数据分析模型 第七章
分类,逻辑回归,结语一. 分类(classifier)二. 二元逻辑回归(binary logistic regression)一. 分类(classifier)当我们预测的变量YYY为分类数据的时候,如果我们使用的是线性回归,我们可以把分类数据的变量变化成指标变量(数据分析模型,第6章)。在这一章我们要讨论的是另外一种模型,即分类模型,利用概率从而进行分类。想象一下,如果我们的变量是城市,我们将
一. 分类(classifier)
当我们预测的变量 Y Y Y为分类数据的时候,如果我们使用的是线性回归,我们可以把分类数据的变量变化成指标变量(数据分析模型,第6章)。
在这一章我们要讨论的是另外一种模型,即分类模型,利用概率从而进行分类。想象一下,如果我们的变量是城市,我们将它数据化变为1,2,3,4,分别对应各个不同的4个城市,用这些数字来计算和预测很明显是没有道理的。如果我们利用线性回归模型,我们将它变为指标变量。如果利用分类模型,我们会计算对应出现的频率,从而得到它会发生的概率。
如果我们有p个变量(也可以叫特征,feature)即
X
1
,
X
2
,
.
.
.
,
X
p
X_1,X_2,...,X_p
X1,X2,...,Xp,我们便可以为变量
Y
Y
Y进行分类,利用概率,即条件概率:
P
{
Y
=
y
∣
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
P\{Y=y|X_1=x_1,X_2=x_2,...,X_p=x_p\}
P{Y=y∣X1=x1,X2=x2,...,Xp=xp}
当然了,我们的变量
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
X_1=x_1,X_2=x_2,...,X_p=x_p
X1=x1,X2=x2,...,Xp=xp也可以为分类变量。那么上述公式可以转化为:
P
{
Y
=
y
∣
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
=
P
{
Y
=
y
,
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
P
{
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
P\{Y=y|X_1=x_1,X_2=x_2,...,X_p=x_p\}=\frac{P\{Y=y,X_1=x_1,X_2=x_2,...,X_p=x_p\}}{P\{X_1=x_1,X_2=x_2,...,X_p=x_p\}}
P{Y=y∣X1=x1,X2=x2,...,Xp=xp}=P{X1=x1,X2=x2,...,Xp=xp}P{Y=y,X1=x1,X2=x2,...,Xp=xp}
其中,
P
{
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
=
∑
y
P
{
Y
=
y
,
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
P\{X_1=x_1,X_2=x_2,...,X_p=x_p\}=\sum_{y}P\{Y=y,X_1=x_1,X_2=x_2,...,X_p=x_p\}
P{X1=x1,X2=x2,...,Xp=xp}=∑yP{Y=y,X1=x1,X2=x2,...,Xp=xp}即为
X
1
,
X
2
,
.
.
.
,
X
p
X_1,X_2,...,X_p
X1,X2,...,Xp的边缘概率。
P
{
Y
=
y
,
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
P\{Y=y,X_1=x_1,X_2=x_2,...,X_p=x_p\}
P{Y=y,X1=x1,X2=x2,...,Xp=xp}为
Y
,
X
1
,
X
2
,
.
.
.
