数据分析模型 第二章
期望,概率分布一. 期望二. 概率分布一. 期望根据数学计算,期望值(Expected Value)即为随机变量的结果乘以其的概率的总和。这么看的话其实期望值也是均值,例如班里共10个人,1米8的人有3个,1米7的人有7个,那么抽到1米8的人概率为3/10, 1米7的人概率为7/10,那么这个班的身高期望值也就是这个班的平均身高即1.8*310\frac{3}{10}103+1.7*710\fr
一. 期望
根据数学计算,期望值(Expected Value)即为随机变量的结果乘以其的概率的总和。这么看的话其实期望值也是均值,例如班里共10个人,1米8的人有3个,1米7的人有7个,那么抽到1米8的人概率为3/10, 1米7的人概率为7/10,那么这个班的身高期望值也就是这个班的平均身高即1.8*
3
10
\frac{3}{10}
103+1.7*
7
10
\frac{7}{10}
107 .所以期望值也是均值。
当然了期望值或均值自然会被异常值干扰,例如有一个学生身高3米8。那么我们这个班的平均身高会被拉高。所以我们也可以发现,其实期望值或均值是可以不存在这个班级里的真实身高。
离散变量的期望值:
E
[
X
]
=
∑
x
∈
X
x
p
(
x
)
E[X]=\sum_{x∈X} xp(x)
E[X]=x∈X∑xp(x)
E
[
f
(
X
)
]
=
∑
x
∈
X
f
(
x
)
p
(
x
)
E[f(X)]=\sum_{x∈X} f(x)p(x)
E[f(X)]=x∈X∑f(x)p(x)
连续变量的期望值:
E
[
X
]
=
∫
x
p
(
x
)
d
x
E[X]=\int xp(x)dx
E[X]=∫xp(x)dx
E
[
f
(
x
)
]
=
∫
f
(
x
)
p
(
x
)
d
x
E[f(x)]=\int f(x)p(x)dx
E[f(x)]=∫f(x)p(x)dx
举个例子:
P(X=1)=0.5, P(X=2)=0.4, P(X=3)=0.1
那么:
E[X]=1x0.5+2x0.4+3x0.1
E[log(X)]=log1x0.5+log2 x 0.4+log3x0.1
无论是离散变量还是连续变量:
E
[
a
X
+
b
]
E[aX+b]
E[aX+b]=
a
E
[
X
]
+
b
aE[X]+b
aE[X]+b
这里利用离散变量证明该公式,连续变量证明大同小异:
E
[
a
X
+
b
]
=
∑
x
(
a
x
+
b
)
p
(
x
)
=
a
∑
x
x
p
(
x
)
+
b
∑
x
p
(
x
)
=
a
E
[
X
]
+
b
E[aX+b]=\sum_{x} (ax+b)p(x)=a\sum_{x}xp(x)+b\sum_{x}p(x)=aE[X]+b
E[aX+b]=∑x(ax+b)p(x)=a∑xxp(x)+b∑xp(x)=aE[X]+b
对于两个变量来说
如果均为离散变量则:
E
[
g
(
X
,
Y
)
]
=
∑
x
∈
X
∑
y
∈
Y
g
(
x
,
y
)
p
(
x
,
y
)
\ E[g(X,Y)]=\sum_{x∈X} \sum_{y∈Y} g(x,y)p(x,y)
E[g(X,Y)]=x∈X∑y∈Y∑g(x,y)p(x,y)
如果均为连续变量则:
E
[
g
(
X
,
Y
)
]
=
∫
−
∞
∞
∫
−
∞
∞
g
(
x
,
y
)
p
(
x
,
y
)
d
x
d
y
\ E[g(X,Y)]=\int_{-∞}^{∞}\int_{-∞}^{∞} g(x,y)p(x,y)dxdy
E[g(X,Y)]=∫−∞∞∫−∞∞g(x,y)p(x,y)dxdy
举个例子:
如果g(x,y)=X+Y,X,Y均为连续变量则:
E
[
X
+
Y
]
=
∫
−
∞
∞
∫
−
∞
∞
(
x
+
y
)
p
(
x
,
y
)
d
x
d
y
=
∫
−
∞
∞
∫
−
∞
∞
x
p
(
x
,
y
)
d
x
d
y
+
∫
−
∞
∞
∫
−
∞
∞
y
p
(
x
,
y
)
d
x
d
y
=
E
[
X
]
+
E
[
Y
]
E[X+Y]=\int_{-∞}^{∞}\int_{-∞}^{∞}(x+y)p(x,y)dxdy=\int_{-∞}^{∞}\int_{-∞}^{∞}xp(x,y)dxdy+\int_{-∞}^{∞}\int_{-∞}^{∞}yp(x,y)dxdy=E[X]+E[Y]
E[X+Y]=∫−∞∞∫−∞∞(x+y)p(x,y)dxdy=∫−∞∞∫−∞∞xp(x,y)dxdy+∫−∞∞∫−∞∞yp(x,y)dxdy=E[X]+E[Y]
这里要注意
∫
−
∞
∞
∫
−
∞
∞
x
p
(
x
,
y
)
d
x
d
y
\int_{-∞}^{∞}\int_{-∞}^{∞}xp(x,y)dxdy
∫−∞∞∫−∞∞xp(x,y)dxdy,因为dx和dy对应的反导范围均为(-∞,+∞),所以我们可以换下反导的位置,也就是说先算dx或者先算dy均一样,写成
∫
−
∞
∞
∫
−
∞
∞
x
p
(
x
,
y
)
d
y
d
x
\int_{-∞}^{∞}\int_{-∞}^{∞}xp(x,y)dydx
∫−∞∞∫−∞∞xp(x,y)dydx=
∫
−
∞
∞
x
p
(
x
)
d
x
\int_{-∞}^{∞}xp(x)dx
∫−∞∞xp(x)dx=
E
[
X
]
E[X]
E[X]
根据上述公式,我们也可以得出另两个关于多变量的期望公式:
E
[
X
1
+
X
2
+
.
.
.
.
+
X
n
]
=
E
[
X
1
]
+
E
[
X
2
]
+
.
.
.
