数据分析模型 第六章
线性回归,结语一. 线性回归(linear regression)二. 结语一. 线性回归(linear regression)线性回归是属于监督学习范畴内的。我们在此先简单的介绍下监督学习.监督学习(Supervised Learning):假如我们有n组数据,每组数据有对应的p+1p+1p+1个变量.我们现在要预测其中一个变量,利用剩余的p个变量.如下图:该图中,我们的n就是行,这里有20行,
线性回归,浅谈其他回归模型,结语
一. 线性回归(linear regression)
线性回归是属于监督学习范畴内的。我们在此先简单的介绍下监督学习.
监督学习(Supervised Learning):
假如我们有n组数据,每组数据有对应的
p
+
1
p+1
p+1个变量.我们现在要预测其中一个变量,利用剩余的p个变量.如下图:

该图中,我们的n就是行,这里有20行,即为20个人,所以n组数据为n个个体。每个个体都有自己对应的具体变量值:Pt(相当于ID), BP(血压),Age(年纪),Weight(体重), 等等.
假如我们的任务是预测BP血压这个变量,那么我们就要用剩下的变量即Age,Weight等等的数据来预测这个BP血压这个变量的具体数值。
如果我们要预测的这个变量是分类数据(categorical),那么我们预测方法为分类
:例如簇,判断是否为男生或女生.
如果我们要预测的这个变量是数值数据(numerical),那么我们要用回归(regression):
例如线性回归,预测房价.
正如小弟第一章所述,监督学习,相当于有一份标准答案,假如我们预测BP血压,我们利用我们预测的血压值和标准答案的血压值进行比对,从而估计出参数,使我们的预测值更准确。还记得第三章的MSE么,如果我们估计的参数偏差过小,那么我们的模型很有可能饱和估计,也就是说我们的模型这能预测我们给定的这堆数据(训练数据)里的BP,如果我们估计的参数偏差过大,那模型可能是非饱和估计,我们的模型连我们给定的这推数据(训练数据)里的BP都预测不了.
我们言归正传,来介绍下监督学习的写法:
假如我们的预测变量
y
i
y_i
yi和我们的变量
x
i
,
1
,
x
i
,
2
,
x
i
,
3
,
.
.
.
,
x
i
,
p
x_{i,1},x_{i,2},x_{i,3},...,x_{i,p}
xi,1,xi,2,xi,3,...,xi,p有关系,即i∈(1,n)
那么:
y
i
=
f
(
x
i
,
1
,
x
i
,
2
,
x
i
,
3
,
.
.
.
,
x
i
,
p
)
y_i=f(x_{i,1},x_{i,2},x_{i,3},...,x_{i,p})
yi=f(xi,1,xi,2,xi,3,...,xi,p)
我们这里的
f
(
⋅
)
f(·)
f(⋅)即为我们的预测
y
ˉ
i
\bar y_i
yˉi,显然我们的预测
y
ˉ
i
\bar y_i
yˉi肯定不会和真值
y
i
y_i
yi一模一样,所以在
f
(
⋅
)
f(·)
f(⋅)里会有一个
ε
i
\varepsilon_i
εi即为误差(error)。
简单线性回归(simple linear regression)
线性模型是属于监督学习,在这里我们认为
f
(
⋅
)
f(·)
f(⋅)为线性的,即为:
Y
=
β
0
+
β
1
x
1
+
.
.
.
.
+
β
p
x
p
+
ε
Y=\beta_0+\beta_1x_1+....+\beta_px_p+\varepsilon
Y=β0+β1x1+....+βpxp+ε
当然了根据上述,假如我们有n组数据,i∈(1,n),你也可以写成:
Y
i
=
β
0
+
β
1
x
i
,
1
+
.
.
.
.
+
β
p
x
i
,
p
+
ε
i
Y_i=\beta_0+\beta_1x_{i,1}+....+\beta_px_{i,p}+\varepsilon_i
Yi=β0+β1xi,1+....+βpxi,p+εi
当p=1时,为简单的线性回归(simple linear regression),当p>1时,为多元线性回归(multiple linear regression).这公式翻译过来的意思为,基于独立变量
x
1
,
.
.
,
x
p
x_1,..,x_p
x1,..,xp关于
Y
Y
Y的回归.
β
0
,
β
1
,
.
.
,
β
p
\beta_0,\beta_1,..,\beta_p
β0,β1,..,βp为回归系数(regression coefficients)
我们一般会假设
ε
\varepsilon
ε即随机误差(random error)的均值/期望为0,那么也可以写成:
E
[
Y
∣
x
]
=
Y
ˉ
=
β
0
+
β
1
x
1
+
.
.
.
.
+
β
p
x
p
E[Y|x]=\bar Y=\beta_0+\beta_1x_1+....+\beta_px_p
E[Y∣x]=Yˉ=β0+β1x1+....+βpxp
E
[
Y
∣
x
]
E[Y|x]
E[Y∣x]意味着,基于x,Y的期望,即我们的预测
当然你也可以写成这样:
E
[
Y
i
∣
x
i
,
1
,
.
.
x
i
,
p
]
=
y
ˉ
i
=
β
0
+
β
1
x
i
,
1
+
.
.
.
.
+
β
p
x
i
,
p
E[Y_i|x_{i,1},..x_{i,p}]=\bar y_i=\beta_0+\beta_1x_{i,1}+....+\beta_px_{i,p}
E[Yi∣xi,1,..xi,p]=yˉi=β0+β1xi,1+....+βpxi,p
线性模型是统计里很重要的模型,因为线性模型具有这么三个优点:
1.线性模型具有很高的解释性,例如
y
=
−
3
x
1
+
2
x
2
y=-3x_1+2x_2
y=−3x1+2x2,y为房价,x1为噪音音呗,x2为附近的商场数量,那么随着噪音的增大y房价会减少,但随着商场数量增多,房价还会提高.
2.线性模型很灵活,它甚至可以处理非线性的变量关系。例如我们可以把logx当成一个变量,而不是把x当成一个变量,这样可以把非线性转换为线性。
3.线性模型即使有大量的变量,计算机计算估计参数也会很快。这一点小弟深有体会,小弟当时做了一个卷积层神经网络来分类垃圾,参数很多,调参,估计参数,一上午就没了(计算机算了一上午)。而线性模型估计参数则会很快。
那么如何判断我们的模型预测是好是坏呢?我们通过预测误差(predication error).
e
i
=
y
ˉ
i
−
y
i
e_i=\bar y_i-y_i
ei=yˉi−yi
对没错,这里的
e
i
e_i
ei和我们上述的
ε
i
\varepsilon_i
εi是一个意思,只是写法不同罢了。这也称为残差(residual error).那么,如果有n组数据,那么对应的会有n组
y
i
y_i
yi,那么它的总共的残差平方和为:
R
S
S
=
∑
i
=
1
n
e
i
2
RSS=\sum_{i=1}^{n}e_i^2
RSS=i=1∑nei2
这也被称为残差平方和(residual sum-pf-squared errors)
残差平方和越小,那说明我们的模型越能诠释我们的数据,能诠释我们的Y与剩下
x
1
,
.
.
.
x
p
x_1,...x_p
x1,...xp变量的关系。至于为什么用平方和的形式,请看第三章估计的均方误差(mean squared error,简写MSE),大同小异。
对于简单的线性模型来说,那我们可以利用上述这个特点,来估计我们的回归系数即参数,即:
(
β
ˉ
0
,
β
ˉ
1
)
=
m
i
n
{
R
S
S
}
=
a
r
g
m
i
n
β
o
,
β
1
{
∑
i
=
1
n
(
y
i
−
β
0
−
β
1
x
i
)
2
}
(\bar \beta_0,\bar \beta_1)=min\{RSS\}=arg min_{\beta_o,\beta_1}\{\sum_{i=1}^{n}(y_i-\beta_0-\beta_1x_i)^2\}
(βˉ0,βˉ1)=min{RSS}=argminβo,β1{i=1∑n(yi−β0−β1xi)2}
这就是最小二乘法估计(LS estimates)
那么:
∂
R
S
S
(
β
0
,
β
1
)
∂
β
0
=
−
2
∑
i
=
1
n
(
y
i
−
β
0
−
β
1
x
i
)
=
0
\frac{\partial RSS(\beta_0,\beta_1)}{\partial \beta_0}=-2\sum_{i=1}^{n}(y_i-\beta_0-\beta_1x_i)=0
∂β0∂RSS(β0,β1)=−2i=1∑n(yi−β0−β1xi)=0
∂
R
S
S
(
β
0
,
β
1
)
∂
β
1
=
−
2
∑
i
=
1
n
x
i
(
y
i
−
β
0
−
β
1
x
i
)
=
0
\frac{\partial RSS(\beta_0,\beta_1)}{\partial \beta_1}=-2\sum_{i=1}^{n}x_i(y_i-\beta_0-\beta_1x_i)=0
∂β1∂RSS(β0,β1)=−2i=1∑nxi(yi−β0−β1xi)=0
得:
β
ˉ
0
=
(
∑
i
=
1
n
y
i
)
(
∑
i
=
1
n
x
i
2
)
−
(
∑
i
=
1
n
y
i
x
i
)
(
∑
i
=
1
n
x
i
)
n
∑
i
=
1
n
x
i
2
−
(
∑
i
=
1
n
x
i
)
2
\bar\beta_0=\frac{(\sum_{i=1}^{n}y_i)(\sum_{i=1}^nx^2_i)-(\sum_{i=1}^ny_ix_i)(\sum_{i=1}^nx_i)}{n\sum_{i=1}^{n}x_i^2-(\sum_{i=1}^nx_i)^2}
βˉ0=n∑i=1nxi2−(∑i=1nxi)2(∑i=1nyi)(∑i=1nxi2)−(∑i=1nyixi)(∑i=1nxi)
β
ˉ
1
=
(
∑
i
=
1
n
y
i
x
i
−
β
ˉ
0
∑
i
=
1
n
x
i
)
/
∑
i
=
1
n
x
i
2
\bar\beta_1=(\sum_{i=1}^ny_ix_i-\bar\beta_0\sum_{i=1}^{n}x_i)/{\sum_{i=1}^{n}x_i^2}
βˉ1=(i=1∑nyixi−βˉ0i=1∑nxi)/i=1∑nxi2
当然了,你也可以先算
β
ˉ
1
\bar \beta_1
βˉ1,后算
β
ˉ
0
\bar \beta_0
βˉ0,均一样,得:
β
ˉ
1
=
(
∑
i
=
1
n
x
i
Y
i
−
x
ˉ
∑
i
=
1
n
Y
i
)
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
\bar \beta_1=(\sum_{i=1}^{n}x_iY_i-\bar x\sum_{i=1}^{n}Y_i)/(\sum_{i=1}^{n}x^2_i-n\bar x^2)
βˉ1=(i=1∑nxiYi−xˉi=1∑nYi)/(i=1∑nxi2−nxˉ2)
β
ˉ
0
=
∑
i
=
1
n
Y
i
n
−
β
ˉ
1
x
ˉ
\bar \beta_0=\sum_{i=1}^{n}\frac{Y_i}{n}-\bar\beta_1\bar x
βˉ0=i=1∑nnYi−βˉ1xˉ
上述的
x
ˉ
\bar x
xˉ为均值。
那么我们的估计的简单线性回归为:
y
ˉ
i
=
β
ˉ
0
+
β
ˉ
1
x
i
\bar y_i=\bar \beta_0+\bar \beta_1x_i
yˉi=βˉ0+βˉ1xi
残差为:
e
i
=
y
i
−
y
ˉ
i
e_i=y_i-\bar y_i
ei=yi−yˉi
根据最小二乘法,拟合出来的简单线性回归有这么个特殊性质,即:
∑
i
=
1
n
e
i
=
0
,
c
o
r
r
(
x
,
e
)
=
0
\sum_{i=1}^{n}e_i=0,corr(x,e)=0
i=1∑nei=0,corr(x,e)=0
这里的
x
=
(
x
1
,
x
2
,
.
