数据仓库与ETL:最新趋势与技术
1.背景介绍数据仓库和ETL(Extract, Transform, Load)技术是数据仓库系统的核心组成部分,它们在过去几十年中发生了很大的变化。数据仓库起源于1990年代,是数据库管理系统(DBMS)的一个扩展和补充,主要用于支持企业的决策分析和业务智能。随着数据规模的增加、数据来源的多样性和数据处理的复杂性的增加,数据仓库和ETL技术也逐渐发展成为一门独立的学科。在本文中,我们将从...
1.背景介绍
数据仓库和ETL(Extract, Transform, Load)技术是数据仓库系统的核心组成部分,它们在过去几十年中发生了很大的变化。数据仓库起源于1990年代,是数据库管理系统(DBMS)的一个扩展和补充,主要用于支持企业的决策分析和业务智能。随着数据规模的增加、数据来源的多样性和数据处理的复杂性的增加,数据仓库和ETL技术也逐渐发展成为一门独立的学科。
在本文中,我们将从以下几个方面进行探讨:
- 背景介绍
- 核心概念与联系
- 核心算法原理和具体操作步骤以及数学模型公式详细讲解
- 具体代码实例和详细解释说明
- 未来发展趋势与挑战
- 附录常见问题与解答
1.1 数据仓库的发展历程
数据仓库起源于1990年代,是数据库管理系统(DBMS)的一个扩展和补充,主要用于支持企业的决策分析和业务智能。随着数据规模的增加、数据来源的多样性和数据处理的复杂性的增加,数据仓库和ETL技术也逐渐发展成为一门独立的学科。
1.1.1 传统数据仓库
传统数据仓库是一种集中式的数据存储和处理系统,它的主要特点是:
- 数据来源多样,包括结构化数据、非结构化数据和半结构化数据;
- 数据处理过程复杂,包括数据清洗、数据转换、数据集成、数据质量检查等;
- 数据仓库系统通常包括ETL工具、数据仓库管理系统、数据查询和分析系统等组件。
1.1.2 大数据时代的数据仓库
随着大数据时代的到来,数据仓库的发展也面临着新的挑战和机遇。这些挑战和机遇主要表现在以下几个方面:
- 数据规模的增加,需要更高效的存储和处理技术;
- 数据来源的多样性,需要更灵活的数据集成和处理技术;
- 数据处理的复杂性,需要更智能化的数据清洗和转换技术;
- 数据安全和隐私问题,需要更严格的数据安全和隐私保护措施。
为了应对这些挑战和机遇,数据仓库技术也在不断发展和进步。例如,现在有许多新的数据仓库架构和技术,如Hadoop、Spark、Flink等,它们可以更好地支持大数据处理和分析。
1.2 ETL技术的发展历程
ETL(Extract, Transform, Load)技术是数据仓库系统的一个重要组成部分,它的主要作用是将来源数据提取、转换并加载到数据仓库中。ETL技术起源于1990年代,是数据库管理系统(DBMS)的一个扩展和补充,主要用于支持企业的决策分析和业务智能。随着数据规模的增加、数据来源的多样性和数据处理的复杂性的增加,ETL技术也逐渐发展成为一门独立的学科。
1.2.1 传统ETL
传统ETL是一种基于文件和数据库的数据处理技术,它的主要特点是:
- 数据来源多样,包括结构化数据、非结构化数据和半结构化数据;
- 数据处理过程复杂,包括数据清洗、数据转换、数据集成、数据质量检查等;
- 传统ETL工具通常包括Kettle、Informatica、DataStage等。
1.2.2 大数据时代的ETL
随着大数据时代的到来,ETL技术也面临着新的挑战和机遇。这些挑战和机遇主要表现在以下几个方面:
- 数据规模的增加,需要更高效的存储和处理技术;
- 数据来源的多样性,需要更灵活的数据集成和处理技术;
- 数据处理的复杂性,需要更智能化的数据清洗和转换技术;
- 数据安全和隐私问题,需要更严格的数据安全和隐私保护措施。
