
大数据案例--网站流量项目(上)
一、网站流量统计项目概述1、项目背景网站流量统计是改进网站服务的重要手段之一,通过获取用户在网站的行为,可以分析出哪些内容受到欢迎,哪些页面存在问题,从而使网站改进活动更具有针对性。2、统计指标说明常用的网站流量统计指标一般包括以下情况分析:①、按在线情况分析在线情况分析分别记录在线用户的活动信息,包括:来访时间、访客地域、来路页面、当前停留页面等,这些功能对企业实时掌握自身网站流量有很大的帮助。
目录
一、网站流量统计项目概述
1、项目背景
网站流量统计是改进网站服务的重要手段之一,通过获取用户在网站的行为,可以分析出哪些内容受到欢迎,哪些页面存在问题,从而使网站改进活动更具有针对性。
2、统计指标说明
常用的网站流量统计指标一般包括以下情况分析:
①、按在线情况分析
在线情况分析分别记录在线用户的活动信息,包括:来访时间、访客地域、来路页面、当前停留页面等,这些功能对企业实时掌握自身网站流量有很大的帮助。
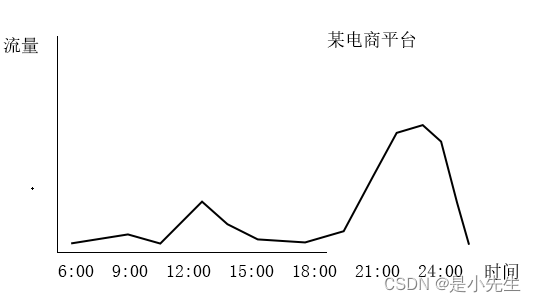
②、按时间段分析
时段分析提供网站任意时间内的流量变化情况.或者某一段时间到某一段时间的流量变化,比如小时段分布,日访问量分布,对于企业了解用户浏览网页的的时间段有一个很好的分析。
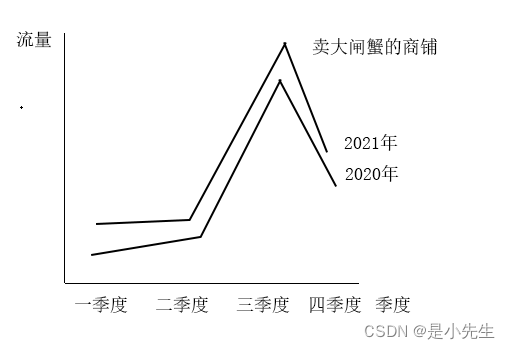
③、按来源分析
来源分析提供来路域名带来的来访次数、IP、独立访客、新访客、新访客浏览次数、站内总浏览次数等数据。这个数据可以直接让企业了解推广成效的来路,从而分析出那些网站投放的广告效果更明显。
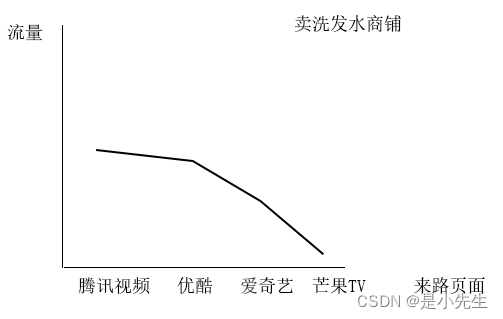
④、按访客地区分析

本项目的8个指标:
1、PV-PageView
页面访问量,也是常说的流量。用户点击一次页面,就算作一个PV,包括刷新操作也算
2、UV-Unique Visitor
独立访客数量。是按不同的用户来统计的。
实现思路:
①、当一个新用户初次访问网站时,网站后台会为此用户生成一个唯一的标识id(uvid)
②、将uvid存到用户浏览器的cookie中
③、后续用户再次访问网站时,会携带cookie中的信息(uvid)
