
pandas数据可视化-CDA数据分析师
在完整的数据分析工作流程里面,除了对数据进行清洗处理分析的环节,还包括对分析结果进行可视化输出。本次文章就来简单介绍一下围绕pandas进行的数据可视化输出,主要包括表格样式和图表可视化。
本文将被收录在CDA打卡系列专栏,更多相关文章可以在里面查找
前言
在完整的数据分析工作流程里面,除了对数据进行清洗处理分析的环节,还包括对分析结果进行可视化输出。本次文章就来简单介绍一下围绕pandas进行的数据可视化输出,主要包括表格样式和图表可视化。
表格样式
按照惯例,DataFrame的打印默认是一个表格,我们可以对表格样式进行一些设置,就像Excel那样
import pandas as pd
import numpy as np
df = pd.DataFrame(
{'A': ['孙云', '郑成', '冯敏', '王忠', '郑花', '孙华', '赵白', '王花', '黄成', '钱明', '孙宇'],
'B': [79, 70, 39, 84, 87, 26, 29, 47, 32, 22, 99],
'C': [28, 77, 84, 26, 29, 47, 32, 22, 99, 76, 44],
'D': [18, 53, 78, 4, 36, 88, 79, 47, 54, 25, 14]})
df
A B C D 0 孙云 79 28 18 1 郑成 70 77 53 2 冯敏 39 84 78 3 王忠 84 26 4 4 郑花 87 29 36 5 孙华 26 47 88 6 赵白 29 32 79 7 王花 47 22 47 8 黄成 32 99 54 9 钱明 22 76 25 10 孙宇 99 44 14
通过自定义函数设置字体颜色
def color_negative_red(val):
color = 'red' if val > 80 else 'black'
return f'color: {color}'
df.set_index('A').style.map(color_negative_red)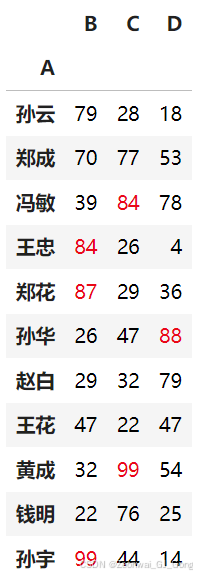
根据空值设置单元格背景颜色
df1 = df.copy()
df1.iloc[1, 1] = np.nan
df1.iloc[2, 1] = np.nan
df1
A B C D 0 孙云 79.0 28 18 1 郑成 NaN 77 53 2 冯敏 NaN 84 78 3 王忠 84.0 26 4 4 郑花 87.0 29 36 5 孙华 26.0 47 88 6 赵白 29.0 32 79 7 王花 47.0 22 47 8 黄成 32.0 99 54 9 钱明 22.0 76 25 10 孙宇 99.0 44 14
df1.style.highlight_null(color='lightgray')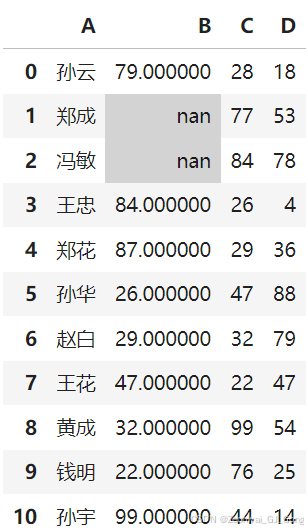
高亮背景标记最大最小值
