江科大数据挖掘实验二
江科大数据挖掘实验二
6.7 使用一种你熟悉的程序设计语言,如C++或JAVA,实现本章介绍的三种频繁项集挖掘算法:(1)Apriori[AS94b];(2)FP-growth[HPY00](使用垂直数据格式挖掘)和。在各种不同的数据集上比较每种算法性能。写一个报告,分析在哪些情况下(如数据大小、数据分布、最小支持度阈值设置和模式的稠密性),一种算法比其他算法好,并陈述理由。
(1) Apriori[AS94b]
简介:
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。
基本思想:
首先扫描数据库中所需要进行分析的数据,在设置完支持度以及置信度以后,在最小支持度的支持下产生频繁项,即统计所有项目集中包含一个或一个以上的元素频数,找出大于或者等于设置的支持度的项目集。其次就是频繁项的自连接。再者是如果对频繁项自连接以后的项的子集如果不是频繁项的话,则进行剪枝处理。接着对频繁项处理后产生候选项。最后循环
调用产生频繁项集。
支持度:
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。
置信度:
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
实现:
import java.util.ArrayList;
import java.util.*;
public class Apriori {
private final static int SUPPORT = 2; // 支持度阈值
private final static double CONFIDENCE = 0.5; // 置信度阈值
private final static String ITEM_SPLIT="、"; // 项之间的分隔符
private final static String CON=" → "; // 项之间的分隔符
private List<String> transList ; //所有交易
public Apriori(List<String> transList) {
this.transList = transList;
}
/**
*
* @return 交易的所有频繁项集
*/
public Map<List<String>,Integer> getFC(){
Map<List<String>,Integer> frequentCollectionMap = new HashMap<>();//所有的频繁集
frequentCollectionMap.putAll(getItem1FC());//合并频繁1项集
Map<List<String>,Integer> itemkFcMap = getItem1FC(),candidateCollection;
while (itemkFcMap!=null && itemkFcMap.size()!=0){
candidateCollection = getCandidateCollection(itemkFcMap);//获得候选集
//对候选集项进行累加计数
for (List<String> candidate : candidateCollection.keySet()){
for (String trans : transList){
boolean flag = true;// 用来判断交易中是否出现该候选项,如果出现,计数加1
for (String candidateItem : candidate){
if (trans.indexOf(candidateItem)==-1){
flag = false;
break;
}
}
if (flag){
candidateCollection.put(candidate,candidateCollection.get(candidate)+1);
}
}
}
itemkFcMap.clear();
//从候选集中找到符合支持度的频繁集项
for (List<String> candidate : candidateCollection.keySet()){
Integer fc = candidateCollection.get(candidate);
if (fc>=SUPPORT){
itemkFcMap.put(candidate,fc);
}
}
//合并所有频繁集
frequentCollectionMap.putAll(itemkFcMap);
}
return frequentCollectionMap;
}
/**
* 关联规则
* @param frequentCollectionMap 频繁集
* @return 关联规则
*/
public Map<String,Double> getRelationRules(Map<List<String>,Integer> frequentCollectionMap){
Map<String,Double> relationRules=new HashMap<>();
for (List<String> itmes : frequentCollectionMap.keySet()){
if (itmes.size()>1){
double countAll = frequentCollectionMap.get(itmes);
List<List<String>> result = getSubsets(itmes);//获得itmes的所有非空子集
for (List<String> itemList : result){
if (itemList.size() < itmes.size()){//只处理真子集
StringBuilder reasonStr = new StringBuilder();//前置
StringBuilder resultStr = new StringBuilder();//结果
for (String item : itemList) reasonStr.append(ITEM_SPLIT).append(item);
for (String item : itmes) if (!itemList.contains(item)) resultStr.append(ITEM_SPLIT).append(item);
double countReason = frequentCollectionMap.get(itemList);
double itemConfidence = countAll / countReason;//计算置信度
if (itemConfidence >= CONFIDENCE){
String rule = reasonStr.append(CON).append(resultStr.substring(1)).substring(1);
