一维时序数据_教育数据挖掘:Knowledge Tracing Machines
Knowledge Tracing Machines: Factorization Machines for Knowledge Tracing一、概述这是发表在AAAI2019上的一篇文章。区别与基于概率图模型的知识追踪算法(BKT)和基于序列模型的知识追踪算法(DKT,DKVMN),本文提出了新的一种基于因子分解机(FM)的方法。在多个数据集中验证发现该模型能够处理基于序列的数据,也能很好的处
Knowledge Tracing Machines: Factorization Machines for Knowledge Tracing
一、概述
这是发表在AAAI2019上的一篇文章。区别与基于概率图模型的知识追踪算法(BKT)和基于序列模型的知识追踪算法(DKT,DKVMN),本文提出了新的一种基于因子分解机(FM)的方法。在多个数据集中验证发现该模型能够处理基于序列的数据,也能很好的处理稀疏数据,同时还可以很方便的引入多种side information 如多种知识概念组成成分,题目尝试次数,知识概念掌握水平。
二、模型架构
KTM模型主要思想就是通过FM做特征交互。其中N为特征总数,特征包含着练习,知识概念,学习的因素(成功失败信息),还有一些其他因素。KTM基于事件中涉及的所有特征的稀疏集,对学生做题(正确或错误)的二进制结果的概率进行建模。通过以下公式运算预测:
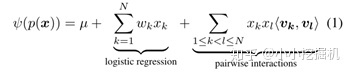
ψ代表着全连接函数(例如tanh),µ是全局偏差,每个特征通过一维特征与二维特征交叉发挥影响。
只有特征大于0的时候才能对预测产生影响(废话),如下图所示:

三、辅助信息的数据和编码
下面介绍如何编码各种side information:
Users:用户的独热向量。
Items:题目的独热向量。
Skills:题目涉及到的知识概念,涉及到为1,未涉及到为0。
Attempts: 人们可以分配额外的特征作为一个学生在测试中学习一项技能的机会的计数器。
Wins & Fails:成功与失败次数的计数器,特征维数为知识点数量,分别记录每个知识点被用户做对,做错多少次。他没有选择只使用一个计数器来计算正确的次数减去错误的次数,而是将正确次数错误次数分别计数,事实上根据学出来的结果,无论是否作对知识水平都是上升的。除此之外,值得一提的是,Wins&Fails counter仅仅与与当前是记录当前用户做的本题相关的知识点,其余知识点的Wins&Fails counter全部置零。
Extra side information:将更多的side information可以加入到现有的稀疏特征,例如学生的学校ID和教师ID,或者其他信息,例如测试类型: low stake (practice) 与high stake (posttest)等。
四、可视化
KTM的另一个优点是我们可以可视化它们学习的特征隐向量。在图中,我们展示了Fraction subtraction数据集上KTM所学习的学生,题目和知识概念的二维特征隐向量。在下图中观察到几种现象,说明模型与可视化结果是具有可解释性的。
1. 计算学生WALL-E隐向量与知识点2,7隐向量的点积,为负数,在数据集中WALL-E也确实对2,7的掌握不好
2. 问题5与知识概念2,7正点积高,问题5确实用到了知识点2,7。
3. 问题5与用户的负点积也高,用户没有做出来这个题。

五、实验
选用了两个有时序关系的数据集(Assistments和Berkeley)和四个没有时序关系的数据集(Castor,ECPE,TIMSS,Fraction),结果如下:
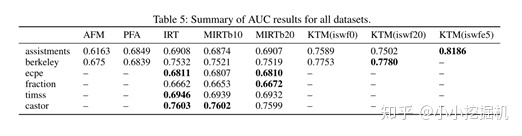
说明在时序数据集与非时序数据集中都有一个较好的效果。
这篇工作最大的意义就是把在推荐系统中应用很广泛的FM用到KT上,虽然是忽略了时序信息,但是能够方便的对各种side information进行集成,交叉。对一个题目相关的知识点进行正误分别记数这个想法很少见,也确实很有效。至于对时序关系的忽略,我记得陈恩红组的NeuralCDM模型中提到,其实学生的做题序列都很短,平均在5左右(assistant数据集),方差也小,时序关系所带来的提升有限。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)