
比深度学习还强的算法:算法大赛中的冠军算法,结构化数据挖掘中的最优算法,从决策树到随机森林、CBDT、XGBOOST、LightGBM、CATBOOT原理解析
在结构化数据的挖掘领域,以决策树为基石,一个古老而强大的家族——“树族”,仍然以其无与伦比的实力,统治着这片领域。如同司马家族在三国时代一样,树族在传统机器学习的舞台上展现着无可匹敌的威势,左右着传统机器学习算法的命运。
在机器学习的浩瀚宇宙中,深度学习无疑是最耀眼的星辰,尤其在计算机视觉(CV)和自然语言处理(NLP)领域,它的光芒几乎掩盖了其他所有算法。然而,在结构化数据的挖掘领域,以决策树为基石,一个古老而强大的家族——“树族”,仍然以其无与伦比的实力,统治着这片领域。如同司马家族在三国时代一样,树族在传统机器学习的舞台上展现着无可匹敌的威势,左右着传统机器学习算法的命运。
结构化数据挖掘的荣光
随着AIGC的火爆,尤其是ChatGPT和AI绘画的大放异彩,以神经网络为底模的深度学习算法犹如一把锤子在数据处理领域到处砸钉子,不论什么问题都要用深度学习Train上一Train。传统机器学习算法似乎逐渐失去了往日的光辉,各类前沿论文和大神论坛中也鲜见传统机器学习算法的应用进展和理论突破。
但是,在实际工作和算法比赛中,结构化数据【表格型数据】仍占有半壁江山,传统机器学习算法中的决策树家族尤其是XGBOOST、Light GBM和CATBOOST三大算法仍然活跃在各类结构化数据的算法比赛中,并且也都能取得不错的成绩,就像司马家族统一三国一样,决策树家族算法也大有一统传统机器学习领域的趋势。
我在央企工作时,以及参加的一些结构化数据算法大赛中,频繁应用过这三个算法,深入研究了算法原理和论文,下面我就从决策树开始聊一聊决策树家族的成员:决策树、随机森林、GBDT、XGBOOST、Light GBM和CATBOOST。
树族族谱 :从决策树到集成学习
决策树算是这个家族里的族长,其他几个算法都是以决策树为基模型的集成算法,一切树模型本质上都是基于特征空间划分的条件概率分布,都具有方差大的特性,对量纲无要求,因此,使用这些算法的时候基本上都不需要做归一化、标准化,除非你的问题有量纲方面的特殊要求。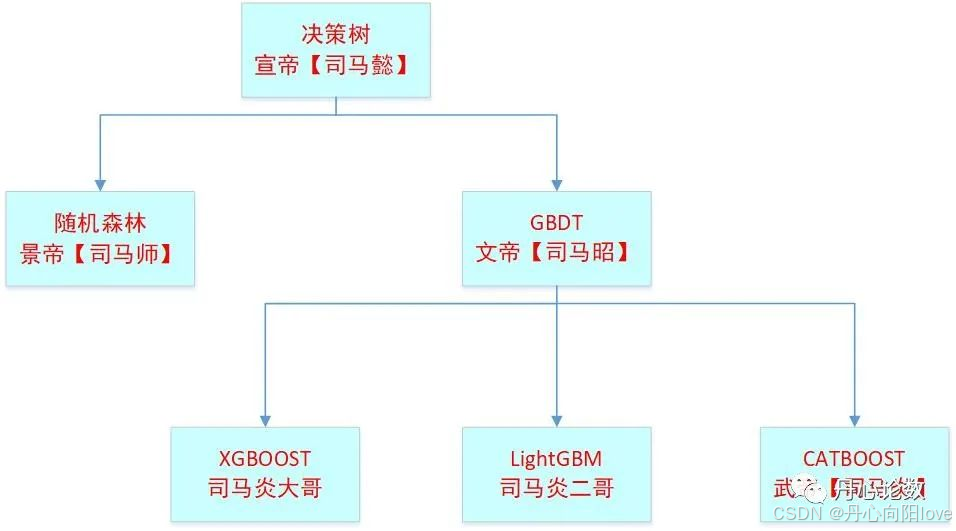
决策树 :家族的基石
原理:将特征空间划分为互不相交的单元。递归划分特征 ,生成多个if-then的规则,每条规则对应一个从根节点到叶子节点的条件概率分布单元,该单元由总的条件概率分布计算得来,表示给定特征条件下的不同类别的概率分布。这是比较学术的介绍,用人类的语言简单总结就是条件判断,这个跟我们平时做决定的逻辑思维是一样的,只不过是将这个过程以数学语言进行了严格的量化,举个栗子:
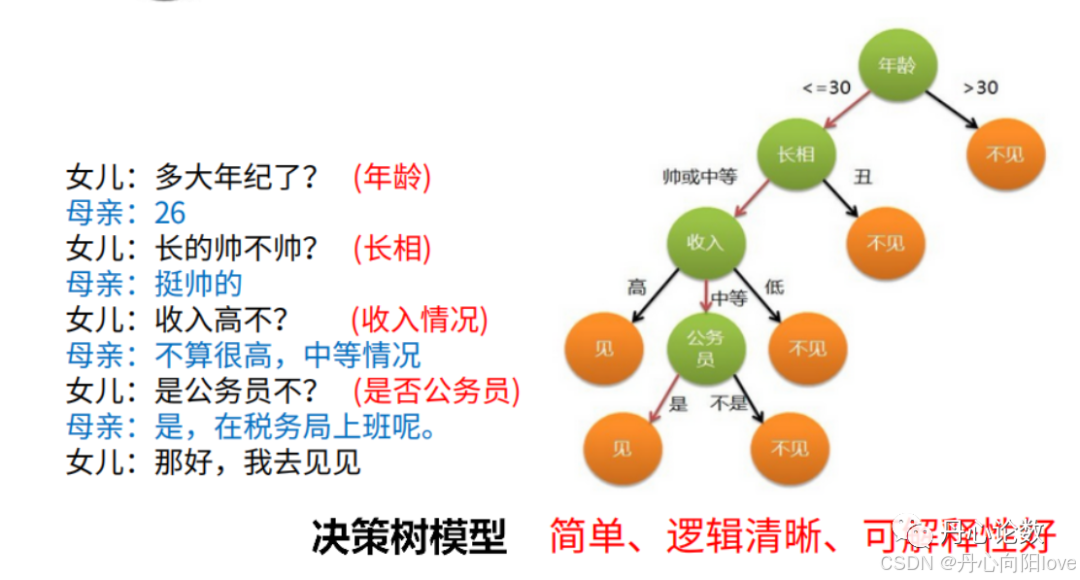
