基于Python的旅游景点数据分析系统设计与实现_基于python的旅游系统
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(
② 传达性:数据库结构被任何人都能理解的语言文档化。
③ 精确性:基于数据模型创建正确标准化的结构。
用于Python之中即是以Python类形式定义数据模型,类中的每一个属性对应着数据库中的一列。引入ORM后,无需编写原生SQL语句,使用基于面向对象的思想去编写类、对象、调用方法等,ORM会将其映射成SQL语句通过pymysql执行。
(2)路由配置(URLConf):Django的URL设置更加灵活优雅,看似复杂难懂,但使用的都是简单的正则表达式,你可以随心所欲的创造优美的、简洁的、专业
的地址。
(3)模板(Template):模板可以理解为承载数据的工具,为了将数据从视图中分离出来,通过各种各样的标签来进行数据的传输。Django的模板融入了面向对象中继承的思想,提高了复用减少冗余代码。
(4)视图(View):视图就是views.py中的函数,也就是逻辑代码,为了将URL和视图关联起来,用到了上述的URLConfs,URLConfs将URL模式映射到视图中,每个视图有两件事是必须要做的:返回一个包含被请求页面的HttpResponse对象,或者抛出一个异常。
(5)后台管理系统(Django-Admin):Django提供的一个基于Web的管理工具。
Django-Admin来自django.contrib也就是Django的标准库,默认被配置好,只需要激活启用即可,它的优势在于可以快速对数据库的各个表进行增删改查,一行代码即可管理一张数据库表,相比于手动后台1个模型一般需要4个urls,4个视图函数和4个模板,可以说Django完成了一个程序编写的大部分重复工作,并且对于图书管理这种以管理工作为重系统来说,极度契合。
(6)应用(Application):当项目规模过大时,难免会产生目录过长,文件过多的问题,Django理念中的App可以将项目相对独立的进行开发,插拔的工作方式和独立性让开发者废弃的App即使删除也不会影响整体,是一种不可多得的理念。
因为本次使用的Python版本为3.6.4,低版本的Django不支持Python3,故此次使用的Django版本为3.2.12。
2.4 Hadoop介绍
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。主要有以下优点:
(1)高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
(2)高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
(3)高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
(4)低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
