
大数据毕业设计hadoop+spark+hive知识图谱股票推荐系统 股票数据分析可视化大屏 股票基金爬虫 股票基金大数据 机器学习 计算机毕业设计
大数据毕业设计hadoop+spark+hive知识图谱股票推荐系统 股票数据分析可视化大屏 股票基金爬虫 股票基金大数据 机器学习 计算机毕业设计
博主介绍:✌全网粉丝100W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业毕业设计项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
🍅由于篇幅限制,想要获取完整文章或者源码,或者代做,可以给我留言或者找我聊天。🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人 。
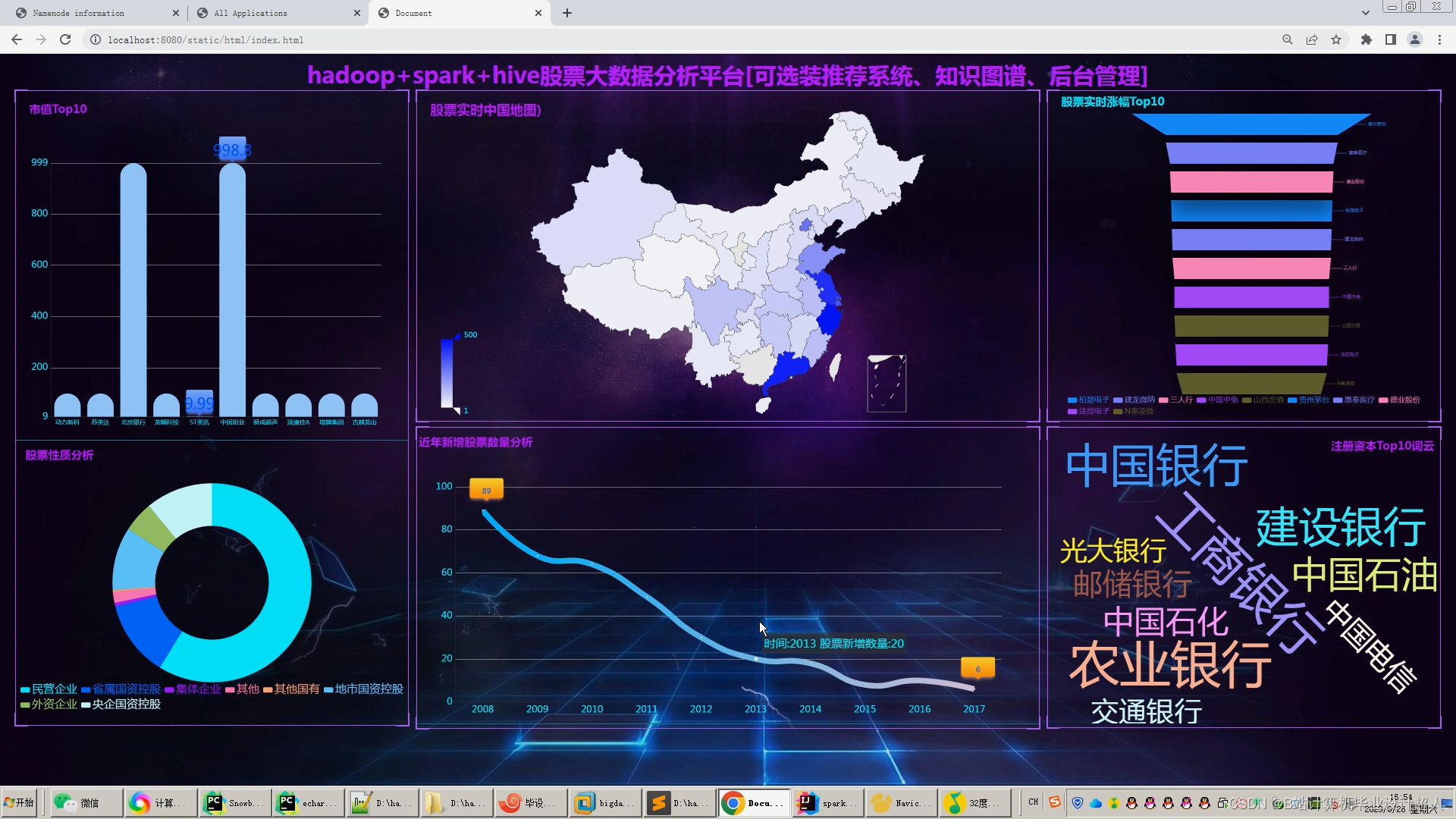
文章包含:项目选题 + 项目展示图片 (必看)
随着大数据时代的到来,股票数据分析与可视化成为了金融领域的重要研究方向。传统的股票数据分析方法已经无法满足海量数据的需求,而Hadoop和Hive作为大数据处理和分析的强大工具,为股票数据分析提供了新的解决方案。因此,本研究旨在利用Hadoop和Hive对股票数据进行深入分析和可视化,为投资者提供更加准确、全面的决策支持。本研究的成果将有助于提高投资者的决策效率和准确性,同时为金融领域的大数据应用提供新的思路和方法。本研究将采用以下步骤进行:
数据采集:收集股票市场的历史数据和实时数据,包括股票价格、成交量、财务指标等。