决策树基于“树”结构进行决策的,总体流程是“分而治之”的思想,一是自根至叶的递归过程,一是在每个中间节点寻找一个“划分”属性,相当于就是一个特征属性了。这里就面临两个问题:
“树”怎么长
这颗“树”长到什么时候停
解决了这两个问题也就搞懂了决策树的原理。
这颗“树”长到什么时候停
1.当前结点包含的样本全属于同一类别,无需划分;例如:样本当中都是决定去相亲的,属于同一类别,就是不管特征如何改变都不会影响结果,这种就不需要划分了。
2.当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;例如:所有的样本特征都是一样的,就造成无法划分了,训练集太单一。
3.当前结点包含的样本集合为空,不能划分。
“树”怎么长
在生活当中,我们都会碰到很多需要做出决策的地方,例如:吃饭地点、数码产品购买、旅游地区等,你会发现在这些选择当中都是依赖于大部分人做出的选择,也就是跟随大众的选择。其实在决策树当中也是一样的,当大部分的样本都是同一类的时候,那么就已经做出了决策。
我们将大众的选择数据化,就是引入一个概念信息的纯度,关于纯度的衡量有三种概念:
信息增益、信息增益率和基尼系数,对应的就有三类决策树:ID3算法【利用信息增益选择划分属性】、C4.5【利用信息增益率选择划分属性】、CART算法【使用基尼系数选择划分属性】。
详细的公式推导这里就不展开了,有兴趣的读者可以去阅读一下李航大佬的《统计学习方法论》【电子版可私信我获取】
随机森林:多样性的力量
特点:放回抽样,特征\样本随机采样,无剪枝,投票,可以减小方差,CART弱学习器
RandomForest是一种Bagging的集成方法,Bagging具有如下特点:
1)一种放回抽样
2)投票表决(分类)或平均误差最小(回归)
3)弱学习器之间属于并列生成,不存在强依赖关系。
随机性:
特征选择随机性:每次迭代从M个feature中,随机选择m个(m << M)
样本抽样随机性:采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本
总的来说就是随机选择样本数,随机选取特征,随机选择分类器,建立多颗这样的决策树,然后通过这几棵决策树来投票,决定数据属于哪一类(投票机制有一票否决制、少数服从多数、加权多数)
GBDT:减少偏差的艺术
特点:串行,回归树,容易过拟合,减小偏差,最小化错误样本(损失函数),异常值敏感,CART弱学习器。
传统的GBDT是一种基于Boosting的加性模型,基模型是CART。CART最终结果是多颗CART的结论之和,因此学习过程是依次学习每一颗树。每颗树的学习方向是目标函数在当前已学到模型的梯度方向。整体框架还是基于Gradient Boosting。