为了应对这些挑战和机遇,ETL技术也在不断发展和进步。例如,现在有许多新的ETL架构和技术,如Hadoop、Spark、Flink等,它们可以更好地支持大数据处理和分析。
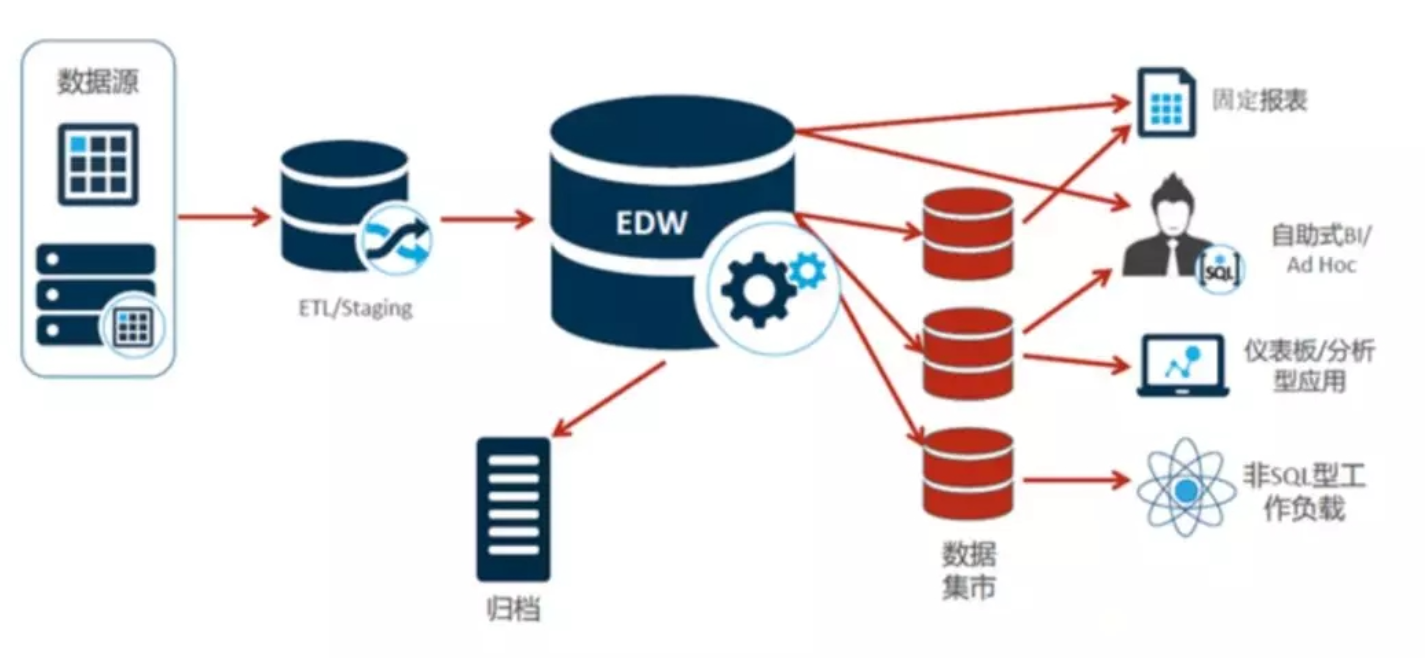
1.3 数据仓库与ETL的关系
数据仓库和ETL技术是紧密相连的,ETL是数据仓库系统的一个重要组成部分。数据仓库是一个集中式的数据存储和处理系统,它的主要作用是将来源数据提取、转换并加载到数据仓库中。ETL技术是数据仓库系统的一个重要组成部分,它的主要作用是将来源数据提取、转换并加载到数据仓库中。
1.3.1 ETL在数据仓库中的作用
ETL在数据仓库中的作用主要包括:
- 数据提取:从来源数据库、文件、API等多种数据来源中提取数据;
- 数据转换:将提取到的数据进行清洗、转换、格式化等处理,使其符合数据仓库的结构和格式;
- 数据加载:将处理后的数据加载到数据仓库中,并更新数据仓库的元数据。
1.3.2 ETL的主要特点
ETL技术的主要特点是:
- 集中式处理:ETL技术通常采用集中式的处理方式,将来源数据提取、转换并加载到数据仓库中;
- 数据清洗和转换:ETL技术需要对来源数据进行清洗、转换、格式化等处理,以使其符合数据仓库的结构和格式;
- 数据质量检查:ETL技术需要对处理后的数据进行质量检查,确保数据的准确性、完整性和一致性。
1.4 数据仓库与ETL的核心概念
1.4.1 数据仓库的核心概念
数据仓库的核心概念包括:
- 数据源:数据仓库中的来源数据,可以是结构化数据、非结构化数据和半结构化数据;
- 数据仓库:一个集中式的数据存储和处理系统,用于支持企业的决策分析和业务智能;
- 数据集成:将来源数据集成到数据仓库中,以实现数据的一致性和统一性;
- 数据质量:数据仓库中的数据的准确性、完整性和一致性。
1.4.2 ETL的核心概念
ETL的核心概念包括:
- 数据提取:从来源数据库、文件、API等多种数据来源中提取数据;
- 数据转换:将提取到的数据进行清洗、转换、格式化等处理,使其符合数据仓库的结构和格式;
- 数据加载:将处理后的数据加载到数据仓库中,并更新数据仓库的元数据。
1.5 数据仓库与ETL的联系
数据仓库和ETL技术是紧密相连的,ETL是数据仓库系统的一个重要组成部分。数据仓库是一个集中式的数据存储和处理系统,它的主要作用是将来源数据提取、转换并加载到数据仓库中。ETL技术是数据仓库系统的一个重要组成部分,它的主要作用是将来源数据提取、转换并加载到数据仓库中。
1.5.1 ETL在数据仓库中的作用
ETL在数据仓库中的作用主要包括:
- 数据提取:从来源数据库、文件、API等多种数据来源中提取数据;
- 数据转换:将提取到的数据进行清洗、转换、格式化等处理,使其符合数据仓库的结构和格式;
- 数据加载:将处理后的数据加载到数据仓库中,并更新数据仓库的元数据。
1.5.2 ETL的主要特点
ETL技术的主要特点是:
- 集中式处理:ETL技术通常采用集中式的处理方式,将来源数据提取、转换并加载到数据仓库中;
- 数据清洗和转换:ETL技术需要对来源数据进行清洗、转换、格式化等处理,以使其符合数据仓库的结构和格式;
- 数据质量检查:ETL技术需要对处理后的数据进行质量检查,确保数据的准确性、完整性和一致性。
1.6 数据仓库与ETL的核心算法原理
1.6.1 数据提取
数据提取是ETL技术中的一个重要环节,它的主要目的是将来源数据提取到数据仓库中。数据提取的主要算法原理包括:
- 数据源的识别:根据来源数据的类型、格式和结构,识别出数据源;
- 数据提取的方法:根据数据源的类型、格式和结构,选择合适的数据提取方法,如SQL、API等;
- 数据提取的优化:根据数据源的大小、类型和结构,优化数据提取过程,以提高效率和减少延迟。