2.5 Scrapy介绍
Scrapy是一个抓取网站数据和提取结构化数据的框架,它可以应用在广泛的应用中:Scrapy通常用于一系列应用,包括数据挖掘、信息处理或存储历史数据。使用Scrapy框架实现一个爬虫程序通常非常简单,抓取给定网站的内容或图像。
虽然Scrapy是为屏幕抓取(或者更准确地说是网页抓取)而设计的,但它也可以用于访问api以提取数据。
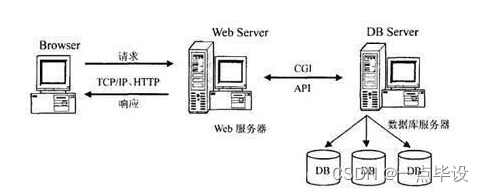
2.6 B/S架构
Browser/Server简称(B/S),即:浏览器/服务器架构模式;属于WEB发展后的所出现的一种网络构造,而WEB又是主要的浏览器应用商品软件。B/S架构模式不仅将系统的重新开发、维修及利用等简单化,更将其重点放到了服务器上。它使客户端得到了统一,在服务器上汇集了系统功能的最核心部分。
B/S架构模式,在服务器接收到浏览器发出请求后将进行对应的回应。Internet上文本、图片、动画等信息主要由Web服务器产生,而用户主要是通过浏览器访问这些信息。在Web上下载程序时遇到某些和数据库相关的指令,可以将这些指令转接到数据库服务器来进行解释和执行。B/S架构工作流程图如图所示:
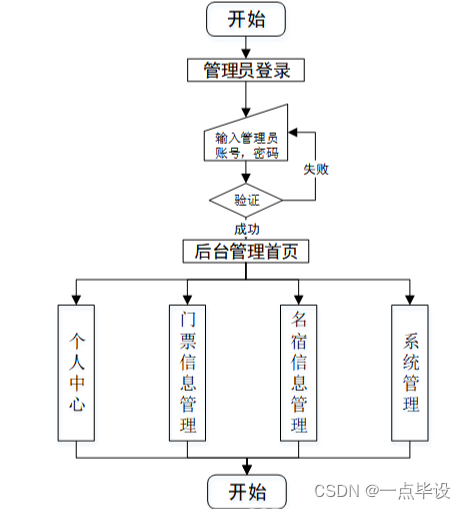
三、功能设计
旅游景点数据分析系统综合网络空间开发设计要求。目的是将传统管理方式转换为在网上管理,完成热门旅游景点数据分析管理的方便快捷、安全性高、交易规范做了保障,目标明确。热门旅游景点数据分析系统功能主要包括个人中心、门票信息管理、名宿信息管理、系统管理等进行管理。
四、数据设计
概念模型的设计是为了抽象真实世界的信息,并对信息世界进行建模。它是数据库设计的强大工具。数据库概念模型设计可以通过E-R图描述现实世界的概念模型。系统的E-R图显示了系统中实体之间的链接。而且Mysql数据库是自我保护能力比较强的数据库,下图主要是对数据库实体的E-R图:
五、部分效果展示
系统登录,在登录页面正确输入用户名和密码后,点击登录进入操作系统进行操作;如图所示。
当人们打开系统的网址后,首先看到的就是首页界面。在这里,人们能够看到系统的导航条,通过导航条导航进入各功能展示页面进行操作。系统首页界面如图所示:
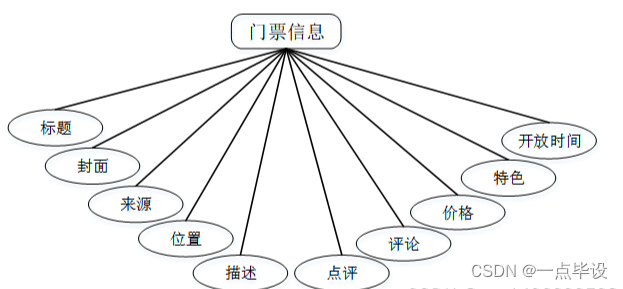
管理员点击门票信息管理。在门票信息页面输入标题和位置进行查询、爬取数据、新增或删除门票信息列表,并根据需要对门票详情信息进行详情、修改或删除操作;如图所示: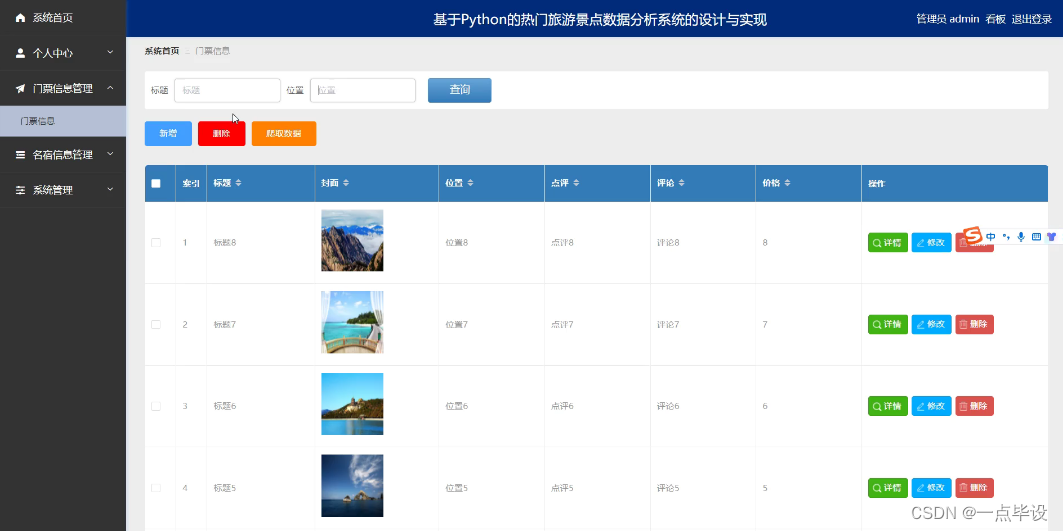
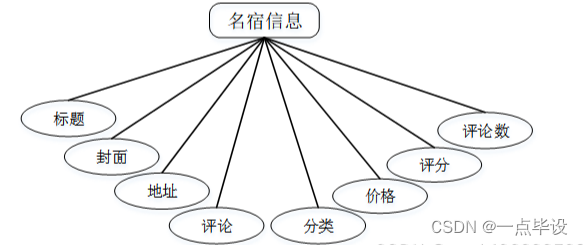
管理员点击名宿信息管理。在名宿信息页面输入标题和地址进行查询、爬取数据、新增或删除名宿信息列表,并根据需要对名宿详情信息进行详情、修改或删除操作;如图所示: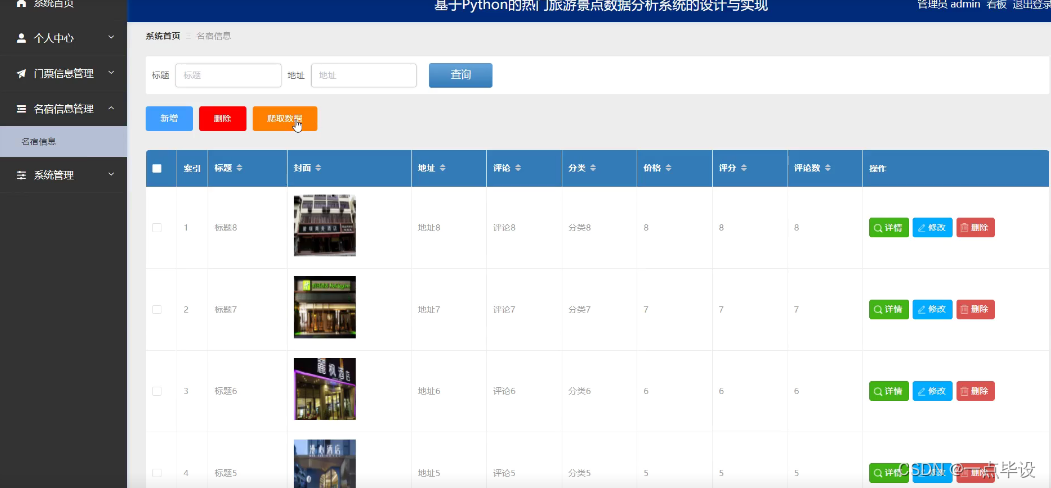
