数据挖掘实践(二):分类之OneR算法
数据挖掘算法之oneR算法实现分类的笔记
分类问题简介
分类是数据挖掘领域最为常用的方法之一。分类应用的目标是,根据已知类别的数据集,经过训练得到一个分类模型,再用模型对类别未知的数据进行分类。例如,我们可以对收到的邮件进行分类,标注哪些是自己希望收到的,哪些是垃圾邮件,然后用这些数据训练分类模型,实现一个垃圾邮件过滤器,这样以后再收到邮件,就不用自己去确认它是不是垃圾邮件了,过滤器就能帮你搞定。
一、准备数据集
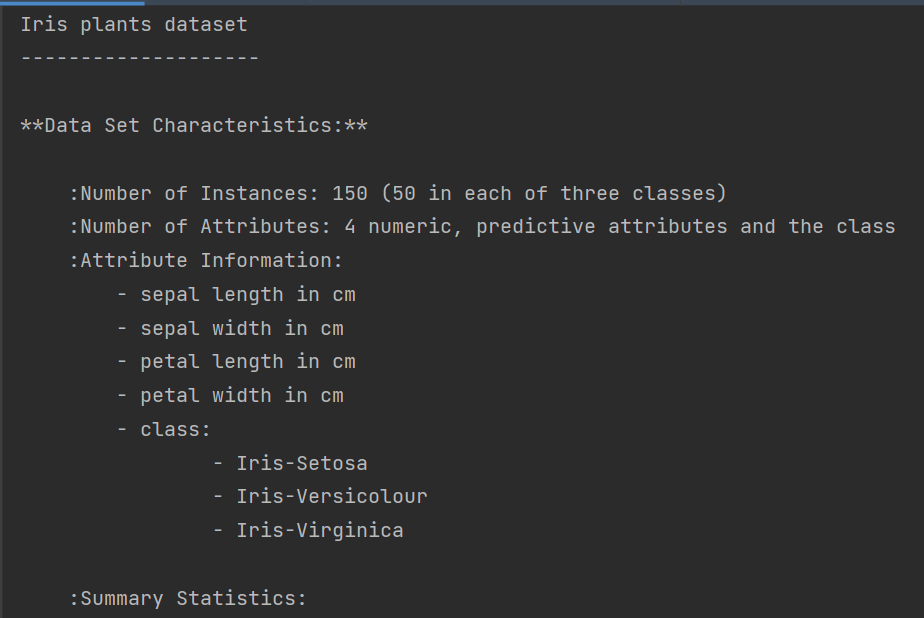
数据集:使用著名的Iris植物分类数据集。这个数据集共有150条植物数据,每条数据都给出了四个特征:sepal length、sepal width、petal length、petal width(分别表示萼片和花瓣的长与宽),单位均为cm。这是数据挖掘中的经典数据集之一。该数据集共有三种类别:Iris Setosa(山鸢尾)、Iris Versicolour(变色鸢尾)和Iris Virginica(维吉尼亚鸢尾)。我们这里的分类目的是根据植物的特征推测它的种类。
1.加载数据集
import numpy as np
from sklearn.datasets import load_iris
dataset = load_iris()
print(dataset.DESCR) # 了解数据集,包括特征
X = dataset.data
y = dataset.target数据集的详细信息:
2.数据离散化
离散化:将连续值转变为类别值。
最简单的离散化算法:确定一个阈值,将低于该阈值的特征值置为0,高于阈值的置为1。可以把某项特征的阈值设定为该特征所有特征值的均值。
接下来,用该方法将数据集打散,把连续的特征值转换为类别型
attribute_means = X.mean(axis=0)
X_d = np.array(X >= attribute_means, dtype='int')二、实现OneR算法
1.OneR算法简介
它根据已有数据中,具有相同特征值的个体最可能属于哪个类别进行分类。(比如对特征1:特征值为0最可能属于A类、B类、C类的哪个类别,特征值为1的最可能属于A类、B类、C类的哪个类别)one rule表示我们只选取四个特征中分类效果最好的一个用作分类依据。
2.OneR算法实现步骤
1)算法首先遍历每个特征的每一个取值,对于每一个特征值,统计它在各个类别中的出现次数,找到它 出现次数最多的类别,并统计它在其他类别中的出现次数。
假如对特征1:特征值为0的100个样本中,属于A类:20个,属于B类:60个,属于C类:20 个。 特征值为1的100个样本中,属于A类:10个,属于B类:20个,属于C类:70个。则对特征1 来说,特征值为0的个体最有可能属于B类,错误率为40/100=40%;特征值为1的个体最有可能属于C类,错误率为30/100=30%;
2)计算其他各特征值最可能属于的类别及错误率
对特征2:特征值为0的错误率:30%,特征值为1的错误率:20%。
对特征3:特征值为0的错误率:20%,特征值为1的错误率:10%。
3)计算每个特征的错误率
方法为把它的各个取值的错误率相加,选取错误率最低的特征作为唯一的分类准则(OneR)
对特征1:70%,特征2:50%,特征3:30%。则选取特征3作为唯一的分类准则。
3.OneR算法的代码实现
(1)创建一个函数,根据某一特征的特征值预测最有可能属于哪个类别,并给出错误率(如上述步骤1)。
# 1.创建一个函数,根据某一特征的特征值预测最有可能属于哪个类别,并给出错误率。
def train_feature_value(X, y_true, feature_index, feature_value): # (数据集,类别数组,选好的特征索引值,特征值)
# 1.1遍历数据集中每一条数据(代表一个个体),统计具有给定特征值的个体在各个类别中的出现次数
class_counts = defaultdict(int)
for sample, y in zip(X, y_true):
if sample[feature_index] == feature_value:
class_counts[y] += 1
# 1.2 对class_counts 进行排序,找到最大值,就能找出具有给定特征值的个体在哪个类别中出现次数最多。
sorted_class_counts = sorted(class_counts.items(), key=itemgetter(1), reverse=True)
most_frequent_class = sorted_class_counts[0][0]