.
.
.
,
x
n
)
x=(x_1,x_2,....,x_n)
x=(x1,x2,....,xn),
e
=
(
e
1
,
e
2
,
.
.
.
,
e
n
)
e=(e_1,e_2,...,e_n)
e=(e1,e2,...,en),也就是说由最小二乘法拟合出来的该简单线性回归的残差均值/期望为0,并且残差与我们的变量x无关.
这部分的推导很简单,利用公式
∂
R
S
S
(
β
0
,
β
1
)
∂
β
0
\frac{\partial RSS(\beta_0,\beta_1)}{\partial \beta_0}
∂β0∂RSS(β0,β1)因为:
−
2
∑
i
=
1
n
(
y
i
−
β
0
−
β
1
x
i
)
=
−
2
∑
i
=
1
n
e
i
=
0
-2\sum_{i=1}^{n}(y_i-\beta_0-\beta_1x_i)=-2\sum_{i=1}^{n}e_i=0
−2i=1∑n(yi−β0−β1xi)=−2i=1∑nei=0
所以简单线性回归的残差均值/期望为0,其实多元线性回归也是残差均值/期望=0(小弟先在这提一下),小弟的意思就是想说这也就是为什么每次讨论线性回归的时候,我们总假设残差或者误差(
e
i
=
ε
i
e_i=\varepsilon_i
ei=εi这俩写法指的是一个意思就是误差)的均值为0。
还记得
c
o
v
(
X
,
Y
)
=
E
[
X
Y
]
−
E
[
X
]
E
[
Y
]
cov(X,Y)=E[XY]-E[X]E[Y]
cov(X,Y)=E[XY]−E[X]E[Y]么,同理
c
o
v
(
x
,
e
)
=
E
[
X
e
]
−
E
[
X
]
E
[
e
]
cov(x,e)=E[Xe]-E[X]E[e]
cov(x,e)=E[Xe]−E[X]E[e],因为E[e]=0,又因为
E
[
X
e
]
=
∑
i
=
1
n
x
i
e
i
n
E[Xe]=\frac{\sum_{i=1}^{n}x_ie_i}{n}
E[Xe]=n∑i=1nxiei,我们再利用公式
∂
R
S
S
(
β
0
,
β
1
)
∂
β
1
\frac{\partial RSS(\beta_0,\beta_1)}{\partial \beta_1}
∂β1∂RSS(β0,β1)知道
∑
i
=
1
n
x
i
e
i
=
0
\sum_{i=1}^{n}x_ie_i=0
∑i=1nxiei=0,所以
c
o
v
(
x
,
e
)
=
E
[
X
e
]
−
E
[
X
]
E
[
e
]
=
0
−
0
=
0
cov(x,e)=E[Xe]-E[X]E[e]=0-0=0
cov(x,e)=E[Xe]−E[X]E[e]=0−0=0,所以
c
o
r
r
(
x
,
e
)
=
0
corr(x,e)=0
corr(x,e)=0.
简单线性回归和正态分布(simple linear regression and normal distribution)
可能有的同学会问“我们明白残差均值/期望为0,因为
∑
e
i
n
=
0
\frac{\sum e_i}{n}=0
n∑ei=0,那么残差是否有方差呢?”对没错,我们其实本质一般会令我们的残差/误差
e
i
~
N
(
0
,
σ
2
)
e_i~N(0,\sigma^2)
ei~N(0,σ2),
σ
2
\sigma^2
σ2是未知的,那么我们的简单线性回归可以写成:
Y
i
~
N
(
β
0
+
β
1
x
i
,
σ
2
)
Y_i~N(\beta_0+\beta_1x_i,\sigma^2)
Yi~N(β0+β1xi,σ2)
这写法很巧妙!!!小弟上学时特别喜欢简单线性回归能写成这样,为什么。因为它将概率和简单线性回归相融合,并且这样的写法基本上不违反小弟上述所说所有简单线性回归的知识点。举个例子, E [ Y i ] = β 0 + β 1 x i E[Y_i]=\beta_0+\beta_1x_i E[Yi]=β0+β1xi它诠释了上述的 E [ Y i ∣ x i , 1 ] = Y ˉ i = β 0 + β 1 x i , 1 E[Y_i|x_{i,1}]=\bar Y_i=\beta_0+\beta_1x_{i,1} E[Yi∣xi,1]=Yˉi=β0+β1xi,1。因为我们的预测 Y ˉ i \bar Y_i Yˉi和真值 Y i Y_i Yi肯定会有误差 e i e_i ei,那么 Y i = Y ˉ i + e i Y_i=\bar Y_i+e_i Yi=Yˉi+ei, Y ˉ i ~ N ( β 0 + β 1 x i , σ u 2 < 0.00001 ) , e i ~ N ( 0 , σ 2 ) \bar Y_i~N(\beta_0+\beta_1x_i,\sigma_u^2<0.00001),e_i~N(0,\sigma^2) Yˉi~N(β0+β1xi,σu2<0.00001),ei~N(0,σ2)那么 Y i ~ N ( β ˉ 0 + β ˉ 1 x i , σ 2 = σ 2 + σ u 2 ) Y_i~N(\bar\beta_0+\bar\beta_1x_i,\sigma^2=\sigma^2+\sigma_u^2) Yi~N(βˉ0+βˉ1xi,σ2=σ2+σu2)。
Y ˉ i ~ N ( β 0 + β 1 x i , σ u 2 < 0.00001 ) \bar Y_i~N(\beta_0+\beta_1x_i,\sigma^2_u<0.00001) Yˉi~N(β0+β1xi,σu2<0.00001)的意思也很巧妙,为什么,我们都知道正态分布以均值对称往外加减多少个标准差, σ u 2 < 0.00001 \sigma^2_u<0.00001 σu2<0.00001意味着标准差极小,则该正态分布两边快速下降收敛,那么 Y ˉ i = β 0 + β 1 x i \bar Y_i=\beta_0+\beta_1x_i Yˉi=β0+β1xi的概率几乎100%,这不就是我们的预测么。
最小二乘法的无偏性
现在我们来利用上述的
Y
i
~
N
(
β
0
+
β
1
x
i
,
σ
2
)
Y_i~N(\beta_0+\beta_1x_i,\sigma^2)
Yi~N(β0+β1xi,σ2)写法的简单线性回归来证明我们最小二乘法的无偏性和计算对应
β
ˉ
0
,
β
ˉ
1
\bar\beta_0,\bar \beta_1
βˉ0,βˉ1的方差。还记得小弟写的第三章内容里的MSE,对,我们来计算估计参数的期望和方差从而得到它的MSE。
通过最小二乘得到的
β
ˉ
1
=
(
∑
i
=
1
n
x
i
Y
i
−
x
ˉ
∑
i
=
1
n
Y
i
)
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
\bar \beta_1=(\sum_{i=1}^{n}x_iY_i-\bar x\sum_{i=1}^{n}Y_i)/(\sum_{i=1}^{n}x^2_i-n\bar x^2)
βˉ1=(∑i=1nxiYi−xˉ∑i=1nYi)/(∑i=1nxi2−nxˉ2)
那么:
E
[
β
ˉ
1
]
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
E
[
Y
i
]
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
(
β
0
+
β
1
x
i
)
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
=
β
0
∑
(
x
i
−
x
ˉ
)
+
β
1
∑
x
i
(
x
i
−
x
ˉ
)
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
E[\bar \beta_1]=\sum_{i=1}^{n}(x_i-\bar x)E[Y_i]/(\sum_{i=1}^{n}x^2_i-n\bar x^2)=\sum_{i=1}^{n}(x_i-\bar x)(\beta_0+\beta_1x_i)/(\sum_{i=1}^{n}x^2_i-n\bar x^2)=\frac{\beta_0\sum(x_i-\bar x)+\beta_1\sum x_i(x_i-\bar x)}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}
E[βˉ1]=i=1∑n(xi−xˉ)E[Yi]/(i=1∑nxi2−nxˉ2)=i=1∑n(xi−xˉ)(β0+β1xi)/(i=1∑nxi2−nxˉ2)=(∑i=1nxi2−nxˉ2)β0∑(xi−xˉ)+β1∑xi(xi−xˉ)
因为
∑
(
x
i
−
x
ˉ
)
=
0
\sum(x_i-\bar x)=0
∑(xi−xˉ)=0,继续化简得:
E
[
β
ˉ
1
]
=
β
1
E[\bar \beta_1]=\beta_1
E[βˉ1]=β1
我们发现最小二乘法估计
β
1
\beta_1
β1是无偏估计.接下来我们计算它的方差:
V
a
r
(
β
ˉ
1
)
=
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
V
[
Y
i
]
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
2
=
σ
2
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
2
=
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
Var(\bar\beta_1)=\sum_{i=1}^{n}(x_i-\bar x)^2V[Y_i]/(\sum_{i=1}^{n}x^2_i-n\bar x^2)^2=\sigma^2 \sum_{i=1}^{n}(x_i-\bar x)^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)^2=\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)
Var(βˉ1)=i=1∑n(xi−xˉ)2V[Yi]/(i=1∑nxi2−nxˉ2)2=σ2i=1∑n(xi−xˉ)2/(i=1∑nxi2−nxˉ2)2=σ2/(i=1∑nxi2−nxˉ2)
那么:
M
S
E
β
1
(
β
ˉ
1
)
=
0
2
+
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
MSE_{\beta_1}(\bar \beta_1)=0^2+\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)
MSEβ1(βˉ1)=02+σ2/(i=1∑nxi2−nxˉ2)
现在同理计算
β
ˉ
0
\bar\beta_0
βˉ0的期望和方差,下述公式
x
ˉ
\bar x
xˉ为均值
E
[
β
ˉ
0
]
=
E
[
∑
i
=
1
n
Y
i
n
−
β
ˉ
1
x
ˉ
]
=
∑
i
=
1
n
E
[
Y
i
]
n
−
E
[
β
ˉ
1
]
x
ˉ
=
∑
i
=
1
n
β
0
+
β
1
x
i
n
−
β
1
x
ˉ
=
β
0
+
β
1
x
ˉ
−
β
1
x
ˉ
=
β
0