+
E
[
X
n
]
E[X1+X2+....+Xn]=E[X1]+E[X2]+...+E[Xn]
E[X1+X2+....+Xn]=E[X1]+E[X2]+...+E[Xn]
E
[
f
(
X
)
+
g
(
Y
)
]
=
E
[
f
(
X
)
]
+
E
[
g
(
Y
)
]
E[f(X)+g(Y)]=E[f(X)]+E[g(Y)]
E[f(X)+g(Y)]=E[f(X)]+E[g(Y)]
若两个变量独立:
E
[
f
(
X
,
Y
)
]
=
E
[
f
(
X
)
f
(
Y
)
]
=
E
[
f
(
X
)
]
E
[
f
(
Y
)
]
E[f(X,Y)]=E[f(X)f(Y)]=E[f(X)] E[f(Y)]
E[f(X,Y)]=E[f(X)f(Y)]=E[f(X)]E[f(Y)]
1.方差(Variance):
V
[
X
]
=
E
[
(
X
−
E
[
X
]
)
2
]
=
∑
x
∈
X
(
x
−
E
[
X
]
)
2
p
(
x
)
V[X]=E[(X-E[X])^2]=\sum_{x∈X} (x-E[X])^2 p(x)
V[X]=E[(X−E[X])2]=x∈X∑(x−E[X])2p(x)从这个公式中我们可以看到,方差也是种期望(很重要),它是关于你随机变量的值和随机变量均值的“距离”的期望或均值。换句话说,方差是用来度量随机变量和其数学期望(即均值)之间的偏离程度。所以我们经常说方差是看该点的离散程度,方差越大点的离散越大,方差越小点的离散度越小。在预测方面,我们也经常会说你对于未来的预测是否有信心,方差越大,说明你预测的点离散程度越大即你预测的点飘忽不定,你越没信心。方差越小,说明你预测的点离散程度越小即你预测的点不会飘忽不定,你越有信心。这里要明确一点,有信心是否意味着你预测的准么。显然不,这里稍微提一下偏差(bias)的概念,后续会细讲,偏差即你预测的值和真值的差距,方差即你预测值的离散程度。偏差的计算有很多种,我们举个最简单的平均偏差,即单项测定值与平均值的偏差(取绝对值)之和,除以测定次数。你会发现,它的算法和方差完全不一样,不是因为距离是否被平方或被绝对值的关系,而是因为期望,是否乘以随机变量对应的概率。总的一句话,偏差是计算预测值和均值的差距,而方差是计算差距的期望或差距的均值 =>离散度。
在预测方面,假设我们预测随机变量X,
E
[
X
]
=
μ
E[X]=\mu
E[X]=μ,如果我们预测随机变量X为c,我们利用平方差(Squared error)公式取期望值:
E
[
(
X
−
c
)
2
]
=
E
[
(
X
−
μ
+
μ
−
c
2
)
]
=
E
[
(
X
−
μ
)
2
]
+
2
(
μ
−
c
)
E
[
X
−
μ
]
+
(
μ
−
c
)
2
=
E
[
(
X
−
μ
)
2
]
+
(
μ
−
c
2
)
>
=
E
[
(
X
−
μ
)
2
]
=
V
[
X
]
E[(X-c)^2]=E[(X-\mu+\mu-c^2)]=E[(X-\mu)^2]+2(\mu -c)E[X-\mu]+(\mu-c)^2=E[(X-\mu)^2]+(\mu-c^2)>=E[(X-\mu)^2]=V[X]
E[(X−c)2]=E[(X−μ+μ−c2)]=E[(X−μ)2]+2(μ−c)E[X−μ]+(μ−c)2=E[(X−μ)2]+(μ−c2)>=E[(X−μ)2]=V[X].
这个推导要注意一点,
E
[
X
−
μ
]
=
E
[
X
]
−
μ
=
E
[
X
]
−
E
[
X
]
=
0
E[X-\mu]=E[X]-\mu=E[X]-E[X]=0
E[X−μ]=E[X]−μ=E[X]−E[X]=0那么如果我们预测X,那最好预测值c是X的期望或者均值,这样其预测的值离散度最低。
方差的计算转化为
V
[
X
]
=
E
[
(
X
−
E
[
X
]
)
2
]
=
E
[
X
2
−
2
X
E
[
X
]
+
E
[
X
]
2
]
=
E
[
X
2
]
−
2
E
[
X
]
E
[
X
]
+
E
[
X
]
2
=
E
[
X
2
]
−
E
[
X
]
2
\ V[X]=E[(X-E[X])^2]= E[X^2-2XE[X]+E[X]^2]=E[X^2]-2E[X]E[X]+E[X]^2=E[X^2]-E[X]^2
V[X]=E[(X−E[X])2]=E[X2−2XE[X]+E[X]2]=E[X2]−2E[X]E[X]+E[X]2=E[X2]−E[X]2
所以
V
[
X
]
=
E
[
X
2
]
−
E
[
X
]
2
V[X]=\ E[X^2]-E[X]^2
V[X]= E[X2]−E[X]2, 这里有个小算法E[ E[X] ]=E[X],也很简单理解E[X]是个数值,数值的期望是它本身,例如E[3]=3 。
方差还有一个运算法则,即
V
[
a
X
]
=
a
2
V
[
X
]
V[aX]=a^2V[X]
V[aX]=a2V[X],这个推导也很简单,
V
[
a
X
]
=
E
[
a
2
X
2
]
−
E
[
a
X
]
2
=
a
2
(
E
[
X
2
]
−
E
[
X
]
2
)
=
a
2
V
[
X
]
V[aX]=\ E[a^2X^2]-E[aX]^2=a^2( E[X^2]-E[X]^2)=a^2V[X]
V[aX]= E[a2X2]−E[aX]2=a2(E[X2]−E[X]2)=a2V[X]
2.协方差(Covariance)
两个变量X,Y,则这俩个变量的协方差为:
c
o
v
(
X
,
Y
)
=
E
[
(
X
−
E
[
X
]
)
(
Y
−
E
[
Y
]
)
]
=
E
[
X
Y
]
−
E
[
X
]
E
[
Y
]
\ cov(X,Y)=E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y]
cov(X,Y)=E[(X−E[X])(Y−E[Y])]=E[XY]−E[X]E[Y]
协方差表示两个变量的总体误差的期望,我们从协方差的公式中可以看到,其实是方差X乘方差Y。
如果Y=X,则变化为
V
[
X
]
=
E
[
X
2
]
−
E
[
X
]
2
\ V[X]=E[X^2]-E[X]^2
V[X]=E[X2]−E[X]2两个变量相同那就是该变量的方差,也就是说方差是协方差的一种特殊情况。数学好的同学会明白这种特殊情况本质就是:X的数学期望E(X)是X的一阶原点矩,方差V(X)是X的二阶中心矩,协方差Cov(X,Y)是X和Y的二阶混合中心矩。再看回协方差的公式,如果X和Y这两个变量的变化趋势相同那么(X-E[X])和(Y-E[Y])的正负符号相同那么最后结果协变量的值为正值,如果X和Y两个变化趋势相反,那么(X-E[X])和(Y-E[Y])的正负符号不同,则协变量的值为负值。若X和Y互相独立,则E[XY]=E[X]E[Y],也就说
c
o
v
(
X
,
Y
)
=
0
\ cov(X,Y)=0
cov(X,Y)=0. 但是,反过来说,如果
c
o
v
(
X
,
Y
)
=
0
\ cov(X,Y)=0
cov(X,Y)=0,那么X和Y不一定独立。如果
c
o
v
(
X
,
Y
)
\ cov(X,Y)
cov(X,Y)不为0,则X和Y必然不独立。
这里有几个推导:
根据方差公式
V
[
X
]
=
E
[
X
2
]
−
E
[
X
]
2
V[X]=\ E[X^2]-E[X]^2
V[X]= E[X2]−E[X]2,我们将X+Y或者X-Y带换X,我们将得到:
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
+
2
c
o
v
(
X
,
Y
)
V[X+Y]=V[X]+V[Y]+2cov(X,Y)
V[X+Y]=V[X]+V[Y]+2cov(X,Y), 若X,Y独立则,
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
V[X+Y]=V[X]+V[Y]
V[X+Y]=V[X]+V[Y]
V
[
X
−
Y
]
=
V
[
X
]
+
V
[
Y
]
−
2
c
o
v
(
X
,
Y
)
V[X-Y]=V[X]+V[Y]-2cov(X,Y)
V[X−Y]=V[X]+V[Y]−2cov(X,Y),若X,Y独立则,
V
[
X
−
Y
]
=
V
[
X
]
+
V
[
Y
]
V[X-Y]=V[X]+V[Y]
V[X−Y]=V[X]+V[Y]
这里有个小细节:
V[X+X]!=V[X]+V[X], V[X+X]=V[2X]=4V[X]
还有几个推导也很简单,这里不在赘述推导过程了:
c
o
v
(
a
X
,
Y
)
=
a
c
o
v
(
X
,
Y
)
cov(aX,Y)=acov(X,Y)
cov(aX,Y)=acov(X,Y)
c
o
v
(
a
X
,
b
Y
)
=
a
b
c
o
v
(
X
,
Y
)
cov(aX,bY)=abcov(X,Y)
cov(aX,bY)=abcov(X,Y)
c
o
v
(
X
+
Z
,
Y
)
=
c
o
v
(
X
,
Y
)
+
c
o
v
(
Z
,
Y
)
cov(X+Z,Y)=cov(X,Y)+cov(Z,Y)
cov(X+Z,Y)=cov(X,Y)+cov(Z,Y)
c
o
v
(
∑
i
=
1
n
X
i
,
∑
j
=
1
m
Y
j
)
=
∑
i
=
1
n
∑
j
=
1
m
c
o
v
(
X
i
,
Y
j
)
cov(\sum_{i=1}^{n}Xi,\sum_{j=1}^{m}Yj)=\sum_{i=1}^{n}\sum_{j=1}^{m}cov(Xi,Yj)
cov(∑i=1nXi,∑j=1mYj)=∑i=1n∑j=1mcov(Xi,Yj)
V
[
∑
i
=
1
n
X
i
]
=
∑
i
=
1
n
V
[
X
i
]
+
∑
i
=
1
n
∑
j
=
1
,
j
!
