数据挖掘:聚类算法
g
·
聚类算法
聚类是无监督学习的典型算法,不需要标记结果。试图探索和发现一定的模式,用于发现共同的群体,按照内在相似性将数据划分为多个类别使得内内相似性大,内间相似性小。它与分类算法的区别如下: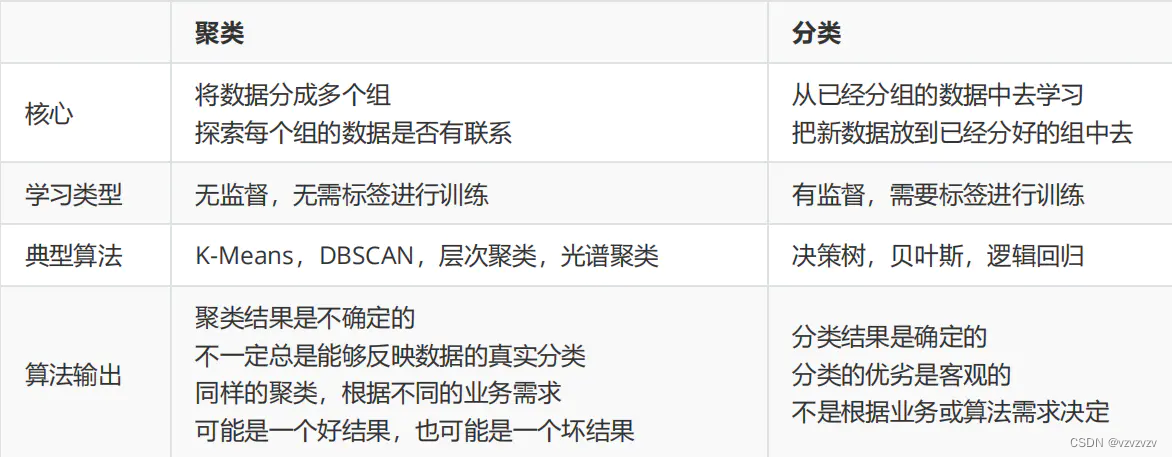 由于聚类算法没有标签,结果的好坏几乎完全取决于使用者对于各类别的定义。
由于聚类算法没有标签,结果的好坏几乎完全取决于使用者对于各类别的定义。
KMeans
K-means 的算法步骤为:
1.选择初始化的 k 个样本作为初始聚类中心
2.针对数据集中每个样本 计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中;
3.针对每个类别 ,重新计算它的聚类中心 (即属于该类的所有样本的质心);
4.重复上面 2 3 两步操作,直到达到某个中止条件(迭代次数、最小误差变化等)。
下图展现了其运作方式 KMeans的优缺点:
KMeans的优缺点:
优点:
容易理解,聚类效果不错,虽然是局部最优, 但往往局部最优就够了;
处理大数据集的时候,该算法可以保证较好的伸缩性;
当簇近似高斯分布的时候,效果非常不错;
算法复杂度低。
缺点:
K 值需要人为设定,不同 K 值得到的结果不一样;
对初始的簇中心敏感,不同选取方式会得到不同结果;
对异常值敏感;
样本只能归为一类,不适合多分类任务;
不适合太离散的分类、样本类别不平衡的分类、非凸形状的分类。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)