E[\bar\beta_0]=E[\sum_{i=1}^{n}\frac{Y_i}{n}-\bar\beta_1\bar x]=\sum_{i=1}^{n}\frac{E[Y_i]}{n}-E[\bar\beta_1]\bar x=\sum_{i=1}^{n}\frac{\beta_0+\beta_1x_i}{n}-\beta_1\bar x=\beta_0+\beta_1\bar x-\beta_1\bar x=\beta_0
E[βˉ0]=E[i=1∑nnYi−βˉ1xˉ]=i=1∑nnE[Yi]−E[βˉ1]xˉ=i=1∑nnβ0+β1xi−β1xˉ=β0+β1xˉ−β1xˉ=β0
我们发现最小二乘法估计
β
0
\beta_0
β0是无偏估计.接下来我们计算它的方差:
V
a
r
(
β
ˉ
0
)
=
σ
2
∑
i
=
1
n
x
i
2
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
Var(\bar\beta_0)=\frac{\sigma^2\sum_{i=1}^{n}x^2_i}{n(\sum_{i=1}^{n}x^2_i-n\bar x^2)}
Var(βˉ0)=n(∑i=1nxi2−nxˉ2)σ2∑i=1nxi2
那么:
M
S
E
β
0
(
β
ˉ
0
)
=
0
2
+
σ
2
∑
i
=
1
n
x
i
2
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
MSE_{\beta_0}(\bar \beta_0)=0^2+\frac{\sigma^2\sum_{i=1}^{n}x^2_i}{n(\sum_{i=1}^{n}x^2_i-n\bar x^2)}
MSEβ0(βˉ0)=02+n(∑i=1nxi2−nxˉ2)σ2∑i=1nxi2
那么我们用最小二乘法得到的
β
ˉ
0
,
β
ˉ
1
\bar \beta_0,\bar\beta_1
βˉ0,βˉ1也会服从正态分布,将上述的分别计算对应的期望和方差放入正态分布即可,得:
β
ˉ
1
~
N
(
β
1
,
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
)
\bar\beta_1~N(\beta_1,\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2))
βˉ1~N(β1,σ2/(i=1∑nxi2−nxˉ2))
β
ˉ
0
~
N
(
β
0
,
σ
2
∑
i
=
1
n
x
i
2
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
)
\bar\beta_0~N(\beta_0,\frac{\sigma^2\sum_{i=1}^{n}x^2_i}{n(\sum_{i=1}^{n}x^2_i-n\bar x^2)})
βˉ0~N(β0,n(∑i=1nxi2−nxˉ2)σ2∑i=1nxi2)
最小二乘法和似然估计
正如小弟在第三章末尾所说,最小二乘法跟似然估计很像,均是为了追求无偏性,而增加了方差。也就是说,在给定的数据里这样得到的拟合模型准确度是很高的,但在未知数据里即预测方面,因为方差很大所以它的预测变化很大,是我们对于预测没有很大信心。那么有的同学会问:“似然估计可以用在线性回归上么”,对没错,是可以的,在线性回归上,最小二乘法其实就是似然估计。
我们依然用:
残差/误差
e
i
~
N
(
0
,
σ
2
)
e_i~N(0,\sigma^2)
ei~N(0,σ2),
σ
2
\sigma^2
σ2是未知的
Y
i
~
N
(
β
0
+
β
1
x
i
,
σ
2
)
Y_i~N(\beta_0+\beta_1x_i,\sigma^2)
Yi~N(β0+β1xi,σ2)
那么我们计算似然得:
Π
i
=
1
n
1
2
π
σ
e
x
p
(
−
(
y
i
−
β
0
−
β
1
x
i
)
2
/
2
σ
2
)
=
1
(
2
π
)
n
2
σ
2
e
x
p
(
−
∑
i
=
1
n
(
y
i
−
β
0
−
β
1
x
i
)
2
/
2
σ
2
)
\Pi_{i=1}^{n}\frac{1}{\sqrt{2\pi}\sigma}exp(-(y_i-\beta_0-\beta_1x_i)^2/2\sigma^2)=\frac{1}{(2\pi)^{\frac{n}{2}}\sigma^2}exp(-\sum_{i=1}^{n}(y_i-\beta_0-\beta_1x_i)^2/2\sigma^2)
Πi=1n2πσ1exp(−(yi−β0−β1xi)2/2σ2)=(2π)2nσ21exp(−i=1∑n(yi−β0−β1xi)2/2σ2)
得:
L
(
y
∣
β
0
,
β
1
,
σ
2
)
=
n
2
l
o
g
(
2
π
σ
2
)
+
R
S
S
(
β
0
,
β
1
)
2
σ
2
L(y|\beta_0,\beta_1,\sigma^2)=\frac{n}{2}log(2\pi\sigma^2)+\frac{RSS(\beta_0,\beta_1)}{2\sigma^2}
L(y∣β0,β1,σ2)=2nlog(2πσ2)+2σ2RSS(β0,β1)
我们可以清楚得看到,要计算最大似然估计依然需要计算
m
i
n
{
∑
i
=
1
n
(
y
i
−
β
0
−
β
1
x
i
)
2
}
min\{\sum_{i=1}^{n}(y_i-\beta_0-\beta_1x_i)^2\}
min{∑i=1n(yi−β0−β1xi)2},这不就是最小二乘法么,所以说最小二乘法和似然估计在估计线性回归的系数方面上计算方法是一样的。
残差的方差估计
现在还剩下一个问题,当残差/误差
e
i
~
N
(
0
,
σ
2
)
e_i~N(0,\sigma^2)
ei~N(0,σ2),估计未知的
σ
2
\sigma^2
σ2,即我们现在来尝试着估计它.
因为我们知道:
R
S
S
=
∑
i
=
1
n
(
y
i
−
β
ˉ
0
−
β
ˉ
1
x
i
)
2
RSS=\sum_{i=1}^{n}(y_i-\bar\beta_0-\bar\beta_1x_i)^2
RSS=i=1∑n(yi−βˉ0−βˉ1xi)2
那么:
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22
可能大家会有疑问为什么
R
S
S
σ
2
\frac{RSS}{\sigma^2}
σ2RSS服从n-2个自由度的卡方.
首先卡方分布小弟就不带大家回顾了,大家可以上网查,或者看小弟第三章内容里卡方分布(chi-square)和第四章内容里置信区间和总体方差(CI & variance)有关卡方的应用.
证明
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22:
因为
Y
i
Y_i
Yi是正态随机变量,那么
Y
i
−
E
[
Y
i
]
V
[
Y
i
]
~
N
(
0
,
1
)
\frac{Y_i-E[Y_i]}{\sqrt{V[Y_i]}}~N(0,1)
V[Yi]Yi−E[Yi]~N(0,1)
为标准正态随机变量.
那么根据卡方分布定义,得:
∑
i
=
1
n
(
Y
i
−
E
[
Y
i
]
)
2
V
[
Y
i
]
=
∑
i
=
1
n
(
Y
i
−
β
0
−
β
1
x
i
)
2
σ
2
~
χ
n
2
\sum_{i=1}^{n}\frac{(Y_i-E[Y_i])^2}{V[Y_i]}=\sum_{i=1}^{n}\frac{(Y_i-\beta_0-\beta_1x_i)^2}{\sigma^2}~\chi_n^2
i=1∑nV[Yi](Yi−E[Yi])2=i=1∑nσ2(Yi−β0−β1xi)2~χn2
再根据我们上述知道的
β
ˉ
0
,
β
ˉ
1
\bar\beta_0,\bar\beta_1
βˉ0,βˉ1服从的正态分布,得
(
β
ˉ
1
−
β
1
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
/
σ
2
~
χ
1
2
(\bar\beta_1-\beta_1)^2(\sum_{i=1}^{n}x^2_i-n\bar x^2)/\sigma^2~\chi^2_1
(βˉ1−β1)2(i=1∑nxi2−nxˉ2)/σ2~χ12
(
β
ˉ
0
−
β
0
)
2
(
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
)
/
(
σ
2
∑
i
=
1
n
x
i
2
)
~
χ
1
2
(\bar\beta_0-\beta_0)^2(n(\sum_{i=1}^{n}x^2_i-n\bar x^2))/(\sigma^2\sum_{i=1}^{n}x^2_i)~\chi^2_1
(βˉ0−β0)2(n(i=1∑nxi2−nxˉ2))/(σ2i=1∑nxi2)~χ12
可得:
R
S
S
σ
2
=
∑
i
=
1
n
(
Y
i
−
β
0
−
β
1
x
i
)
2
σ
2
−
(
β
ˉ
1
−
β
1
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
/
σ
2
−
(
β
ˉ
0
−
β
0
)
2
(
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
)
/
(
σ
2
∑
i
=
1
n
x
i
2
)
~
χ
n
2
−
χ
1
2
−
χ
1
2
=
χ
n
−
2
2
\frac{RSS}{\sigma^2}=\sum_{i=1}^{n}\frac{(Y_i-\beta_0-\beta_1x_i)^2}{\sigma^2}-(\bar\beta_1-\beta_1)^2(\sum_{i=1}^{n}x^2_i-n\bar x^2)/\sigma^2-(\bar\beta_0-\beta_0)^2(n(\sum_{i=1}^{n}x^2_i-n\bar x^2))/(\sigma^2\sum_{i=1}^{n}x^2_i)~\chi_n^2-\chi_1^2-\chi_1^2=\chi_{n-2}^2
σ2RSS=i=1∑nσ2(Yi−β0−β1xi)2−(βˉ1−β1)2(i=1∑nxi2−nxˉ2)/σ2−(βˉ0−β0)2(n(i=1∑nxi2−nxˉ2))/(σ2i=1∑nxi2)~χn2−χ12−χ12=χn−22
是不是很头疼,实不相瞒,小弟看到这公式也想吐,上学期间老师说了个类比的方式(也可以说是一种背诵小技巧),在此也分享给大家有助于大家理解和记忆。
大家是否还记的
∑
(
y
i
−
μ
)
2
σ
2
=
∑
(
y
i
−
y
ˉ
)
2
σ
2
+
n
(
y
ˉ
−
μ
)
2
σ
2
~
χ
n
2
=
χ
n
−
1
2
+
χ
1
2
\frac{\sum(y_i-\mu)^2}{\sigma^2}=\frac{\sum(y_i-\bar y)^2}{\sigma^2}+\frac{n(\bar y-\mu)^2}{\sigma^2}~\chi_{n}^2=\chi_{n-1}^2+\chi_{1}^2
σ2∑(yi−μ)2=σ2∑(yi−yˉ)2+σ2n(yˉ−μ)2~χn2=χn−12+χ12(具体原因请看小弟第三章内容里卡方分布(chi-square)和第四章内容里置信区间和总体方差(CI & variance)有关卡方的应用.)我们会发现有多少个估计参数,那就在原真参数的公式下减多少个自由度,前提是
y
i
y_i
yi服从正态分布!!!