,
X
p
Y,X_1,X_2,...,X_p
Y,X1,X2,...,Xp的联合概率。
举个例子:
| 无心脏病(H=0) | 心脏病(H=1) | |
|---|---|---|
| 无突变(M=0) | 0.35 | 0.30 |
| 有突变(M=1) | 0.10 | 0.25 |
那么:
P
(
H
=
1
∣
M
=
0
)
=
P
(
H
=
1
,
M
=
0
)
P
(
M
=
1
)
=
0.4615
P(H=1|M=0)=\frac{P(H=1,M=0)}{P(M=1)}=0.4615
P(H=1∣M=0)=P(M=1)P(H=1,M=0)=0.4615
P
(
H
=
1
∣
M
=
1
)
=
P
(
H
=
1
,
M
=
1
)
P
(
M
=
1
)
=
0.7143
P(H=1|M=1)=\frac{P(H=1,M=1)}{P(M=1)}=0.7143
P(H=1∣M=1)=P(M=1)P(H=1,M=1)=0.7143
我们可以清晰的看出,有突变的情况下更容易得心脏病。
接着上述例题讲,在现实中很明显,我们肯定没有那么容易获得上述例子的数据,要得到上述例子的数据需要大量的数据作为总体,然后计算无心脏病无突变的频率,等等。
那么问题来了,如果我们知道联合概率,那么边缘概率很容易计算即在同类情况下把各联合概率相加即可,那么重点是我们该如何利用样本数据估计总体的联合概率。
利用这个公式来计算联合概率:
P
(
H
=
h
,
M
=
m
)
=
1
n
∑
i
=
1
n
I
(
h
i
=
h
&
m
i
=
m
)
P(H=h,M=m)=\frac{1}{n}\sum_{i=1}^{n}I(h_i=h \& m_i=m)
P(H=h,M=m)=n1i=1∑nI(hi=h&mi=m)
对没错,这就是在算频率然后算概率。什么意思?如果我们得到的样本为
m
=
(
1
,
1
,
0
,
1
,
1
,
1
,
0
,
0
)
m=(1,1,0,1,1,1,0,0)
m=(1,1,0,1,1,1,0,0),
h
=
(
1
,
0
,
1
,
1
,
0
,
0
,
1
,
0
)
h=(1,0,1,1,0,0,1,0)
h=(1,0,1,1,0,0,1,0),我们的
I
(
⋅
)
I(·)
I(⋅)则为指标方程,举个例子,那么我们可以计算
P
(
H
=
0
,
M
=
0
)
=
1
8
P(H=0,M=0)=\frac{1}{8}
P(H=0,M=0)=81了,根据样本计算出的概率,我们也称为经验概率,那么根据样本计算的联合概率,我们称它为经验联合概率(empirical joint probabilities).那么便得到了我们利用样本计算的概率,即下表格:
| 无心脏病(H=0) | 心脏病(H=1) | |
|---|---|---|
| 无突变(M=0) | 1/8 | 2/8 |
| 有突变(M=1) | 3/8 | 2/8 |
那么我们再来算算:
P
ˉ
(
H
=
1
∣
M
=
0
)
=
P
ˉ
(
H
=
1
,
M
=
0
)
P
ˉ
(
M
=
1
)
=
1
/
8
1
/
8
+
2
/
8
=
0.66
\bar P(H=1|M=0)=\frac{\bar P(H=1,M=0)}{\bar P(M=1)}=\frac{1/8}{1/8+2/8}=0.66
Pˉ(H=1∣M=0)=Pˉ(M=1)Pˉ(H=1,M=0)=1/8+2/81/8=0.66
P
ˉ
(
H
=
1
∣
M
=
1
)
=
P
ˉ
(
H
=
1
,
M
=
1
)
P
ˉ
(
M
=
1
)
=
0.2
\bar P(H=1|M=1)=\frac{\bar P(H=1,M=1)}{\bar P(M=1)}=0.2
Pˉ(H=1∣M=1)=Pˉ(M=1)Pˉ(H=1,M=1)=0.2
我们利用样本发现,无突变获得心脏病的概率更大。是不是跟我们总体数据得到的结论不对,根据我们常识也知道细胞病变肯定不好的,那获得心脏病自然也是高概率的。对没错,我们的数据样本太少了,才8个。根据弱大数理论,我们知道当样本数量
n
→
∞
n→∞
n→∞时,那必然会收敛于我们总体数据分析出的结果。
但现在又有个问题,因为我们的H,M都是二元变量即0或者1,那也就是说会有2x2=4个组合。那如果再来个二元变量呢?我们会有2x2x2=8个组合,那如果有p个二元变量,则有 2 p 2^p 2p个组合。在数据分析模型的课程中不涉及多元分类变量,小弟会在高等数据分析的课程中会仔细分享该内容。但我们也会算,如果H,M为三元分类变量,那么为3x3=9种组合,如果H为三元分类,M为二元分类,那么有3x2=6种组合。
于是我们会发现,如果有p个二元变量,则有 2 p 2^p 2p个组合,也就是说我们要算 2 p 2^p 2p个不同的联合分布,再加上庞大的数据量,这计算起来是要话很长时间。学过自动机和C语言的同学们应该深有体会,这么大数据量,不单单是计算时间复杂度很大,最重要的是线程的读取,转换,存栈的时间过长。所以买个固态硬盘和好点的CPU吧,别花钱买什么1080ti高级显卡了。
这当然是句玩笑话,回归正题,一般我们会直接计算它的条件概率,即:
P
{
Y
=
y
∣
X
1
=
x
1
,
X
2
=
x
2
,
.