relationRules.put(rule,itemConfidence);
}
}
}
}
}
return relationRules;
}
/**
*对于给定的频繁K项集,获得他的K+1项候选集
* @param itemkFcMap 频繁K项集
* @return K+1项候选集
*/
private Map<List<String>,Integer> getCandidateCollection(Map<List<String>,Integer> itemkFcMap){
Map<List<String>,Integer> candidateCollection = new HashMap<>();
Set<List<String>> itemkSet1 = itemkFcMap.keySet();
Set<List<String>> itemkSet2 = itemkFcMap.keySet();
//连接
for (List<String> itemk1 : itemkSet1){
for (List<String> itemk2 : itemkSet2){
if (!itemk1.equals(itemk2)){
for (String item : itemk2){
if (itemk1.contains(item)) continue;
List<String> temp = new ArrayList<>(itemk1);
temp.add(item);
temp.sort(Comparator.naturalOrder());
candidateCollection.put(temp,0);
}
}
}
}
return candidateCollection;
}
/**
* 获取频繁1项集
* @return map<key,value> key-items value-frequency
*/
private Map<List<String>,Integer> getItem1FC(){
Map<List<String>,Integer> sItem1FCMap = new HashMap<>();//statistics frequency of each item
Map<List<String>,Integer> rItem1FCMap = new HashMap<>();//频繁1项集
for (String trans : transList){
String[] items = trans.split(ITEM_SPLIT);
for (String item : items){
List<String> itemList = new ArrayList<>();
itemList.add(item);
sItem1FCMap.put(itemList,sItem1FCMap.getOrDefault(itemList,0)+1);
}
}
for (List itemList : sItem1FCMap.keySet()){
Integer fc = sItem1FCMap.get(itemList);
if (fc>=SUPPORT) rItem1FCMap.put(itemList,fc);
}
return rItem1FCMap;
}
/**
* 构造子集
* @param sourceSet
* @return sourceSet的所有非空子集
*/
private List<List<String>> getSubsets(List<String> sourceSet){
List<List<String>> result = new ArrayList<>();
result.add(new ArrayList<>());
for(int i = 0;i<sourceSet.size();i++){
int size = result.size();
for (int j = 0;j<size;j++){
List<String> temp = new ArrayList<>(result.get(j));
temp.add(sourceSet.get(i));
result.add(temp);
}
}
return result.subList(1,result.size());//去掉空集
}
}
测试:
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class TestApriori {
public static void main(String[] args) {
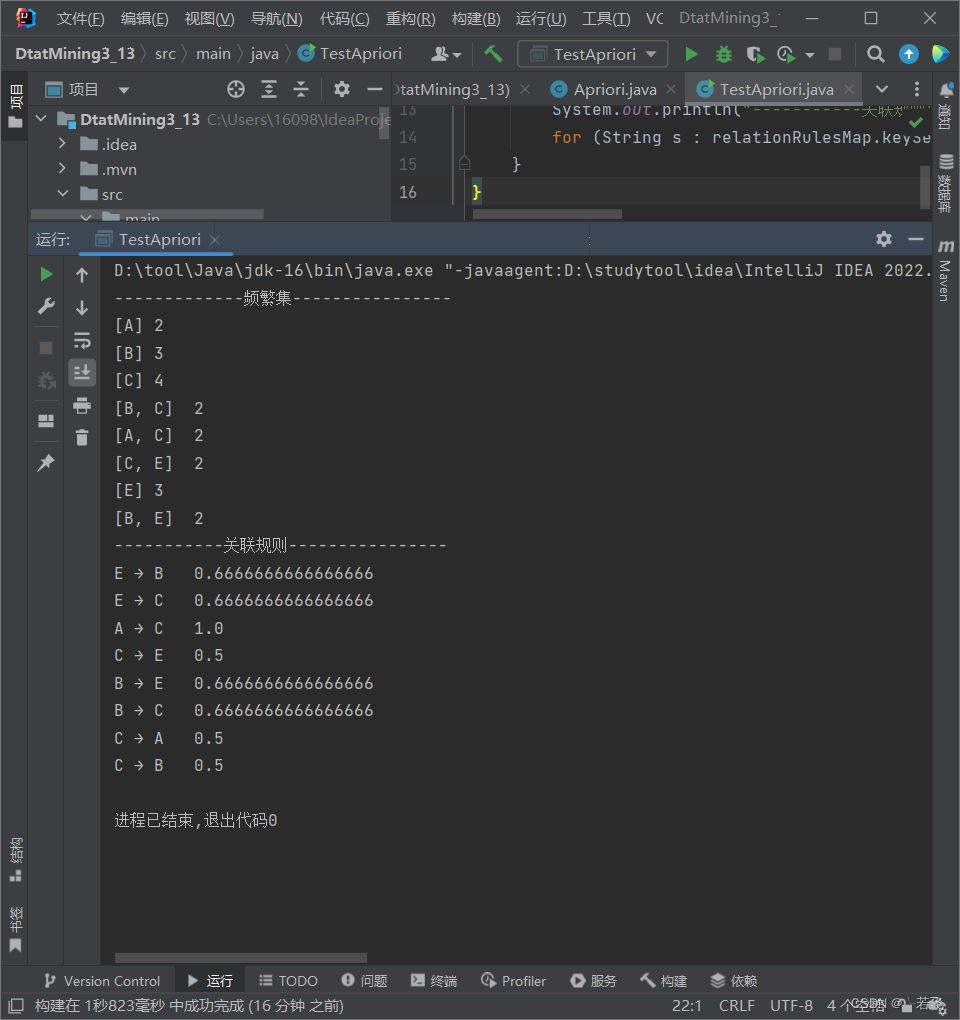
Apriori apriori = new Apriori(Arrays.asList("A、C","B、C、E","A、C、E","B、E","B、C"));
Map<List<String>,Integer> frequentCollectionMap = apriori.getFC();
System.out.println("-------------频繁集"+"----------------");
for(List<String> list : frequentCollectionMap.keySet()) System.out.println(list+ "\t"+ frequentCollectionMap.get(list));
Map<String,Double> relationRulesMap = apriori.getRelationRules(frequentCollectionMap);
System.out.println("-----------关联规则"+"----------------");
for (String s : relationRulesMap.keySet()) System.out.println(s+"\t"+relationRulesMap.get(s));
}
}
数据集:
![]()
结果:
(2) FP-growth[HPY00]
Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下。FPGrowth不同于Apriori的“试探”策略,算法只需扫描原始数据两遍,通过FP-tree数据结构对原始数据进行压缩,效率较高。
FP代表频繁模式(Frequent Pattern) ,算法主要分为两个步骤:FP-tree构建、挖掘频繁项集。
FP树通过逐个读入事务,并把事务映射到FP树中的一条路径来构造。由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠。路径相互重叠越多,使用FP树结构获得的压缩效果越好;如果FP树足够小,能够存放在内存中,就可以直接从这个内存中的结构提取频繁项集,而不必重复地扫描存放在硬盘上的数据。
