大数据挖掘与分析复习总结:教材《Python数据科学手册》
Python大数据挖掘与分析NumPy基础和高级numpy的基本运算(已知arr=np.array(list))arr.min()和arr.max()求arr最小或最大值arr.exp()和arr.sqrt()指数运算和开方运算arr.mean([axis=x])求数组均值。arr.sum([axis=x])数组求和arr.sort([axis=x])和arr.argsort(axis=x)前者为
Python大数据挖掘与分析
NumPy基础和高级
-
numpy的基本运算(已知
arr=np.array(list))-
arr.min()和arr.max()求arr最小或最大值
-
arr.exp()和arr.sqrt()指数运算和开方运算
-
arr.mean([axis=x])求数组均值。
arr.sum([axis=x])数组求和
arr.sort([axis=x])和arr.argsort(axis=x)前者为数组元素排序,后者为数组索引排序(即排序后得到一个索引数组)
-
axis参数中x的取值确定求值:
- =1时,求每一行的平均
- =0时,求每一列的平均
-
-
创建矩阵:
-
全为0的矩阵:
arr=np.zeros(shape=(x,x)) -
全为1的矩阵:
arr=np.ones(shape=(x,x)) -
单位矩阵(对角线为1):
arr=np.eye(x)
-
-
数组创建和改变数组形状
-
数组创建:
np.array(list)list创建:
np.random.randint()range(x,x)
-
改变数组形状:
-
reshape(),括号内可为任意形状 -
ravel(),括号内无参数拆解,将多维数组变成一维数组。
-
flatten(),括号内无参数拉直,其功能与
ravel()相同,但是flatten()返回的是真实的数组,需要分配新的内存空间,而ravel()仅仅是改变视图。 -
shape(), 括号内可为任意形状使用元组改变数组形状。
-
transpose(),括号内无参数转置。
-
-
-
数组堆叠
hstack():水平叠加vstack():垂直叠加dstack():深度叠加
-
数组拆分
-
hsplit():横向拆分 -
vsplit():纵向拆分 -
dsplit():深度拆分深度拆分要求数组的秩大于等于3
-
Pandas
-
dataframe选择行和列的区别
-
选择单列和单行
-
单列,不需要加
loc函数,直接选择列名:df['country'] -
单行,需要加
loc函数,后面添加行名:df.loc['country']
-
-
选择特定多列、多行
-
特定多列,不需要加
loc函数,直接选择列名:df[['revenues', 'years_on_global_500_list']] -
特定多行,需要加
loc函数,后面添加行名:df.loc['revenues', 'years_on_global_500_list']
-
-
选择连续多列、多行(这里和前面逻辑相反)
-
连续多列,需要加
loc函数,括号内添加:,+列名列表:df.loc[:, 'ceo': 'sector'] -
连续多行,不需要加
loc函数,括号内直接添加行名列表:df['ceo': 'sector']
-
-
-
info()函数与describe()函数