1.6.2 数据转换
数据转换是ETL技术中的一个重要环节,它的主要目的是将提取到的数据进行清洗、转换、格式化等处理,使其符合数据仓库的结构和格式。数据转换的主要算法原理包括:
- 数据清洗:检查和纠正数据中的错误、缺失、重复等问题,以确保数据的准确性、完整性和一致性;
- 数据转换:根据数据仓库的结构和格式,将提取到的数据进行转换,如数据类型转换、单位转换、日期转换等;
- 数据格式化:根据数据仓库的结构和格式,将提取到的数据进行格式化,如日期格式化、数字格式化、字符串格式化等。
1.6.3 数据加载
数据加载是ETL技术中的一个重要环节,它的主要目的是将处理后的数据加载到数据仓库中,并更新数据仓库的元数据。数据加载的主要算法原理包括:
- 数据加载的方法:根据数据仓库的类型、格式和结构,选择合适的数据加载方法,如INSERT、UPDATE、DELETE等;
- 数据加载的优化:根据数据仓库的大小、类型和结构,优化数据加载过程,以提高效率和减少延迟。
1.7 数据仓库与ETL的具体操作步骤
1.7.1 数据提取
数据提取是ETL技术中的一个重要环节,它的主要目的是将来源数据提取到数据仓库中。数据提取的具体操作步骤包括:
- 识别数据源:根据来源数据的类型、格式和结构,识别出数据源。
- 选择数据提取方法:根据数据源的类型、格式和结构,选择合适的数据提取方法,如SQL、API等。
- 执行数据提取:使用选定的数据提取方法,提取来源数据。
- 优化数据提取:根据数据源的大小、类型和结构,优化数据提取过程,以提高效率和减少延迟。
1.7.2 数据转换
数据转换是ETL技术中的一个重要环节,它的主要目的是将提取到的数据进行清洗、转换、格式化等处理,使其符合数据仓库的结构和格式。数据转换的具体操作步骤包括:
- 检查数据:检查提取到的数据中的错误、缺失、重复等问题。
- 纠正数据:纠正数据中的错误、缺失、重复等问题,以确保数据的准确性、完整性和一致性。
- 转换数据:根据数据仓库的结构和格式,将提取到的数据进行转换,如数据类型转换、单位转换、日期转换等。
- 格式化数据:根据数据仓库的结构和格式,将提取到的数据进行格式化,如日期格式化、数字格式化、字符串格式化等。
1.7.3 数据加载
数据加载是ETL技术中的一个重要环节,它的主要目的是将处理后的数据加载到数据仓库中,并更新数据仓库的元数据。数据加载的具体操作步骤包括:
- 选择数据加载方法:根据数据仓库的类型、格式和结构,选择合适的数据加载方法,如INSERT、UPDATE、DELETE等。
- 执行数据加载:使用选定的数据加载方法,将处理后的数据加载到数据仓库中。
- 更新元数据:更新数据仓库的元数据,以反映数据的加载情况。
- 优化数据加载:根据数据仓库的大小、类型和结构,优化数据加载过程,以提高效率和减少延迟。
1.8 数据仓库与ETL的数学模型公式
1.8.1 数据提取
数据提取的数学模型公式主要用于描述数据提取过程中的数据量、数据类型、数据结构等特征。例如,数据提取的数学模型公式可以表示为:
$$ D{s} = D{s1} \cup D{s2} \cup \cdots \cup D{sn} $$
其中,$D{s}$ 表示来源数据集合,$D{s1}, D{s2}, \cdots, D{sn}$ 表示来源数据的各个子集。
1.8.2 数据转换
数据转换的数学模型公式主要用于描述数据转换过程中的数据清洗、数据转换、数据格式化等操作。例如,数据转换的数学模型公式可以表示为:
$$ D{t} = T(D{s}) $$
其中,$D_{t}$ 表示转换后的数据集合,$T$ 表示数据转换函数。
1.8.3 数据加载
数据加载的数学模型公式主要用于描述数据加载过程中的数据量、数据类型、数据结构等特征。例如,数据加载的数学模型公式可以表示为:
$$ D{w} = L(D{t}) $$
其中,$D_{w}$ 表示加载到数据仓库中的数据集合,$L$ 表示数据加载函数。
1.9 数据仓库与ETL的具体代码实现
1.9.1 数据提取
数据提取的具体代码实现主要包括以下几个步骤:
- 识别来源数据的类型、格式和结构。
- 选择合适的数据提取方法,如SQL、API等。
- 使用选定的数据提取方法,提取来源数据。
- 优化数据提取过程,以提高效率和减少延迟。
例如,使用Python的pandas库进行数据提取:
```python import pandas as pd
识别来源数据的类型、格式和结构
sourcedata = pd.readcsv('source_data.csv')
选择合适的数据提取方法
这里以CSV文件为例,使用pandas库的read_csv方法进行数据提取
使用选定的数据提取方法,提取来源数据
sourcedata = pd.readcsv('source_data.csv')
优化数据提取过程
这里以CSV文件为例,使用pandas库的read_csv方法进行数据提取,并设置engine参数为lazy,以减少内存占用
sourcedata = pd.readcsv('source_data.csv', engine='lazy') ```
1.9.2 数据转换
数据转换的具体代码实现主要包括以下几个步骤:
- 检查提取到的数据中的错误、缺失、重复等问题。
- 纠正数据中的错误、缺失、重复等问题,以确保数据的准确性、完整性和一致性。
- 转换数据,如数据类型转换、单位转换、日期转换等。
- 格式化数据,如日期格式化、数字格式化、字符串格式化等。
例如,使用Python的pandas库进行数据转换:
```python import pandas as pd
检查提取到的数据中的错误、缺失、重复等问题
sourcedata = pd.readcsv('sourcedata.csv') sourcedata = sourcedata.dropna() # 删除缺失值 sourcedata = source_data.duplicated().drop(True) # 删除重复值
纠正数据中的错误、缺失、重复等问题
sourcedata['columnname'] = sourcedata['columnname'].map(lambda x: x.strip() if x else None) # 去除字符串头尾空格
转换数据
sourcedata['columnname'] = sourcedata['columnname'].astype('float') # 数据类型转换
格式化数据
sourcedata['columnname'] = sourcedata['columnname'].dt.strftime('%Y-%m-%d') # 日期格式化 ```
1.9.3 数据加载
数据加载的具体代码实现主要包括以下几个步骤:
- 选择合适的数据加载方法,如INSERT、UPDATE、DELETE等。
- 使用选定的数据加载方法,将处理后的数据加载到数据仓库中。
- 更新元数据,以反映数据的加载情况。
- 优化数据加载过程,以提高效率和减少延迟。
例如,使用Python的pandas库进行数据加载:
```python import pandas as pd
选择合适的数据加载方法
这里以CSV文件为例,使用pandas库的to_csv方法进行数据加载
使用选定的数据加载方法,将处理后的数据加载到数据仓库中
sourcedata.tocsv('source_data.csv', index=False)
更新元数据