通常,FP树的大小比未压缩的数据小,因为数据的事务常常共享一些共同项,在最好的情况下,所有的事务都具有相同的项集,FP树只包含一条节点路径;当每个事务都具有唯一项集时,导致最坏情况发生,由于事务不包含任何共同项,FP树的大小实际上与原数据的大小一样。
FP树的根节点用φ表示,其余节点包括一个数据项和该数据项在本路径上的支持度;每条路径都是一条训练数据中满足最小支持度的数据项集;FP树还将所有相同项连接成链表,上图中用蓝色连线表示。
为了快速访问树中的相同项,还需要维护一个连接具有相同项的节点的指针列表(headTable),每个列表元素包括:数据项、该项的全局最小支持度、指向FP树中该项链表的表头的指针。
实现:
package baiyyang;
import java.util.ArrayList;
import java.util.List;
public class TreeNode implements Comparable<TreeNode> {
private String name; // 节点名称
private int count; // 计数
private TreeNode parent; // 父节点
private List<TreeNode> children; // 子节点
private TreeNode nextHomonym; // 下一个同名节点
public TreeNode() {
}
public TreeNode(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
public TreeNode getParent() {
return parent;
}
public void setParent(TreeNode parent) {
this.parent = parent;
}
public List<TreeNode> getChildren() {
return children;
}
public void addChild(TreeNode child) {
if (this.getChildren() == null) {
List<TreeNode> list = new ArrayList<TreeNode>();
list.add(child);
this.setChildren(list);
} else {
this.getChildren().add(child);
}
}
public TreeNode findChild(String name) {
List<TreeNode> children = this.getChildren();
if (children != null) {
for (TreeNode child : children) {
if (child.getName().equals(name)) {
return child;
}
}
}
return null;
}
public void setChildren(List<TreeNode> children) {
this.children = children;
}
public void printChildrenName() {
List<TreeNode> children = this.getChildren();
if (children != null) {
for (TreeNode child : children) {
System.out.print(child.getName() + " ");
}
} else {
System.out.print("null");
}
}
public TreeNode getNextHomonym() {
return nextHomonym;
}
public void setNextHomonym(TreeNode nextHomonym) {
this.nextHomonym = nextHomonym;
}
public void countIncrement(int n) {
this.count += n;
}
@Override
public int compareTo(TreeNode arg0) {
// TODO Auto-generated method stub
int count0 = arg0.getCount();
// 跟默认的比较大小相反,导致调用Arrays.sort()时是按降序排列
return count0 - this.count;
}
}
package baiyyang;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class FPTree {
private int minSuport;
public int getMinSuport() {
return minSuport;
}
public void setMinSuport(int minSuport) {
this.minSuport = minSuport;
}
// 从若干个文件中读入Transaction Record
public List<List<String>> readTransRocords(String... filenames) {
List<List<String>> transaction = null;
if (filenames.length > 0) {
transaction = new LinkedList<List<String>>();
for (String filename : filenames) {
try {
FileReader fr = new FileReader(filename);
BufferedReader br = new BufferedReader(fr);
try {
String line;
List<String> record;
while ((line = br.readLine()) != null) {
if(line.trim().length()>0){
String str[] = line.split(",");
record = new LinkedList<String>();
for (String w : str)
record.add(w);
transaction.add(record);
}
}
} finally {
br.close();
}
} catch (IOException ex) {
System.out.println("Read transaction records failed."