# 1.3计算该条规则错误率
incorrect_predictions = [class_count for class_value, class_count in class_counts.items() if class_value != most_frequent_class]
error = sum(incorrect_predictions)
return most_frequent_class, error # 1.4返回待预测个体的类别和错误率(2)定义一个函数,对于某项特征,遍历其每一个特征值,使用上述函数,就能得到预测结果和每个特征值所带来的错误率,然后把所有错误率累加起来,就能得到该特征的总错误率。(对应上述步骤2,3)
def train_on_feature(X, y_ture,feature_index):
values = set(X[:, feature_index]) # 找出给定特征共有几种不同的取值
predictors = {} # 再创建字典predictors,用作预测器。字典的键为特征值,值为类别。比如键为1.5、值为2,表示特征值为1.5的个体属于类别2
errors = [] # 创建errors列表,存储每个特征值的错误率
for current_value in values:
most_frequent_class, error = train_feature_value(X, y_ture,feature_index, current_value)
predictors[current_value] = most_frequent_class
errors.append(error)
total_error = sum(errors)
return predictors, total_error三、测试算法
-
划分数据集
scikit-learn的切分函数train_test_split,该函数根据设定的比例(默认把数据集的25%作为测试集)将数据集随机切分为两部分。切分函数的第三个参数random_state用来指定切分的随机状态。每次切分,使用相同的随机状态,切分结果相同。(相当于随机种子)。
from sklearn.model_selection import train_test_split
xd_train, xd_test, yd_train, yd_test = train_test_split(X_d, y, random_state=14)-
在训练集上计算所有特征的目标类别(预测器)
all_predictors = {}
errors = {}
for feature_index in range(xd_train.shape[1]):
predictors, total_error = train_on_feature(xd_train, yd_train, feature_index)
all_predictors[feature_index] = predictors
errors[feature_index] = total_error-
找出错误率最低的特征,作为分类的唯一规则
best_feature, best_error = sorted(errors.items(), key=itemgetter(1))[0]-
对预测器进行排序,找到最佳特征值,创建model模型。
model模型是一个字典结构,包含两个元素:用于分类的特征和预测器
model = {'feature': best_feature,
'predictor': all_predictors[best_feature]}-
完成预测
def predict(X_test, model):
variable = model['feature']
predictor = model['predictor']
y_predicted = np.array([predictor[int(sample[variable])] for sample in X_test])
return y_predicted
y_predicted = predict(xd_test, model)
accuracy = np.mean(y_predicted == yd_test) * 100
print("The test accuracy is {:.1f}%".format(accuracy))
输出结果为68%,对于只使用一条规则来说,这就很不错了 !

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)