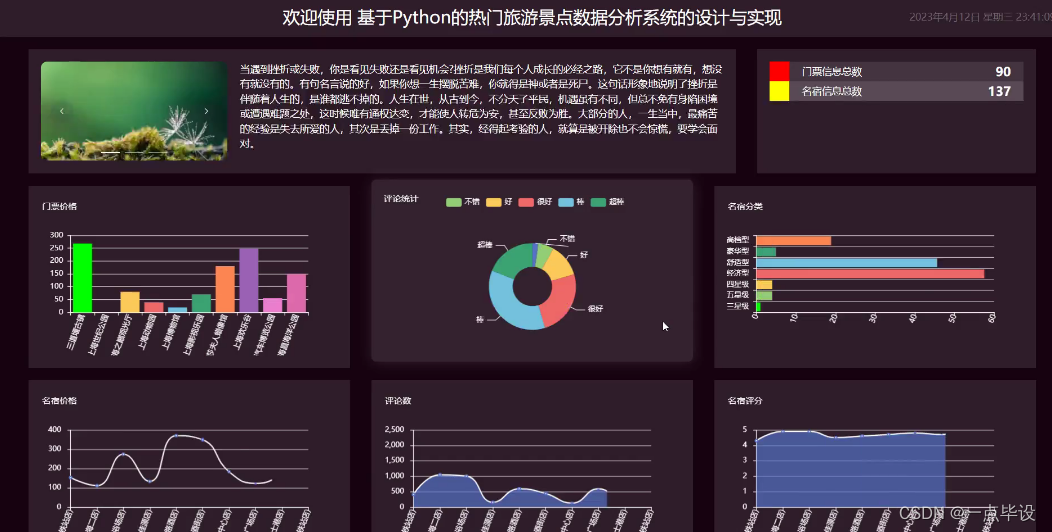
管理员进行爬取数据后,点击主页面右上角的看板,可以查看到系统简介、门票信息管理、名宿信息总数、门票价格、评论统计、名宿分类、名宿价格、评论数、名宿评分等实时的分析图进行可视化管理,可视化大屏展示界面如下图所示:
部分功能代码
# 爬虫
def db\_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table\_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.\*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp\_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `menpiaoxinxi`(
id
,laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
)
select
id
,laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
from `08375\_menpiaoxinxi`
where(not exists (select
id
,laiyuan
,biaoti
,fengmian
,miaoshu
,weizhi
,dianping
,pinglun
,jiage
,tese
,kaifangshijian
from `menpiaoxinxi` where
`menpiaoxinxi`.id=`08375\_menpiaoxinxi`.id
))
limit {0}
'''.format(random.randint(10,15))
cursor.execute(sql)
connect.commit()
connect.close()
#民宿评价
def minsupingjia\_page(request):
'''
'''
if request.method in ["POST", "GET"]:
msg = {"code": normal_code, "msg": mes.normal_code, "data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req\_dict")
global minsupingjia
#获取全部列名
columns= minsupingjia.getallcolumn( minsupingjia, minsupingjia)
#当前登录用户所在表
tablename = request.session.get("tablename")
#authColumn=list(\_\_authTables\_\_.keys())[0]