那么回到
R
S
S
σ
2
\frac{RSS}{\sigma^2}
σ2RSS,因为有两个估计参数
β
ˉ
0
,
β
ˉ
1
\bar\beta_0,\bar\beta_1
βˉ0,βˉ1需要减去,那么则需要减去两个自由度即n-2个自由度。对没错,可能有的同学想到了,如果是多元线性回归,我们有p个随机变量对应有p个系数参数(
β
1
,
.
.
.
,
β
p
\beta_1,..., \beta_p
β1,...,βp),那么就要减去p+1个自由度了(因为我们还有个
β
0
\beta_0
β0)即n-p-1个自由度。这个说法有点野路子,但没错过。有点像高考数学填空题记个套路,算的快点。另外有的同学会说如果p>=n呢,那岂不0个或负个自由度??这问题小弟还真没细想过,但一般来说参数的数量p是远远小于数据量(训练数据量)n的。你有见过30000个训练数据量模型有30000个参数么,小弟只有在神经网络上面有见过类似的还没有那么多参数,这还是饱和模型的情况下,因为当参数量过大,模型会饱和预测即对于未知预测表现差,但那恐怕也不是在线性回归模型上吧,况且那里的
y
i
y_i
yi还是个矩阵,跟我们现在讲的
y
i
y_i
yi不是一回事,更不会服从正态分布吧。
现在回归正题,那么:
E
[
R
S
S
σ
2
]
=
n
−
2
E[\frac{RSS}{\sigma^2}]=n-2
E[σ2RSS]=n−2
我们也可以写成:
E
[
R
S
S
n
−
2
]
=
σ
2
E[\frac{RSS}{n-2}]=\sigma^2
E[n−2RSS]=σ2
我们会发现
R
S
S
n
−
2
\frac{RSS}{n-2}
n−2RSS是无偏估计
σ
2
\sigma^2
σ2
简单线性回归的假设检验和置信区间:
正如第五章所述,假设检验和置信区间已经被统一了,什么意思,就是95%置信区间,以外的在假设检验里面被称为阈值,如果p值大于阈值则原假设成立。
β
1
\beta_1
β1的假设检验和置信区间
很多情况下,我们在做假设检验的时候经常写成:
H
0
:
β
1
=
0
,
v
s
H
1
:
β
1
≠
0
H_0:\beta_1=0, vs H_1:\beta_1≠0
H0:β1=0,vsH1:β1=0
小弟以这个假设检验做例子是因为,大部分得时候我们想判断下是否存在
β
1
\beta_1
β1
那么根据我们先前计算的:
β
ˉ
1
~
N
(
β
1
,
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
)
\bar\beta_1~N(\beta_1,\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2))
βˉ1~N(β1,σ2/(i=1∑nxi2−nxˉ2))
那么:
(
β
ˉ
1
−
β
1
)
/
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
~
N
(
0
,
1
)
(\bar\beta_1-\beta_1)/\sqrt{\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)}~N(0,1)
(βˉ1−β1)/σ2/(i=1∑nxi2−nxˉ2)~N(0,1)
又因为:
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22
我们可得;
(
β
ˉ
1
−
β
1
)
/
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
σ
2
(
n
−
2
)
~
t
n
−
2
\frac{(\bar\beta_1-\beta_1)/\sqrt{\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}{\sqrt{\frac{RSS}{\sigma^2(n-2)}}}~t_{n-2}
σ2(n−2)RSS(βˉ1−β1)/σ2/(∑i=1nxi2−nxˉ2)~tn−2
至于为什么为n-2自由度的t分布,请看数据分析模型 第四章,t分布。
我们现在有了对应的分布,那么做假设检验和置信区间便容易多了。
假设原假设成立
β
1
=
0
\beta_1=0
β1=0,那么:
v
=
(
β
ˉ
1
)
/
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
σ
2
(
n
−
2
)
~
t
n
−
2
v=\frac{(\bar\beta_1)/\sqrt{\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}{\sqrt{\frac{RSS}{\sigma^2(n-2)}}}~t_{n-2}
v=σ2(n−2)RSS(βˉ1)/σ2/(∑i=1nxi2−nxˉ2)~tn−2
那么计算p值:
p
=
2
P
{
T
n
−
2
>
v
}
p=2P\{T_{n-2}>v\}
p=2P{Tn−2>v}
我们是不是算置信区间也容易了,即:
P
{
−
t
α
/
2
,
n
−
2
<
(
β
ˉ
1
−
β
1
)
/
σ
2
/
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
n
−
2
<
−
t
α
/
2
,
n
−
2
}
=
1
−
α
P\{-t_{\alpha/2,n-2}<\frac{(\bar\beta_1-\beta_1)/\sqrt{\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}{\frac{RSS}{n-2}}<-t_{\alpha/2,n-2}\}=1-\alpha
P{−tα/2,n−2<n−2RSS(βˉ1−β1)/σ2/(∑i=1nxi2−nxˉ2)<−tα/2,n−2}=1−α
得:
(
β
ˉ
1
−
R
S
S
(
n
−
2
)
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
t
α
/
2
,
n
−
2
<
β
1
<
β
ˉ
1
+
R
S
S
(
n
−
2
)
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
t
α
/
2
,
n
−
2
)
(\bar\beta_1-\sqrt{\frac{RSS}{(n-2)(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}t_{\alpha/2,n-2}<\beta_1<\bar\beta_1+\sqrt{\frac{RSS}{(n-2)(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}t_{\alpha/2,n-2})
(βˉ1−(n−2)(∑i=1nxi2−nxˉ2)RSStα/2,n−2<β1<βˉ1+(n−2)(∑i=1nxi2−nxˉ2)RSStα/2,n−2)
以上是关于 β 1 \beta_1 β1的假设检验和置信区间,
β
0
\beta_0
β0的假设检验和置信区间
真的大同小异,但小弟知道大家都很懒,所以小弟还是多写几笔。
那么根据我们先前计算的:
β
ˉ
0
~
N
(
β
0
,
σ
2
∑
i
=
1
n
x
i
2
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
)
\bar\beta_0~N(\beta_0,\frac{\sigma^2\sum_{i=1}^{n}x^2_i}{n(\sum_{i=1}^{n}x^2_i-n\bar x^2)})
βˉ0~N(β0,n(∑i=1nxi2−nxˉ2)σ2∑i=1nxi2)
那么:
(
β
ˉ
0
−
β
0
)
/
σ
2
∑
i
=
1
n
x
i
2
n
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
~
N
(
0
,
1
)
(\bar\beta_0-\beta_0)/\sqrt{\frac{\sigma^2\sum_{i=1}^{n}x^2_i}{n(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}~N(0,1)
(βˉ0−β0)/n(∑i=1nxi2−nxˉ2)σ2∑i=1nxi2~N(0,1)
又因为:
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22
同理与关于上述
β
1
\beta_1
β1的计算我们可得:
n
(
n
−
2
)
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
∑
i
=
1
n
x
i
2
R
S
S
(
β
ˉ
0
−
β
0
)
~
t
n
−
2
\sqrt{\frac{n(n-2)(\sum_{i=1}^{n}x^2_i-n\bar x^2)}{\sum_{i=1}^{n}x_i^2 RSS}}(\bar\beta_0-\beta_0)~t_{n-2}
∑i=1nxi2RSSn(n−2)(∑i=1nxi2−nxˉ2)(βˉ0−β0)~tn−2
如果是假设检验,我们就假设原假设成立将
β
0
\beta_0
β0具体值带入,然后计算p值
如果是置信区间则:
β
ˉ
0
±
∑
i
=
1
n
x
i
2
R
S
S
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
n
(
n
−
2
)
t
α
/
2
,
n
−
2
\bar\beta_0±\sqrt{\frac{\sum_{i=1}^{n}x_i^2 RSS}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)n(n-2)}}t_{\alpha/2,n-2}
βˉ0±(∑i=1nxi2−nxˉ2)n(n−2)∑i=1nxi2RSStα/2,n−2
β
0
+
β
1
x
0
\beta_0+\beta_1x_0
β0+β1x0的置信区间
这里的
x
0
x_0
x0是未来的数据,我们要利用置信区间来判断预测值的范围。
我们最早不是利用最小二乘法估计出
β
ˉ
0
,
β
ˉ
1
\bar\beta_0,\bar\beta_1
βˉ0,βˉ1么?即:
β
ˉ
1
=
1
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
(
∑
i
=
1
n
x
i
Y
i
−
x
ˉ
∑
i
=
1
n
Y
i
)
\bar\beta_1=\frac{1}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}(\sum_{i=1}^{n}x_iY_i-\bar x\sum_{i=1}^{n}Y_i)
βˉ1=(∑i=1nxi2−nxˉ2)1(i=1∑nxiYi−xˉi=1∑nYi)
β
ˉ
0
=
∑
i
=
1
n
Y
i
n
−
β
ˉ
1
x
ˉ
\bar \beta_0=\sum_{i=1}^{n}\frac{Y_i}{n}-\bar\beta_1\bar x
βˉ0=i=1∑nnYi−βˉ1xˉ
这里的
x
ˉ
\bar x
xˉ为xi均值
那么我可以得到:
β
ˉ
0
+
β
ˉ
x
0
=
∑
i
=
1
n
Y
i
[
1
n
−
1
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
(
x
i
−
x
ˉ
)
(
x
ˉ
−
x
0
)
]
\bar\beta_0+\bar\beta x_0=\sum_{i=1}^{n}Y_i[\frac{1}{n}-\frac{1}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}(x_i-\bar x)(\bar x-x_0)]
βˉ0+βˉx0=i=1∑nYi[n1−(∑i=1nxi2−nxˉ2)1(xi−xˉ)(xˉ−x0)]
那么:
V
[
β
ˉ
0
+
β
ˉ
x
0
]
=
∑
i
=
1
n
[
1
n
−
1
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
(
x
i
−
x
ˉ
)
(
x
ˉ
−
x
0
)
]
2
V
[
Y
i
]
V[\bar\beta_0+\bar\beta x_0]=\sum_{i=1}^{n}[\frac{1}{n}-\frac{1}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}(x_i-\bar x)(\bar x-x_0)]^2V[Y_i]
V[βˉ0+βˉx0]=i=1∑n[n1−(∑i=1nxi2−nxˉ2)1(xi−xˉ)(xˉ−x0)]2V[Yi]
因为
Y
i
~
N
(
β
0
+
β
1
x
i
,
σ
2
)
Y_i~N(\beta_0+\beta_1x_i,\sigma^2)
Yi~N(β0+β1xi,σ2),
V
[
Y
i
]
=
σ
2
V[Y_i]=\sigma^2
V[Yi]=σ2
那么化简后:
V
[
β
ˉ
0
+
β
ˉ
x
0
]
=
σ
2
[
1
n
+
(
x
ˉ
−
x
0
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
]
V[\bar\beta_0+\bar\beta x_0]=\sigma^2[\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}]
V[βˉ0+βˉx0]=σ2[n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2]
接下来我们又要做同样操作了:
β
ˉ
0
+
β
ˉ
1
x
0
~
N
(
β
0
+
β
1
x
0
,
V
[
β
ˉ
0
+
β
ˉ
x
0
]
=
σ
2
[
1
n
+
(
x
ˉ
−
x
0
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
]
)
\bar\beta_0+\bar\beta_1 x_0~N(\beta_0+\beta_1 x_0,V[\bar\beta_0+\bar\beta x_0]=\sigma^2[\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}])
βˉ0+βˉ1x0~N(β0+β1x0,V[βˉ0+βˉx0]=σ2[n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2])
又因为:
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22
那么:
[
β
ˉ
0
+
β
ˉ
1
x
0
−
(
β
0
+
β
1
x
0
)
]
/
[
1
n
+
(
x
ˉ
−
x
0
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
n
−
2
]
~
t
n
−
2
[{\bar\beta_0+\bar\beta_1 x_0-(\beta_0+\beta_1 x_0)]/}[{\sqrt{\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}\sqrt{\frac{RSS}{n-2}}}]~t_{n-2}
[βˉ0+βˉ1x0−(β0+β1x0)]/[n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2n−2RSS]~tn−2
小弟相信大家明白为什么服从n-2自由度的t分布!!