+ ex.getMessage());
System.exit(1);
}
}
}
return transaction;
}
// FP-Growth算法
public void FPGrowth(List<List<String>> transRecords,
List<String> postPattern) {
// 构建项头表,同时也是频繁1项集
ArrayList<TreeNode> HeaderTable = buildHeaderTable(transRecords);
// 构建FP-Tree
TreeNode treeRoot = buildFPTree(transRecords, HeaderTable);
// 如果FP-Tree为空则返回
if (treeRoot.getChildren()==null || treeRoot.getChildren().size() == 0)
return;
//输出项头表的每一项+postPattern
if(postPattern!=null){
for (TreeNode header : HeaderTable) {
System.out.print(header.getCount() + "\t" + header.getName());
for (String ele : postPattern)
System.out.print("\t" + ele);
System.out.println();
}
}
// 找到项头表的每一项的条件模式基,进入递归迭代
for (TreeNode header : HeaderTable) {
// 后缀模式增加一项
List<String> newPostPattern = new LinkedList<String>();
newPostPattern.add(header.getName());
if (postPattern != null)
newPostPattern.addAll(postPattern);
// 寻找header的条件模式基CPB,放入newTransRecords中
List<List<String>> newTransRecords = new LinkedList<List<String>>();
TreeNode backnode = header.getNextHomonym();
while (backnode != null) {
int counter = backnode.getCount();
List<String> prenodes = new ArrayList<String>();
TreeNode parent = backnode;
// 遍历backnode的祖先节点,放到prenodes中
while ((parent = parent.getParent()).getName() != null) {
prenodes.add(parent.getName());
}
while (counter-- > 0) {
newTransRecords.add(prenodes);
}
backnode = backnode.getNextHomonym();
}
// 递归迭代
FPGrowth(newTransRecords, newPostPattern);
}
}
// 构建项头表,同时也是频繁1项集
public ArrayList<TreeNode> buildHeaderTable(List<List<String>> transRecords) {
ArrayList<TreeNode> F1 = null;
if (transRecords.size() > 0) {
F1 = new ArrayList<TreeNode>();
Map<String, TreeNode> map = new HashMap<String, TreeNode>();
// 计算事务数据库中各项的支持度
for (List<String> record : transRecords) {
for (String item : record) {
if (!map.keySet().contains(item)) {
TreeNode node = new TreeNode(item);
node.setCount(1);
map.put(item, node);
} else {
map.get(item).countIncrement(1);
}
}
}
// 把支持度大于(或等于)minSup的项加入到F1中
Set<String> names = map.keySet();
for (String name : names) {
TreeNode tnode = map.get(name);
if (tnode.getCount() >= minSuport) {
F1.add(tnode);
}
}
Collections.sort(F1);
return F1;
} else {
return null;
}
}
// 构建FP-Tree
public TreeNode buildFPTree(List<List<String>> transRecords,
ArrayList<TreeNode> F1) {
TreeNode root = new TreeNode(); // 创建树的根节点
for (List<String> transRecord : transRecords) {
LinkedList<String> record = sortByF1(transRecord, F1);
TreeNode subTreeRoot = root;
TreeNode tmpRoot = null;
if (root.getChildren() != null) {
while (!record.isEmpty()
&& (tmpRoot = subTreeRoot.findChild(record.peek())) != null) {
tmpRoot.countIncrement(1);
subTreeRoot = tmpRoot;
record.poll();
}
}
addNodes(subTreeRoot, record, F1);