.
.
,
X
p
=
x
p
}
=
f
(
x
1
,
.
.
.
,
x
p
)
P\{Y=y|X_1=x_1,X_2=x_2,...,X_p=x_p\}=f(x_1,...,x_p)
P{Y=y∣X1=x1,X2=x2,...,Xp=xp}=f(x1,...,xp)
这里的
f
(
⋅
)
f(·)
f(⋅)是某个计算方程,用来直接计算基于
x
1
,
.
.
.
,
x
p
x_1,...,x_p
x1,...,xp得出y的概率。这种方法很常用,不算联合概率,而直接根据事情要求计算条件概率。例如,在贝叶斯估计中我们也会采用这个方法。
二. 二元逻辑回归(binary logistic regression)
还记得第6章,讲述关于线性回归的分类问题么,把分类数据的变量变化成指标变量。那么其中我们的
Y
∈
{
0
,
1
}
Y∈\{0,1\}
Y∈{0,1},我们的线性回归为:
E
[
Y
i
]
=
β
0
+
∑
j
=
i
p
β
j
x
i
,
j
≡
η
i
E[Y_i]=\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j}≡\eta_i
E[Yi]=β0+j=i∑pβjxi,j≡ηi
我们可以简单粗暴的讲线性回归模型转换为分类模型,即:
P
(
Y
i
=
1
∣
x
i
,
1
,
.
.
.
,
x
i
,
p
)
=
η
i
P(Y_i=1|x_{i,1},...,x_{i,p})=\eta_i
P(Yi=1∣xi,1,...,xi,p)=ηi
然后利用最小二乘法估计出
β
\beta
β们,使我们的
η
i
\eta_i
ηi在0到1区间内(作为概率)。但这种方法,也很容易计算出
η
i
<
0
\eta_i<0
ηi<0或者
η
i
>
0
\eta_i>0
ηi>0这就使我们很苦恼。
解决这个问题,统计里有很多种方法,但令我们最熟知的还是逻辑方程(logistic function).
对数几率(Log-odds)
我们定义一个成功和失败的几率即为:
O
=
P
(
Y
=
1
)
P
(
Y
=
0
)
O=\frac{P(Y=1)}{P(Y=0)}
O=P(Y=0)P(Y=1)
假如我们的成功率为
θ
=
0.75
\theta=0.75
θ=0.75,那么失败率为0.25,那么
O
=
0.75
0.25
=
3
O=\frac{0.75}{0.25}=3
O=0.250.75=3它意味着成功概率比失败概率多三倍。当然了这里的成功是我们定义的,例如硬币正面认为是成功。我们也可以把反面认为是成功,那么为
0.25
0.75
=
1
/
3
\frac{0.25}{0.75}=1/3
0.750.25=1/3,那就是成功比失败多1/3倍,是不是有点拗口,其实就是少三倍. 但我们一般会加上log即
l
o
g
O
logO
logO,为什么?我们来看下,如果加上log,那么我们会有
l
o
g
3
log3
log3和
−
l
o
g
3
-log3
−log3,这样看相比没有加log的时候
3
3
3和
1
3
\frac{1}{3}
31,更自然一些,也就是数值相同,符号相反,也就是数值以0互相对称,这样的好处在于我们可以任意武断的决定谁是成功谁是失败。还有个好处就是在于加完log,我们的对数几率的范围在
(
−
∞
,
+
∞
)
(-∞,+∞)
(−∞,+∞),范围更广了,否则单纯的几率(odds)其范围仅仅
(
0
,
+
∞
)
(0,+∞)
(0,+∞)
那么现在我们成功的解决了
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
=
η
i
∈
(
0
,
1
)
P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})=\eta_i∈(0,1)
P(Yi=1∣xi,1,xi,2,..,xi,p)=ηi∈(0,1)这个问题,因为我们可以写成:
l
o
g
(
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
P
(
Y
i
=
0
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
)
=
β
0
+
∑
j
=
i
p
β
j
x
i
,
j
≡
η
i
log(\frac{P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})}{P(Y_i=0|x_{i,1},x_{i,2},..,x_{i,p})})=\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j}≡\eta_i
log(P(Yi=0∣xi,1,xi,2,..,xi,p)P(Yi=1∣xi,1,xi,2,..,xi,p))=β0+j=i∑pβjxi,j≡ηi这样我们得到的
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
∈
(
0
,
1
)
P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})∈(0,1)
P(Yi=1∣xi,1,xi,2,..,xi,p)∈(0,1)
二元逻辑回归
二元逻辑回归是由条件对数几率而来的,根据上面所述公式,即
l
o
g
(
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
P
(
Y
i
=
0
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
