一次数据挖掘的简单检测
测试Sigmod、 relu 和tanh函数的表达式及取值范围什么是精确率、准确率、召回率、f1值为什么要将数据归一化/标准化?为什么Dropout可以解决过拟合?特征选择的方法Sigmod、 relu 和tanh函数的表达式及取值范围引入激活函数是为了增加神经网络模型的非线性。如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感
Sigmod、 relu 和tanh函数的表达式及取值范围
引入激活函数是为了增加神经网络模型的非线性。
如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,这种情况就是最原始的感知机(Perceptron)。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
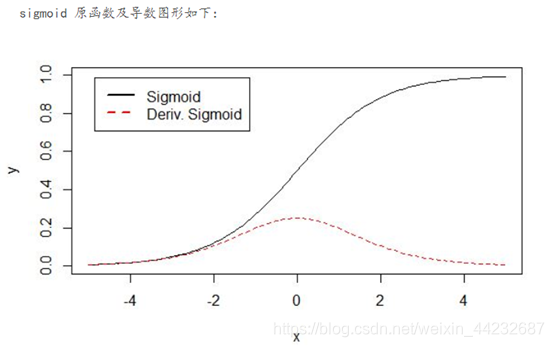
Sigmod激活函数: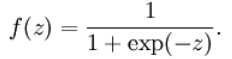
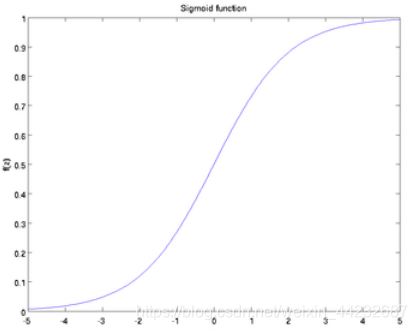
也叫 Logistic 函数,用于隐层神经元输出,取值范围为(0,1)。
导数: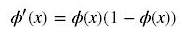
Tanh函数: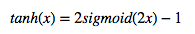
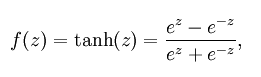
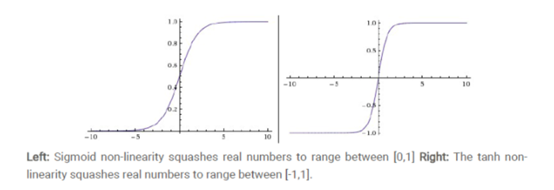
也称为双切正切函数,取值范围为[-1,1]。
tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好,然而,tanh一样具有软饱和性,从而造成梯度消失。
ReLU函数: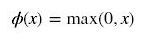
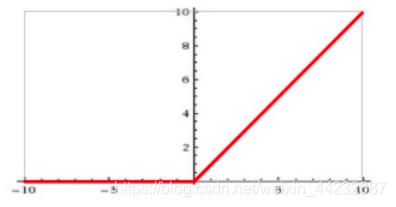
输入信号 <0 时,输出都是0,>0 的情况下,输出等于输入。
随着训练的推进,部分输入会落入硬饱和区,导致对应权重无法更新。这种现象被称为“神经元死亡”。与sigmoid类似,ReLU的输出均值也大于0,偏移现象 和 神经元死亡会共同影响网络的收敛性。
什么是精确率、准确率、召回率、f1值
首先先理解一下混淆矩阵,混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。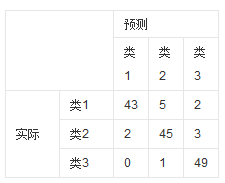
准确率:分类器正确分类的样本数与总样本数之比。即预测 == 实际的,即斜对角线上的值总和 / 总样本。
精确率:预测结果为类n中,其中实际为类n所占的比例。
召回率:所有”正确被检索的item(TP)”占所有”应该检索到的item(TP+FN)”的比例。
F1值 :精确值和召回率的调和均值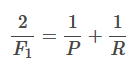
P为精确率,R为召回率。
为什么要将数据归一化/标准化?
① 将数据变为一个特定范围内的的数值,如映射到[0,1],方便数据处理和使用;
② 将有量纲表达式,变为无量纲表达式,成为一个纯量;
③ 可以提升模型的迭代速度;
④ 可以提升模型的精度,比如在计算欧式距离时,x维度的取值范围远远大于y维度时,容易造成精度的损失。
因此,为了提高结果的准确性和可靠性,需要对原始指标数据进行归一化/标准化处理。
为什么Dropout可以解决过拟合?
简单来说:即随机丢弃一些隐藏神经元,然后就会加强未丢弃神经元的训练。(类似随机森林,用一部分的特征来建立一个决策树,又用另一部分特征来建立另一个决策树)
(1)取平均的作用:在运用Dropout我们用相同的训练数据去训练5个不同的神经网络,一般会得到5个不同的结果,此时我们可以才用‘5个结果取均值’ 或者’多数取胜的投票策略’去决定最终结果。
(2)减少神经元之间复杂的共适应关系:因为Dropout程序导致两个神经元不一定每次都在一个Dropout网络中出现。这样权值的更新不再依赖于有固定关系的隐含节点的共同作用,阻止了某些特征仅仅再其他特定特征下才有效果的情况。
(3)Dropout类似于性别再生物进化中的角色:物种为了生存往往会倾向于适应这种环境,环境突变则会导致物种难以做出及时反应,性别的出现可以繁衍出适应新环境的变种,有效的组织过拟合,即避免环境改变时物种可能面临的灭绝。
正则化
基本思想:在训练过程中要抑制参数增长规模,不能让参数的变化范围无限增大。即loss也会惩罚权重的规模,使在训练中权重和参数不会无限制的增大。
L1正则: loss = s* abs(w1+w2+…+wn) + mes %loss= 权值(人为设置)权重和的绝对值+真正的loss
L2正则: loss= s(w1w1 +W2W2+…))+mes %权重的平方
特征选择的方法
去掉取值变化小的特征
单变量特征选择
线性模型和正则化
随机森林
顶层特征选择算法(稳定性选择、递归特征消除)
这里是详解

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)