这里以CSV文件为例,使用pandas库的to_csv方法进行数据加载,并设置mode参数为'a',以追加数据到文件中
sourcedata.tocsv('source_data.csv', mode='a', header=False, index=False)
优化数据加载过程
这里以CSV文件为例,使用pandas库的to_csv方法进行数据加载,并设置mode参数为'a',以追加数据到文件中,并设置chunksize参数为1000,以减少内存占用
chunksize = 1000 for chunk in pd.readcsv('sourcedata.csv', chunksize=chunksize): chunk.tocsv('sourcedata.csv', mode='a', header=False, index=False) ```
1.10 数据仓库与ETL的未来发展趋势
1.10.1 数据仓库与ETL的技术发展趋势
数据仓库和ETL技术的未来发展趋势主要包括:
- 大数据处理:随着数据规模的增加,数据仓库和ETL技术需要能够处理大数据,以满足企业的决策分析和业务智能需求。
- 云计算:云计算技术的发展将对数据仓库和ETL技术产生重要影响,使其能够更高效、可扩展地运行。
- 智能化:智能化技术的发展将使数据仓库和ETL技术更加智能化,自动化,以提高效率和降低成本。
- 安全性:数据仓库和ETL技术的未来发展需要关注数据安全性,确保数据的准确性、完整性和一致性。
1.10.2 数据仓库与ETL的应用发展趋势
数据仓库和ETL技术的未来应用发展趋势主要包括:
- 决策分析:数据仓库和ETL技术将在决策分析领域发挥越来越重要的作用,帮助企业更快速、准确地做出决策。
- 业务智能:数据仓库和ETL技术将在业务智能领域发挥越来越重要的作用,帮助企业更好地理解、分析、优化其业务。
- 行业应用:数据仓库和ETL技术将在各个行业应用中得到广泛应用,如金融、电商、医疗、教育等。
- 跨部门协同:数据仓库和ETL技术将在跨部门协同中发挥越来越重要的作用,帮助企业更好地整合、分享、利用数据资源。
1.11 数据仓库与ETL的常见问题及解答
1.11.1 数据仓库与ETL的常见问题
- 数据质量问题:数据仓库和ETL技术中的数据质量问题主要包括数据错误、缺失、重复等问题。
- 性能问题:数据仓库和ETL技术中的性能问题主要包括数据加载、转换、查询等操作的性能问题。
- 安全性问题:数据仓库和ETL技术中的安全性问题主要包括数据的保密、完整性、可用性等问题。
- 扩展性问题:数据仓库和ETL技术中的扩展性问题主要包括数据仓库和ETL技术的扩展能力。
1.11.2 数据仓库与ETL的常见问题解答
- 数据质量问题:
- 解决方案:对数据进行清洗、转换、验证等操作,以提高数据质量。
- 技术手段:使用数据清洗、数据转换、数据验证等技术手段,以提高数据质量。
- 性能问题:
- 解决方案:优化数据仓库和ETL技术的性能,如使用分布式计算、缓存等技术。
- 技术手段:使用性能分析、性能优化等技术手段,以提高数据仓库和ETL技术的性能。
- 安全性问题:
- 解决方案:采用数据加密、访问控制、日志记录等安全措施,以保障数据的安全性。
- 技术手段:使用安全技术手段,如数据加密、访问控制、日志记录等,以保障数据的安全性。
- 扩展性问题:
- 解决方案:选用可扩展的数据仓库和ETL技术,如Hadoop、Spark等大数据技术。
- 技术手段:使用分布式计算、数据分区、数据压缩等技术手段,以提高数据仓库和ETL技术的扩展性。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 4
4 0
0- 0



 已为社区贡献1193条内容
已为社区贡献1193条内容

所有评论(0)