GBDT与传统的Boosting区别较大,它的每一次计算都是为了减少上一次的残差,而为了消除残差,在残差减小的梯度方向上建立模型,在GradientBoost中,每个新的模型的建立是为了使得之前的模型的残差往梯度下降的方法,与传统的Boosting中关注正确错误的样本加权有着很大的区别。关键就是利用损失函数的负梯度方向在当前模型的值作为残差的近似值,进而拟合一棵CART回归树。GBDT的会累加所有树的结果,而这种累加是无法通过分类完成的,因此GBDT的树都是CART回归树,而不是分类树(尽管GBDT调整后也可以用于分类但不代表GBDT的树为分类树)
XGBoost :效率与精度的结合
特点:GBDT变种、特征排序分裂并行、支持线性分类器、低方差、低偏差、二阶泰勒展开损失函数、列抽样、增量训练、正则化减弱单树影响、降低了方差。
XGBoost在GBDT的基础上,对目标函数增加了二阶泰勒展开项,同时加入了正则项,是一个更高效、更高精度的树模型实现框架。
虽然Boosting是一种串行的学习框架,但是树模型学习过程的主要计算消耗在特征及分裂阈值的计算上。XGBoost的并行方式则主要是在计算分裂阈值时,分多个线程,每个线程分配一部分的特征进行计算,然后再将所有线程的计算结果取分裂增益最大的特征及阈值进行树的生长。
LightGBM:速度与精度的新高度
特点:优化XGBOOST
由微软于2017年开源。借鉴了许多XGBoost的实现方法,如目标函数的二阶泰勒展开、树叶子节点值的计算、树复杂度表达等。但是在此基础上,LightGBM采用了直方图加速方法以及Leafwise的树生长方式,因此在训练速度方面表现比XGBoost更加卓越,同时训练精度也能保持相当水平
CatBoost:类别特征的救星
特点:自动处理分类特征、GPU加速、算法性能提升
性能:CatBoost提供最先进的结果,在性能方面与任何领先的机器学习算法相比都具有竞争力。
自动处理分类特征:CatBoost无需对数据特征进行任何显式的预处理就可以将类别转换为数字。CatBoost使用关于分类特征组合以及分类和数字特征组合的各种统计信息将分类值转换为数字。
鲁棒性:它减少了对广泛的超参数优化的需要,并降低了过拟合的机会,这也会导致更一般化的模型。CatBoost的参数包括树的数量、学习率、正则化、树的深度、折叠尺寸、装袋温度等。
易于使用:可以从命令行使用CatBoost为Python和R用户提供方便的API。
总结
决策树家族的算法在结构化数据挖掘领域展现出了强大的统治力。它们不仅在算法大赛中屡获佳绩,而且在实际应用中也表现出了卓越的性能。当深度学习在某些问题上难以取得突破时,回归到这些经典的算法,往往能够带来意想不到的

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)