那么我便得到了
β
0
+
β
1
x
0
\beta_0+\beta_1x_0
β0+β1x0的置信区间,即:
β
ˉ
0
+
β
ˉ
1
x
0
±
1
n
+
(
x
ˉ
−
x
0
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
n
−
2
t
α
/
2
,
n
−
2
\bar\beta_0+\bar\beta_1 x_0±\sqrt{\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}\sqrt{\frac{RSS}{n-2}}t_{\alpha/2,n-2}
βˉ0+βˉ1x0±n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2n−2RSStα/2,n−2
但是有的同学会问,虽然我们利用最小二乘法估计,计算 m i n { R S S } min\{RSS\} min{RSS},但怎么着也不可能RSS=0,也就是说在怎么模型的拟合度高,也会有误差 ε \varepsilon ε。对,没错,我们一般会用 Y ( x 0 ) = β 0 + β 1 x 0 + ε Y(x_0)=\beta_0+\beta_1 x_0+\varepsilon Y(x0)=β0+β1x0+ε来计算基于未来数据的预测的置信区间
Y ( x 0 ) = β 0 + β 1 x 0 + ε Y(x_0)=\beta_0+\beta_1 x_0+\varepsilon Y(x0)=β0+β1x0+ε来计算基于未来数据的预测的置信区间
因为:
Y
=
Y
(
x
0
)
~
N
(
β
0
+
β
1
x
0
,
σ
2
)
Y=Y(x_0)~N(\beta_0+\beta_1 x_0,\sigma^2)
Y=Y(x0)~N(β0+β1x0,σ2)
又因为:
β
ˉ
0
+
β
ˉ
1
x
0
~
N
(
β
0
+
β
1
x
0
,
V
[
β
ˉ
0
+
β
ˉ
x
0
]
=
σ
2
[
1
n
+
(
x
ˉ
−
x
0
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
]
)
\bar\beta_0+\bar\beta_1 x_0~N(\beta_0+\beta_1 x_0,V[\bar\beta_0+\bar\beta x_0]=\sigma^2[\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}])
βˉ0+βˉ1x0~N(β0+β1x0,V[βˉ0+βˉx0]=σ2[n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2])
所以:
Y
−
β
ˉ
0
−
β
ˉ
1
x
0
~
N
(
0
,
σ
2
[
1
+
1
n
+
(
x
ˉ
−
x
0
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
]
)
Y-\bar\beta_0-\bar\beta_1 x_0~N(0,\sigma^2[1+\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}])
Y−βˉ0−βˉ1x0~N(0,σ2[1+n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2])
即:
Y
−
β
ˉ
0
−
β
ˉ
1
x
0
σ
n
+
1
n
+
(
x
0
−
x
ˉ
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
~
N
(
0
,
1
)
\frac{Y-\bar\beta_0-\bar\beta_1 x_0}{\sigma\sqrt{\frac{n+1}{n}+\frac{(x_0-\bar x)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}}~N(0,1)
σnn+1+(∑i=1nxi2−nxˉ2)(x0−xˉ)2Y−βˉ0−βˉ1x0~N(0,1)
又来了,同样的操作:
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22
那么:
(
Y
−
β
ˉ
0
−
β
ˉ
1
x
0
)
/
[
n
+
1
n
+
(
x
0
−
x
ˉ
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
n
−
2
]
~
t
n
−
2
({Y-\bar\beta_0-\bar\beta_1 x_0})/{[\sqrt{\frac{n+1}{n}+\frac{(x_0-\bar x)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}} \sqrt{\frac{RSS}{n-2}}}]~t_{n-2}
(Y−βˉ0−βˉ1x0)/[nn+1+(∑i=1nxi2−nxˉ2)(x0−xˉ)2n−2RSS]~tn−2
置信区间:
β
ˉ
0
+
β
ˉ
1
x
0
±
n
+
1
n
+
(
x
0
−
x
ˉ
)
2
(
∑
i
=
1
n
x
i
2
−
n
x
ˉ
2
)
R
S
S
n
−
2
t
α
/
2
,
n
−
2
\bar\beta_0+\bar\beta_1 x_0±{\sqrt{\frac{n+1}{n}+\frac{(x_0-\bar x)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}} \sqrt{\frac{RSS}{n-2}}}t_{\alpha/2,n-2}
βˉ0+βˉ1x0±nn+1+(∑i=1nxi2−nxˉ2)(x0−xˉ)2n−2RSStα/2,n−2
我知道,看到这,如果大家没发现小弟上述的推导有一定的规律的话,可能大家会觉得世界很沧桑,为什么要学数学。
真的它不难,只是繁琐,上述所有推导的本质都来源于线性回归和正态分布的结合即
Y
i
~
N
(
β
0
+
β
1
x
i
,
σ
2
)
Y_i~N(\beta_0+\beta_1x_i,\sigma^2)
Yi~N(β0+β1xi,σ2),和我们对于估计
σ
2
\sigma^2
σ2时,得到的
R
S
S
σ
2
~
χ
n
−
2
2
\frac{RSS}{\sigma^2}~\chi_{n-2}^2
σ2RSS~χn−22,从而找到对应得分布,又因为置信区间和假设检验已经被前人统一,那么无论是计算置信区间和p值均很容易。
小弟在此写个汇总给大家吧。
简单线性模型和分布的汇总
模型:
Y
=
β
0
+
β
1
x
+
e
Y=\beta_0+\beta_1x+e
Y=β0+β1x+e,
e
~
N
(
0
,
σ
2
)
e~N(0,\sigma^2)
e~N(0,σ2)
数据(x_i,Y_i), i=1,2,3,…,n
| 关于谁的推论 | 涉及的分布 |
|---|---|
| β 1 \beta_1 β1 | ( β ˉ 1 − β 1 ) / σ 2 / ( ∑ i = 1 n x i 2 − n x ˉ 2 ) R S S σ 2 ( n − 2 ) ~ t n − 2 \frac{(\bar\beta_1-\beta_1)/\sqrt{\sigma^2/(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}{\sqrt{\frac{RSS}{\sigma^2(n-2)}}}~t_{n-2} σ2(n−2)RSS(βˉ1−β1)/σ2/(∑i=1nxi2−nxˉ2)~tn−2 |
| β 0 \beta_0 β0 | n ( n − 2 ) ( ∑ i = 1 n x i 2 − n x ˉ 2 ) ∑ i = 1 n x i 2 R S S ( β ˉ 0 − β 0 ) ~ t n − 2 \sqrt{\frac{n(n-2)(\sum_{i=1}^{n}x^2_i-n\bar x^2)}{\sum_{i=1}^{n}x_i^2 RSS}}(\bar\beta_0-\beta_0)~t_{n-2} ∑i=1nxi2RSSn(n−2)(∑i=1nxi2−nxˉ2)(βˉ0−β0)~tn−2 |
| β 0 + β 1 x 0 \beta_0+\beta_1 x_0 β0+β1x0 | [ β ˉ 0 + β ˉ 1 x 0 − ( β 0 + β 1 x 0 ) ] / [ 1 n + ( x ˉ − x 0 ) 2 ( ∑ i = 1 n x i 2 − n x ˉ 2 ) R S S n − 2 ] ~ t n − 2 [{\bar\beta_0+\bar\beta_1 x_0-(\beta_0+\beta_1 x_0)]/}[{\sqrt{\frac{1}{n}+\frac{(\bar x-x_0)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}}\sqrt{\frac{RSS}{n-2}}}]~t_{n-2} [βˉ0+βˉ1x0−(β0+β1x0)]/[n1+(∑i=1nxi2−nxˉ2)(xˉ−x0)2n−2RSS]~tn−2 |
| Y ( x 0 ) Y(x_0) Y(x0) | ( Y − β ˉ 0 − β ˉ 1 x 0 ) / [ n + 1 n + ( x 0 − x ˉ ) 2 ( ∑ i = 1 n x i 2 − n x ˉ 2 ) R S S n − 2 ] ~ t n − 2 ({Y-\bar\beta_0-\bar\beta_1 x_0})/{[\sqrt{\frac{n+1}{n}+\frac{(x_0-\bar x)^2}{(\sum_{i=1}^{n}x^2_i-n\bar x^2)}} \sqrt{\frac{RSS}{n-2}}}]~t_{n-2} (Y−βˉ0−βˉ1x0)/[nn+1+(∑i=1nxi2−nxˉ2)(x0−xˉ)2n−2RSS]~tn−2 |
* x 0 x_0 x0为未来数据
大家有没有发现,简单线性模型和n-2自由度的t分布有关,那么多元线性模型呢?对没错和n-p-1个自由度的t 分布有关。为什么,因为它们的本质没有变化,只是计算结果发生了变化,多元线性模型我们可以写成 Y i ~ N ( β 0 + β 1 x i , 1 + , . . . . , + β p x i , p , σ 2 ) Y_i~N(\beta_0+\beta_1x_{i,1}+,....,+\beta_px_{i,p},\sigma^2) Yi~N(β0+β1xi,1+,....,+βpxi,p,σ2),残差也服从 N ( 0 , σ 2 ) N(0,\sigma^2) N(0,σ2),它的$ R S S σ 2 ~ χ n − p − 1 2 \frac{RSS}{\sigma^2}~\chi_{n-p-1}^2 σ2RSS~χn−p−12剩下的所有推论方法跟简单线性模型的所有推论均一样,只是计算结果不一样罢了。
其实,上学期间,这推论也只能最多在平常作业里算着玩的,在考试的时候,没有老师那么变态要计算这个吧,应该会给一些推论的表格的。平常我们在用excel,或者matlab,R,只要一给模型,一给数据,在来个summary(),啪,什么t-统计答案乱七八糟的,计算机帮我们算好了,我们读结果做题就行了。考试考这个计算就没多大意思了。但小弟还是写了,为了满足初学者对所有细节刨根问底的需求。
加权最小二乘法(weighted least squares)
小弟讲下自己对于权值的理解,大家有见过某些同学跑步腿上绑铁块耍帅的吧,嗯没错权值就是负重。像神经网络里的权值,深度学习里注意力机制的权值,它们都代表着希望提高或者相对降低被负重的对象在计算中的影响力。
一般最小二乘法将时间序列中的各项数据的重要性同等看待,而事实上时间序列各项数据对未来的影响作用应是不同的。一般来说,近期数据比起远期数据对未来的影响更大。因此比较合理的方法就是使用加权的方法,对近期数据赋以较大的权数,对远期数据则赋以较小的权数。加权最小二乘法采用指数权数
W
n
−
i
,
(
0
<
W
<
1
)
i
=
1
,
2
,
3
,
4
,
.