#authTable=\_\_authTables\_\_.get(authColumn)
# if authTable==tablename:
#params = request.session.get("params")
#req\_dict[authColumn]=params.get(authColumn)
'''\_\_authSeparate\_\_此属性为真,params添加userid,后台只查询个人数据'''
try:
__authSeparate__=minsupingjia.__authSeparate__
except:
__authSeparate__=None
if __authSeparate__=="是":
tablename=request.session.get("tablename")
if tablename!="users" and 'userid' in columns:
try:
req_dict['userid']=request.session.get("params").get("id")
except:
pass
#当项目属性hasMessage为”是”,生成系统自动生成留言板的表messages,同时该表的表属性hasMessage也被设置为”是”,字段包括userid(用户id),username(用户名),content(留言内容),reply(回复)
#接口page需要区分权限,普通用户查看自己的留言和回复记录,管理员查看所有的留言和回复记录
try:
__hasMessage__=minsupingjia.__hasMessage__
except:
__hasMessage__=None
if __hasMessage__=="是":
tablename=request.session.get("tablename")
if tablename!="users":
req_dict["userid"]=request.session.get("params").get("id")
# 判断当前表的表属性isAdmin,为真则是管理员表
# 当表属性isAdmin=”是”,刷出来的用户表也是管理员,即page和list可以查看所有人的考试记录(同时应用于其他表)
__isAdmin__ = None
allModels = apps.get_app_config('main').get_models()
for m in allModels:
if m.__tablename__==tablename:
try:
__isAdmin__ = m.__isAdmin__
except:
__isAdmin__ = None
break
最后

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 44
44 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)