df.set_index('A').style.highlight_max(color='red').highlight_min(color='yellow')
背景颜色按数值渐变
df.style.background_gradient()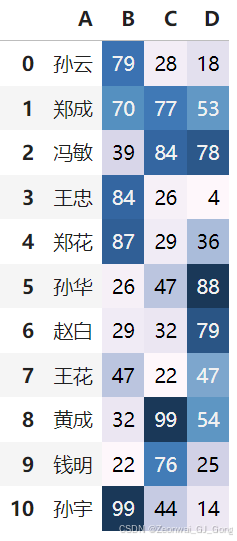
通过subset参数选取子列应用渐变背景
df.style.background_gradient(subset=['B'], cmap='BuGn')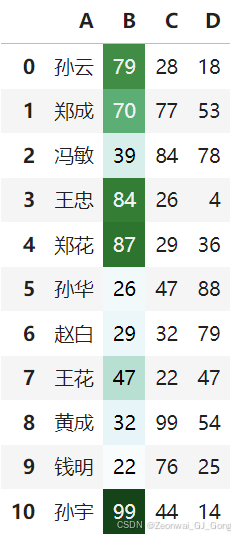
给出渐变起始的最小值和结束的最大值并设置表格标题
df.style.background_gradient(vmin=60, vmax=100).set_caption('三年级二班学生成绩表')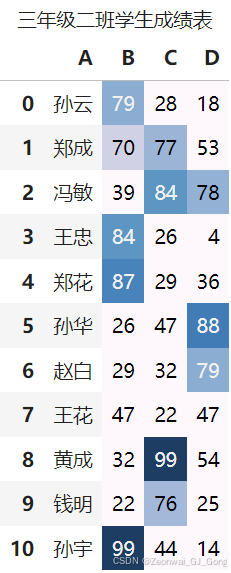
表格样式案例
以下分享两个应用表格样式的案例
案例一,对科目分数小于60分的用红色背景高亮突出显示
df.style.map(lambda x: 'background-color: red' if x < 60 else "",
subset=pd.IndexSlice[:, ['B', 'C', 'D']])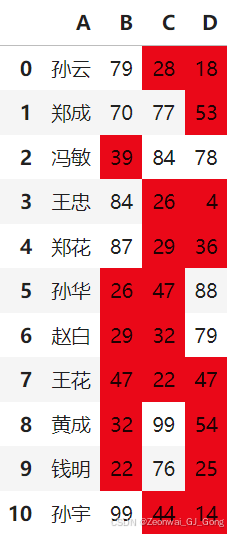
案例二,对每个学生的成绩进行求和并标记出总分小于120的学生
(df.set_index('A').assign(sum = df.set_index('A').sum(axis=1))
.style.map(lambda x: 'background-color: red' if x < 120 else "",
subset=pd.IndexSlice[:, ['sum']]))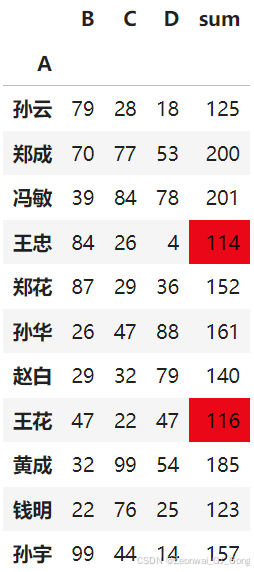
图表可视化
常见的数据统计分析图表包括:
折线图、饼图、柱状图、直方图、箱型图、面积图和散点图,接下来结合matplotlib可视化工具进行介绍。
首先导入包,设置一些全局参数和准备数据
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import random
df = pd.DataFrame({
'A': ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i'],
'B': ['L', 'L', 'M', 'L', 'M', 'M', 'M', 'L', 'L'],
'C': [107, 177, 139, 38, 52, 38, 87, 38, 56],
'D': [22, 59, 38, 59, 59, 82, 89, 48, 88]}).set_index('A')
df
B C D A a L 107 22 b L 177 59 c M 139 38 d L 38 59 e M 52 59 f M 38 82 g M 87 89 h L 38 48 i L 56 88