=
i
n
c
o
v
(
X
i
,
X
j
)
V[\sum_{i=1}^{n}Xi]=\sum_{i=1}^{n}V[Xi]+\sum_{i=1}^{n}\sum_{j=1,j!=i}^{n}cov(Xi,Xj)
V[∑i=1nXi]=∑i=1nV[Xi]+∑i=1n∑j=1,j!=incov(Xi,Xj),j!=i,否则变成方差了。如果这n个Xi互相独立,则
V
[
∑
i
=
1
n
X
i
]
=
∑
i
=
1
n
V
[
X
i
]
V[\sum_{i=1}^{n}Xi]=\sum_{i=1}^{n}V[Xi]
V[∑i=1nXi]=∑i=1nV[Xi].
小结常用的几个公式:
E
[
f
(
X
)
+
g
(
Y
)
]
=
E
[
f
(
X
)
]
+
E
[
g
(
Y
)
]
E[f(X)+g(Y)]=E[f(X)]+E[g(Y)]
E[f(X)+g(Y)]=E[f(X)]+E[g(Y)]
E
[
c
f
(
X
)
]
=
c
E
[
f
(
X
)
]
E[cf(X)]=cE[f(X)]
E[cf(X)]=cE[f(X)]
V
[
c
f
(
X
)
]
=
c
2
V
[
f
(
X
)
]
V[cf(X)]=c^2V[f(X)]
V[cf(X)]=c2V[f(X)]
如果X和Y独立则:
E
[
f
(
X
)
g
(
Y
)
]
=
E
[
f
(
X
)
]
E
[
g
(
Y
)
]
E[f(X)g(Y)]=E[f(X)]E[g(Y)]
E[f(X)g(Y)]=E[f(X)]E[g(Y)]
V
[
f
(
X
)
+
g
(
Y
)
]
=
V
[
f
(
X
)
]
+
V
[
(
g
(
Y
)
)
]
V[f(X)+g(Y)]=V[f(X)]+V[(g(Y))]
V[f(X)+g(Y)]=V[f(X)]+V[(g(Y))]
与协方差关系很紧密的概念是相关系数,相关系数(Correlation) 公式为:
c
o
r
r
(
X
,
Y
)
=
c
o
v
(
X
,
Y
)
V
[
X
]
V
[
Y
]
corr(X,Y)=\frac{cov(X,Y)}{\sqrt{V[X] V[Y]}}
corr(X,Y)=V[X]V[Y]cov(X,Y)为什么会有相关系数这个概念,如果我们单单有协方差,我们会发现当协方差是会受到量纲的影响,什么意思,若你X和Y本身单位是m(米),你计算完后假如是100米的协方差,若你把X和Y的单位换成厘米,那么对应的协方差将会至少扩大100倍。所以为了避免量纲的影响从而引入相关系数,我们从相关系数的公式里也会发现,分母和分子量纲将会约掉。使相关系数的结果但但是一个值,无单位,容易比较。这种方法很常见,之后我们会在高等数据分析里讲到计算风险,风险的值也是无量纲的。
切回正题,
c
o
r
r
(
X
,
Y
)
\ corr(X,Y)
corr(X,Y)的值∈[0,1],值越靠近1,则说明X,Y这两个变量关系越大且趋势相同例如正比,否则越靠近0则说明X,Y这里变量没有关系。
3.弱大数理论(weak law of large numbers)
假如从一个变量X里面取n个样本,即x1,x2,…xn
那么样本均值为:
x
‾
=
1
n
∑
i
=
1
n
x
i
\overline{x}=\frac{1}{n} \sum_{i=1}^{n} xi
x=n1i=1∑nxi
当n增加时,
x
‾
\overline{x}
x会收敛于X的期望 E[X].
假如这边有n个i.i.d变量(独立同分布变量),X1,X2,…Xn,既然同分布,那么假设该分布期望E[Xi]=
μ
\mu
μ, 当n越大,则这些变量的均值(
X
1
+
X
2
+
.
.
.
X
n
n
\frac{X1+X2+...Xn}{n}
nX1+X2+...Xn)会向其分布的期望
μ
\mu
μ收敛. 我们用数学公式写的好看一点,即
P
{
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
−
μ
∣
>
ε
}
→
0
,
当
n
→
∞
\ P\{ |\frac{X1+X2+...+Xn}{n} -\mu| >\varepsilon \} →0,当n→∞
P{∣nX1+X2+...+Xn−μ∣>ε}→0,当n→∞
这个公式在说,当n→
∞
∞
∞时,
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
−
μ
∣
|\frac{X1+X2+...+Xn}{n} -\mu|
∣nX1+X2+...+Xn−μ∣的值比
ε
\varepsilon
ε(一个特别小的数值,也叫做误差例如0.001)大的概率趋近于0,也就是说
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
−
μ
∣
|\frac{X1+X2+...+Xn}{n} -\mu|
∣nX1+X2+...+Xn−μ∣的值比
ε
\varepsilon
ε还小,侧面说明
X
1
+
X
2
+
.
.
.
+
X
n
n
\frac{X1+X2+...+Xn}{n}
nX1+X2+...+Xn几乎等于
μ
\mu
μ.
这就是大数定律里弱大数定律的一个概念,大数定律还有很多定律在总结大数所产生的规律。我在此仅把老师所讲的弱大数理论和推导给大家分享下。因为该推导涉及了切比雪夫不等式,而切比雪夫不等式涉及了马尔可夫不等式,所以在此简略的带大家回顾温习下这俩个不等式。
马尔可夫不等式(Markov’s inequality)
马尔可夫不等式:
X 为非负数的随机变量, a>0的任何值,则
P
{
X
>
=
a
}
<
=
E
[
X
]
a
\ P\{ X \ >=a \} <= \frac{E[X]}{a}
P{X >=a}<=aE[X]
证明:
在此利用连续变量X和该概率分布p(x)来证明,离散变量证明大同小异。
E
[
X
]
=
∫
0
∞
x
p
(
x
)
d
x
=
∫
0
a
x
p
(
x
)
d
x
+
∫
a
∞
x
p
(
x
)
d
x
>
=
∫
a
∞
x
p
(
x
)
d
x
>
=
∫
a
∞
a
p
(
x
)
d
x
=
a
∫
a
∞
p
(
x
)
d
x
=
a
P
{
X
>
=
a
}
E[X]=\int_{0}^{∞}xp(x)dx=\int_{0}^{a}xp(x)dx+\int_{a}^{∞}xp(x)dx >=\int_{a}^{∞}xp(x)dx >=\int_{a}^{∞}ap(x)dx=a\int_{a}^{∞}p(x)dx=a P\{ X>=a \}
E[X]=∫0∞xp(x)dx=∫0axp(x)dx+∫a∞xp(x)dx>=∫a∞xp(x)dx>=∫a∞ap(x)dx=a∫a∞p(x)dx=aP{X>=a}
切比雪夫不等式(Chebyshev’s inequality)
切比雪夫不等式:
假如一个X随机变量它的E[X]=
μ
\mu
μ, V[X]=
σ
2
\sigma ^2
σ2, 那么对于任何 k>0, 则
P
{
∣
X
−
μ
∣
>
=
k
}
<
=
σ
2
k
2
\ P\{ |X-\mu |>=k \} <= \frac{\sigma^2}{k^2}
P{∣X−μ∣>=k}<=k2σ2
证明:
我们可以把
(
X
−
μ
)
2
(X-\mu)^2
(X−μ)2看做一个非负数的随机变量,带入a=
k
2
\ k^2
k2,利用马尔可夫不等式,则
P
{
(
X
−
μ
)
2
>
=
k
2
}
<
=
E
[
(
X
−
μ
)
2
]
k
2
\ P\{ (X-\mu)^2 >=k^2 \} <= \frac{E[(X-\mu)^2]}{k^2}
P{(X−μ)2>=k2}<=k2E[(X−μ)2]
因为
(
X
−
μ
)
2
(X-\mu)^2
(X−μ)2 与
∣
X
−
μ
∣
>
=
k
|X-\mu|>=k
∣X−μ∣>=k是充分必要条件。则
P
{
∣
X
−
μ
∣
>
=
k
}
<
=
E
[
(
X
−
μ
)
2
]
k
2
=
σ
2
k
2
\ P\{ |X-\mu| >=k \} <= \frac{E[(X-\mu)^2]}{k^2}=\frac{\sigma ^2}{k^2}
P{∣X−μ∣>=k}<=k2E[(X−μ)2]=k2σ2
弱大数理论(weak law of large numbers)
证明:
已知这些随机变量为i.i.d独立同分布,那么假设这些随机变量有有限的方差
σ
2
\sigma^2
σ2
即:
V[
X
1
+
X
2
+
.
