QBUS6810统计机器学习和数据挖掘
文章目录损失函数评估方法偏差方差分解no free lunch theorem损失函数针对训练集来说:回归squared error loss:L(y,f(x))=(y−f(x))2L(y, f(\boldsymbol{x}))=(y-f(\boldsymbol{x}))^{2}L(y,f(x))=(y−f(x))2分类 0-1 loss:L(y,f(x))={1 if y≠f
损失函数
针对训练集来说:
回归 squared error loss:
L ( y , f ( x ) ) = ( y − f ( x ) ) 2 L(y, f(\boldsymbol{x}))=(y-f(\boldsymbol{x}))^{2} L(y,f(x))=(y−f(x))2
分类 0-1 loss:
L ( y , f ( x ) ) = { 1 if y ≠ f ( x ) 0 if y = f ( x ) . L(y, f(\boldsymbol{x}))=\left\{\begin{array}{l}1 \text { if } y \neq f(\boldsymbol{x}) \\ 0 \text { if } y=f(\boldsymbol{x}) .\end{array}\right. L(y,f(x))={1 if y=f(x)0 if y=f(x).
评估方法
针对测试集
回归:
mean square error:
M S E = 1 m ∑ i = 1 m ( y i − f ^ ( x i ) ) 2 \mathrm{MSE}=\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-\widehat{f}\left(\boldsymbol{x}_{i}\right)\right)^{2} MSE=m1∑i=1m(yi−f
(xi))2
此外,均方根误差和预测R2由均方误差推导而来,是报告结果的常用方法:
RMSE = 1 m ∑ i = 1 m ( y i − y ^ i ) 2 Prediction R 2 = 1 − ∑ i = 1 m ( y i − y ^ i ) 2 ∑ i = 1 m ( y i − y ˉ ) 2 \begin{array}{c} \text { RMSE }=\sqrt{\frac{1}{m} \sum_{i=1}^{m}\left(y_{i}-\widehat{y}_{i}\right)^{2}} \\ \text { Prediction } \mathrm{R}^{2}=1-\frac{\sum_{i=1}^{m}\left(y_{i}-\widehat{y}_{i}\right)^{2}}{\sum_{i=1}^{m}\left(y_{i}-\bar{y}\right)^{2}} \end{array} RMSE =m1∑i=1m(yi−y
i)2 Prediction R2=1−∑i=1m(yi−yˉ)2∑i=1m(yi−y
i)2
偏差方差分解
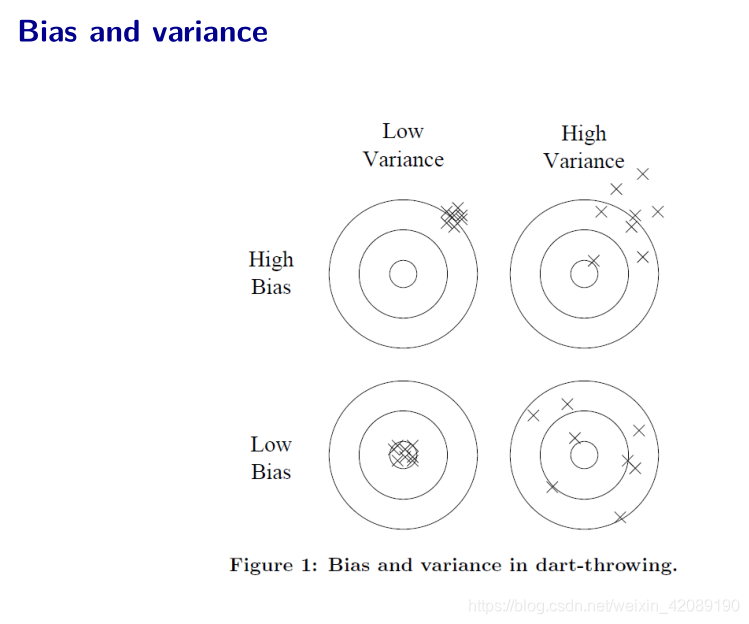
模型越复杂,对训练集数据拟合越好,偏差越小,越flexible,也就是对噪声敏感,方差越大。换个数据集就不太行了。
no free lunch theorem
没有一种问题可以适合所有方法。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)