折线图
df[['C', 'D']].plot.line()<Axes: xlabel='A'>
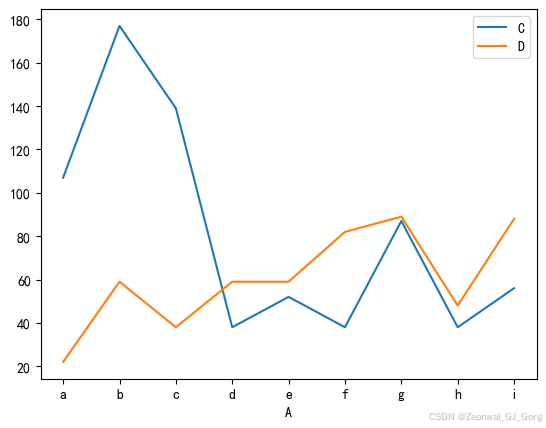
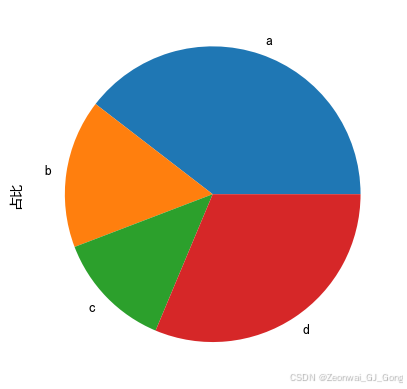
饼图
np.random.seed(123)
df1 = pd.Series(3 * np.random.rand(4),
index=['a', 'b', 'c', 'd'], name='占比')
df1a 2.089408 b 0.858418 c 0.680554 d 1.653944 Name: 占比, dtype: float64
df1.plot.pie()<Axes: ylabel='占比'>
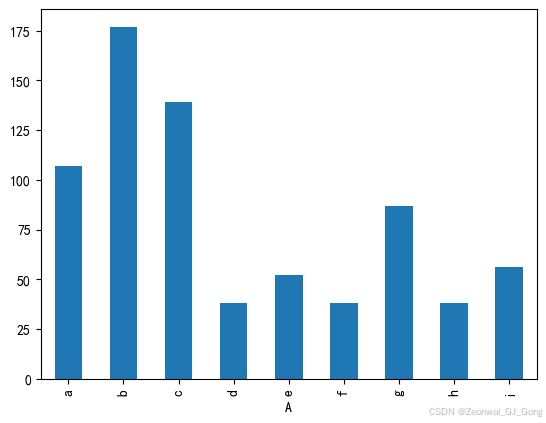
柱状图
柱状图有竖向柱状图和横向柱状图两种
df['C'].plot.bar()<Axes: xlabel='A'>
df.plot.barh()<Axes: ylabel='A'>
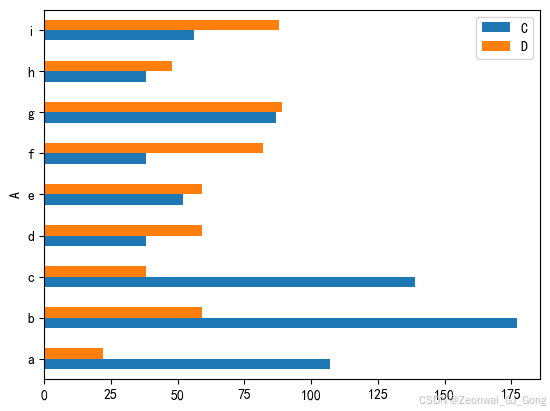
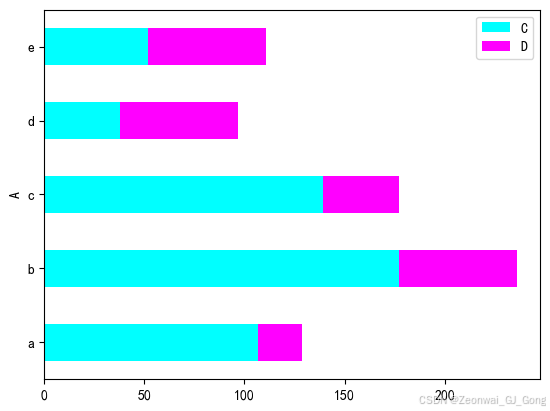
如果传入参数stacked=True,还可以生成堆积柱状图
df.head(5).plot.barh(stacked=True, colormap='cool')<Axes: ylabel='A'>
直方图
np.random.seed(123)
df2 = pd.DataFrame({
'a': np.random.randn(1000) + 1,
'b': np.random.randn(1000),
'c': np.random.randn(1000) - 1})
df2df2['a'].plot.hist()<Axes: ylabel='Frequency'>
同样传入参数stacked可以生成堆积直方图,并且还能指定分箱个数bins
df2.plot.hist(stacked=True, bins=30)<Axes: ylabel='Frequency'>
箱型图
箱型图是稍微专业一点的统计图表,能够展示数据的分布情况
df.boxplot('C')<Axes: >

箱型图的语句稍有不同,但同样也有横向箱型图
df.boxplot(['C', 'D'], vert=False)<Axes: >
面积图
np.random.seed(123)
df4 = pd.DataFrame(np.random.rand(10, 4), columns=['a', 'b', 'c', 'd'])
df4