.
.
.
+
X
n
n
\frac{X1+X2+....+Xn}{n}
nX1+X2+....+Xn]=
σ
2
n
\frac{\sigma^2}{n}
nσ2 和E[
X
1
+
X
2
+
.
.
.
.
+
X
n
n
\frac{X1+X2+....+Xn}{n}
nX1+X2+....+Xn]=
μ
\mu
μ
那么利用切比雪夫不等式得:
P
{
∣
X
1
+
X
2
+
.
.
.
+
X
n
n
−
μ
∣
>
ε
}
<
=
σ
2
n
ε
2
\ P\{ |\frac{X1+X2+...+Xn}{n} -\mu| >\varepsilon \}<=\frac{\sigma^2}{n\varepsilon^2}
P{∣nX1+X2+...+Xn−μ∣>ε}<=nε2σ2, 当n越大时,
σ
2
n
ε
2
→
0
\frac{\sigma^2}{n\varepsilon^2}→0
nε2σ2→0.
4.期望值的存在(Existence of expected values)
①期望值不一定总是存在的
②如果X作为我们的总体是有限的,那么E[X]总是存在,但通常情况下X作为总体一般是无穷的。
③X作为总体一般由整数或者实数组成的,这样的话不能保证期望值的存在。相反,四分位总是存在。
5.估计方程关于随机变量的期望值和方差(Approximate Expectations of Functions of RVs)
假设这里有个方程f(x)和随机变量X,我们要明确一点E[f(X)]!=f(E[X])。
假设我们已知E[X]=
μ
\mu
μ,V[X]=
σ
2
\sigma^2
σ2当然了具体的E[X]和V[X]需要你自己找,这里仅仅利用
μ
\mu
μ和
σ
2
\sigma^2
σ2做个例子。这里的期望和方差,不要对号入座,不要看到
μ
,
σ
2
\mu,\sigma^2
μ,σ2就觉得这是正态分布,无论是什么分布它都会有期望和方差,只不过正态分布的参数是期望和方差,举个例子,伯努利分布的参数是
θ
\theta
θ和
n
n
n,它的期望和方差分别是
θ
,
(
1
−
θ
)
\theta,(1-\theta)
θ,(1−θ)
那么:
E
[
f
(
X
)
]
≈
f
(
μ
)
+
[
d
2
f
(
X
)
d
X
2
∣
X
=
μ
]
✖
σ
2
2
E[f(X)]≈f(\mu)+[\frac{d^2f(X)}{dX^2}|_{X=\mu}] ✖\frac{\sigma^2}{2}
E[f(X)]≈f(μ)+[dX2d2f(X)∣X=μ]✖2σ2
V
[
f
(
X
)
]
≈
[
d
f
(
X
)
d
x
∣
X
=
μ
]
2
σ
2
V[f(X)]≈[\frac{df(X)}{dx}|_{X=\mu}]^2\sigma^2
V[f(X)]≈[dxdf(X)∣X=μ]2σ2
我们可以利用该公式找到方程的期望值和方差,这公式的本质其实是泰勒函数展开的形式。
举个例子:
假设E[X]=
μ
\mu
μ,V[X]=
σ
2
\sigma^2
σ2,该方程f(X)=a
X
2
X^2
X2+c
那么我们能得到:
d
f
(
X
)
d
x
\frac{df(X)}{dx}
dxdf(X)=2aX和
d
2
f
(
X
)
d
X
2
\frac{d^2f(X)}{dX^2}
dX2d2f(X)=2a
那么带入上述公式得:
E[f(X)]≈a
μ
2
\mu^2
μ2+c+a
σ
2
\sigma^2
σ2
V[f(X)]≈
4
(
a
μ
)
2
σ
2
4(a\mu)^2 \sigma^2
4(aμ)2σ2
二. 概率分布
讲概率分布之前,先说明下写法和基本的概念:
p
(
x
∣
θ
)
,
x
∈
X
,
θ
∈
Θ
p(x|\theta), x∈X,\theta∈Θ
p(x∣θ),x∈X,θ∈Θ
θ
\theta
θ=(
θ
1
,
θ
2
,
.
.
.
θ
k
\theta1,\theta2,...\theta k
θ1,θ2,...θk)为参数,一般参数的数量k要远小于X总体的数量。
举个例子:
p(x|a=1,b=2),那么该概率分布由参数a=1,和参数b=2控制该分布的形状。Θ意味着a和b能取得值,例如a和b只能是正整数,也称为有效参数空间,所以a,b∈Θ。
另外要提得一点是,E[X]=f(θ),V[X]=g(θ),如果随机变量符合某个分布,那么它得期望值和方差其实可以写成关于该分布参数的一个函数数学表达式的。
另外对于连续随机变量的概率分布的面积为1,离散随机变量的概率和也为1.