.
.
,
n
W^{n-i},(0<W<1) i=1,2,3,4,...,n
Wn−i,(0<W<1)i=1,2,3,4,...,n,W的具体取值根据你数据分析后,自己定的。
那么我们的RSS加权后为:
R
S
S
w
e
i
g
h
t
=
∑
i
=
1
n
W
n
−
i
(
y
i
−
y
ˉ
i
)
2
RSS_{weight}=\sum_{i=1}^{n}W^{n-i}(y_i-\bar y_i)^2
RSSweight=i=1∑nWn−i(yi−yˉi)2
那么根据我们的简单线性回归,得:
R
S
S
w
e
i
g
h
t
=
∑
i
=
1
n
W
n
−
i
(
y
i
−
y
ˉ
i
)
2
=
R
S
S
w
e
i
g
h
t
=
∑
i
=
1
n
W
n
−
i
(
y
i
−
β
0
−
β
1
x
i
)
2
RSS_{weight}=\sum_{i=1}^{n}W^{n-i}(y_i-\bar y_i)^2=RSS_{weight}=\sum_{i=1}^{n}W^{n-i}(y_i-\beta_0-\beta_1 x_i)^2
RSSweight=i=1∑nWn−i(yi−yˉi)2=RSSweight=i=1∑nWn−i(yi−β0−β1xi)2
同理求
β
0
,
β
1
\beta_0,\beta_1
β0,β1偏导后:
∑
W
n
−
1
y
i
=
β
ˉ
0
∑
W
n
−
i
+
β
ˉ
1
∑
W
n
−
1
x
i
\sum W^{n-1}y_i=\bar\beta_0\sum W^{n-i}+\bar\beta_1\sum W^{n-1}x_i
∑Wn−1yi=βˉ0∑Wn−i+βˉ1∑Wn−1xi
∑ W n − 1 x i y i = β ˉ 0 ∑ W n − i x i + β ˉ 1 ∑ W n − i x i 2 \sum W^{n-1}x_iy_i=\bar\beta_0\sum W^{n-i}x_i+\bar\beta_1\sum W^{n-i}x_i^2 ∑Wn−1xiyi=βˉ0∑Wn−ixi+βˉ1∑Wn−ixi2
那么根据上述我们可以无偏估计得到 β ˉ 0 , β ˉ 1 \bar\beta_0,\bar\beta_1 βˉ0,βˉ1,解方程组即可。
根据
R
S
S
w
e
i
g
h
t
=
∑
i
=
1
n
W
n
−
i
(
y
i
−
β
0
−
β
1
x
i
)
2
RSS_{weight}=\sum_{i=1}^{n}W^{n-i}(y_i-\beta_0-\beta_1 x_i)^2
RSSweight=∑i=1nWn−i(yi−β0−β1xi)2,我们知道我们的简单线性回归应该写成:
Y
i
W
n
−
i
=
β
0
W
n
−
i
+
β
1
W
n
−
i
+
e
W
n
−
i
Y_i\sqrt{W^{n-i}}=\beta_0\sqrt{W^{n-i}}+\beta_1\sqrt{W^{n-i}}+e\sqrt{W^{n-i}}
YiWn−i=β0Wn−i+β1Wn−i+eWn−i
所以我们也能写成正态分布的形式:
Y
i
W
n
−
i
~
N
(
β
0
W
n
−
i
+
β
1
W
n
−
i
,
σ
2
W
n
−
i
)
Y_i\sqrt{W^{n-i}}~N(\beta_0\sqrt{W^{n-i}}+\beta_1\sqrt{W^{n-i}},\sigma^2W^{n-i})
YiWn−i~N(β0Wn−i+β1Wn−i,σ2Wn−i)
这个方差来自,因为
e
i
~
N
(
0
,
1
)
e_i~N(0,1)
ei~N(0,1),所以
e
i
W
n
−
i
~
N
(
0
,
σ
2
W
n
−
i
)
e_i\sqrt{W^{n-i}}~N(0,\sigma^2W^{n-i})
eiWn−i~N(0,σ2Wn−i).
多元线性回归(multiple linear regression)
终于讲到了多元线性回归了。小弟耗费了大量笔墨在简单线性回归上面,想必大家对简单线性回归有了基本的了解,那理解多元线性回归就简单多了。
再重申一点,参数的数量p是远远小于数据量(训练数据量)n的,那么我利用最小二乘法估计多元线性回归的参数,即:
(
β
ˉ
0
,
β
ˉ
1
,
.
.
.
.
,
β
ˉ
p
)
=
m
i
n
{
R
S
S
(
β
0
,
β
1
,
.
.
.
.
,
β
p
)
}
=
a
r
g
m
i
n
β
0
,
β
1
,
.
.
.
.
,
β
p
{
∑
i
=
1
n
(
y
i
−
β
0
−
∑
j
=
1
p
β
j
x
i
,
j
)
2
}
(\bar \beta_0,\bar \beta_1,....,\bar\beta_p)=min\{RSS(\beta_0,\beta_1,....,\beta_p)\}=arg min_{\beta_0,\beta_1,....,\beta_p}\{\sum_{i=1}^{n}(y_i-\beta_0-\sum_{j=1}^{p}\beta_jx_{i,j})^2\}
(βˉ0,βˉ1,....,βˉp)=min{RSS(β0,β1,....,βp)}=argminβ0,β1,....,βp{i=1∑n(yi−β0−j=1∑pβjxi,j)2}
(详请看第三章,线性模型和最小二乘法的参数估计(linear model &least square))
多元线性回归除了计算估计参数的结果不一样,其余性质均和简单线性回归一样。我们也会有多元线性回归和正态分布
Y
i
~
N
(
β
0
+
β
1
x
i
,
1
+
,
.
.
.
.
,
+
β
p
x
i
,
p
,
σ
2
)
Y_i~N(\beta_0+\beta_1x_{i,1}+,....,+\beta_px_{i,p},\sigma^2)
Yi~N(β0+β1xi,1+,....,+βpxi,p,σ2),残差也服从
N
(
0
,
σ
2
)
N(0,\sigma^2)
N(0,σ2)
那么
c
o
r
r
(
x
j
,
e
)
=
0
,
∑
i
=
1
n
e
i
=
0
corr(x_j,e)=0,\sum_{i=1}^{n}e_i=0
corr(xj,e)=0,i=1∑nei=0
即残差和所有随机变量x无关,同理于简单线性回归。
那么估计残差的方差
σ
\sigma
σ:
E
[
R
S
S
n
−
p
−
1
]
=
σ
2
E[\frac{RSS}{n-p-1}]=\sigma^2
E[n−p−1RSS]=σ2
那么:
R
S
S
σ
2
~
χ
n
−
p
−
1
2
\frac{RSS}{\sigma^2}~\chi_{n-p-1}^2
σ2RSS~χn−p−12
多元线性回归和n-p-1个自由度的t 分布有关.
