由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式。如S3、HDFS、Cassandra、HBase,有了这些数据的组织形式,数据的来源和存储都可以多样化~
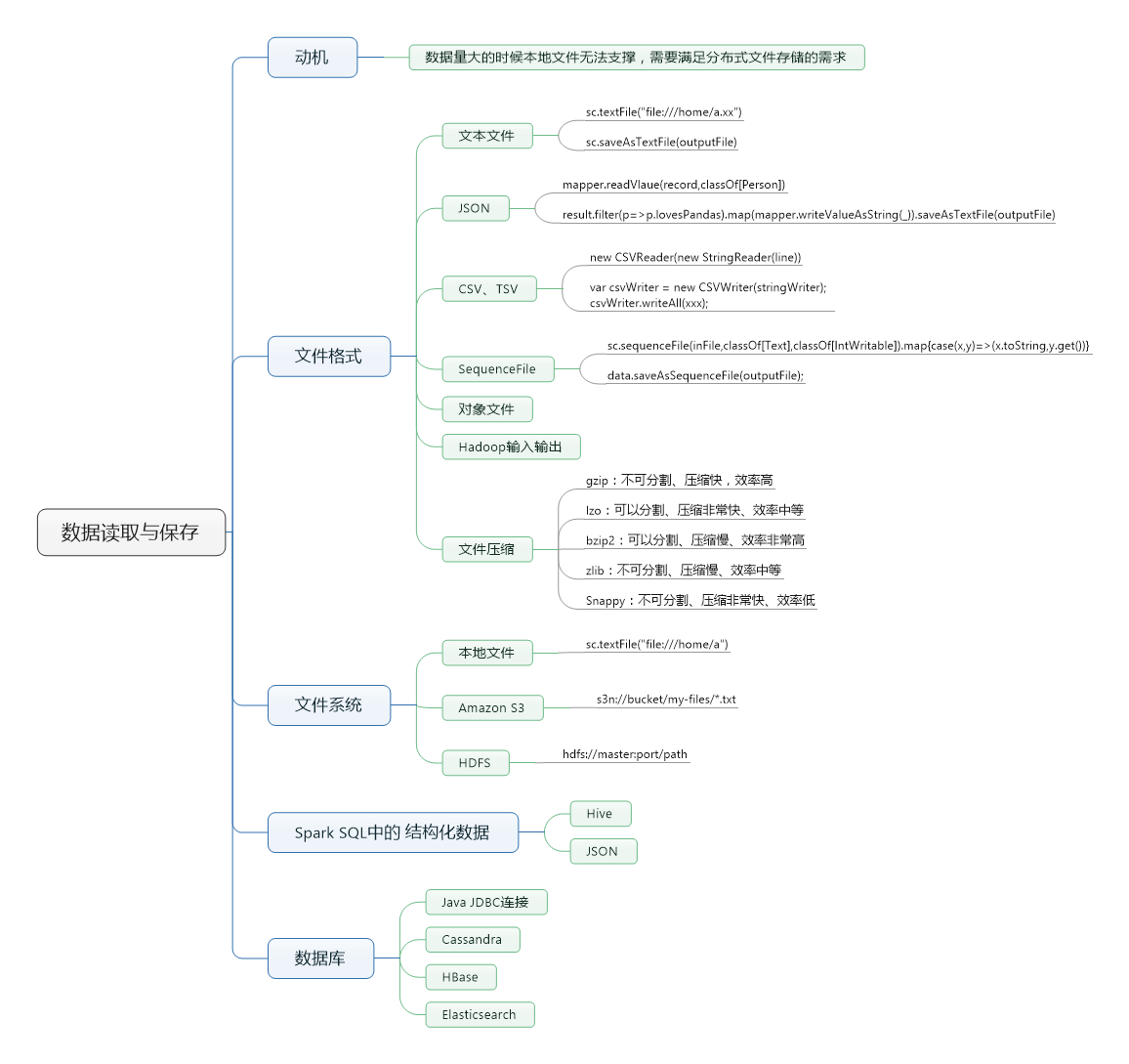
由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式。如S3、HDFS、Cassandra、HBase,有了这些数据的组织形式,数据的来源和存储都可以多样化~本文转自博客园xingoo的博客,原文链接:《Spark快速大数据分析》—— 第五章 数据读取和保存,如需转载请自行联系原博主。...
由于Spark是在Hadoop家族之上发展出来的,因此底层为了兼容hadoop,支持了多种的数据格式。如S3、HDFS、Cassandra、HBase,有了这些数据的组织形式,数据的来源和存储都可以多样化~

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 1
1 0
0

 已为社区贡献3条内容
已为社区贡献3条内容




所有评论(0)