Ⅰ.高斯分布(也称正态分布,Normal distribution)
在数据分析模型这课里,不涉及多元高斯分布,而我会在高等数据分析的课里讲解。正态分布以X=
μ
\mu
μ对称,中间高两边低。正态分的随机变量是连续的,不是离散的。
正态分布的公式:
p
(
x
∣
μ
,
σ
2
)
=
(
1
2
π
σ
2
)
1
2
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
p(x|\mu,\sigma^2)=(\frac{1}{2\pi\sigma^2})^{\frac{1}{2}}exp({-\frac{(x-\mu)^2}{2\sigma^2}})
p(x∣μ,σ2)=(2πσ21)21exp(−2σ2(x−μ)2)
这里θ=(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),
μ
\mu
μ是该分布的均值,
σ
2
\sigma^2
σ2是该分布的方差,如下是正态分布的图: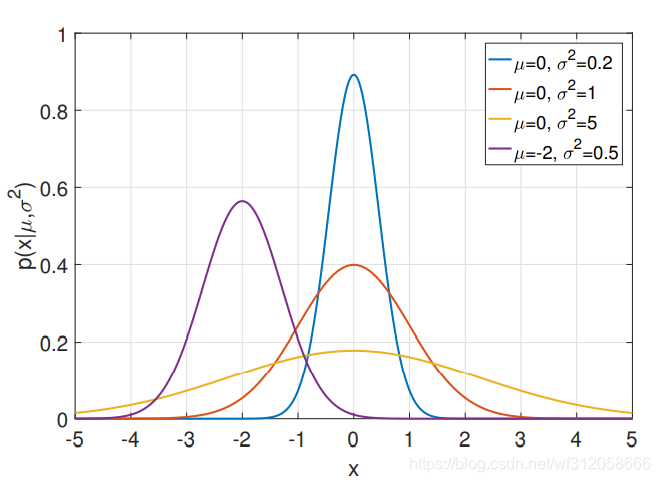
如果一个随机变量X服从正态分布,我们的写法是:
X
~
N
(
μ
,
σ
2
)
X ~N(\mu,\sigma^2)
X~N(μ,σ2)
E
[
X
]
=
μ
,
V
[
X
]
=
σ
2
E[X]=\mu, V[X]=\sigma^2
E[X]=μ,V[X]=σ2
N(0,1)为标准正态分布(standard normal distribution)
如果Z~N(0,1), X~N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),那么:
X
=
σ
Z
+
μ
X=\sigma Z+\mu
X=σZ+μ
Z
=
X
−
μ
σ
Z=\frac{X-\mu}{\sigma}
Z=σX−μ为标准正态随机变量(standard normal random variable )
如果X~N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),那么:
E
[
X
]
=
μ
,
V
[
X
]
=
σ
2
E[X]=\mu,V[X]=\sigma^2
E[X]=μ,V[X]=σ2
对于任意正态分布N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),68.27%的概率会落在(
μ
−
σ
,
μ
+
σ
\mu -\sigma ,\mu+\sigma
μ−σ,μ+σ)即下图蓝色区域
对于任意正态分布N(
μ
,
σ
2
\mu,\sigma^2
μ,σ2),95.45%的概率会落在(
μ
−
2
σ
,
μ
+
2
σ
\mu -2\sigma ,\mu+2\sigma
μ−2σ,μ+2σ)即下图蓝色区域
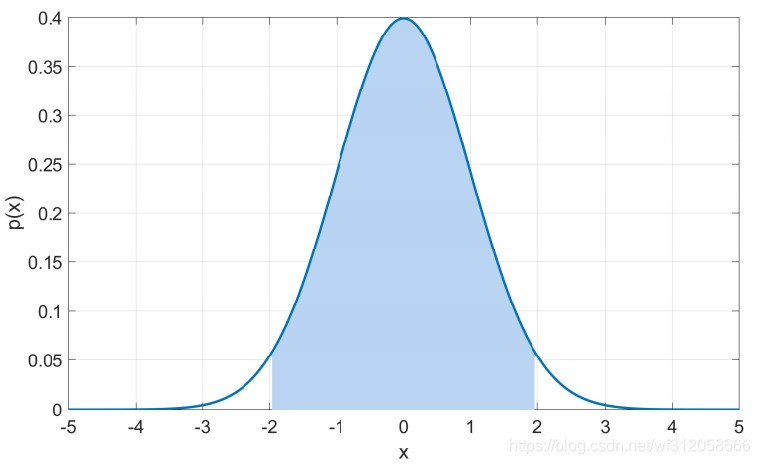
正态分布还有最后一个性质,即正态分布的可加性。
如果X1~N(
μ
1
,
σ
1
2
\mu_1,\sigma^2_1
μ1,σ12), X2~N(
μ
2
,
σ
2
2
\mu_2,\sigma^2_2
μ2,σ22)
那么,X1+X2~N(
μ
1
+
μ
2
\mu_1+\mu_2
μ1+μ2,
σ
1
2
+
σ
2
2
\sigma^2_1+\sigma^2_2
σ12+σ22)
如果X~N(
μ
,
σ
2
\mu, \sigma^2
μ,σ2), X=
∑
i
=
1
n
X
i
\sum_{i=1}^{n}X_i
∑i=1nXi,
X
i
X_i
Xi~N(
μ
i
,
σ
i
2
\mu_i,\sigma^2_i
μi,σi2)
那么,
∑
i
=
1
n
μ
i
=
μ
\sum_{i=1}^{n}\mu_i=\mu
∑i=1nμi=μ,
∑
i
=
1
n
σ
i
2
=
σ
2
\sum_{i=1}^{n}\sigma^2_i=\sigma^2
∑i=1nσi2=σ2
其证明也很简单,如果X1~N(
μ
1
,
σ
1
2
\mu_1,\sigma^2_1
μ1,σ12), X2~N(
μ
2
,
σ
2
2
\mu_2,\sigma^2_2
μ2,σ22),那么E[X1]+E[X2]=E[X1+X2]=
μ
1
+
μ
2
\mu_1+\mu_2
μ1+μ2, V[X1]+V[X2]=V[X1+X2]=
σ
1
2
+
σ
2
2
\sigma^2_1+\sigma^2_2
σ12+σ22, 所以X1+X2~N(
μ
1
+
μ
2
\mu_1+\mu_2
μ1+μ2,
σ
1
2
+
σ
2
2
\sigma^2_1+\sigma^2_2
σ12+σ22)。
Ⅱ伯努利分布(Bernoulli distribution)
伯努利分布的随机变量是离散的,即X={0,1}
伯努利分布公式:
P
(
X
=
1
∣
θ
)
=
θ
,
θ
∈
[
0
,
1
]
P(X=1|\theta)=\theta, \theta∈[0,1]
P(X=1∣θ)=θ,θ∈[0,1]
当X=1是代表成功,而一般我们定义
θ
\theta
θ是成功的概率。X=0是失败,那么
1
−
θ
1-\theta
1−θ为失败的概率。
这样我们又可以把该公式写成:
p
(
x
∣
θ
)
=
θ
x
(
1
−
θ
)
(
1
−
x
)
,
θ
∈
[
0
,
1
]
,
x
∈
{
0
,
1
}
p(x|\theta)=\theta^x(1-\theta)^{(1-x)} ,\theta∈[0,1],x∈\{0,1\}
p(x∣θ)=θx(1−θ)(1−x),θ∈[0,1],x∈{0,1}
如果X服从伯努利分布,那么我们可以写成X~Be(
θ
\theta
θ).
E
[
X
]
=
θ
,
V
[
X
]
=
θ
(
1
−
θ
)
E[X]=\theta, V[X]=\theta(1-\theta)
E[X]=θ,V[X]=θ(1−θ)
推导也很简单,因为
E
[
X
]
=
0
∗
(
1
−
θ
)
+
1
∗
θ
=
θ
,
V
[
X
]
=
E
[
X
2
]
−
E
[
X
]
2
=
θ
−
θ
2
=
θ
(
1
−
θ
)
E[X]=0*(1-θ)+1*θ=θ,V[X]=E[X^2]-E[X]^2=\theta-\theta^2=\theta(1-\theta)
E[X]=0∗(1−θ)+1∗θ=θ,V[X]=E[X2]−E[X]2=θ−θ2=θ(1−θ).
