察数据和先验假设推测出来的参数分布,而
P
(
θ
)
P(\theta)
P(θ)称之为先验分布,指的是对于参数的专家知识或者假设而引入的知识,可以指导参数
θ
\theta
θ的学习,而
P
(
D
∣
θ
)
P(D|\theta)
P(D∣θ)称之为似然函数,指的就是由于观察数据导致的参数更新。
其实没有那么高深,对于贝叶斯公式而言还有一个变形
P ( A ∣ B ) = P ( A B ) / P ( B ) P(A|B)=P(AB)/P(B) P(A∣B)=P(AB)/P(B)
通常用白话理解就是:在B的作业条件下,A发生的概率!(贝叶斯学说,在观察数据后对参数分布的修正),是不是和前面蕴含式很像。
A → B A \rightarrow B A→B:如果A则B,在数学上考虑这条蕴含式发生的可能性,是不是就是考虑A出现条件下,B发生的概率!
所以我们有了第一个衡量标准:
关联规则的置信度
C o n f i d e n c e ( A → B ) = P ( A B ) / P ( A ) = P ( B ∣ A ) Confidence(A \rightarrow B)=P(AB)/P(A)=P(B|A) Confidence(A→B)=P(AB)/P(A)=P(B∣A)
P ( A B ) P(AB) P(AB)表示AB一起出现的概率。
在自然社会中,我们一般要求概率达到一定阈值就可以了,所以通常设定一个最小置信度 c o n f m i n conf_{min} confmin,只要 C o n f i d e n c e ( A → B ) > = c o n f m i n Confidence(A \rightarrow B)>=conf_{min} Confidence(A→B)>=confmin,就称关联规则为可信的。
那现在问题又来了,光是可信可以吗?
举个栗子。
假设一个超市有很多条购物单,商家希望在这么多条记录中找到好的关联规则,在挖掘的过程中发现,有一条记录是 {钻戒,牛奶,五花肉}(唯一一条在超市买钻戒的购物单,不要问为什么超市卖钻戒),根据经验频率估计概率可以得到:
c
o
n
f
(
钻
戒
→
五
花
肉
)
=
P
(
钻
戒
,
五
花
肉
)
/
P
(
钻
戒
)
=
(
钻
戒
,
五
花
肉
一
起
出
现
次
数
)
/
(
总
购
物
记
录
数
)
(
钻
戒
出
现
次
数
)
/
(
总
购
物
记
录
数
)
=
(
钻
戒
,
五
花
肉
一
起
出
现
次
数
)
(
钻
戒
出
现
次
数
)
=
1
/
1
=
1
conf(钻戒 \rightarrow 五花肉)=P(钻戒,五花肉)/P(钻戒)\\= \frac{(钻戒,五花肉一起出现次数)/(总购物记录数)}{(钻戒出现次数)/(总购物记录数)}\\=\frac{(钻戒,五花肉一起出现次数)}{(钻戒出现次数)}=1/1=1
conf(钻戒→五花肉)=P(钻戒,五花肉)/P(钻戒)=(钻戒出现次数)/(总购物记录数)(钻戒,五花肉一起出现次数)/(总购物记录数)=(钻戒出现次数)(钻戒,五花肉一起出现次数)=1/1=1
哎哟,这个是1呀,可信度也太高了,可是真的有用吗:
如果顾客购买钻戒,那么他/她大概率购买五花肉