)
=
β
0
+
∑
j
=
i
p
β
j
x
i
,
j
≡
η
i
log(\frac{P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})}{P(Y_i=0|x_{i,1},x_{i,2},..,x_{i,p})})=\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j}≡\eta_i
log(P(Yi=0∣xi,1,xi,2,..,xi,p)P(Yi=1∣xi,1,xi,2,..,xi,p))=β0+j=i∑pβjxi,j≡ηi
那么我化简该公式:
l
o
g
(
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
1
−
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
)
=
β
0
+
∑
j
=
i
p
β
j
x
i
,
j
≡
η
i
log(\frac{P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})}{1-P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})})=\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j}≡\eta_i
log(1−P(Yi=1∣xi,1,xi,2,..,xi,p)P(Yi=1∣xi,1,xi,2,..,xi,p))=β0+j=i∑pβjxi,j≡ηi
得:
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
=
1
1
+
e
−
η
i
P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})=\frac{1}{1+e^{-\eta_i}}
P(Yi=1∣xi,1,xi,2,..,xi,p)=1+e−ηi1
即我们得逻辑回归。
但我们一般会写为:
g
(
x
)
=
1
1
+
e
−
x
g(x)=\frac{1}{1+e^{-x}}
g(x)=1+e−x1
这个被称为逻辑方程(logistic function).
看到这里,想必同学们会问:“是否我们可以利用线性回归来寻找某个函数的关系,像 l o g ( P ( Y i = 1 ∣ x i , 1 , x i , 2 , . . , x i , p ) 1 − P ( Y i = 1 ∣ x i , 1 , x i , 2 , . . , x i , p ) ) = β 0 + ∑ j = i p β j x i , j ≡ η i log(\frac{P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})}{1-P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})})=\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j}≡\eta_i log(1−P(Yi=1∣xi,1,xi,2,..,xi,p)P(Yi=1∣xi,1,xi,2,..,xi,p))=β0+∑j=ipβjxi,j≡ηi一样,从而得到某个新的回归方程或者新的表达式。” 对没错, η i \eta_i ηi其实就是广义的线性模型,而 l o g ( P ( Y i = 1 ∣ x i , 1 , x i , 2 , . . , x i , p ) 1 − P ( Y i = 1 ∣ x i , 1 , x i , 2 , . . , x i , p ) ) log(\frac{P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})}{1-P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})}) log(1−P(Yi=1∣xi,1,xi,2,..,xi,p)P(Yi=1∣xi,1,xi,2,..,xi,p))作为某个函数的关系,我们称为连接方程(link function). 举个例子:对于泊松分布,我们可以找到一个连接方程即 l o g ( λ i ) = β 0 + ∑ j = i p β j x i , j ≡ η i log(\lambda_i)=\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j}≡\eta_i log(λi)=β0+∑j=ipβjxi,j≡ηi. 它们的本质就是利用线性回归来代替充当参数,使我们的模型更加灵活,更可以诠释我们的数据。其实关于改内容的讨论已经超出了数据分析模型这门课的知识范围,等小弟更新到高等数据时还会重提并深入讨论。
言归正传,我们的逻辑回归为:
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
=
1
1
+
e
−
η
i
P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})=\frac{1}{1+e^{-\eta_i}}
P(Yi=1∣xi,1,xi,2,..,xi,p)=1+e−ηi1
图像为:
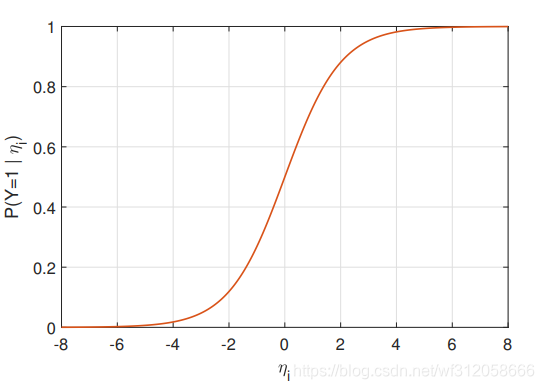
当
η
i
→
−
∞
\eta_i→-∞
ηi→−∞,
P
(
Y
i
=
1
∣
x
i
,
1
,
x
i
,
2
,
.