伯努利分布图像为:

我们利用伯努利分布的方差画图如下:
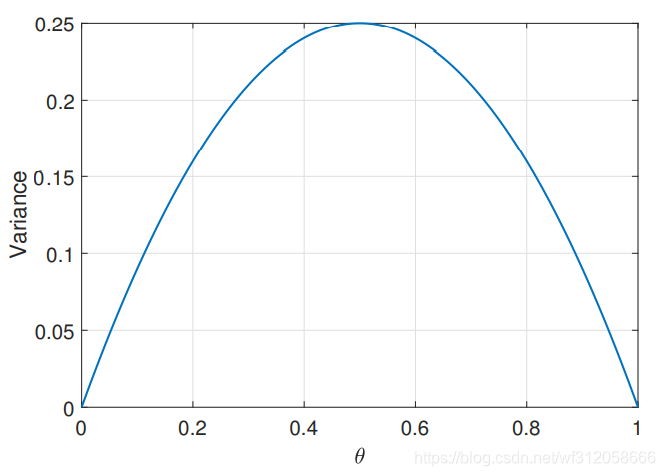
我们可以看到,当
θ
=
1
2
\theta=\frac{1}{2}
θ=21时,方差最大。在数学意义上
θ
(
1
−
θ
)
\theta(1-\theta)
θ(1−θ)这就是个一元二次函数算极值而已。但在哲学含义上却很值得我们思考,假设有这么A,B,C三种硬币,A硬币正面为人头,反面为花色。B硬币正反两面均为人头,C硬币正反两面均为花色。这三种硬币都仅仅抛一次,你觉得仅靠抛这一次硬币得到人头的概率,我们对哪种硬币掷出人头的概率更有信心,当然是B和C硬币,B硬币掷出人头的概率为1,C硬币掷出人头的概率是0.这也就是为什么
θ
\theta
θ=1或者0时,它的方差为0. 这里在稍微提一下二项式分布,二项式分布仅仅是做了n次伯努利实验而已,假设我们做了5次抛各A,B,C硬币的实验,人头为1,花色为0,我们得到A硬币结果[0,0,0,1,1],B硬币结果[1,1,1,1,1], C硬币结果[0,0,0,0,0],我们当然对B硬币和C硬币得到人头概率更有信心,而A硬币人头的概率我们却拿不准。 从这我们也可以明白A硬币虽然
θ
=
1
2
\theta=\frac{1}{2}
θ=21但它的方差是很大的,预测结果很离散,你可以说它是
2
5
\frac{2}{5}
52也可能下次你再抛5次概率又变成其它值。甚至你抛五次有可能全人头或全花色。
Ⅲ.二项式分布(Binomial distribution)
二项式分布是做了n次伯努利试验,即有n个随机变量X=(X1,X2,…,Xn),Xi∈{0,1}举个例子X=(0,1,1,1,0,1,0,0)
我们一般用n来表示有多少个随机变量即为多少次伯努利试验,而m来表示成功的次数,那么根据上述例子,n=8,m=4.θ是一次伯努利试验的成功概率.
那么实验n次,成功m次的概率即为二项式分布公式:
p
(
m
∣
θ
)
=
(
n
m
)
∏
j
=
1
n
p
(
x
i
∣
θ
)
=
(
n
m
)
θ
m
(
1
−
θ
)
(
n
−
m
)
p(m|\theta)=\begin{pmatrix}n\\m\\\end{pmatrix} \prod_{j=1}^{n} p(x_i|\theta) =\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}
p(m∣θ)=(nm)j=1∏np(xi∣θ)=(nm)θm(1−θ)(n−m)
(
n
m
)
=
n
!
(
n
−
m
)
!
m
!
\begin{pmatrix}n\\m\\\end{pmatrix}=\frac{n!}{(n-m)!m!}
(nm)=(n−m)!m!n!这里涉及高中数学的排列组合,在此不再赘述。
二项式分布为离散函数,如下图:

若M服从二项式分布,我们写法为
M
~
B
i
n
(
θ
,
n
)
M~Bin(\theta,n)
M~Bin(θ,n),M为一共成功的次数.
E
[
M
]
=
n
θ
,
V
[
M
]
=
n
θ
(
1
−
θ
)
E[M]=n\theta, V[M]=n\theta(1-\theta)
E[M]=nθ,V[M]=nθ(1−θ)
推导也很简单,因为进行了n次伯努利分布实验,每次实验独立。则E[M]=n*(0*(1-θ)+1*θ)=nθ,根据我们之前讲的若
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
+
2
c
o
v
(
X
,
Y
)
V[X+Y]=V[X]+V[Y]+2cov(X,Y)
V[X+Y]=V[X]+V[Y]+2cov(X,Y), 若X,Y独立则,
V
[
X
+
Y
]
=
V
[
X
]
+
V
[
Y
]
V[X+Y]=V[X]+V[Y]
V[X+Y]=V[X]+V[Y], 那么进行n次伯努利实验,每次实验独立,X~Be(θ),V[M]=nV[X]=nθ(1-θ)。当然了这里还有一个计算量很大的方法,那就是利用我们最早说的离散变量期望值公式来计算
E
[
M
]
E[M]
E[M]和
E
[
M
2
]
E[M^2]
E[M2],即:
E
[
M
]
=
∑
m
=
0
n
m
(
n
m
)
θ
m
(
1
−
θ
)
(
n
−
m
)
=
n
θ
E[M]=\sum_{m=0}^{n}m\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}=n\theta
E[M]=∑m=0nm(nm)θm(1−θ)(n−m)=nθ
E
[
M
2
]
=
∑
m
=
0
n
m
2
(
n
m
)
θ
m
(
1
−
θ
)
(
n
−
m
)
=
n
(
n
−
1
)
θ
2
+
n
θ
E[M^2]=\sum_{m=0}^{n}m^2\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}=n(n−1)\theta^2+n\theta
E[M2]=∑m=0nm2(nm)θm(1−θ)(n−m)=n(n−1)θ2+nθ
再利用
V
[
M
]
=
E
[
M
2
]
−
E
[
M
]
2
V[M]=E[M^2]-E[M]^2
V[M]=E[M2]−E[M]2得出V[M]=nθ(1-θ)。
二项式分布的最后一个性质是连加性
如果
M
1
~
B
i
n
(
θ
,
n
1
)
M_1~Bin(\theta,n_1)
M1~Bin(θ,n1),
M
2
~
B
i
n
(
θ
,
n
2
)
M_2~Bin(\theta,n_2)
M2~Bin(θ,n2)
那么:
M
1
+
M
2
~
B
i
n
(
θ
,
n
1
+
n
2
)
M_1+M_2~Bin(\theta,n_1+n_2)
M1+M2~Bin(θ,n1+n2)
推导也很简单,因为
M
1
~
B
i
n
(
θ
,
n
1
)
M_1~Bin(\theta,n_1)
M1~Bin(θ,n1),
M
2
~
B
i
n
(
θ
,
n
2
)
M_2~Bin(\theta,n_2)
M2~Bin(θ,n2),那么
E
[
M
1
]
+
E
[
M
2
]
=
E
[
M
1
+
M
2
]
=
(
n
1
+
n
2
)
θ
E[M_1]+E[M_2]=E[M_1+M_2]=(n_1+n_2)\theta
E[M1]+E[M2]=E[M1+M2]=(n1+n2)θ,
V
[
M
1
]
+
V
[
M
2
]
=
V
[
M
1
+
M
2
]
=
(
n
1
+
n
2
)
θ
(
1
−
θ
)
V[M_1]+V[M_2]=V[M_1+M_2]=(n_1+n_2)\theta(1-\theta)
V[M1]+V[M2]=V[M1+M2]=(n1+n2)θ(1−θ),所以
M
1
+
M
2
~
B
i
n
(
θ
,
n
1
+
n
2
)
M_1+M_2~Bin(\theta,n_1+n_2)
M1+M2~Bin(θ,n1+n2)
大家可能会问,伯努利分布是否有连加性质,答案是没有,大家可以尝试这个方法自己证明下。这个连加性的证明方法是小弟我当时给我老师提出的,老师的回答是默许了,但告诉小弟我有一套更复杂的官方证明。感兴趣的同学可以查查并告诉小弟我,在此感谢了。
Ⅳ.离散均匀分布(Discrete Uniform Distribution)