数据预处理:对采集到的数据进行清洗、整理和标准化处理,以提高数据分析的准确性。
数据分析:利用Hadoop和Hive对处理后的数据进行深入分析,包括数据挖掘、机器学习等,提取有价值的信息。
数据可视化:将分析结果以图表、图像等形式进行可视化呈现,以便投资者更好地理解股票市场。
具体研究任务包括:
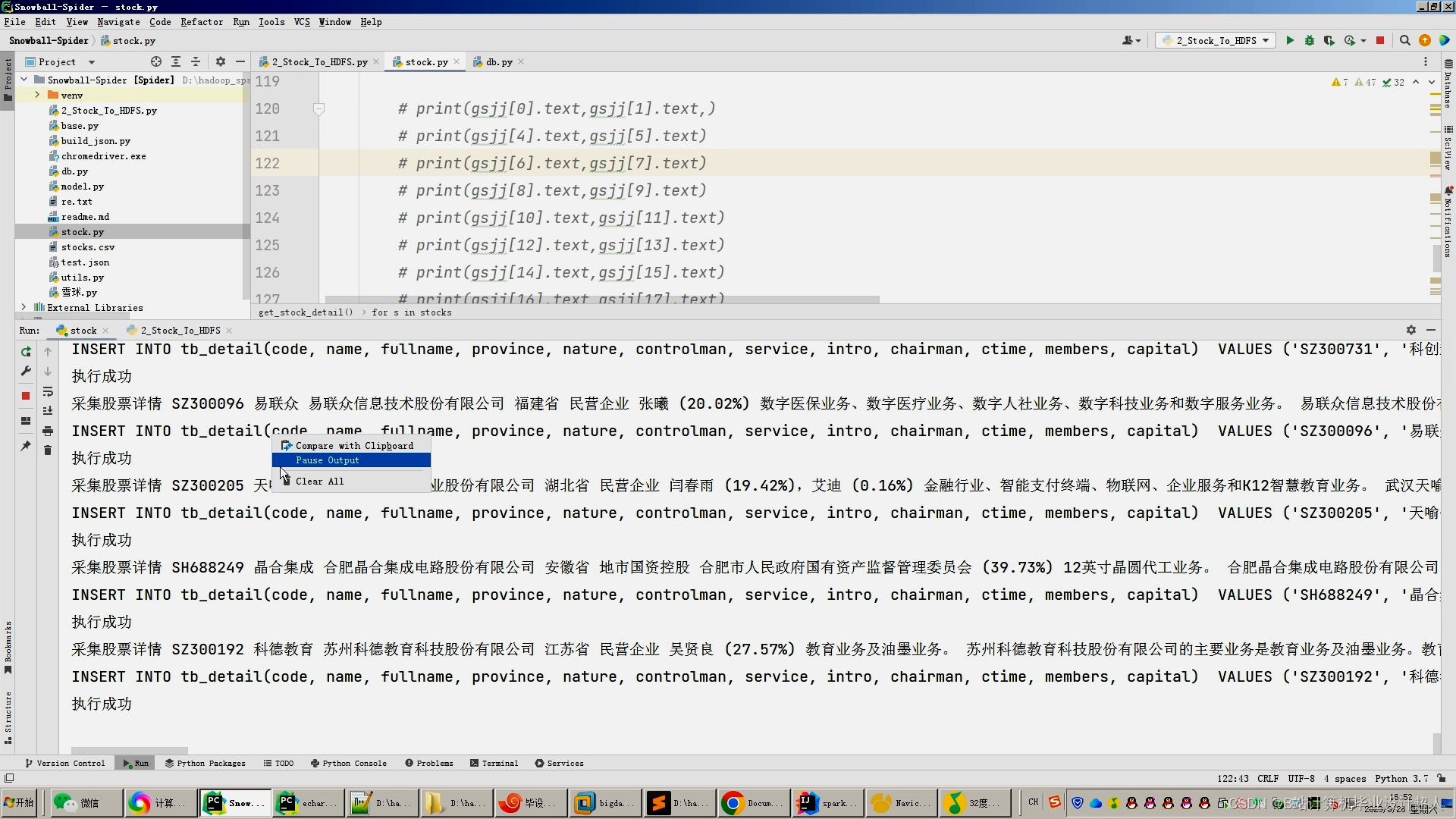
1.采集雪球网约50万股票数据存入mysql;
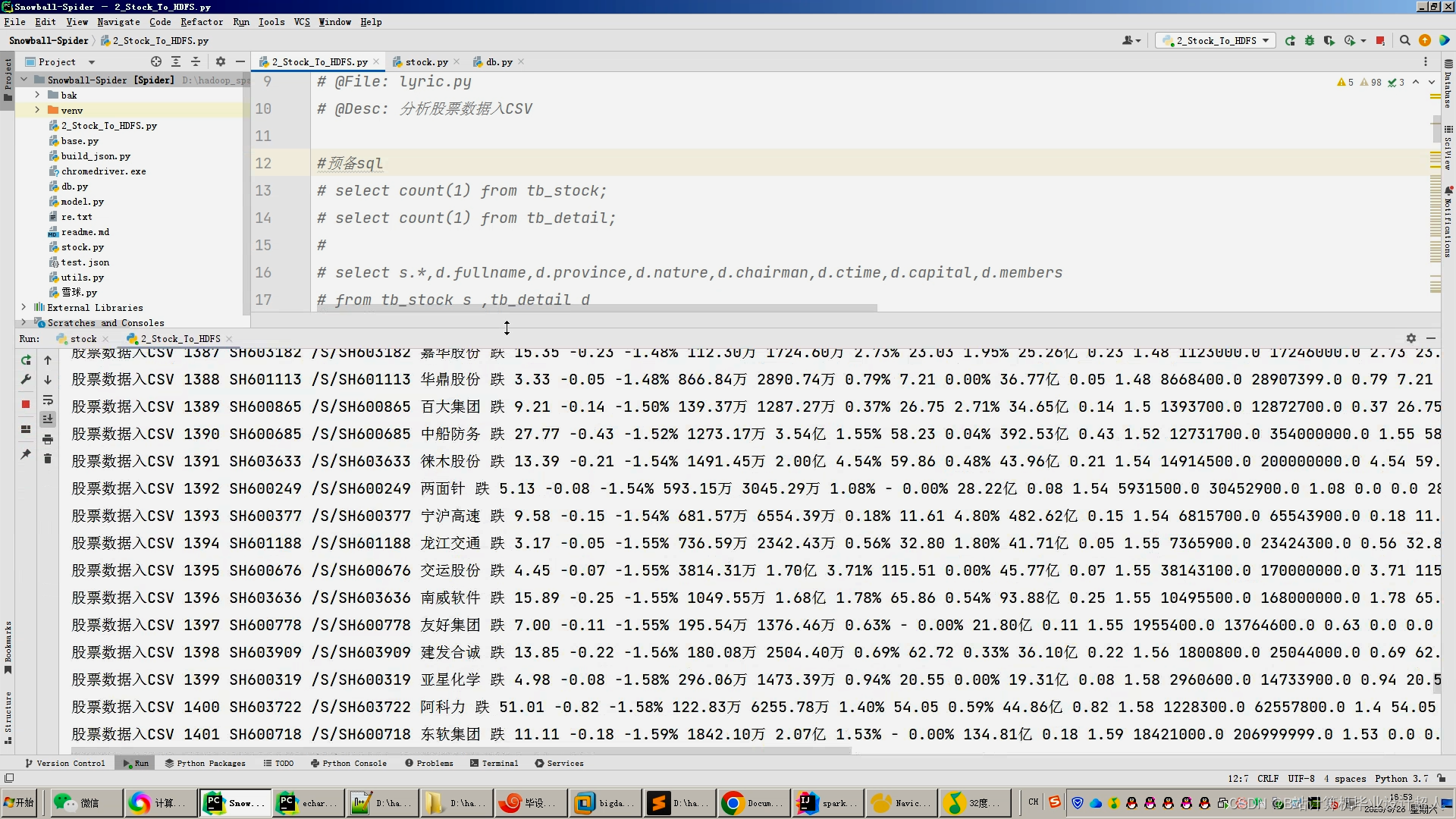
2.使用pandas+numpy或hadoop+mapreduce对mysql中的数据进行数据清洗并转存.csv文件上传到hdfs;
