大数据毕业设计hadoop+spark+hive新闻数据分析可视化大屏 知识图谱新闻推荐系统 新闻爬虫 新闻大数据 新闻语料分析 新闻情感分析 计算机毕业设计
大数据毕业设计hadoop+spark+hive新闻数据分析可视化大屏 知识图谱新闻推荐系统 新闻爬虫 新闻大数据 新闻语料分析 新闻情感分析 计算机毕业设计
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
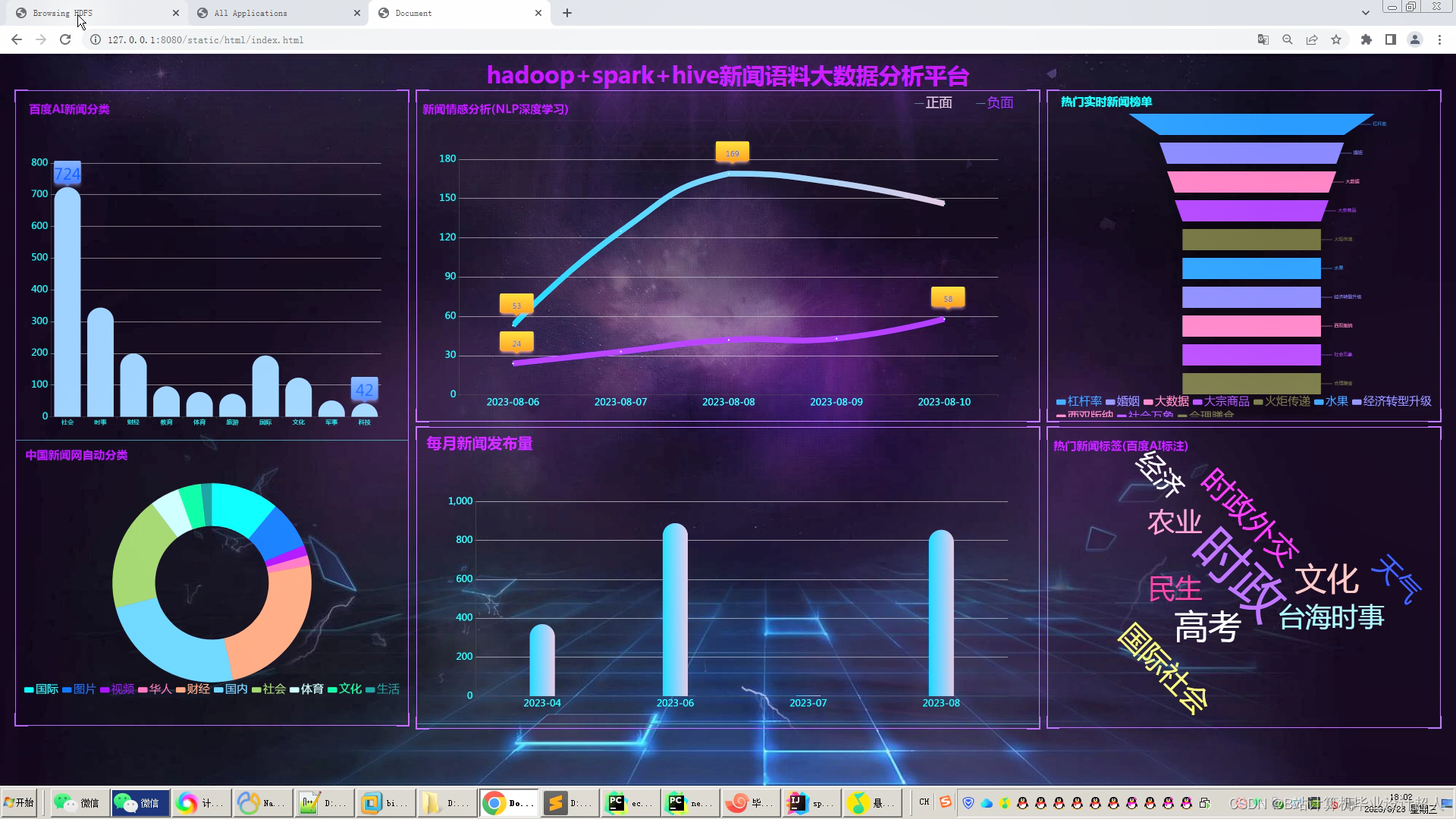
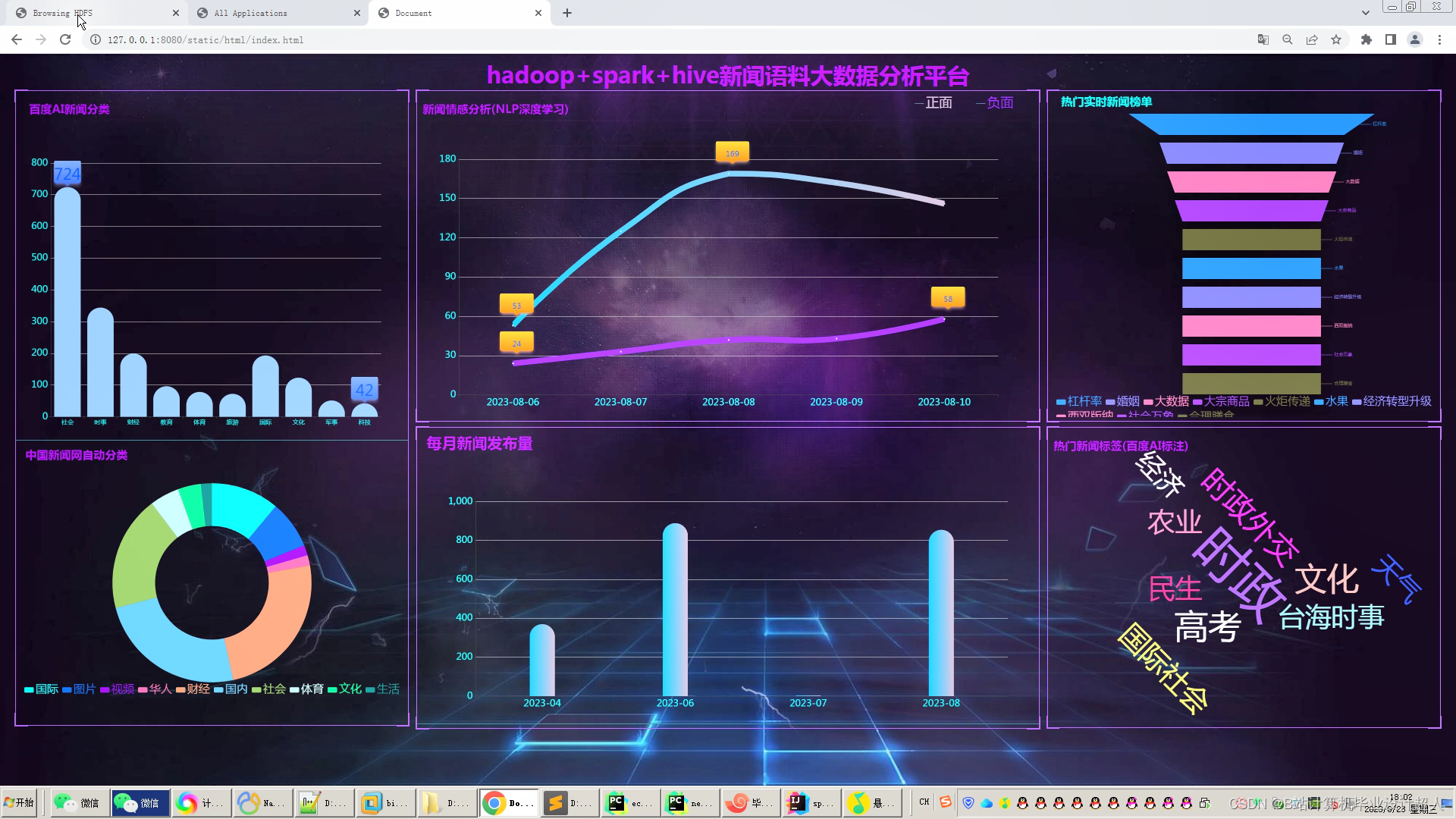
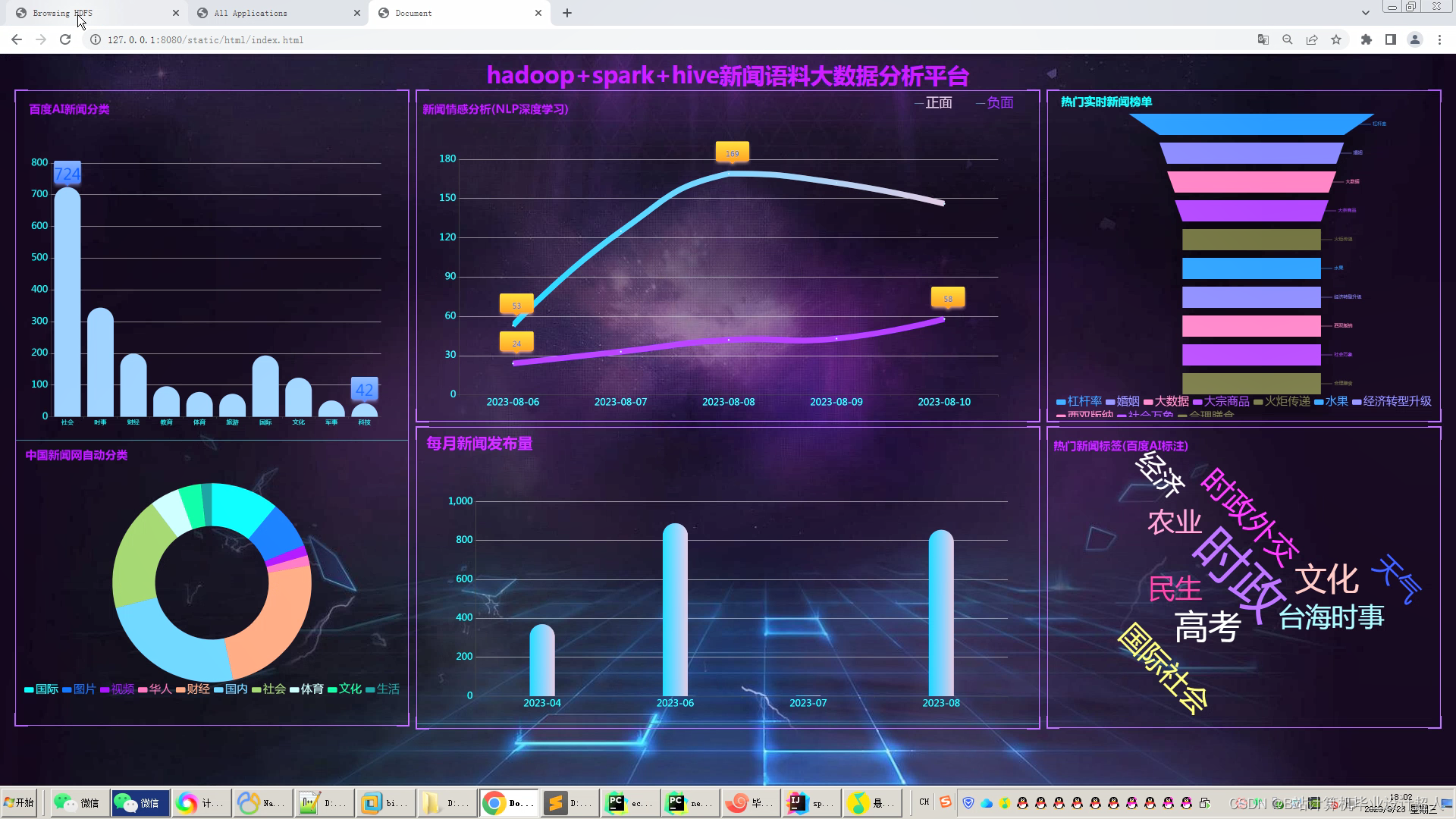
文章包含:项目选题 + 项目展示图片 (必看)
流程:
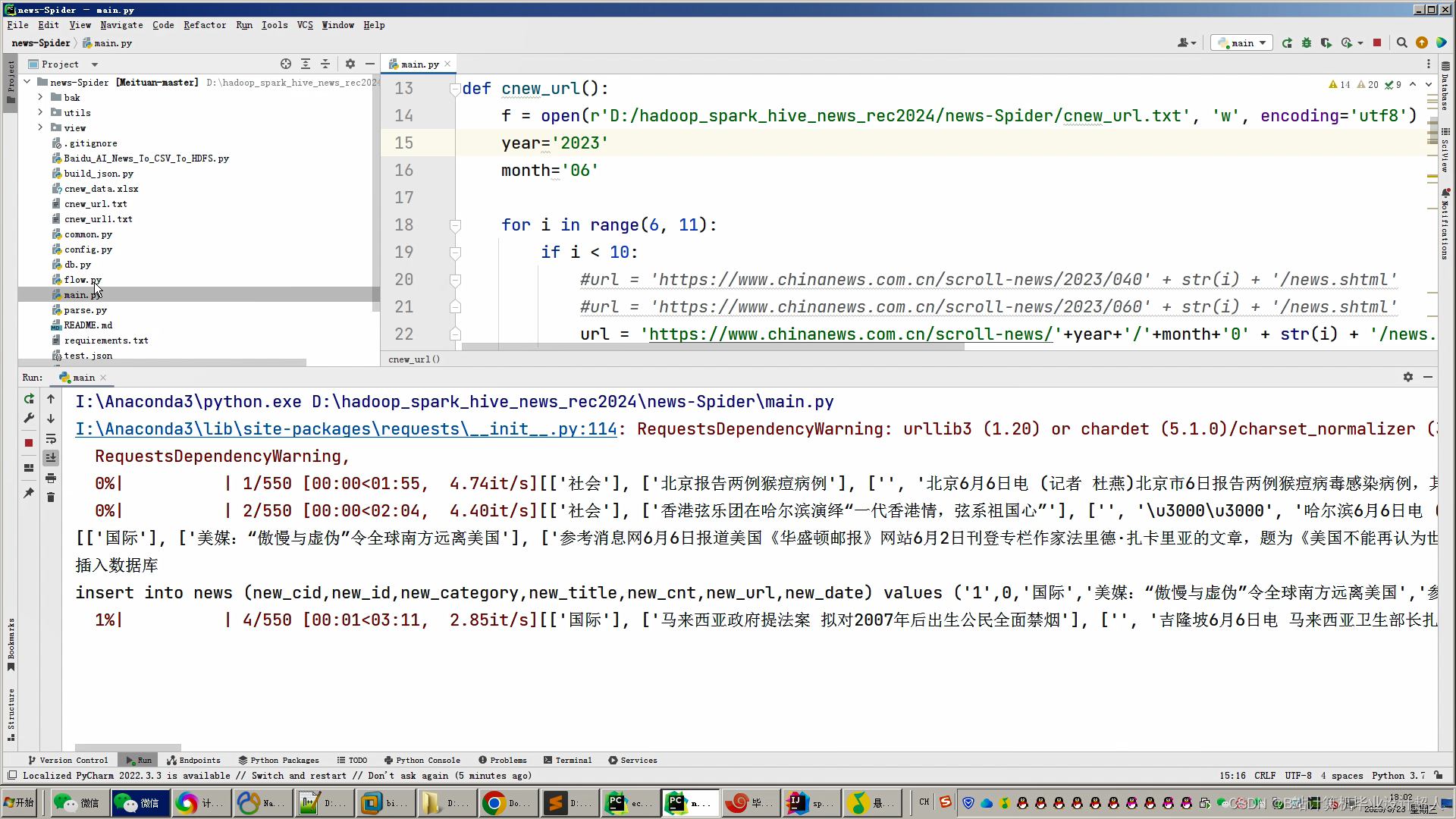
1.使用Python采集新闻数据约10万条存入mysql数据库;
2.使用pandas+numpy或者hadoop+mapreduce进行数据清洗,尝试用深度学习的分析模型对新闻语料、情感、数据标注等进行大模型分析,最终结果保存为.csv文件并上传hdfs;