不像二项式分布一样,m的取不同的值有唯一的概率对应。当然这些概率会随着n的增大,向nθ收敛。但是离散均匀分布则是,随机变量取不同的值可以有相同的概率,例如掷色子,随机变量X=1,2,3,4,5,6的概率均为
1
6
\frac{1}{6}
61这就是一种均匀分布(uniform distribution)
那么离散均匀分布的公式:
P
(
X
=
k
∣
a
,
b
)
=
1
b
−
a
+
1
P(X=k|a,b)=\frac{1}{b-a+1}
P(X=k∣a,b)=b−a+11
X∈{a,…,b},且b>=a. 例如骰子X∈{1,2,3,4,5,6},a=1,b=6.其实这里的两个参数a,b其实可以看做一个参数即b-a+1, b-a+1的含义是有多少个元素在随机变量里,例如骰子有b-a+1=6-1+1=6个面。
如果一个随机变量X服从离散均匀分布
X
~
U
(
a
,
b
)
X~U(a,b)
X~U(a,b):
E
[
X
]
=
a
+
b
2
,
V
[
X
]
=
(
b
−
a
+
1
)
2
−
1
12
E[X]=\frac{a+b}{2}, V[X]=\frac{(b-a+1)^2-1}{12}
E[X]=2a+b,V[X]=12(b−a+1)2−1
这里注意的是E[X]不一定是整数。
Ⅴ.连续均匀分布(Continuous Uniform Distribution)
如果随机变量是连续的,那么如果X服从连续均匀分布
X
~
U
(
a
,
b
)
,
a
>
b
X~U(a,b),a>b
X~U(a,b),a>b:
p
(
x
∣
a
,
b
)
=
{
0
,
x
<
a
1
b
−
a
,
a
<
=
x
<
=
b
0
,
x
>
b
p(x|a,b) = \begin{cases} \ 0, & x<a \\ \frac{1}{b-a}, & a<=x<=b \\ \ 0,& x>b \\ \end{cases}
p(x∣a,b)=⎩⎪⎨⎪⎧ 0,b−a1, 0,x<aa<=x<=bx>b
E
[
X
]
=
a
+
b
2
=
a
+
w
2
,
V
[
X
]
=
(
b
−
a
)
2
12
=
w
2
12
E[X]=\frac{a+b}{2}=a+\frac{w}{2}, V[X]=\frac{(b-a)^2}{12}=\frac{w^2}{12}
E[X]=2a+b=a+2w,V[X]=12(b−a)2=12w2
a:决定了分布从哪里开始
w=b-a:决定了分布的宽度
如下图关于连续均匀分布:

Ⅵ.泊松分布(Poisson Distribution)
如果离散随机变量X服从泊松分布,我们写成X~Poi(
λ
\lambda
λ),
λ
\lambda
λ的含义是在单位时间内发生事件的次数,也称为率(rate)。X的含义是在一段时间内(一段周期)内发生事件的次数。
泊松分布的公式:
p
(
X
=
k
∣
λ
)
=
λ
k
e
x
p
(
−
λ
)
k
!
p(X=k|\lambda)=\frac{\lambda^kexp(-\lambda)}{k!}
p(X=k∣λ)=k!λkexp(−λ)
E
[
X
]
=
λ
,
V
[
X
]
=
λ
E[X]=\lambda, V[X]=\lambda
E[X]=λ,V[X]=λ
泊松分布得期望和方差推导,依旧按照离散随机变量期望公式来算
E
[
X
]
,
E
[
X
2
]
E[X],E[X^2]
E[X],E[X2].
E
[
X
]
=
∑
k
=
1
∞
k
λ
k
e
x
p
(
−
λ
)
k
!
=
λ
e
−
λ
∑
k
=
1
∞
λ
k
−
1
(
k
−
1
)
!
E[X]=\sum_{k=1}^{∞} k \frac{\lambda^{k} exp(-\lambda)}{k!}=\lambda e^{-\lambda} \sum_{k=1}^{∞} \frac{\lambda^{k-1}}{(k-1)!}
E[X]=∑k=1∞kk!λkexp(−λ)=λe−λ∑k=1∞(k−1)!λk−1
∑
k
=
1
∞
λ
k
−
1
(
k
−
1
)
!
=
e
λ
\sum_{k=1}^{∞} \frac{\lambda^{k-1}}{(k-1)!}=e^\lambda
∑k=1∞(k−1)!λk−1=eλ泰勒展开式
所以
E
[
X
]
=
λ
e
−
λ
e
λ
=
λ
E[X]=\lambda e^{-\lambda} e^{\lambda}=\lambda
E[X]=λe−λeλ=λ
因为
E
[
X
2
]
=
∑
k
=
1
∞
k
2
λ
k
e
x
p
(
−
λ
)
k
!
=
λ
(
λ
+
1
)
E[X^2]=\sum_{k=1}^{∞} k^2 \frac{\lambda^{k} exp(-\lambda)}{k!}=\lambda (\lambda +1)
E[X2]=∑k=1∞k2k!λkexp(−λ)=λ(λ+1)
所以V[X]=
E
[
X
2
]
−
E
[
X
]
2
=
λ
E[X^2]-E[X]^2=\lambda
E[X2]−E[X]2=λ
如下图关于泊松分布: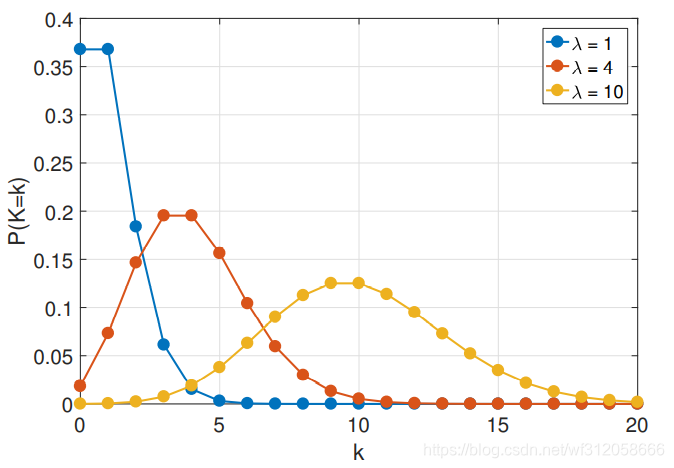
泊松分布也有连加性:
如果X1∈Poi(
λ
1
\lambda_1
λ1), X1∈Poi(
λ
2
\lambda_2
λ2),那么X1+X2∈Poi(
λ
1
+
λ
2
\lambda_1+\lambda_2
λ1+λ2)
另外,如果
X
T
X_T
XT意味着发生多少事情在一段时间或者周期
T
T
T内,那么将这段时间缩短k倍,那么会发生
X
T
/
k
X_{T/k}
XT/k个事情,且
X
T
/
k
X_{T/k}
XT/k~Poi(
λ
k
\frac{\lambda}{k}
kλ).
因为我们的
λ
\lambda
λ本质是单位时间T=1乘以发生事件的期望,如果单位时间变成T=
1
k
\frac{1}{k}
k1那么我们
λ
\lambda
λ*
1
k
\frac{1}{k}
k1.
根据泊松分布的图像,我们可以看出泊松分布好像和二项式分布很像,没错,当二项式的n足够多,二项式将近似为泊松,当泊松的 λ \lambda λ足够大时,从离散函数变成连续函数时,它将变化为正态分布。所以正态分布其实是所有分布的样子,当样本趋于极限总体时。
二项式分布推导泊松分布(
n
→
∞
n→∞
n→∞时)
lim
n
→
∞
p
(
m
∣
θ
)
=
(
n
m
)
θ
m
(
1
−
θ
)
(
n
−
m
)
\lim_{n\to ∞}p(m|\theta)=\begin{pmatrix}n\\m\\\end{pmatrix}\theta^m(1-\theta)^{(n-m)}
limn→∞p(m∣θ)=(nm)θm(1−θ)(n−m)
令 θ \theta θ= λ n \frac{\lambda}{n} nλ
= lim n → ∞ ( n m ) ( λ n ) m ( 1 − λ n ) n − m =\lim_{n\to ∞}\begin{pmatrix}n\\m\\\end{pmatrix}(\frac{\lambda}{n})^m(1-\frac{\lambda}{n})^{n-m} =limn→∞(nm)(nλ)m(1−nλ)n−m
当n→∞,θ→∞ 时.