a b c d 0 0.696469 0.286139 0.226851 0.551315 1 0.719469 0.423106 0.980764 0.684830 2 0.480932 0.392118 0.343178 0.729050 3 0.438572 0.059678 0.398044 0.737995 4 0.182492 0.175452 0.531551 0.531828 5 0.634401 0.849432 0.724455 0.611024 6 0.722443 0.322959 0.361789 0.228263 7 0.293714 0.630976 0.092105 0.433701 8 0.430863 0.493685 0.425830 0.312261 9 0.426351 0.893389 0.944160 0.501837
df4[['a', 'b', 'c', 'd']].plot.area()<Axes: >
散点图
最后是散点图,散点图是描述两特征相关性的可视化工具
np.random.seed(123)
df5 = pd.DataFrame(np.random.randn(10, 2), columns=['B', 'C']).cumsum()
df5
B C 0 -1.085631 0.997345 1 -0.802652 -0.508949 2 -1.381252 1.142487 3 -3.807932 0.713575 4 -2.541995 -0.153166 5 -3.220881 -0.247875 6 -1.729492 -0.886777 7 -2.173474 -1.321128 8 0.032456 0.865658 9 1.036510 1.251844
df5.plot.scatter('C', 'B')<Axes: xlabel='C', ylabel='B'>
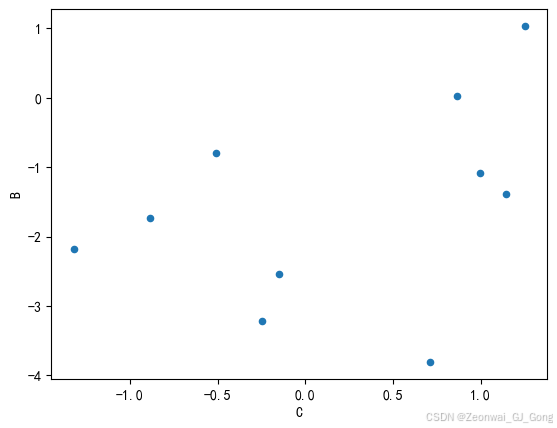
可见两变量并不是很相关。
小结
数据可视化是展现数据分析结果的重要步骤,无论是传统的静态分析报告(使用表格样式)还是现在流行的动态看板(使用图表工具)都需要用到数据可视化工具。其中图表工具的基本逻辑是源自matplotlib工具包,虽然代码中没有显式地调用matplotlib工具包的任何内容,但是如果没有正确配置好该工具包(使用pip安装即可)还是会触发报错无法正常运行的。
致谢
这次文章是这个CDA打卡活动系列的最后一篇更新,课程名称为《山有木兮:Python数据分析极简入门》,感兴趣的朋友可以在CDA网校里面找到。
感谢CDA网校组织这次活动,感谢领队和辅助小伙伴在学习过程中提供的支持和帮助。通过这次学习不仅获得了这个系列的文章更新同时还对我的个人知识库进行了查缺补漏,无论如何都是有意义的。
最后感谢身边的队员们互相扶持,让我能一直坚持到现在。本系列打卡活动的文章更新完毕,感谢读者朋友的关注,在此致以真诚感谢,来日方长我们有机会再见。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 37
37 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)