- info()函数用于打印DataFrame的简要摘要,显示有关DataFrame的信息,包括索引的数据类型dtype和列的数据类型dtype,非空值的数量和内存使用情况
- describe()函数用于生成描述性统计信息。 描述性统计数据:数值类型的包括均值,标准差,最大值,最小值,分位数等;类别的包括个数,类别的数目,最高数量的类别及出现次数等;输出将根据提供的内容而有所不同。
-
读文件和转换文件
-
读:
df = pd.read_文件类型(r‘filename’)文件类型有CSV、Excel
-
转换:
df.to_csv(filename)
-
-
读取文件信息
df.head(x)头x行df.tail(x)尾x行
-
文件类型、各字段数据类型、全部列名称和shape(多少行多少列)信息
- 文件类型信息:
type(filename) - 各字段数据类型:
df.dtypes - 全部列名称:
df.columns - shape信息:
df.shape
- 文件类型信息:
-
字段类型转换、删除字段、和消除重复项
- 字段类型转换:
df.字段名=pd.to_要转换的类型(df.字段名) - 删除字段(行或列):
del df[字段名] - 消除重复项:
df.drop_duplicates
- 字段类型转换:
-
关于df中缺失值的行或列
- 删除df中有缺失值的行:
df.dropna(how='any') - 删除df中有缺失值的列:
df.dropna(how='any',axis=1) - 删除所有元素都为缺省的行:
df.dropna(how='all') - 删除所有元素都为缺省的列:
df.dropna(how='all',axis=1)
- 删除df中有缺失值的行:
-
透视表:
pd.pivot_table(df,index)将index这一列或行转置为索引,使其突出好查看
-
df拼接融合:
pd.concat()具体见文章:https://www.jb51.net/article/164905.htm
Matplotlib
-
matplotlib图例设置
https://blog.csdn.net/m0_46079750/article/details/107548843
代价函数
用梯度下降法求代价函数最小值过程的前三步的θ值和代价函数J的值
公式:
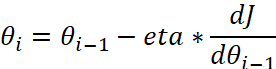
向量三范数(L0、L1、L2)
-
L0范数是指向量中非零元素的个数。
- 如果用L0规则化一个参数矩阵W,就是希望W中大部分元素是零,实现稀疏。
-
L1范数是指向量中各个元素的绝对值之和。
-
也叫”系数规则算子(Lasso regularization)“。
-
L1范数也可以实现稀疏,通过将无用特征对应的参数W置为零实现。
-
-
L2范数是指向量各元素的平方和然后开方。
-
用在回归模型中也称为岭回归(Ridge regression)。
-
L2避免过拟合的原理是:让L2范数的规则项||W||2 尽可能小,可以使得W每个元素都很小,接近于零,但是与L1不同的是,不会等于0;这样得到的模型抗干扰能力强,参数很小时,即使样本数据x发生很大的变化,模型预测值y的变化也会很有限。
-
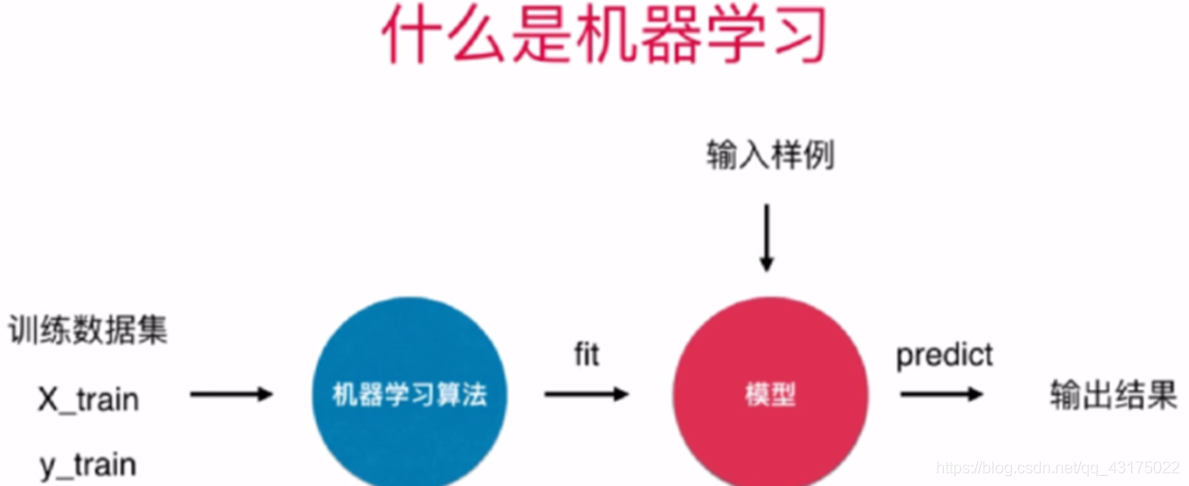
机器学习
-
概念
-
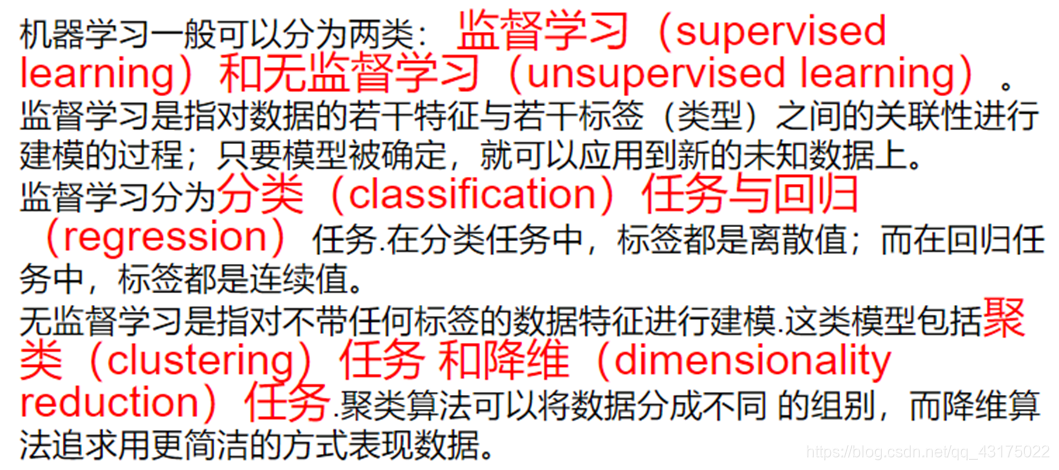
分类
scikit-learn
-
数据表示