= lim n → ∞ n ! ( n − m ) ! m ! ( λ n ) m ( 1 − λ n ) n ( 1 − λ n ) − m =\lim_{n\to ∞}\frac{n!}{(n-m)!m!}(\frac{\lambda}{n})^m(1-\frac{\lambda}{n})^n(1-\frac{\lambda}{n})^{-m} =limn→∞(n−m)!m!n!(nλ)m(1−nλ)n(1−nλ)−m
因为n无穷大时, ( 1 − λ n ) − m (1-\frac{\lambda}{n})^{-m} (1−nλ)−m=1, n ! ( n − m ) ! ( 1 n m ) \frac{n!}{(n-m)!} (\frac{1}{n^m}) (n−m)!n!(nm1)=1, ( 1 − λ n ) n (1-\frac{\lambda}{n})^n (1−nλ)n=exp(- λ \lambda λ)
所以
=
lim
n
→
∞
λ
m
m
!
e
x
p
(
−
λ
)
=\lim_{n\to ∞}\frac{\lambda^m}{m!}exp(-\lambda)
=limn→∞m!λmexp(−λ),泊松分布
泊松分布推导正态分布(当
λ
\lambda
λ→
∞
∞
∞):
先澄清一点,正常情况的泊松分布是推不到正态分布的,中心极限定理的泊松分布可以推导正态分布。中心极限定理是说当样本足够大时,样本均值的分布逐渐变化成正态分布.中心极限定理后续章节还会细说。
泊松分布公式:
p
(
X
=
k
∣
λ
)
=
λ
k
e
x
p
(
−
λ
)
k
!
p(X=k|\lambda)=\frac{\lambda^kexp(-\lambda)}{k!}
p(X=k∣λ)=k!λkexp(−λ)
令k= λ ( 1 + δ ) \lambda(1+\delta) λ(1+δ), δ \delta δ<<1, ( 1 + δ ) (1+\delta) (1+δ)意味着单位时间。当 λ \lambda λ→ ∞ ∞ ∞, k → ∞ k→∞ k→∞,泊松分布的随机变量逐渐变成连续的。
利用斯特林公式(Stirling’s formula)
k
!
→
2
π
k
e
−
k
k
−
k
k!→\sqrt{2\pi k} e^{-k}k^{-k}
k!→2πke−kk−k, 当
k
→
∞
k→∞
k→∞
那么
p
(
X
=
k
∣
λ
)
=
λ
k
e
x
p
(
−
λ
)
k
!
=
λ
λ
(
1
+
δ
)
e
−
λ
2
π
e
−
λ
(
1
+
δ
)
[
λ
(
1
+
δ
)
]
λ
(
1
+
δ
)
+
1
2
=
e
−
λ
δ
2
2
2
π
λ
p(X=k|\lambda)=\frac{\lambda^kexp(-\lambda)}{k!}=\frac{\lambda^{\lambda(1+\delta)}e^{-\lambda}}{\sqrt{2\pi}e^{-\lambda(1+\delta)}[\lambda(1+\delta)]^{\lambda(1+\delta)+\frac{1}{2}}}=\frac{e^\frac{-\lambda \delta^2}{2}}{\sqrt{2\pi \lambda}}
p(X=k∣λ)=k!λkexp(−λ)=2πe−λ(1+δ)[λ(1+δ)]λ(1+δ)+21λλ(1+δ)e−λ=2πλe2−λδ2
再将
δ
\delta
δ=(k-
λ
\lambda
λ)/
λ
\lambda
λ,带入,得
=
e
−
(
k
−
λ
)
2
2
λ
2
π
λ
=\frac{e^{\frac{-(k-\lambda)^2}{2\lambda}}}{\sqrt{2\pi \lambda}}
=2πλe2λ−(k−λ)2
令
λ
=
σ
2
=
μ
\lambda=\sigma^2=\mu
λ=σ2=μ, k=x ,(中心极限定理,
λ
\lambda
λ很大时,
P
o
i
(
λ
)
≈
N
(
μ
=
λ
,
σ
2
=
λ
)
Poi(\lambda)≈N(\mu=\lambda,\sigma^2=\lambda)
Poi(λ)≈N(μ=λ,σ2=λ))
则为
p
(
x
∣
μ
,
σ
2
)
=
(
1
2
π
σ
2
)
1
2
e
x
p
(
−
(
x
−
μ
)
2
2
σ
2
)
p(x|\mu,\sigma^2)=(\frac{1}{2\pi\sigma^2})^{\frac{1}{2}}exp({-\frac{(x-\mu)^2}{2\sigma^2}})
p(x∣μ,σ2)=(2πσ21)21exp(−2σ2(x−μ)2) 正态分布。
最后,这里有张分布的关系图(转载https://www.zhihu.com/question/21756860),大家可以清晰的看到各个分布的关系

在数据分析模型这课里面暂且不涉及过多分布,至于像伽马分布,柯西分布,半柯西分布等均为贝叶斯统计先验里需要用上的,这些内容在后续更新高等数据分析博客会提到。另外小弟专业是数据科学,研究生是机器学习和计算机视觉,对数学方面虽有涉及但不够深入,也希望大家多多点出小弟的不足或有谬误的地方,在此感谢了。
三. 结语
小弟我毕竟不是数学专业,有公式推导错误的或理论有谬误的,请大家指出,我好及时更正。
自习的同学可以参考Ross, S.M. (2014) Introduction to Probability and Statistics for Engineers and Scientists, 5th ed. Academic Press. 第4章-5章
最后,如果有同学对矩生成函数感兴趣的可以参考这个网站,这个大哥写的矩生成函数很详细也很清晰https://www.cnblogs.com/vamei/p/3418589.html 小弟毕竟不是数学专业,小弟我也希望多向大家学习学习,但为了叫大家清楚所以细节,我尽量多写点,以供大家参考.
这里用一个矩生成函数来证明下泊松分布的期望和方差
ϕ
(
t
)
=
E
[
e
t
x
]
=
∑
i
=
0
∞
e
t
i
e
−
λ
λ
i
i
!
=
e
−
λ
∑
i
=
0
∞
(
λ
e
t
)
i
i
!
=
e
−
λ
e
λ
e
t
\phi(t)=E[e^{tx}]=\sum_{i=0}^{∞} \frac{e^{ti}e^{-\lambda} \lambda^{i}}{i!}=e^{-\lambda}\sum_{i=0}^{∞} \frac{(\lambda e^t)^i}{i!}=e^{-\lambda} e^{\lambda e^t}
ϕ(t)=E[etx]=∑i=0∞i!etie−λλi=e−λ∑i=0∞i!(λet)i=e−λeλet
ϕ
′
(
t
)
=
λ
e
t
e
λ
(
e
t
−
1
)
\phi^{'}(t)=\lambda e^{t} e^{\lambda (e^t-1)}
ϕ′(t)=λeteλ(et−1)
ϕ
′
′
(
t
)
=
(
λ
e
t
)
2
e
λ
(
e
t
−
1
)
+
λ
e
t
e
λ
(
e
t
−
1
)
\phi^{''}(t)=(\lambda e^{t})^2 e^{\lambda(e^t-1)}+\lambda e^t e^{\lambda(e^t-1)}
ϕ′′(t)=(λet)2eλ(et−1)+λeteλ(et−1)
那么
E[X]=
ϕ
′
(
0
)
=
λ
\phi^{'}(0)=\lambda
ϕ′(0)=λ
V[X]=
ϕ
′
′
(
0
)
−
(
E
[
X
]
2
)
=
λ
2
+
λ
−
λ
2
=
λ
\phi^{''}(0)-(E[X]^2)=\lambda^2+\lambda-\lambda^2=\lambda
ϕ′′(0)−(E[X]2)=λ2+λ−λ2=λ

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 6
6 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)