3.使用hive建表建库导入hdfs中的.csv数据集;
4.一半指标使用hive_sql进行离线计算分析,一半指标使用Spark之Scala语法进行实时计算分析;
5.分析结果使用sqoop导入mysql数据库;
6.使用flask+echarts搭建可视化大屏界面;
股票管理系统功能:
1、数据采集:收集股票市场的历史数据和实时数据,包括股票价格、成交量、财务指标等。
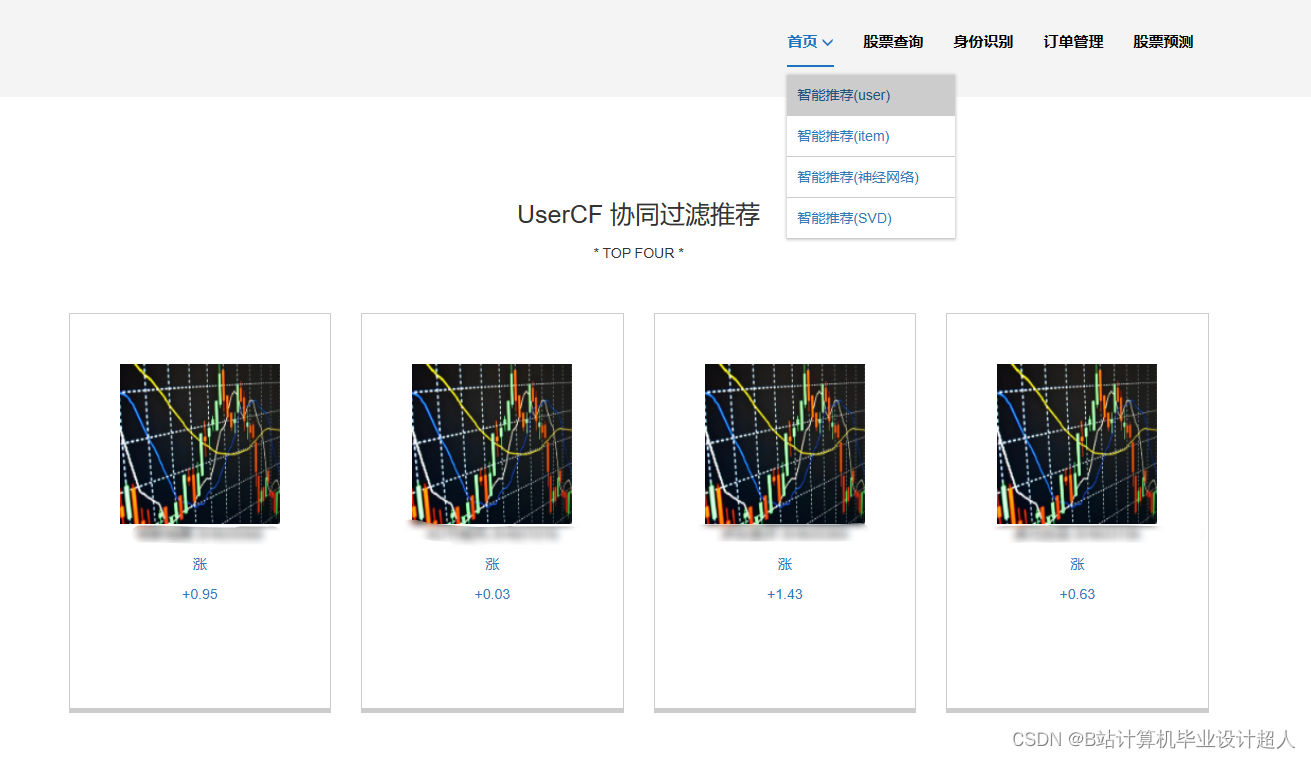
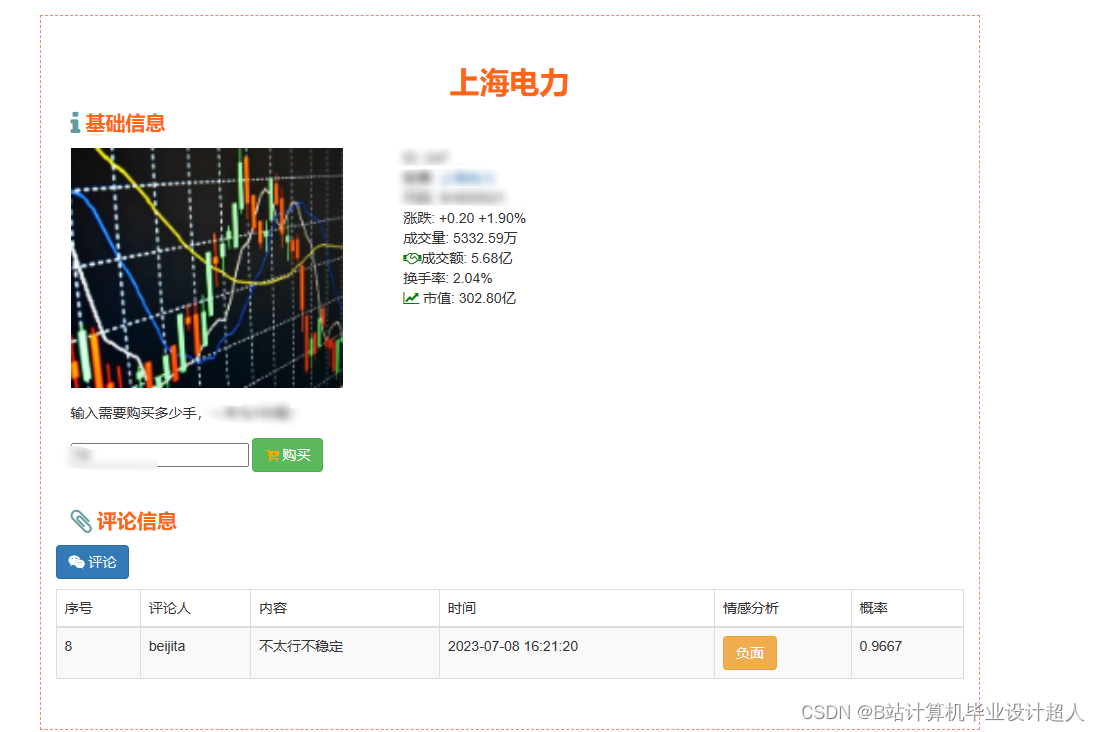
2、用户功能:首页股票信息展示,股票推荐(根据协同过滤基于用户、物品、SVD神经网络、MLP模型), 股票K线预测(CNN卷积神经预测 ),股票信息详情(股票代码,涨跌幅度,成交量,成交额,换手率,股票市值), 购买股票,订单管理,股票信息评论(lstm情感分析模型)
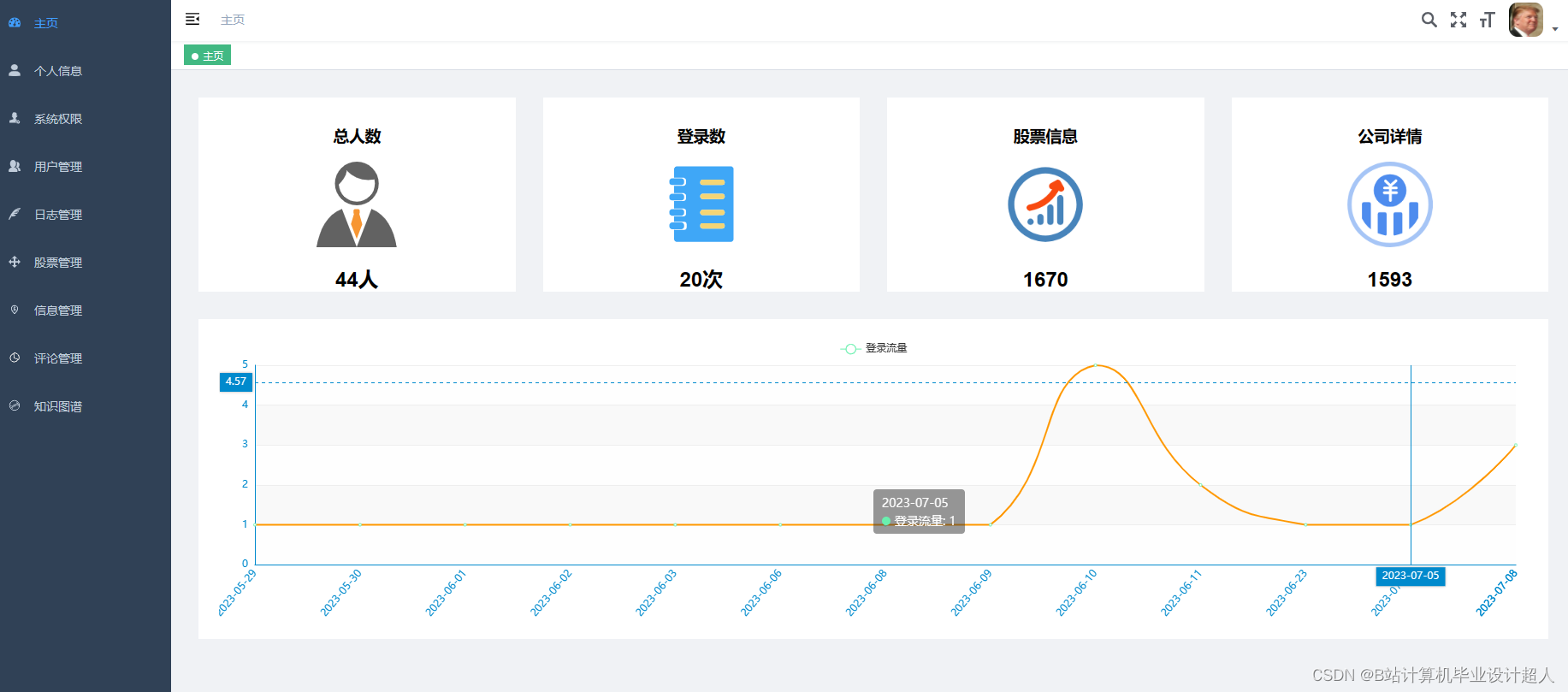
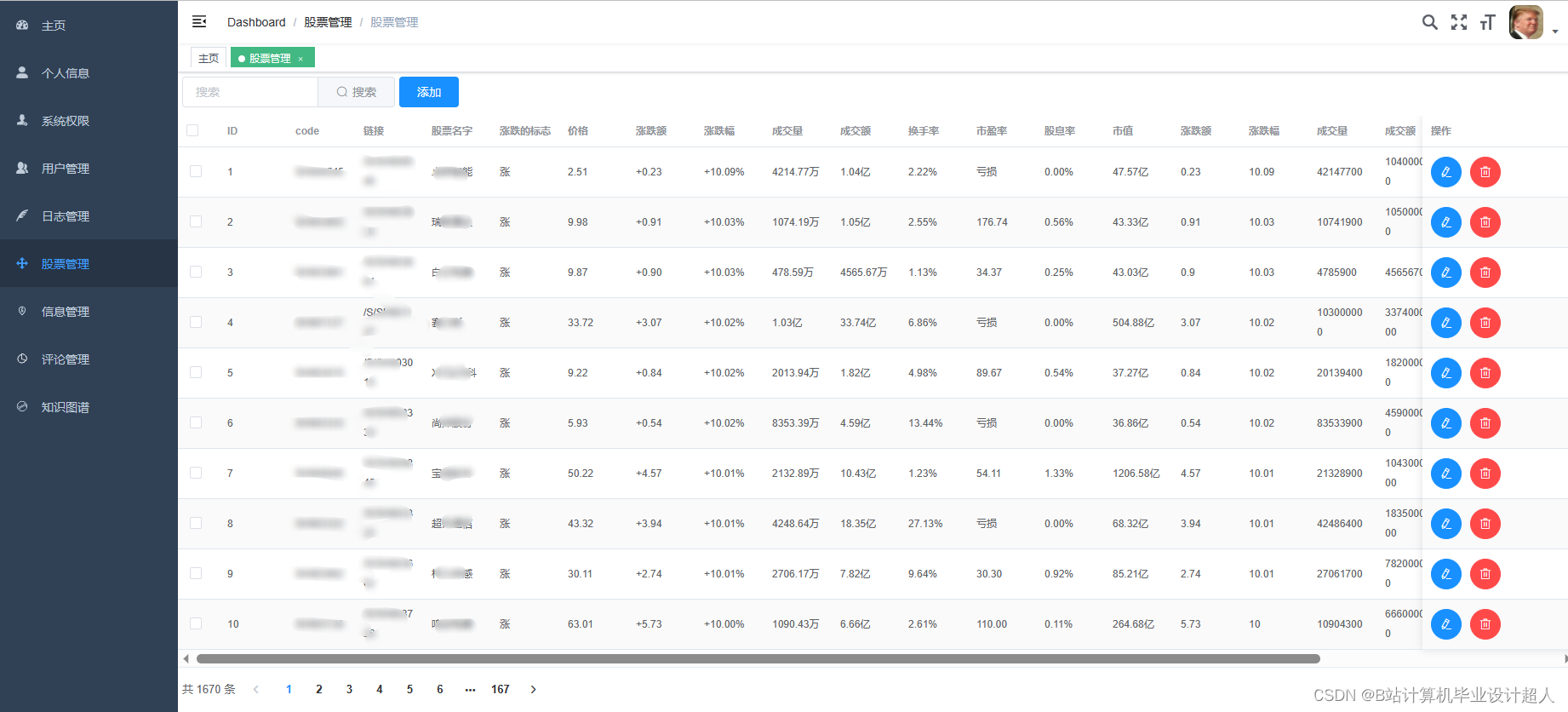
3、管理员功能:个人信息管理,系统管理,用户管理,股票信息管理,评论信息管理

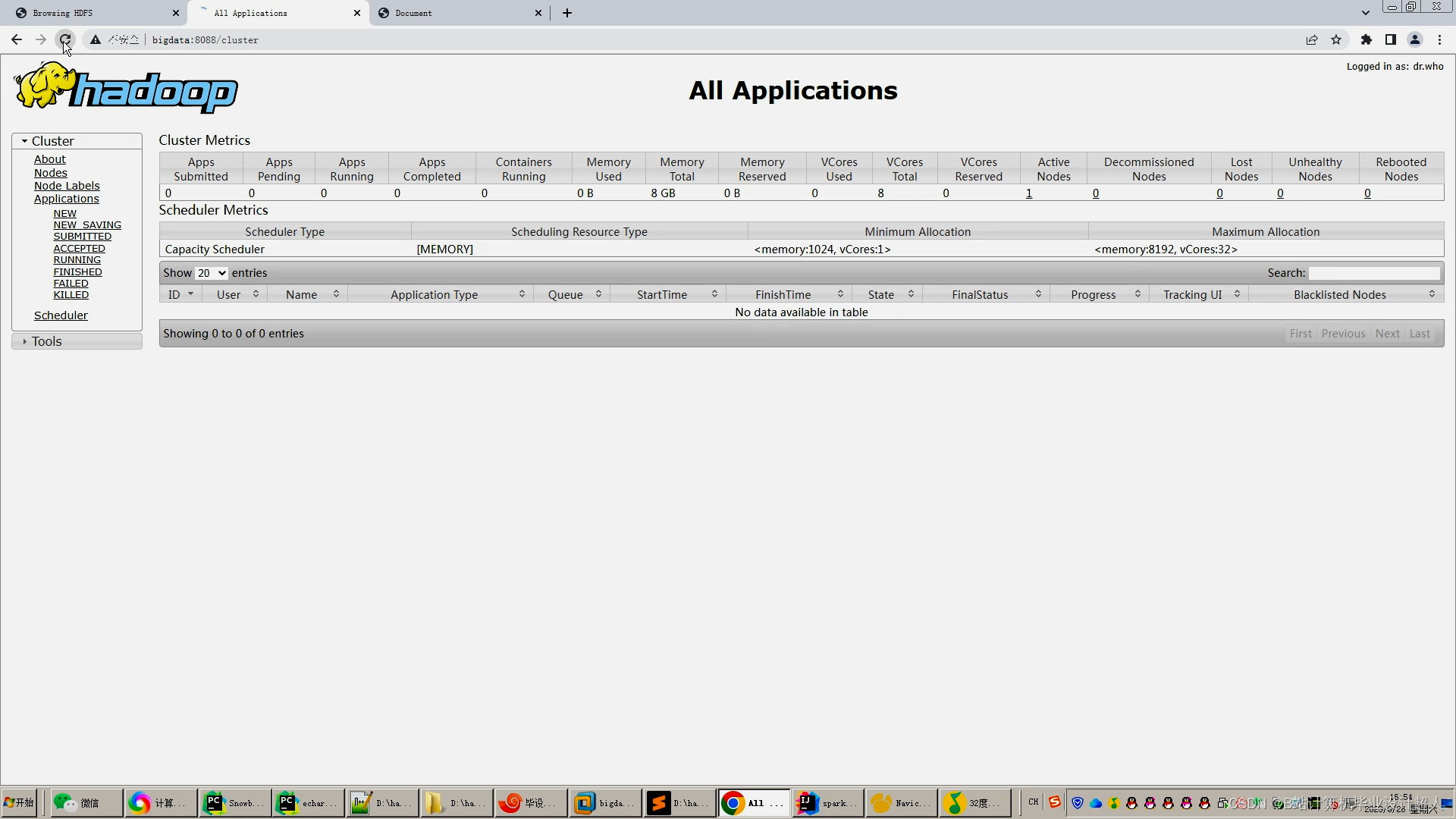
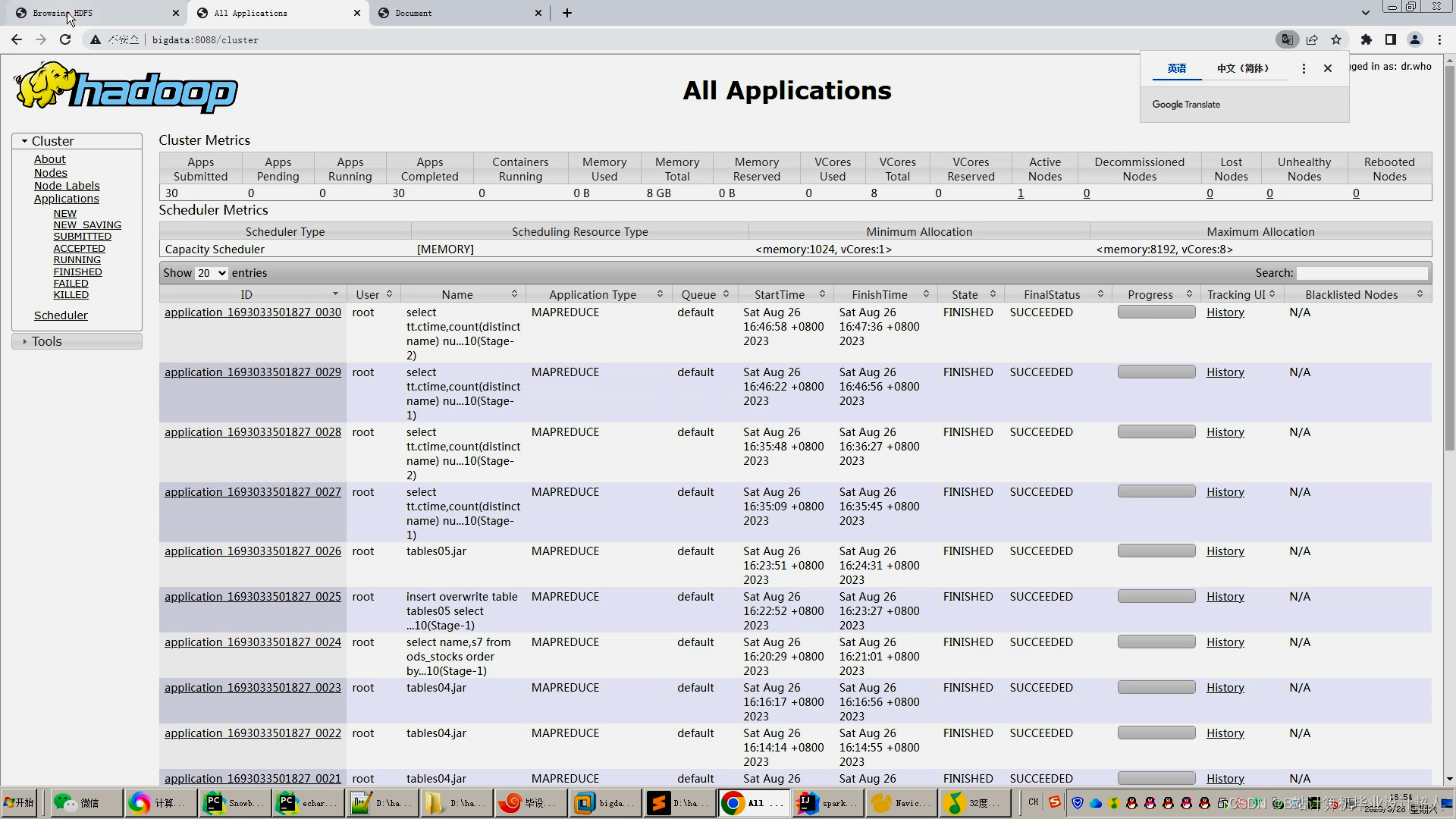
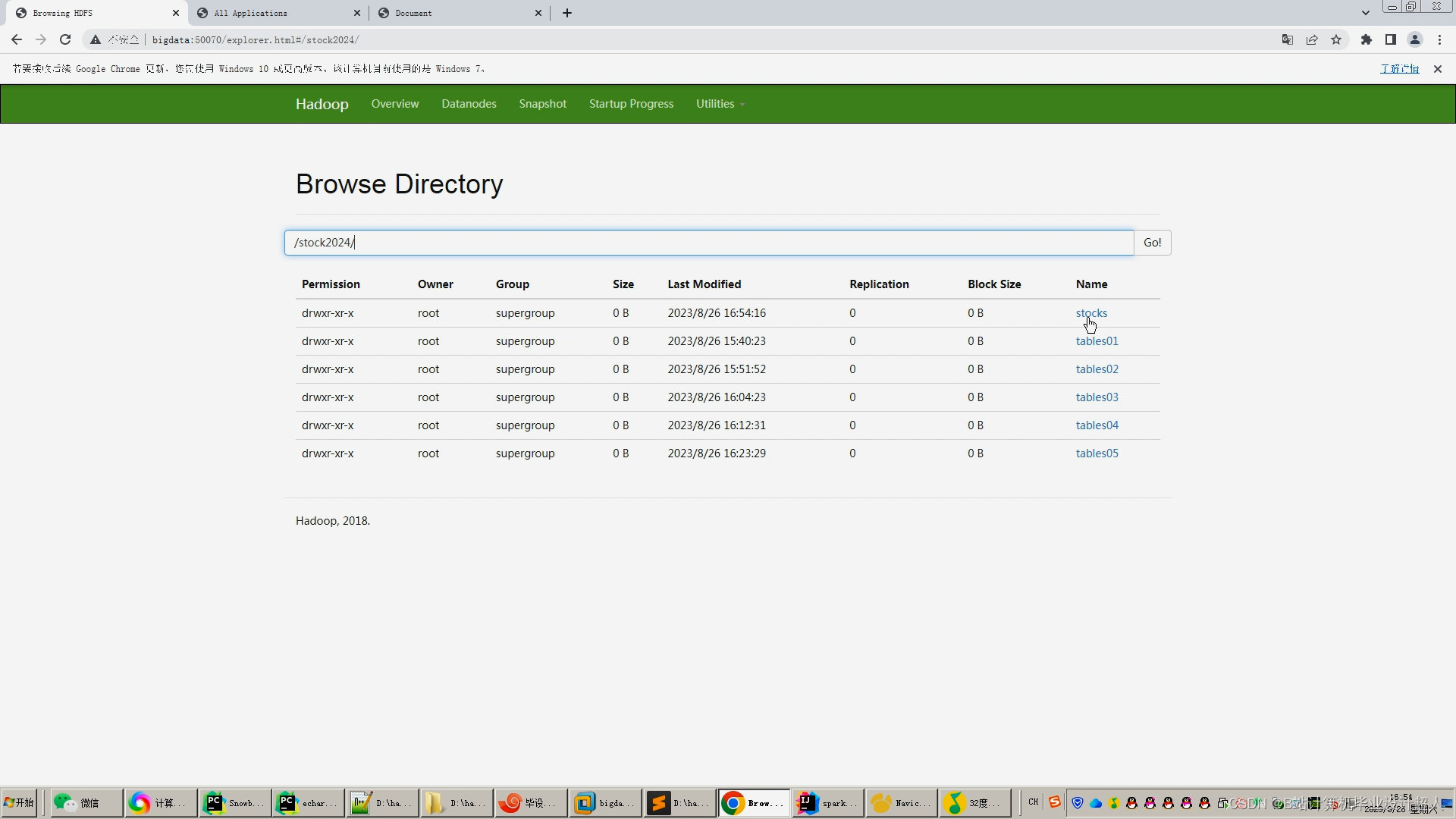
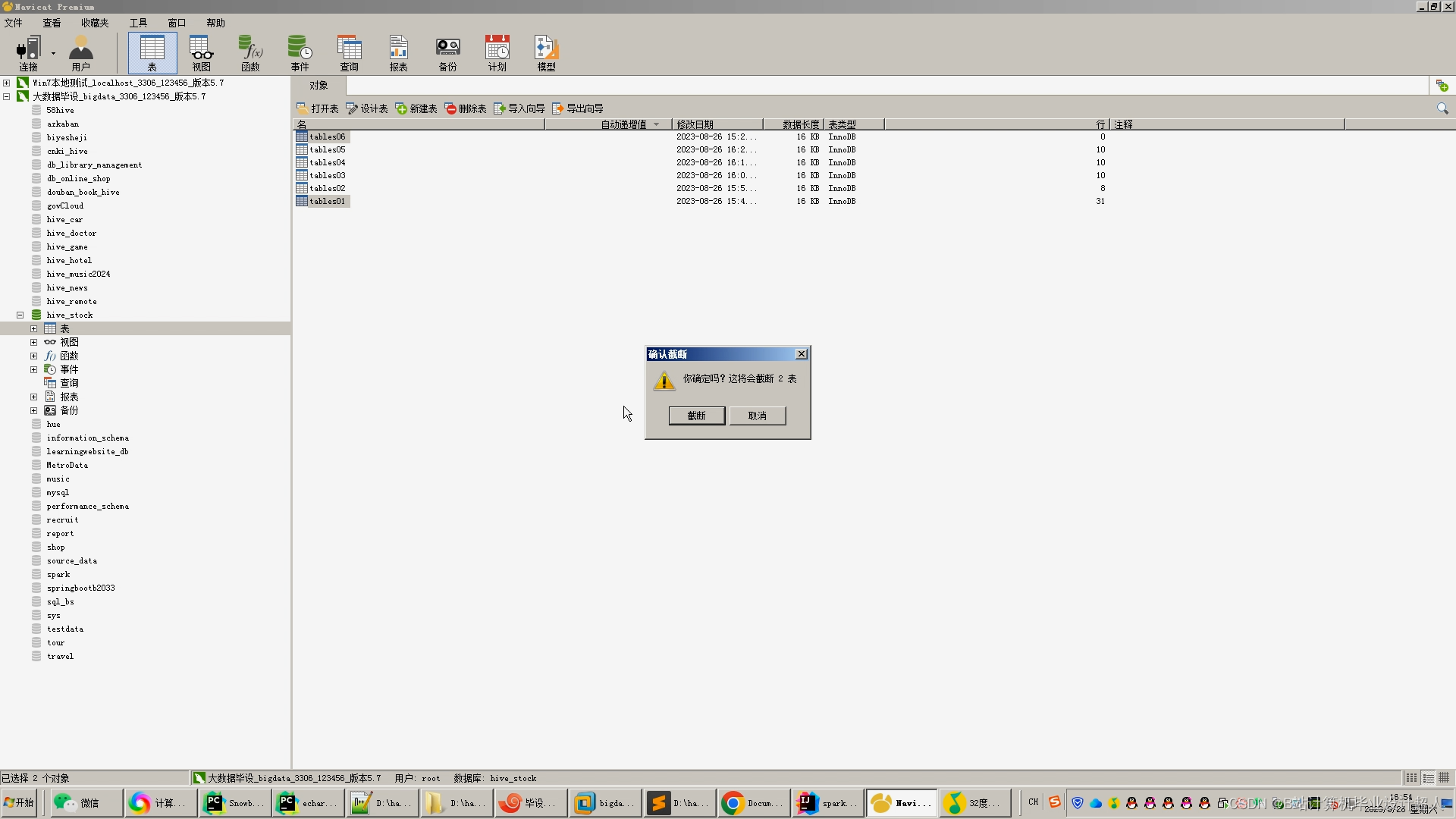