.
,
x
i
,
p
)
→
0
P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})→0
P(Yi=1∣xi,1,xi,2,..,xi,p)→0。
当 η i → + ∞ \eta_i→+∞ ηi→+∞, P ( Y i = 1 ∣ x i , 1 , x i , 2 , . . , x i , p ) → 1 P(Y_i=1|x_{i,1},x_{i,2},..,x_{i,p})→1 P(Yi=1∣xi,1,xi,2,..,xi,p)→1
我们可以清楚看到,当 η i \eta_i ηi增大,那么 Y = 1 Y=1 Y=1的概率会提升。
估计逻辑回归(estimating logistic regressions)
估计逻辑回归,我们要利用伯努利分布,即:
Y
i
~
B
e
(
θ
i
(
β
0
,
β
)
)
Y_i~Be(\theta_i(\beta_0,\beta))
Yi~Be(θi(β0,β))
首先,这里的
β
=
(
β
1
,
.
.
.
,
β
p
)
\beta=(\beta_1,...,\beta_p)
β=(β1,...,βp).其次,每个
Y
i
Y_i
Yi都会有自己的成功率
θ
i
\theta_i
θi基于变量
x
1
,
.
.
.
.
,
x
p
x_1,....,x_p
x1,....,xp
θ
i
(
β
0
,
β
)
=
1
1
+
e
−
η
i
=
1
1
+
e
−
(
β
0
+
∑
j
=
i
p
β
j
x
i
,
j
)
\theta_i(\beta_0,\beta)=\frac{1}{1+e^{-\eta_i}}=\frac{1}{1+e^{-(\beta_0+\sum_{j=i}^{p}\beta_{j} x_{i,j})}}
θi(β0,β)=1+e−ηi1=1+e−(β0+∑j=ipβjxi,j)1
那么我们还是用负log似然估计来做:
p
(
y
∣
β
0
,
β
)
=
Π
i
=
1
n
p
(
y
i
∣
β
0
,
β
)
=
Π
i
=
1
n
θ
i
(
β
0
,
β
)
i
y
(
1
−
θ
i
(
β
0
,
β
)
)
1
−
y
i
p(y|\beta_0,\beta)=\Pi_{i=1}^{n}p(y_i|\beta_0,\beta)=\Pi_{i=1}^{n}\theta_i(\beta_0,\beta)^y_{i}(1-\theta_i(\beta_0,\beta))^{1-y_i}
p(y∣β0,β)=Πi=1np(yi∣β0,β)=Πi=1nθi(β0,β)iy(1−θi(β0,β))1−yi
那么:
L
(
y
∣
β
0
,
β
)
=
−
∑
i
=
1
n
[
y
i
l
o
g
θ
i
(
β
0
,
β
)
+
(
1
−
y
i
)
l
o
g
(
1
−
θ
i
(
β
0
,
β
)
)
]
=
∑
i
=
1
n
[
−
y
i
η
i
+
l
o
g
(
1
+
e
η
i
)
]
L(y|\beta_0,\beta)=-\sum_{i=1}^{n}[y_ilog\theta_i(\beta_0,\beta)+(1-y_i)log(1-\theta_i(\beta_0,\beta))]=\sum_{i=1}^{n}[-y_i\eta_i+log(1+e^{\eta_i})]
L(y∣β0,β)=−i=1∑n[yilogθi(β0,β)+(1−yi)log(1−θi(β0,β))]=i=1∑n[−yiηi+log(1+eηi)]
接下来,就是我们的分别求偏导=0的时间了,斜率为0,这里就不在赘述了. 时间复杂度为
O
(
p
3
)
O(p^3)
O(p3),p为估计参数的数量,3为维度。至于为什么是
O
(
p
3
)
O(p^3)
O(p3),这个的由来很复杂,涉及了深度学习的梯度下降,这里就不说了,感兴趣的同学可以查查。
拟合优度(goodness of fit)
很明显,逻辑回归没有像线性回归那样有
R
2
R^2
R2来看是否模型更拟合数据。
我们一般会用这个公式来判断是否我们的逻辑回归拟合我们的数据:
L
(
y
∣
β
ˉ
0
)
−
L
(
y
∣
β
0
,
β
ˉ
)
L(y|\bar\beta_0)-L(y|\beta_0,\bar\beta)
L(y∣βˉ0)−L(y∣β0,βˉ)
差值越大,拟合度越好。这个也很容易理,假设该模型没有任何变量,那么很明显拟合度很差,
L
(
y
∣
β
ˉ
0
)
L(y|\bar\beta_0)
L(y∣βˉ0)数值很大,那么我们则以它为标准,如果该模型有足够的变量那么