问题出在哪里?
因为没什么人在超市卖钻戒呀!
案例过于独特,不够频繁。
关联规则的支持度
我们希望关心的项集是频繁的,也就是在总交易集中,目标项集出现的次数足够多。
假设商场的交易总数为 ∣ D ∣ |D| ∣D∣,那么项集 I I I的支持度 S u p p o r t ( I ) Support(I) Support(I)(频繁程度)为
S u p p o r t ( I ) = ( I 出 现 次 数 ) ∣ D ∣ = P ( I ) Support(I)=\frac{(I出现次数)}{|D|}=P(I) Support(I)=∣D∣(I出现次数)=P(I)
同样的,我们一般要求概率达到一定阈值就可以了,所以通常设定一个最小支持度 s u p m i n sup_{min} supmin,只要 S u p p o r t ( I ) > = s u p m i n Support(I)>=sup_{min} Support(I)>=supmin,就称项集为频繁集。
假设商场的交易总数为 ∣ D ∣ |D| ∣D∣,那么关联规则的支持度 S u p p o r t ( A → B ) Support(A \rightarrow B) Support(A→B)(频繁程度)为
S u p p o r t ( A → B ) = ( A B 一 起 出 现 次 数 ) ∣ D ∣ = P ( A B ) Support(A \rightarrow B)=\frac{(AB一起出现次数)}{|D|}=P(AB) Support(A→B)=∣D∣(AB一起出现次数)=P(AB)
就是AB一起出现的概率有木有。出现的概率足够高,那么说明AB在一起发生足够频繁!
只要 S u p p o r t ( A → B ) > = s u p m i n Support(A \rightarrow B)>=sup_{min} Support(A→B)>=supmin,就称关联规则为频繁的。
强关联规则
当关联规则 A → B A \rightarrow B A→B满足:
1. S u p p o r t ( A → B ) > = s u p m i n Support(A \rightarrow B)>=sup_{min} Support(A→B)>=supmin;
2. C o n f i d e n c e ( A → B ) > = c o n f m i n Confidence(A \rightarrow B)>=conf_{min} Confidence(A→B)>=confmin;
时候,我们称之为强关联规则。
也就是我们关心的好的规则(二者缺一不可)。
这里值得注意一点 对于支持度而言,关联规则蕴含式的前后顺序并不重要,都是一样的,考虑是二者一起出现的概率 而对于置信度而言就不一样了,因为
P
(
A
∣
B
)
≠
P
(
B
∣
A
)
P(A|B) \neq P(B|A)
P(A∣B)=P(B∣A)
强关联规则一定是有趣的吗?
我们看个栗子:
假设在1000个事务中,数据显示700个螺蛳粉商品,800个包含豆花商品。500个同时包含二者。假设min_sup=0.5,min_conf=0.6
因此考虑关联规则 :“ 螺 蛳 粉 → 豆 花 螺蛳粉 \rightarrow 豆花 螺蛳粉→豆花”,有:
support=500/1000=0.5 >=0.5, confidence=500/700=0.71>=0.6
很强对不对,但是明明豆花单独售出的概率就已经是800/1000=0.8>0.71了,也就是说,在螺蛳粉的作用之下,豆花售出的概率反而下降了,放在实际生活中,倘若螺蛳粉和豆花一起卖,并不会提升豆花的销售量,反而下降。
那么,这样的强关联规则就不一定是有趣的。
关联规则的提升度
仔细观察上述的例子,其根本原因是
螺蛳粉和豆花的销售是负相关的
上述案例已知:支持度和置信度度量不足以过滤掉无趣的关联规则。还需要考虑项集之间的相关性。
相关性度量扩充支持度—置信度框架
也就是说,相关规则不仅用支持度和置信度度量,而且还用项集A和B之间的相关性度量。有许多不同的相关性度量可供选择。
如果A,B独立 则有 𝑃(𝐴∪𝐵)=𝑃(𝐴)𝑃(𝐵) ;否则,A,B是有相关性的(依赖)
因此A,B出现之间的提升度可以定义为 𝑙 𝑖 𝑓 𝑡 ( 𝐴 , 𝐵 ) = 𝑃 ( 𝐴 ∪ 𝐵 ) / 𝑃 ( 𝐴 ) 𝑃 ( 𝐵 ) 𝑙𝑖𝑓𝑡(𝐴,𝐵)=𝑃(𝐴∪𝐵)/𝑃(𝐴)𝑃(𝐵) lift(A,B)=P(A∪B)/P(A)P(B)
𝑙𝑖𝑓𝑡(𝐴,𝐵)<1,则A、B负相关; 𝑙𝑖𝑓𝑡(𝐴,𝐵)>1,则A,B正相关
𝑙
𝑖
𝑓
𝑡
(
𝐴
,
𝐵
)
=
𝑃
(
𝐴
∪
𝐵
)
/
𝑃
(
𝐴
)
𝑃
(
𝐵
)
=
𝑃
(
𝐴
│
𝐵
)
/
𝑃
(
𝐴
)
𝑙𝑖𝑓𝑡(𝐴,𝐵)=𝑃(𝐴∪𝐵)/𝑃(𝐴)𝑃(𝐵) =𝑃(𝐴│𝐵)/𝑃(𝐴)
lift(A,B)=P(A∪B)/P(A)P(B)=P(A│B)/P(A)
也称为关联(相关)规则
A
→
B
A \rightarrow B
A→B的提升度
换言之,它评估一个的出现“ 提升”另一个出现的程度。
因此,在考虑强关联规则时,再加入一个度量标准:𝑙𝑖𝑓𝑡>1
数据仓库与数据挖掘 6 (中)点击这里查看
参考
图片来源:添加链接描述
陈志泊 主编. 数据仓库与数据挖掘(第二版). 清华大学出版社,2019

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

{kind=link}
所有评论(0)