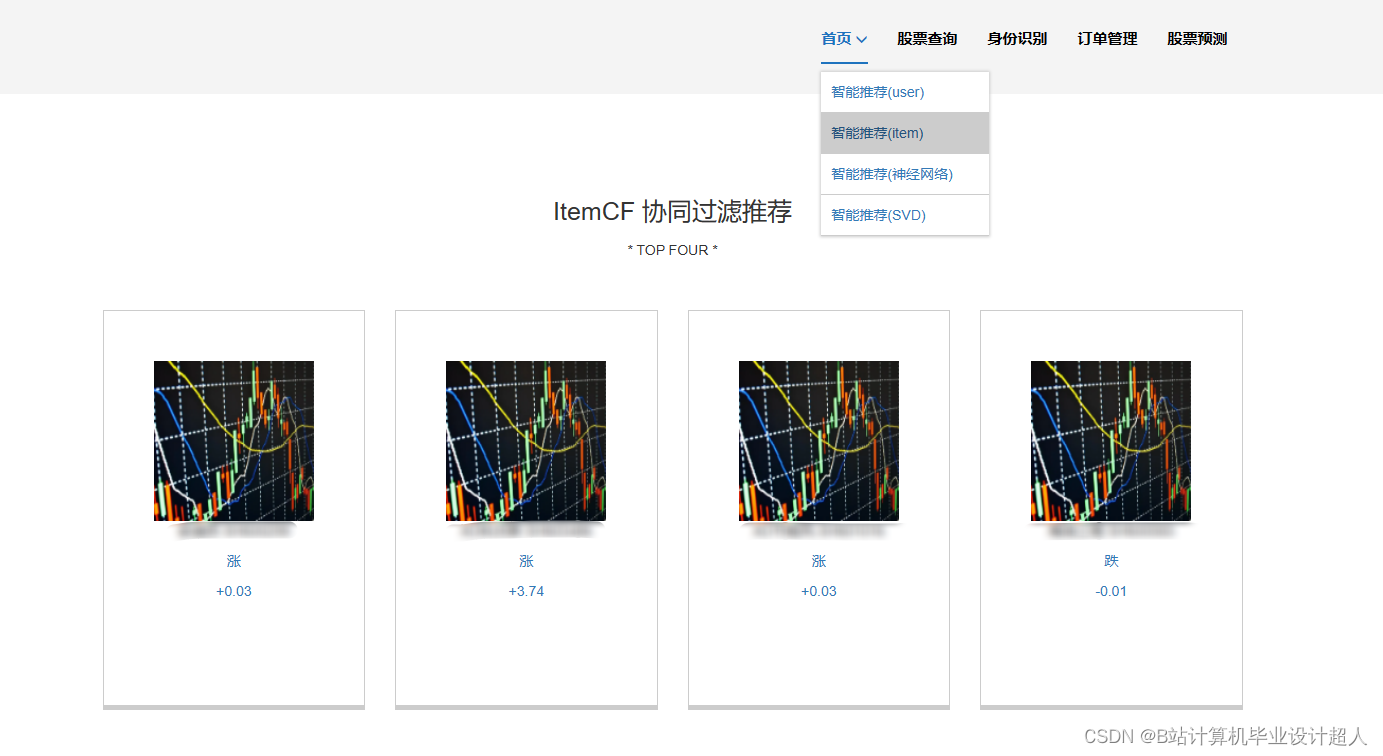
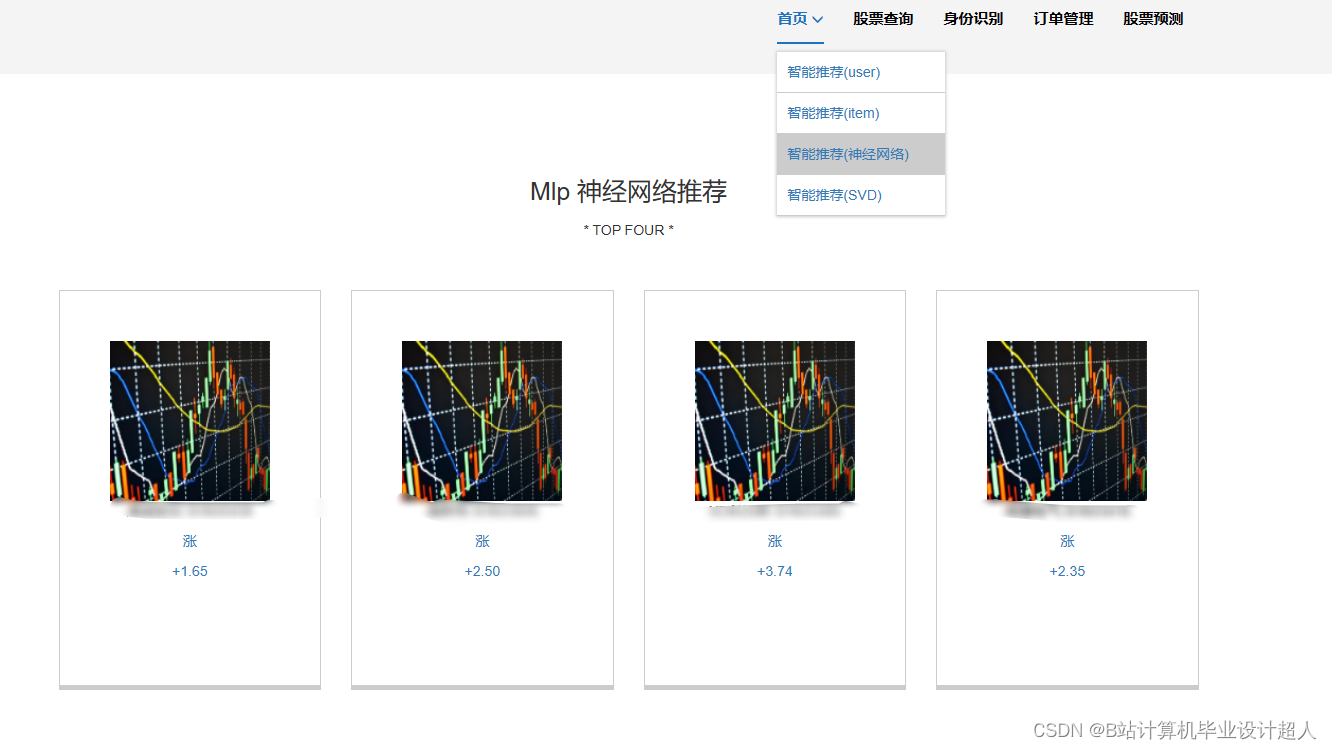
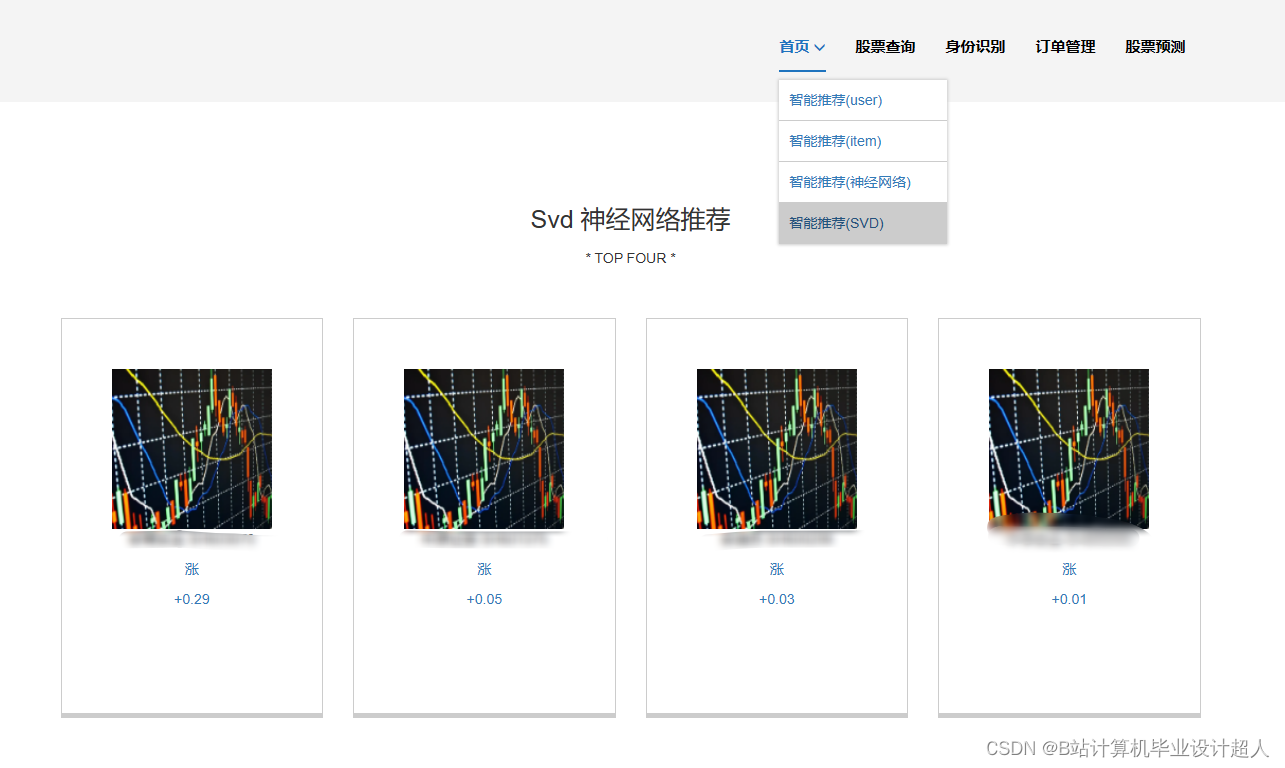
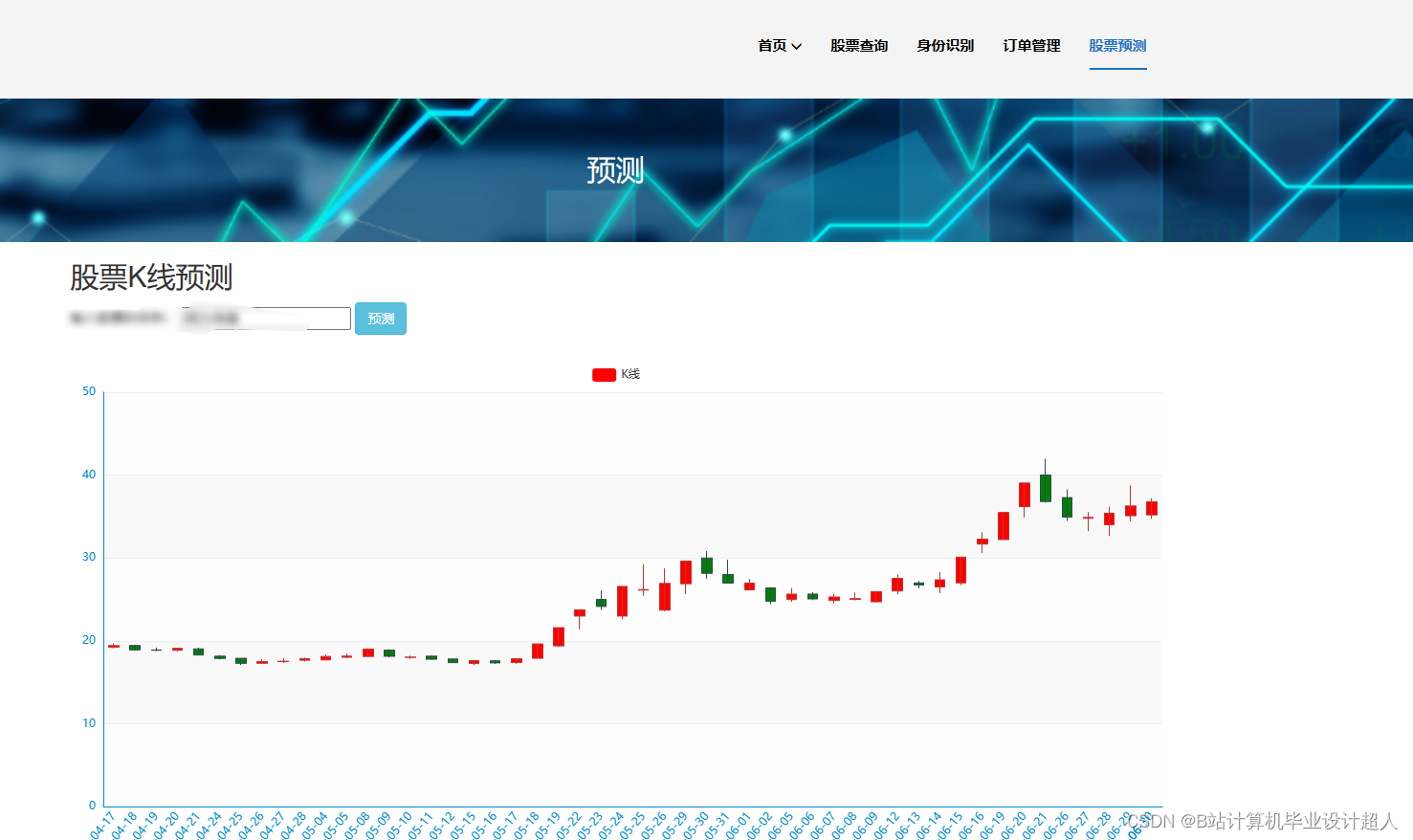
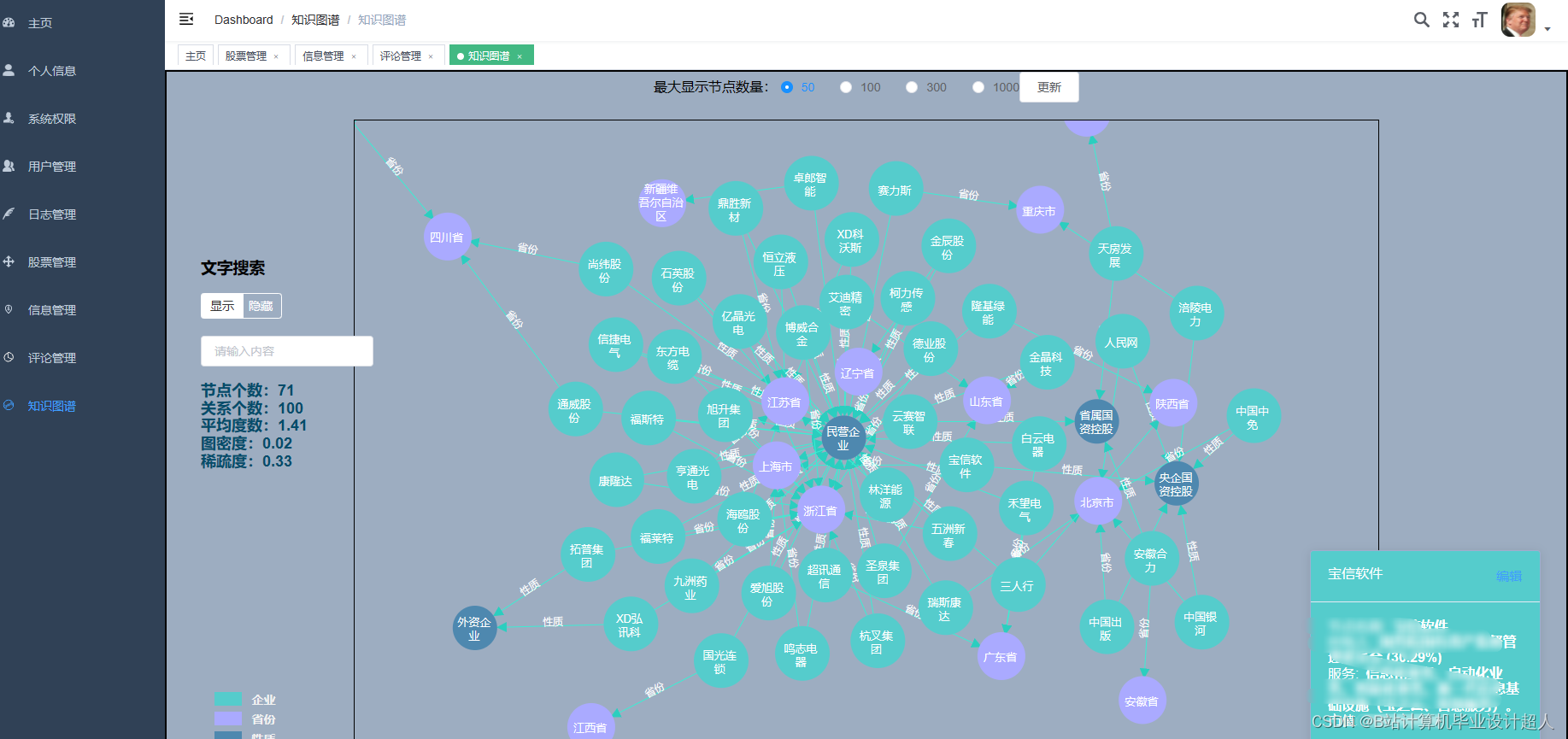
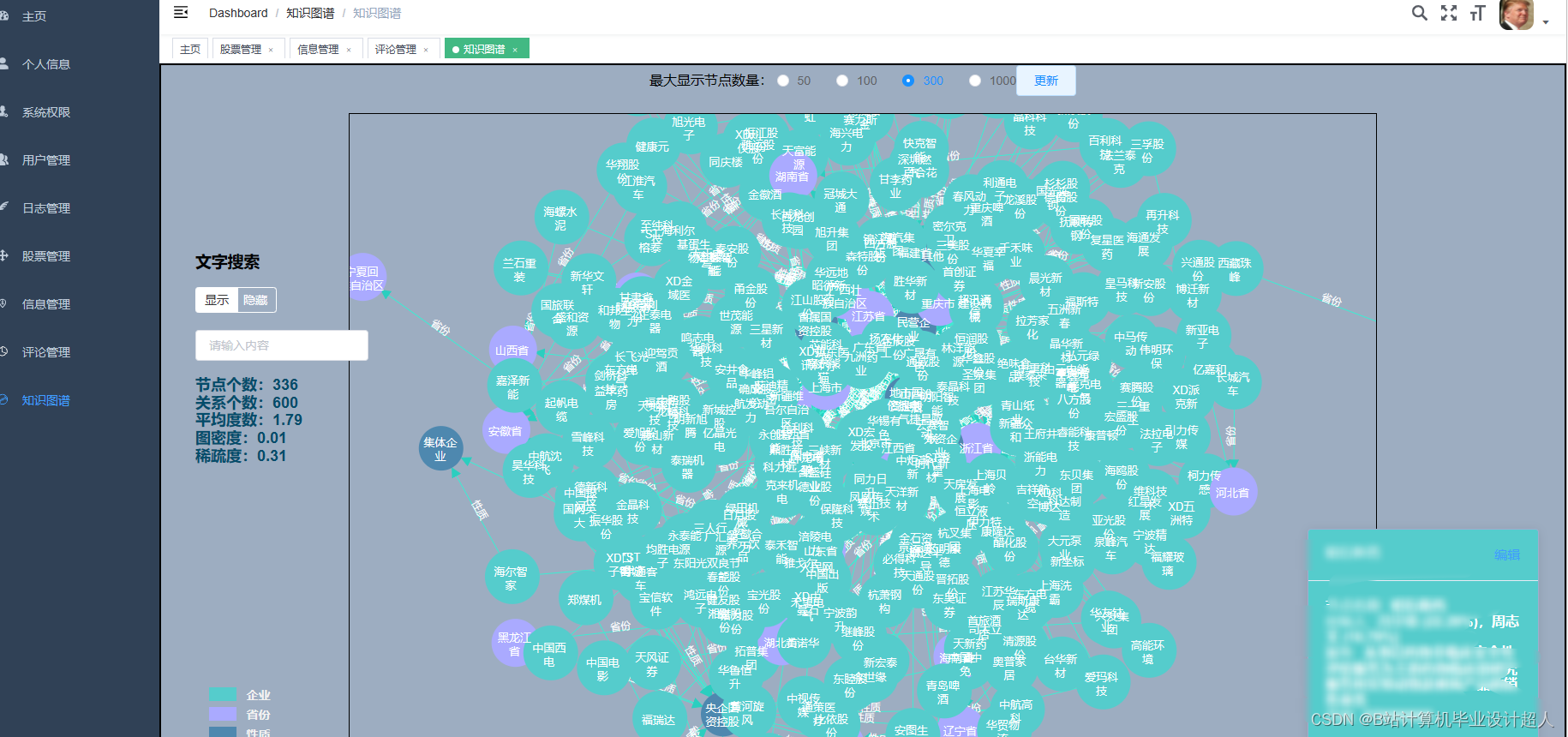

核心代码解析分析如下:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 定义要爬取的股票代码列表
stock_codes = ['000001', '600036', '600519']
# 定义要爬取的股票数据表头
headers = ['股票代码', '股票名称', '收盘价', '涨跌幅']
# 定义爬取数据的URL模板
url_template = 'http://hq.sinajs.cn/list={}'
# 初始化一个空的数据表
data = []
# 循环遍历股票代码列表,爬取对应的数据并保存到data列表中
for code in stock_codes:
url = url_template.format(code)
response = requests.get(url)
soup = BeautifulSoup(response.text, 'lxml')
table = soup.find('table')
rows = table.find_all('tr')
for row in rows:
cols = row.find_all('td')
cols = [element.text.strip() for element in cols]
data.append([code] + cols)
# 将data列表转换为DataFrame格式,并设置表头
df = pd.DataFrame(data, columns=headers)
# 打印数据表
print(df)
永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 5
5 0
0- 0



 已为社区贡献296条内容
已为社区贡献296条内容

所有评论(0)