L
(
y
∣
β
0
,
β
ˉ
)
L(y|\beta_0,\bar\beta)
L(y∣β0,βˉ)会足够的小,那么说明我们的模型拟合度好。之所以用
L
(
y
∣
β
ˉ
0
)
L(y|\bar\beta_0)
L(y∣βˉ0)减去
L
(
y
∣
β
0
,
β
ˉ
)
L(y|\beta_0,\bar\beta)
L(y∣β0,βˉ),因为我们需要用
L
(
y
∣
β
ˉ
0
)
L(y|\bar\beta_0)
L(y∣βˉ0)作为标准来衡量我们的
L
(
y
∣
β
0
,
β
ˉ
)
L(y|\beta_0,\bar\beta)
L(y∣β0,βˉ)到底有多小。
模型的选择(model selection)
还是老问题,如果我们要用逻辑回归模型,那么哪些变量很重要需要加到模型中,哪些变量不重要可以不加到模型中呢?
方法1:
利用
H
0
:
β
j
=
0
H_0: \beta_j=0
H0:βj=0 VS
H
1
:
β
j
≠
0
H_1: \beta_j≠0
H1:βj=0
如果p值足够小那么否定原假设。详可参考第6章简单线性模型和分布的汇总。
方法2:
利用信息准则与正向选择逻辑或者反向选择逻辑,详参考第6章模型的选择
L
(
y
∣
β
ˉ
0
,
β
ˉ
)
+
k
α
n
L(y|\bar\beta_0,\bar\beta)+k\alpha_n
L(y∣βˉ0,βˉ)+kαn
k:多少个变量
α
n
=
1
\alpha_n=1
αn=1 赤池信息准则(AIC)
α
n
=
3
/
2
\alpha_n=3/2
αn=3/2库尔贝科信息准则(KIC)
α
n
=
1
2
l
o
g
n
\alpha_n=\frac{1}{2}logn
αn=21logn贝叶斯信息准则(BIC)
二元逻辑回归其实是线性(logistic regressions are linear)
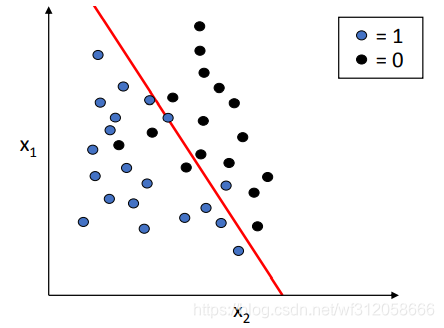
从上图
P
(
Y
=
1
∣
x
1
,
x
2
)
=
1
/
2
P(Y=1|x_1,x_2)=1/2
P(Y=1∣x1,x2)=1/2可看出其实我们的线性回归为线性,分类成成功(1)与失败(0),如果有p个变量,那么为p维度的平面二元分类。
分类器的表现(performance for classifier)
如何评判分类的表现情况,最直接的方法就是真值和预测值比一下嘛。这种评测方法被称为分类精度(classification accuracy)我们简称它为CA
C
A
=
1
n
′
∑
i
=
1
n
′
I
(
y
i
=
y
ˉ
i
)
CA=\frac{1}{n'}\sum_{i=1}^{n'}I(y_i=\bar y_i)
CA=n′1i=1∑n′I(yi=yˉi)
n
′
n'
n′为我们抽取的数据量。
I
(
⋅
)
I(·)
I(⋅)为如果相同为1,否则为0
如果CA=0,那我们模型分类很差。
如果CA=1,那么我们模型分类很好
如果CA=1/2,那么我们分类模型的准确度跟抛硬币差不多。
但通常我们都习惯用混淆矩阵(confusion matrix)
| y i = 0 y_i=0 yi=0 | y i = 1 y_i=1 yi=1 | |
|---|---|---|
| y ˉ i = 0 \bar y_i=0 yˉi=0 | True Negative(TN) | False Negative (FN) |
| y ˉ i = 1 \bar y_i=1 yˉi=1 | False Positive(FP) | True Positive(TP) |
那么:
C
A
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
CA=\frac{TP+TN}{TP+TN+FP+FN}
CA=TP+TN+FP+FNTP+TN
在数据分析模型这门课里只简单解释sensitivity和specificity 以及AUC。更多关于混淆矩阵的应用和推导,将来小弟写深度学习课程分享时会提及。
Sensitivity:
在真值为1的情况下,预测的准确度为多少
T
P
R
=
T
P
T
P
+
F
N
TPR=\frac{TP}{TP+FN}
TPR=TP+FNTP
Specificity:
在真值为0的情况下,预测的准确度为多少
T
N
R
=
T
N
T
N
+
F
P
TNR=\frac{TN}{TN+FP}
TNR=TN+FPTN
我们可以为我们的分类器加一个阈值
T
T
T
如果
P
(
Y
i
=
1
∣
x
i
,
1
,
.