-
API的使用

-
过程示意图:
-
训练过程:
-
验证过程:

-
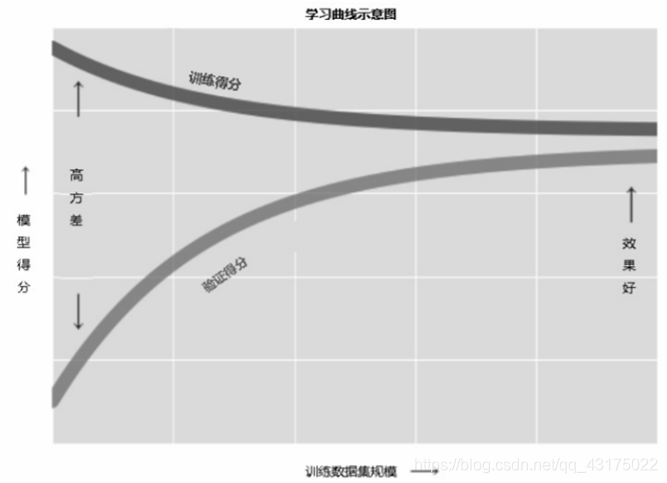
过拟合与欠拟合
-
概念

-
图示
-
欠拟合,训练误差大,测试误差大
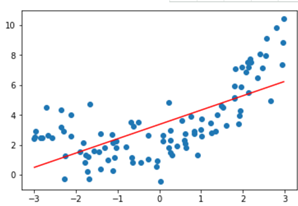
- 解决:增加模型复杂度,如采用高阶模型(预测)或者引入更多特征(分类)等
-
过拟合,训练误差小,测试误差大
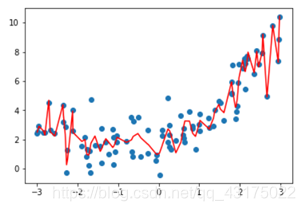
- 解决:降低模型复杂度,如加上正则惩罚项,如L1,L5,增加训练数据等
-
正常示例
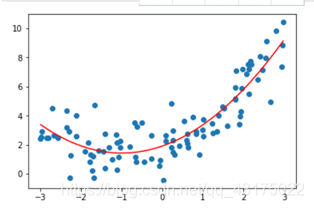
-
-
发现高偏差
- 发现模型存在高偏差(high bias),应该增加模型的特征数量
五大模型
分类
-
线性回归
-
朴素贝叶斯(Naive Bayesian,NBM)
-
逻辑回归(logistic regression)
-
决策树与随机森林(Decision Tree&Random Forest)
-
SVM
方法
- 梯度下降:计算题
相关概念和总结
-
最值归一化