3.使用hive建库建表,导入.csv文件作为数据集;
4.一半分析指标使用hive_sql完成,一半分析指标使用Spark之Scala完成;
5.对分析的结果使用sqoop导入mysql数据库;
6.使用Flask+echarts构建炫酷吊炸天大屏可视化界面;
创新点:1大屏 2Python爬虫 3深度学习自然语言处理分析 4海量百万数据随时可爬 5实时计算+离线计算全部实现
注意点:如果你还觉得工作量不够,可以选装推荐系统(4种机器学习、深度学习推荐算法)、预测系统、知识图谱、后台等,实现界面如下(我保证可以0秒内无缝对接选装安装上)

计算机毕业设计吊打导师hadoop+spark知识图谱新闻推荐系统 新闻预测 新闻文本分类 新闻可视化 新闻爬虫 新闻情感分析 机器学习 深度学习 大数据毕设
运行代码如下:
当涉及到编写爬虫代码时,需要明确爬取的目标网站、数据结构和所需的编程语言。由于我无法直接访问互联网和实时执行代码,我将提供一个基本的Python爬虫代码示例,使用Beautiful Soup库来解析HTML并提取所需的数据。你可以根据自己的需求进行修改和扩展。
首先,请确保已安装必要的库。你可以使用以下命令安装Beautiful Soup和requests库:
bash
