【文档笔记】doris数据仓库-数据表设计:Rollup 与查询
Rollup 可以理解为 Table 的一个物化索引结构。物化 是因为其数据在物理上独立存储,而 索引 的意思是,Rollup可以调整列顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
基本概念
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
Rollup 可以理解为 Table 的一个物化索引结构。物化 是因为其数据在物理上独立存储,而 索引 的意思是,Rollup可以调整列顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
Aggregate 和 Unique 模型中的 ROLLUP
假设base表如下: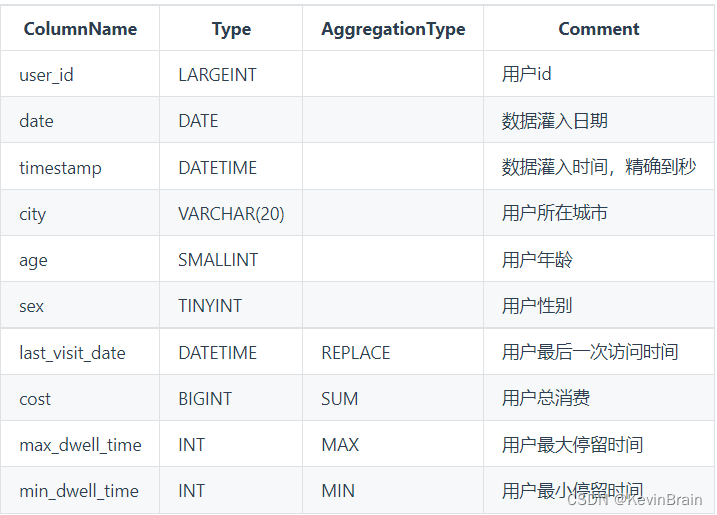
存储的数据如下: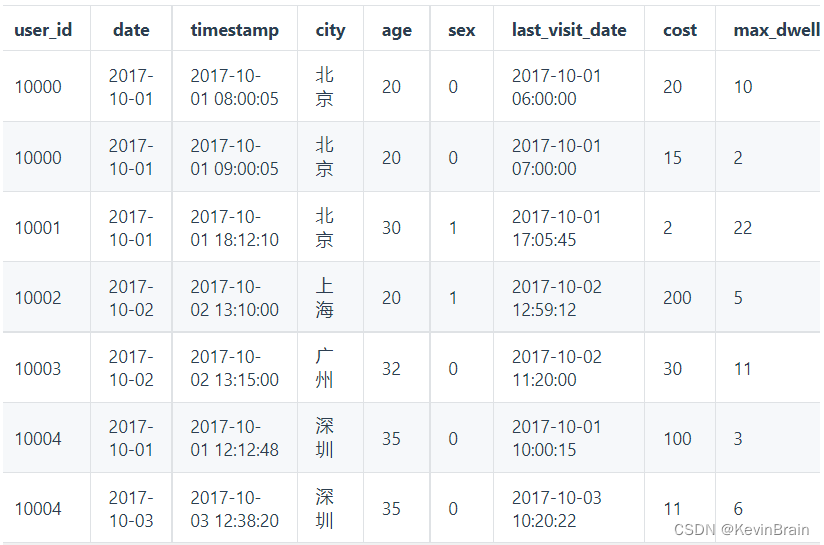
在此基础上,我们创建一个 ROLLUP:
ALTER TABLE table1 ADD ROLLUP rollup_city(user_id, cost);
该 ROLLUP 只包含两列:user_id 和 cost。则创建完成后,该 ROLLUP 中存储的数据如下: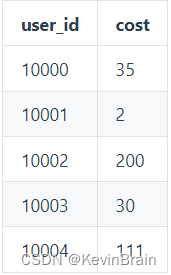
可以看到,ROLLUP 中仅保留了每个 user_id,在 cost 列上的 SUM 的结果。那么当我们进行如下查询时:
SELECT user_id, sum(cost) FROM table GROUP BY user_id;
Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷”这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。
ROLLUP使用说明
ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此 ROLLUP 的含义已经超出了 “上卷” 的范围。这也是为什么我们在源代码中,将其命名为 Materialized Index(物化索引)的原因。
ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
ROLLUP 的数据更新与 Base 表是完全同步的。用户无需关心这个问题。
ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。
某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP。具体参见接下来的 聚合模型的局限性 一节。
可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP。
原文地址:https://doris.apache.org/zh-CN/data-table/hit-the-rollup.html#%E5%9F%BA%E6%9C%AC%E6%A6%82%E5%BF%B5

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)