-
L0、L1、L3范数

L0范数是指向量中非0的元素的个数。
L1范数是指向量中各个元素绝对值之和
L2范数是指向量各元素的平方和然后求平方根
- Lasso 回归适用于特征选择
-
精准率和召回率
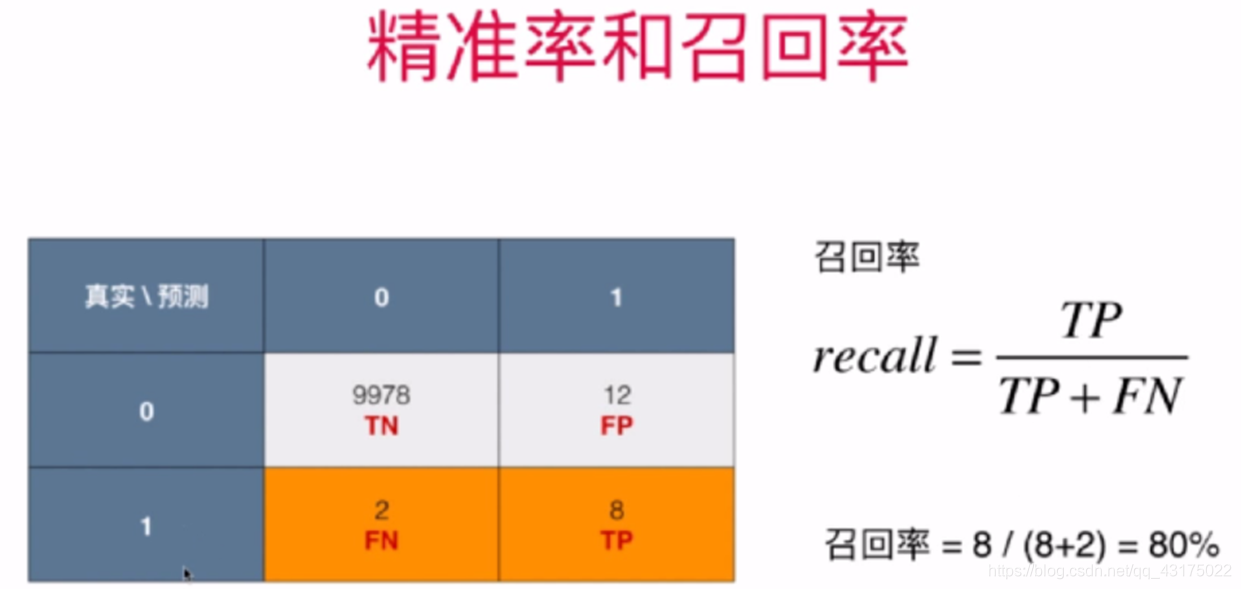
-
F1 Score

-
基尼系数
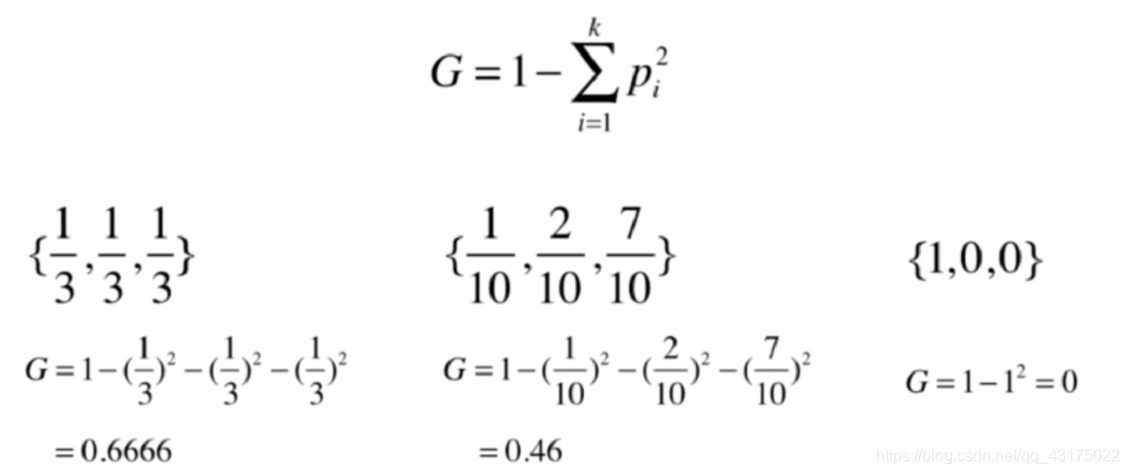
-
总结
- 回归和分类都是有监督学习问题
- 有监督学习是从标签化训练数据集中推断出函数的机器学习任务
- 在回归问题中,标签是连续值;在分类问题中,标签是离散值
- SVM核函数包括多项式核函数、线性核函数、.径向基核函数.Sigmoid核函数
- logistic(逻辑)回归可以用来解决0/1分类问题

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)