pip install beautifulsoup4 requests
以下是一个简单的爬虫代码示例,它从一个假设的网站中提取文章标题和链接:
python
import requests
from bs4 import BeautifulSoup
def fetch_data(url):
response = requests.get(url)
if response.status_code == 200:
return response.text
else:
print("Failed to fetch the data.")
return None
def parse_data(html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
# 假设每个文章都在一个具有特定类名的div标签内
for div in soup.find_all('div', class_='article'):
title = div.find('h2').text.strip() # 提取标题
link = div.find('a')['href'] # 提取链接
articles.append({'title': title, 'link': link})
return articles
def main():
url = 'https://example.com/articles' # 替换为目标网站的URL
html = fetch_data(url)
if html:
articles = parse_data(html)
for article in articles:
print(f"Title: {article['title']}")
print(f"Link: {article['link']}")
print()
if __name__ == '__main__':
main()
请注意,上述代码中的URL和HTML结构是假设的,你需要根据实际情况进行修改。此外,爬虫的使用需要遵守目标网站的使用条款和法律法规,确保你的爬虫行为合法且不会对目标网站造成不必要的负担。
另外,一些网站可能会采取反爬虫措施,如使用动态加载、验证码、登录验证等,这可能需要更复杂的爬虫技术或工具来处理。此示例代码仅适用于静态网页的基本爬取。
永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 10
10 0
0- 0



 已为社区贡献296条内容
已为社区贡献296条内容

所有评论(0)