.
,
x
i
,
p
)
>
=
T
P(Y_i=1|x_{i,1},..,x_{i,p})>=T
P(Yi=1∣xi,1,..,xi,p)>=T我们认为
y
ˉ
i
=
1
\bar y_i=1
yˉi=1, 否则
y
ˉ
i
=
0
\bar y_i=0
yˉi=0
那么我们开始设置阈值
T
=
1
2
T=\frac{1}{2}
T=21,如果Sensitivity增加,我们减小T值,如果Specificity增加,我们增大T值。根据T值得浮动,这样我们得到了一系列不同得预测,我们把它画出来,得:

这张图被称为接收操作曲线(receiver operating curve)我们称它为ROC。 ROC下面的面积称为曲线下面积(area-under the curve)我们称它为AUC。AUC的值在0~1之间
如果AUC=0.5说明我们分类器的表现跟抛硬币差不多。如果AUC=1则分类器表现很好。
AUC=p意味着如果从我们的测试数据中随机取样
y
i
=
1
y_i=1
yi=1和
y
k
=
0
y_k=0
yk=0,那么
P
[
P
(
Y
i
=
1
∣
x
i
,
1
,
.
.
,
x
i
,
p
)
>
[
P
(
Y
k
=
1
∣
x
i
,
1
,
.
.
,
x
i
,
p
)
]
=
p
P[P(Y_i=1|x_{i,1},..,x_{i,p})>[P(Y_k=1|x_{i,1},..,x_{i,p})]=p
P[P(Yi=1∣xi,1,..,xi,p)>[P(Yk=1∣xi,1,..,xi,p)]=p
意味着,样本
i
i
i来自类为1的概率比样本
k
k
k来自类为0的概率更为可能。这句话有点拗口。我们举个例子
AUC=0.6,意味着60%的数据来自类为1的分类,为类1,比分类为类0,更有可能。你可以理解成60%数据都分类对了。
逻辑损失(logarithmic Loss)
在最后,我们还有另一种评测分类表现叫做逻辑损失。
L
(
y
i
)
=
{
−
l
o
g
P
(
Y
=
1
∣
x
i
,
1
,
.
.
.
,
x
i
,
p
)
,
y
i
=
1
−
l
o
g
P
(
Y
=
0
∣
x
i
,
1
,
.
.
.
,
x
i
,
p
)
,
y
i
=
0
L(y_i)= \begin{cases} -logP(Y=1|x_{i,1},...,x_{i,p}), & y_i=1\\ -logP(Y=0|x_{i,1},...,x_{i,p}) , & y_i=0 \\ \end{cases}
L(yi)={−logP(Y=1∣xi,1,...,xi,p),−logP(Y=0∣xi,1,...,xi,p),yi=1yi=0
这里的 y i y_i yi为测试数据,用我们的模型来分类。
L ( y ) = ∑ i = 1 n L ( y i ) L(y)=\sum_{i=1}^{n}L(y_i) L(y)=i=1∑nL(yi)
如果值很小,则说明我们的分类器预测很好。
三. 结语
有公式推导错误的或理论有谬误的,请大家指出,我好及时更正,感谢。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)