}
return root;
}
// 把交易记录按项的频繁程序降序排列
public LinkedList<String> sortByF1(List<String> transRecord,
ArrayList<TreeNode> F1) {
Map<String, Integer> map = new HashMap<String, Integer>();
for (String item : transRecord) {
// 由于F1已经是按降序排列的,
for (int i = 0; i < F1.size(); i++) {
TreeNode tnode = F1.get(i);
if (tnode.getName().equals(item)) {
map.put(item, i);
}
}
}
ArrayList<Entry<String, Integer>> al = new ArrayList<Entry<String, Integer>>(
map.entrySet());
Collections.sort(al, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> arg0,
Entry<String, Integer> arg1) {
// 降序排列
return arg0.getValue() - arg1.getValue();
}
});
LinkedList<String> rest = new LinkedList<String>();
for (Entry<String, Integer> entry : al) {
rest.add(entry.getKey());
}
return rest;
}
// 把record作为ancestor的后代插入树中
public void addNodes(TreeNode ancestor, LinkedList<String> record,
ArrayList<TreeNode> F1) {
if (record.size() > 0) {
while (record.size() > 0) {
String item = record.poll();
TreeNode leafnode = new TreeNode(item);
leafnode.setCount(1);
leafnode.setParent(ancestor);
ancestor.addChild(leafnode);
for (TreeNode f1 : F1) {
if (f1.getName().equals(item)) {
while (f1.getNextHomonym() != null) {
f1 = f1.getNextHomonym();
}
f1.setNextHomonym(leafnode);
break;
}
}
addNodes(leafnode, record, F1);
}
}
}
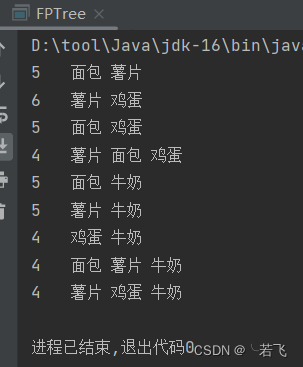
public static void main(String[] args) {
FPTree fptree = new FPTree();
fptree.setMinSuport(4);
List<List<String>> transRecords = fptree
.readTransRocords("foods.txt");
fptree.FPGrowth(transRecords, null);
}
}
foot.txt

结果(支持度为4):
小结:
Apriori算法是第一个关联规则挖掘算法,也是最经典的算法。它利用逐层搜索的迭代方法找出数据库中项集的关系,以形成规则,其过程由连接(类矩阵运算)与剪枝(去掉那些没必要的中间结果)组成。该算法中项集的概念即为项的集合。包含K个项的集合为k项集。项集出现的频率是包含项集的事务数,称为项集的频率。如果某项集满足最小支持度,则称它为频繁项集。
基本思想:
首先扫描数据库中所需要进行分析的数据,在设置完支持度以及置信度以后,在最小支持度的支持下产生频繁项,即统计所有项目集中包含一个或一个以上的元素频数,找出大于或者等于设置的支持度的项目集。其次就是频繁项的自连接。再者是如果对频繁项自连接以后的项的子集如果不是频繁项的话,则进行剪枝处理。接着对频繁项处理后产生候选项。最后循环
调用产生频繁项集。
支持度:
支持度就是几个关联的数据在数据集中出现的次数占总数据集的比重。或者说几个数据关联出现的概率。
置信度:
置信度体现了一个数据出现后,另一个数据出现的概率,或者说数据的条件概率。
然而Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下。FPGrowth不同于Apriori的“试探”策略,算法只需扫描原始数据两遍,通过FP-tree数据结构对原始数据进行压缩,效率较高。
FP代表频繁模式(Frequent Pattern) ,算法主要分为两个步骤:FP-tree构建、挖掘频繁项集。
FP树通过逐个读入事务,并把事务映射到FP树中的一条路径来构造。由于不同的事务可能会有若干个相同的项,因此它们的路径可能部分重叠。路径相互重叠越多,使用FP树结构获得的压缩效果越好;如果FP树足够小,能够存放在内存中,就可以直接从这个内存中的结构提取频繁项集,而不必重复地扫描存放在硬盘上的数据。
通常,FP树的大小比未压缩的数据小,因为数据的事务常常共享一些共同项,在最好的情况下,所有的事务都具有相同的项集,FP树只包含一条节点路径;当每个事务都具有唯一项集时,导致最坏情况发生,由于事务不包含任何共同项,FP树的大小实际上与原数据的大小一样。
FP树的根节点用φ表示,其余节点包括一个数据项和该数据项在本路径上的支持度;每条路径都是一条训练数据中满足最小支持度的数据项集;FP树还将所有相同项连接成链表,上图中用蓝色连线表示。
为了快速访问树中的相同项,还需要维护一个连接具有相同项的节点的指针列表(headTable),每个列表元素包括:数据项、该项的全局最小支持度、指向FP树中该项链表的表头的指针。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)