那么多元
∑
i
=
1
p
x
i
β
ˉ
i
−
∑
i
p
x
i
β
i
/
[
R
S
S
n
−
p
−
1
x
T
(
X
T
X
)
−
1
x
]
~
t
n
−
p
−
1
{\sum_{i=1}^{p} x_i\bar\beta_i-\sum_{i}^{p} x_i\beta_i}/[{\sqrt{\frac{RSS}{n-p-1}}\sqrt{x^T(X^TX)^{-1}x}}]~t_{n-p-1}
i=1∑pxiβˉi−i∑pxiβi/[n−p−1RSSxT(XTX)−1x]~tn−p−1
x
=
[
x
0
x
1
⋮
x
p
]
x=\begin{bmatrix} x_0 \\ x_1 \\ \vdots \\ x_p \\ \end{bmatrix}
x=⎣⎢⎢⎢⎡x0x1⋮xp⎦⎥⎥⎥⎤

上图
X
T
X
X^TX
XTX里的下标为k的为我们的p。
R
2
R^2
R2值(R-squared)
我们先不急着讲
R
2
R^2
R2值,我们来看下这个公式:
T
S
S
=
∑
i
=
1
n
(
y
i
−
y
m
e
a
n
)
2
TSS=\sum_{i=1}^{n}(y_i-y_{mean})^2
TSS=i=1∑n(yi−ymean)2
y
m
e
a
n
y_{mean}
ymean即
y
i
y_i
yi均值.大家是不是觉得这公式很眼熟,很像方差嘛,对没错只不过没有最后取均值而已,否则就是我们意义上的方差即上述公式再求个期望/均值。所以反过来想这就是所有方差的和嘛。
方差本质是由两个因素产生,第一: 输入值
x
i
x_i
xi的数量,多样性和极端性,使我们的输出值
y
i
y_i
yi五花八门。第二:就是我们的随机误差,也就是我们的残差导致的。针对第二点因素,巧了,我们有残差平方和公式,即:
R
S
S
=
∑
i
=
1
n
e
i
2
RSS=\sum_{i=1}^{n}e_i^2
RSS=i=1∑nei2
因为我们本章讨论的是线性回归,那么我们以简单线性回归举例子把RSS写的具体些,即:
R
S
S
=
∑
i
=
1
n
(
y
i
−
β
ˉ
0
−
β
ˉ
1
x
i
)
2
RSS=\sum_{i=1}^{n}(y_i-\bar\beta_0-\bar\beta_1x_i)^2
RSS=i=1∑n(yi−βˉ0−βˉ1xi)2
那么,我们如果去掉第二点因素导致的方差和,即:
T
S
S
−
R
S
S
TSS-RSS
TSS−RSS
便得到是由第一点因素影响我们的方差和,即由输入值
x
i
x_i
xi的多样性和极端性,使我们的输出值
y
i
y_i
yi五花八门,从而导致我们的方差和过高或低。
那么,我们便可以得到关于因素1影响我们方差和的比重,即:
R
2
=
T
S
S
−
R
S
S
T
S
S
=
1
−
R
S
S
T
S
S
R^2=\frac{TSS-RSS}{TSS}=1-\frac{RSS}{TSS}
R2=TSSTSS−RSS=1−TSSRSS
这就是R值,也叫拟合度(coefficient of determination),很明显
R
2
∈
[
0
,
1
]
R^2∈[0,1]
R2∈[0,1],那么,如果
R
2
R^2
R2越大,说明关于因素1影响我们方差和的比重越大,也就是说关于残差影响我们的方差和比重越小,也就是说我们的模型拟合度好,因为唯一影响我们的预测的方差仅仅是
x
i
x_i
xi即我们的训练数据而已,残差根本不会影响很大,这不就说明我们的模型很好的诠释了我们的数据么。反之
R
2
R^2
R2越小,则拟合度越差,说明残差极大的影响了我们预测的方差。我们为啥要min{RSS}不就是为了把残差降到最低嘛从而估计参数嘛,别你最后的模型还有很大残差,这就没意思了说明你模型拟合度差(非饱和)。
处理分类变量(handling categorical predictors)
在做线性回归的时候,我们会碰到分类的变量,例如,这里有4类城市名称,1-上海,2-北京,3-奉天,4-汝南,很明显这数字1,2,3,4不可能加减到我们的线性回归上,均值或计算估计参数上吧。我们要对它们进行下处理,处理完后这些变量称为指标变量(indicator variables)。
首先我们会把它们重新划分为K-1个变量(K为几类),假如我们这里有4个城市即4类,那么我们会划分成4-1=3个变量。
城市: A B C
(
1
2
1
3
4
2
3
2
4
)
→
(
0
,
0
,
0
1
,
0
,
0
0
,
0
,
0
0
,
1
,
0
0
,
0
,
0
1
,
0
,
0
0
,
1
,
0
1
,
0
,
0
0
,
0
,
1
)
\begin{pmatrix} 1 \\ 2\\ 1\\ 3\\ 4\\ 2\\ 3\\ 2\\ 4\\ \end{pmatrix}→\begin{pmatrix} 0,0,0 \\ 1,0,0\\ 0,0,0\\ 0,1,0\\ 0,0,0\\ 1,0,0\\ 0,1,0\\ 1,0,0\\ 0,0,1\\ \end{pmatrix}
⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛121342324⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞→⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛0,0,01,0,00,0,00,1,00,0,01,0,00,1,01,0,00,0,1⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞
原先我们就一个变量即城市,城市这个变量可以表现1,2,3,4即4类城市,现在我们把它转换成3个变量A,B,C这三个变量一起表示4类城市.而每个变量只能表示0或者1,这方法很巧,因为当变量这能表示0或者1时,它对它的系数参数影响很大要么0要么非0,这也是为什么它们叫做指标变量。这种方法可以使用在我们的线性回归上面。
可能有的同学看到0,1就会连想到逻辑回归,多类逻辑回归(深度学习里常用的softmax()),没错,这是当我们的模型是分类器即逻辑回归模型的情况下,预测变量是分类数据的时候。但在线性回归模型下,我们也可以处理,即把变量转变为指标变量.
至于二元逻辑回归,多类逻辑回归在本章第二节回归部分里小弟简略的提一下,等到更新至高等数据分析和深度学习会详说多。
非线性情况(nonlinear effects)
有时候我们的x和y的关系可能不是线性,这时候我们需要改变下我们x变量的写法。当我们的x在指数的位置上,与y的关系形成了非线性,我们一般会用两边log的形式把x从指数上取下来。
例子1:
W
(
t
)
≈
c
e
−
d
t
W(t)≈ce^{-dt}
W(t)≈ce−dt
两边取log:
l
o
g
(
W
(
t
)
)
≈
l
o
g
(
c
)
−
d
t
log(W(t))≈log(c)-dt
log(W(t))≈log(c)−dt
那么:
Y
=
l
o
g
(
W
(
t
)
)
,
β
0
=
l
o
g
c
,
β
1
=
−
d
Y=log(W(t)),\beta_0=logc,\beta_1=-d
Y=log(W(t)),β0=logc,β1=−d
那么即为:
Y
=
β
0
+
β
1
t
+
ε
Y=\beta_0+\beta_1t+\varepsilon
Y=β0+β1t+ε
例子2:
1
−
P
(
x
)
≈
c
(
1
−
d
)
x
1-P(x)≈c(1-d)^x
1−P(x)≈c(1−d)x
两边取log:
l
o
g
(
1
−
P
(
x
)
)
≈
l
o
g
(
c
)
+
x
l
o
g
(
1
−
d
)
log(1-P(x))≈log(c)+xlog(1-d)
log(1−P(x))≈log(c)+xlog(1−d)
那么:
Y
=
l
o
g
(
1
−
P
(
x
)
)
,
β
0
=
l
o
g
(
c
)
,
β
1
=
l
o
g
(
1
−
d
)
Y=log(1-P(x)),\beta_0=log(c),\beta_1=log(1-d)
Y=log(1−P(x)),β0=log(c),β1=log(1−d)
有的同学会问如果是log呢,没错两边取e,这其实就是一个很简单的数学技巧而已,在物理里我们有时候也会用到这种技巧。但很不幸,这种技巧只能用在当我们发现x和y只呈现一个弧度的曲线。非线性如果有多个弧度的曲线呢?没错我们利用多项式回归模型(polynomial regression)。其实在数据分析模型这课里,不强调学习过多的回归模型,但小弟同样还是会在本章第二节回归里简单提一下,更新至高等数据分析会详提。
二. 浅谈其他回归模型
二元逻辑回归模型:
讲二元逻辑回归,我们回顾下,伯努利分布:
P
(
y
=
1
∣
θ
)
=
θ
P(y=1|\theta)=\theta
P(y=1∣θ)=θ
现在小弟打算看看成功和失败的比值,我们用对数几率(log-odds)的方式表达出来,即:
l
o
g
(
θ
1
−
θ
)
=
x
log(\frac{\theta}{1-\theta})=x
log(1−θθ)=x
那么我们化简下,把
θ
\theta
θ单独放在等式左边,即得到:
θ
=
1
1
+
e
−
x
\theta=\frac{1}{1+e^{-x}}
θ=1+e−x1
这就是二元逻辑回归公式。二元分类在公式上一般是S曲线,在深度学习里就是常用的sigmoid()激活函数。
有的同学会说,我们能否把对数几率换个表达,换成多元线性方程,嗯没错,可以呢.那么,我们可以得到:
l
o
g
(
θ
i
1
−
θ
i
)
=
β
0
+
∑
j
=
1
p
β
j
x
j
log(\frac{\theta_i}{1-\theta_i})=\beta_0+\sum_{j=1}^{p}\beta_j x_{j}
log(1−θiθi)=β0+j=1∑pβjxj
那么:
P
{
y
i
=
1
∣
x
i
,
1
,
.
.
.
,
x
i
,
p
}
=
1
1
+
e
−
β
0
−
∑
j
=
1
p
β
j
x
i
,
j
P\{y_i=1|x_{i,1},...,x_{i,p}\}=\frac{1}{1+e^{-\beta_0-\sum_{j=1}^{p}\beta_j x_{i,j}}}
P{yi=1∣xi,1,...,xi,p}=1+e−β0−∑j=1pβjxi,j1
多元逻辑回归
多元逻辑回归就是多个分类嘛,假如有K类,那么:
P
(
Y
=
0
∣
X
1
,
X
2
,
.
.
.
,
X
p
)
P(Y=0|X_1,X_2,...,X_p)
P(Y=0∣X1,X2,...,Xp)
P
(
Y
=
1
∣
X
1
,
X
2
,
.
.
.
,
X
p
)
P(Y=1|X_1,X_2,...,X_p)
P(Y=1∣X1,X2,...,Xp)
…
P
(
Y
=
K
−
1
∣
X
1
,
.
.
.
,
X
p
)
P(Y=K-1|X_1,...,X_p)
P(Y=K−1∣X1,...,Xp)
二元逻辑回归是
y
i
=
1
y_i=1
yi=1的概率和
y
i
=
0
y_i=0
yi=0的概率比,那多元逻辑回归怎么办,那我们找个标杆,我们均和
y
i
=
0
y_i=0
yi=0的概率比,即写成:
l
o
g
(
P
(
Y
=
k
∣
X
1
,
.
.
,
X
p
)
P
(
Y
=
0
∣
X
1
,
.
.
,
X
p
)
)
=
∑
j
=
1
p
β
j
k
X
j
+
β
0
k
log(\frac{P(Y=k|X_1,..,X_p)}{P(Y=0|X_1,..,X_p)})=\sum_{j=1}^{p}\beta_j^{k}X_j+\beta_0^k
log(P(Y=0∣X1,..,Xp)P(Y=k∣X1,..,Xp))=j=1∑pβjkXj+β0k
上述公式k=0,1,2,3,…,K. 这个
β
j
k
\beta_j^{k}
βjk的上标k的意思是不同的概率比,它们对应的
β
\beta
β均不一样,这不相当于多个二元逻辑回归比么,不同的概率比
β
\beta
β是不一样的。例如
β
1
1
≠
β
1
2
≠
β
1
3
\beta_1^1≠\beta_1^2≠\beta_1^3
β11=β12=β13,切记这不是平方,立方的意思。意味着第k类和0类的概率比的
β
\beta
β
这个公式太长了写的太麻烦了,我们可以写成:
l
o
g
(
P
(
Y
=
k
∣
X
1
,
.
.
,
X
p
)
P
(
Y
=
0
∣
X
1
,
.
.
,
X
p
)
)
=
η
i
k
log(\frac{P(Y=k|X_1,..,X_p)}{P(Y=0|X_1,..,X_p)})=\eta^k_i
log(P(Y=0∣X1,..,Xp)P(Y=k∣X1,..,Xp))=ηik
那么化简即可:
P
(
Y
=
0
∣
X
i
)
=
1
1
+
∑
k
=
1
K
−
1
e
η
i
k
P(Y=0|X_i)=\frac{1}{1+\sum_{k=1}^{K-1}e^{\eta^k_i}}
P(Y=0∣Xi)=1+∑k=1K−1eηik1
P
(
Y
=
1
∣
X
i
)
=
e
η
i
1
1
+
∑
k
=
1
K
−
1
e
η
i
k
P(Y=1|X_i)=\frac{e^{\eta_i^1}}{1+\sum_{k=1}^{K-1}e^{\eta^k_i}}
P(Y=1∣Xi)=1+∑k=1K−1eηikeηi1
…
P
(
Y
=
K
−
1
∣
X
i
)
=
e
η
i
K
−
1
1
+
∑
k
=
1
K
−
1
e
η
i
k
P(Y=K-1|X_i)=\frac{e^{\eta_i^{K-1}}}{1+\sum_{k=1}^{K-1}e^{\eta^k_i}}
P(Y=K−1∣Xi)=1+∑k=1K−1eηikeηiK−1
看到这里,可能学过深度学习的人明白,这是啥,这不就是softmax()么,像什么人工智能垃圾分类,卷积层神经网络最后一层不就是softmax()么,是不是突然有点恍然大明白的感觉。初学者若不太理解,也没事,这部分内容其实涵盖了广义的线性模型,属于高等数据分析的范畴,换句话说已经超纲了,等更新至高等数据分析,小弟会详细讲解。
多项式回归模型(polynomial regression)
多项式回归模型比线性模型灵活多了,可以模拟非线性的数据。但是,还记得小弟在第一章讲到的,没有一个模型是万能的,对没错,多项式回归模型只能拟合非线性且该非线性处处可求导,什么意思,也就是说只能拟合光滑曲线。举个例子,大家见过心电图吧,多项式回归模型,就没有树形模型好。可通过计算
R
2
R^2
R2可比较。
多项式回归模型:
y
=
β
0
+
β
1
x
+
β
2
x
2
+
.
.
.
+
β
p
x
p
+
ε
y=\beta_0+\beta_1x+\beta_2 x^2+...+\beta_p x^p+\varepsilon
y=β0+β1x+β2x2+...+βpxp+ε
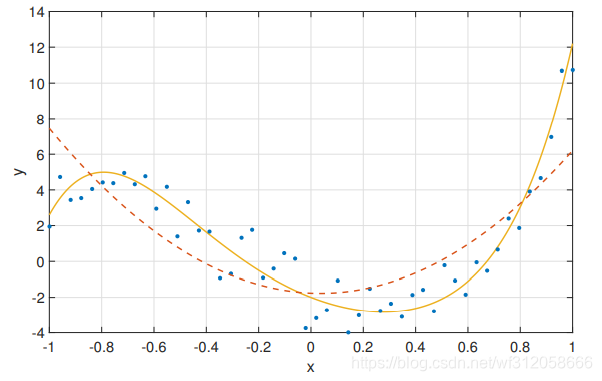
当随着变量越多即x越多它会取向饱和,越少趋向非饱和。
如下图非饱和,实线为真,虚线为
y
=
β
0
+
β
1
x
+
β
2
x
2
y=\beta_0+\beta_1x+\beta_2 x^2
y=β0+β1x+β2x2
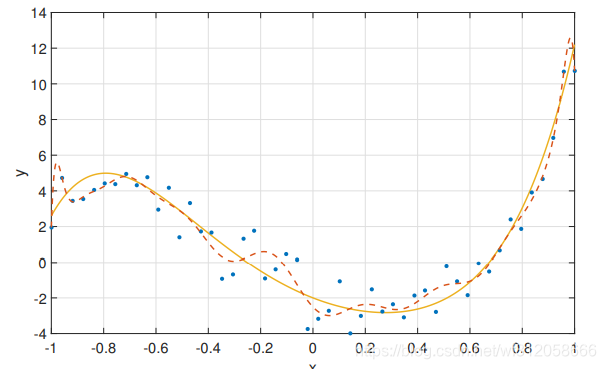
如下图过饱和,实线为真,虚线为
y
=
β
0
+
β
1
x
+
β
2
x
2
+
,
.
.
.
,
+
β
20
x
20
y=\beta_0+\beta_1x+\beta_2 x^2+,...,+\beta_{20} x^{20}
y=β0+β1x+β2x2+,...,+β20x20
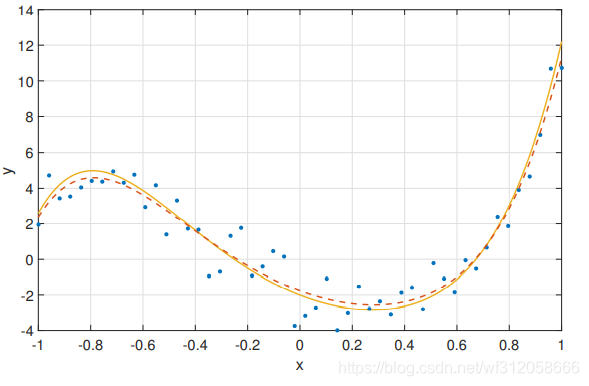
下图,为正正好好,虚线为
y
=
β
0
+
β
1
x
+
β
2
x
2
+
,
.
.
.
,
+
β
6
x
6
y=\beta_0+\beta_1x+\beta_2 x^2+,...,+\beta_{6} x^{6}
y=β0+β1x+β2x2+,...,+β6x6
所以大家发现了,是否
β
j
=
0
\beta_j=0
βj=0很重要,那么我们便可以用假设检验来判断,符合n-p-1的t分布。至于具体推导和公式,在此按下不表了,高等数据分析会详细解释。
模型的选择(model selection)
想必大家已经发现了,变量越多,模型复杂度越大,模型越可能过饱和。那怎样我们可以基于模型一定的情况下,找到适合的变量,以防模型过饱和或者非饱和。
还记得负log似然公式么,估计
β
ˉ
0
,
β
ˉ
1
\bar\beta_0,\bar\beta_1
βˉ0,βˉ1即:
L
(
y
∣
β
ˉ
0
,
β
ˉ
1
)
L(y|\bar\beta_0,\bar\beta_1)
L(y∣βˉ0,βˉ1)
(负log似然公式详请看数据分析模型 第三章,或者看本章前面关于似然=最小二乘法的内容)
负log似然公式仅仅帮我估计参数,但不能帮我们选择模型。当变量越多,即
β
\beta
β越多,一般情况下,我们负log似然的结果就越小,所以模型会过饱和。
现在我们将负log似然公式改一下:
G
=
m
i
n
{
L
(
y
∣
β
ˉ
0
,
β
ˉ
,
M
)
+
α
(
n
,
k
M
)
}
G=min\{L(y|\bar\beta_0,\bar\beta,M)+\alpha(n,k_M)\}
G=min{L(y∣βˉ0,βˉ,M)+α(n,kM)}
该公式在说什么意思呢,
M
M
M代表你的模型,该模型现在有那些估计过的参数,你带入到负log似然中得到一个结果,再加上一个很古怪的东西
α
(
n
,
k
M
)
\alpha(n,k_M)
α(n,kM)。你可以一个个变量加上去,或者把不同的变量组合也加上去,反正疯狂的尝试不同的变量组合,直到我们的G为最小值,就停,那么我们就可以得到该模型搭配的随机变量。
而这个古怪的东西
α
(
n
,
k
M
)
\alpha(n,k_M)
α(n,kM)为复杂度惩罚(complexity penalty),当它为:
α
(
n
,
k
M
)
=
k
M
\alpha(n,k_M)=k_M
α(n,kM)=kM
n为我们样本数据数目,
k
M
k_M
kM为有多少个变量。我们的G为赤池信息准则(Akaike information criterion,AIC)。对没错,它其实本质是一种惩罚性质的似然估计.
当:
α
(
n
,
k
M
)
=
k
M
2
l
o
g
(
n
)
\alpha(n,k_M)=\frac{k_M}{2}log(n)
α(n,kM)=2kMlog(n)
时我们的G即为贝叶斯信息准则(Bayesian Information Criterion,BIC)
我们可以看出,如果变量越多,其实我们的
L
(
⋅
)
L(·)
L(⋅)会变的更低,但这无疑增加了模型的复杂度,所以
α
(
n
,
k
M
)
\alpha(n,k_M)
α(n,kM)作为复杂度惩罚在尝试着增加我们G,使我们G无法变的最小。
这里要注意下贝叶斯准则中的 α ( n , k M ) \alpha(n,k_M) α(n,kM),它必需 1 2 l o g n > 1 \frac{1}{2}logn>1 21logn>1.
如果你用AIC,但AIC的复杂度惩罚 比BIC的复杂度惩罚小,我们的模型有几率过饱和,
如果你用BIC,但BIC复杂度惩罚比AIC复杂度惩罚大,那我们的模型有几率非饱和。
总而言之,AIC是会增加我们模型饱和的概率,BIC是会增加我们模型非饱和的概率。
当你算的AIC和BIC之间差>=3,那么我们认为这个模型正好。
我们之前讨论到我们需要尝试不同的变量组合,如果有p个变量,那么我们要尝试 2 p 2^p 2p次,所以这个方法只能用在p不是很多的情况。
方法1:正向选择逻辑(forward selection algorithm)
1:我们模型什么变量都没有
2:找到一个变量,使我们的信息准则G为最低,你可以选择AIC或者BIC。
3:如果没有一个变量,使我们的G为最低那么停止
4:加一个变量到我们模型里
5:返回第2步
方法2:逆向选择(backward selection)
一开始把所有变量都加入至模型中,然后一个个减去变量。
三. 结语
各位同学辛苦了,有公式推导错误的或理论有谬误的,请大家指出,我好及时更正.
这次更新晚了一些,当时学的时候没发现老师讲课的排版有问题,当自己重新分享给大家时,发现理论的排版不符合新人的认知,所以自己排了下版。不排不知道,一排才发现排版也挺烧脑的。
本章小弟涉及了一丝丝关于高等数据分析的知识和深度学习的关系。大家可以看到,深度学习的根本在于概论,统计和离散数学。所以阿,什么是数据科学专业,其实就是半个数学家会玩计算机罢了。小弟说白了,深度学习牵涉的很多根本逻辑就是数学,它只不过利用人类的神经表现出来了而已。美名其曰人工智能,小弟认为其实就是统计,数学模型的预测,通过计算机计算出来了而已。小弟斗胆认为,数学学的好的人计算机一定强。小弟个人认为自己数学是个半吊子,对于深度学习和计算机视觉学的一般般。所以如果同学们对人工智能感兴趣,请务必学好数学,尤其是离散和概论!
自习的同学可以参考Ross, S.M. (2014) Introduction to Probability and Statistics for Engineers and Scientists, 5th ed. Academic Press. 第9章

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐
 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)