④、后台可以根据uvid来统计uv
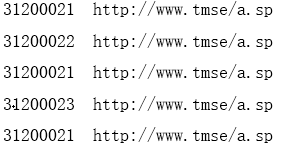
比如,某网站当前的流量数据:
则当天总的pv=5 总的uv=3
3、VV-Vistor View
独立会话数量。统计有多少个不同的Session会话数量
产生Session会话的场景:
①、关闭浏览器,再次打开会产生一个新会话
②、超过了指定的会话操作超时时间(比如30分钟),再次操作会产生新会话
实现思路:
①、每当产生一个新Session会话时,网站后台会为此会话生成一个唯一标识(ssid)
②、将ssid存到用户浏览器的cookie中
③、后续用户再次点击访问时,会携带cookie中的ssid
④、根据ssid来统计vv数量
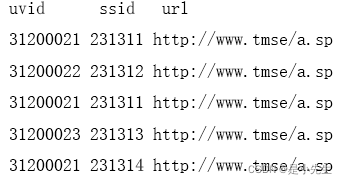
比如,某网站当天的流量数据:
则当天总的pv=5 总的uv=3 总的vv=4
4、BR-Bounced Rate
页面跳出率,BR=总的跳出会话数量/总的会话数量(vv)
跳出会话指的是:对目标网站只有一次访问记录的会话,就是一个跳出会话
比如,某网站当天的流量数据:
则当天总的pv=5 总的uv=3 总的vv=4 总的跳出会话=3 br=3/4=0.75
BR一般用于衡量网站质量的优良性。如果BR高,则说明网站对用户的吸引力低

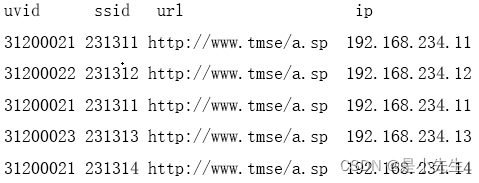
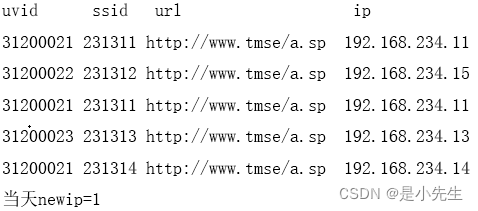
5、NewIp
新增ip数量,统计当前有那些ip在以往的数据中从未出现过的ip数量(这样的ip是新增ip)
比如,某网站当天的流量数据:
历史数据:
当天数据:
6、NewCust
新增用户数。统计当天有哪些用户(uvid)在历史数据中从未出现过的数量。处理思路同newip,判断指标更换为以uvid来统计判断
7、AvgDeep
平均会话访问深度
AvgDeep=总的会话访问深度/总的会话数量(vv)
会话访问深度指的是:一个会话浏览多少个不同的访问地址
比如:
AvgDeep=(3+2)/2=2.5

8、AvgTime
平均的会话访问时长
AvgTime=总的会话时长/总的会话数量(vv)
比如:
统计会话在页面的停留时长,处理方式:记录点击打开页面的时间戳。
所以要统计一个会话的总时长:此会话最大时间戳-此会话最小时间戳
补充:AvgTime得到的结果一般会小于真实结果。因为最后一个页面的停留时长获取不到

二、数据的埋点和采集
1、概述
所谓埋点就是在应用中特定的流程收集一些信息,用来跟踪应用使用的状况,后续用来进一步优化产品或是提供运营的数据支撑,即通过数据埋点来采集数据,比如采集:访问(Vistis),访客(Vistor),停留时间(Time On Site),页面查看(Page Views,又称为页面浏览)和跳出率(Bounce Rate,又可称为蹦失率)等等
一个典型的数据平台,对于数据的处理,是由如下的5个步骤组成的:
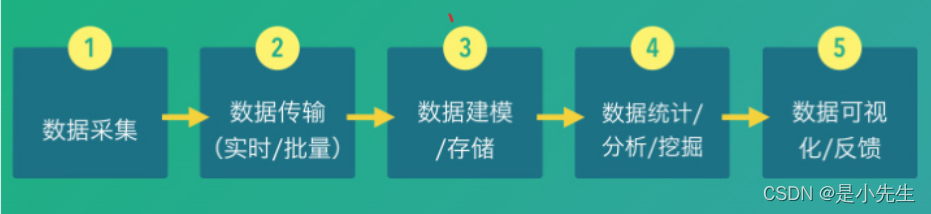
在这个流程里,我们认为第一个步骤,也就是数据埋点和采集数据是最基础的问题,数据采集是否丰富,采集的数据是否准确,采集是否及时,都直接影响整个数据平台的应用的效果。
埋点的两种方式:
第一种:自己公司研发在产品中注入埋点代码进行采集。将埋点代码比如写道一个js里,然后放到某个应用网站上。
第二种:使用第三方统计工具,如友盟,百度移动,魔方,App Annie,talking data等。
本项目的埋点实现:
我们通过js代码来实现埋点。编写特定的js脚本,然后嵌入到需要做日志分析的web页面上(实际是通过<script>标签来嵌入js文件)
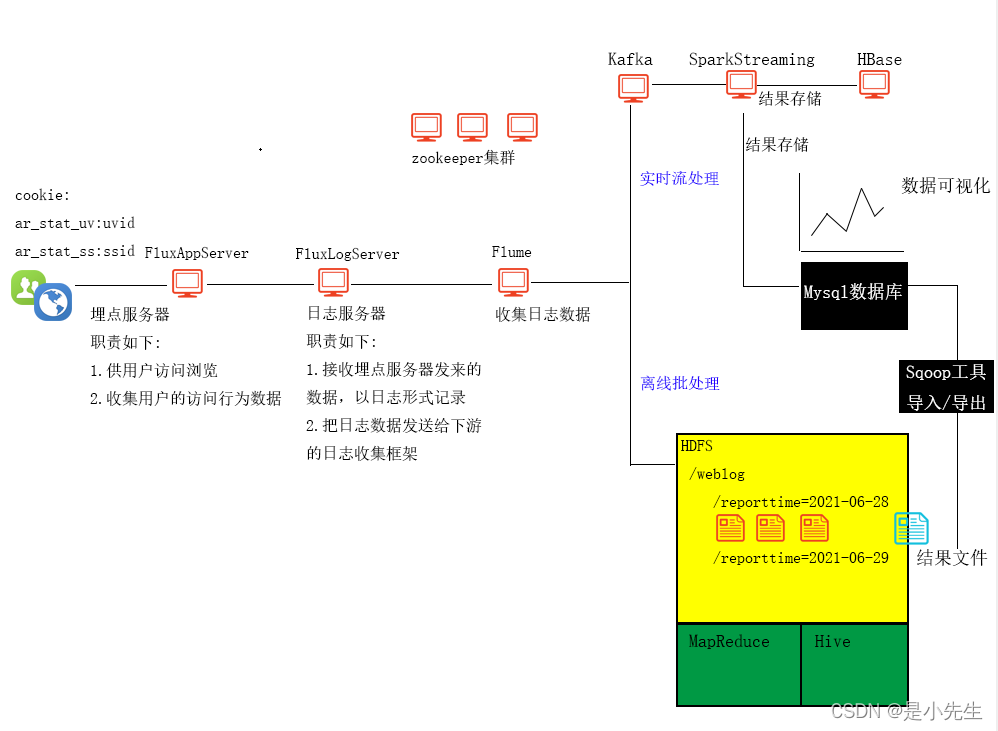
三、项目整体架构
1、架构图
四、项目环境搭建
1、准备
IDEA、Maven、Tomcat
2、搭建
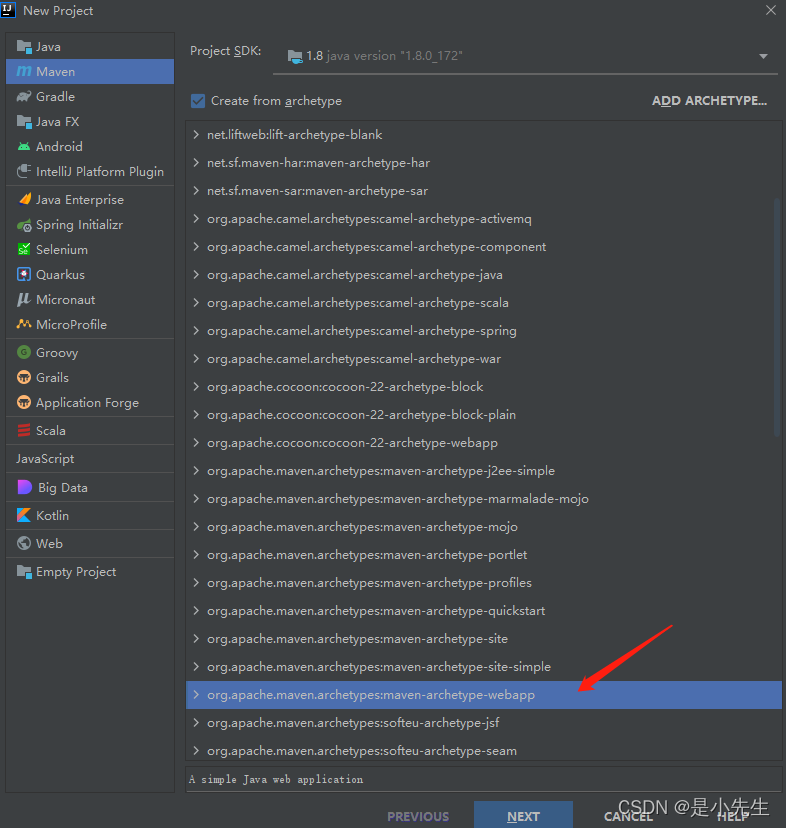
①、创建maven工程,名字自己定义,我的为WebProject,选择webapp。
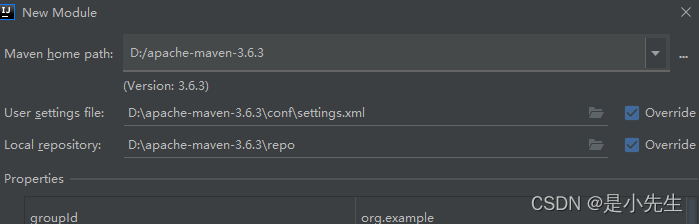
②、选择maven的仓库,我直接选择我的本地仓库
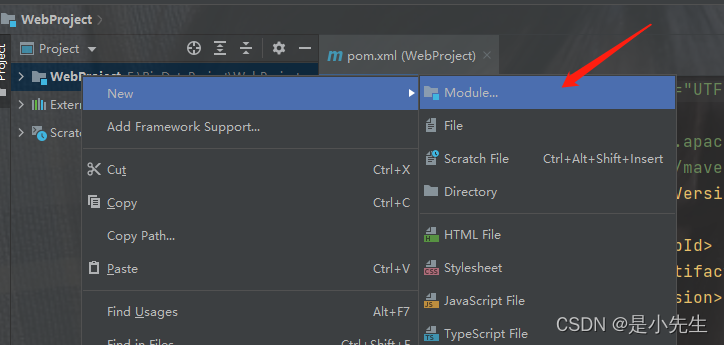
③、 然后再新建两个FluxAppServer和FluxLogServer模块,还是maven选择webapp

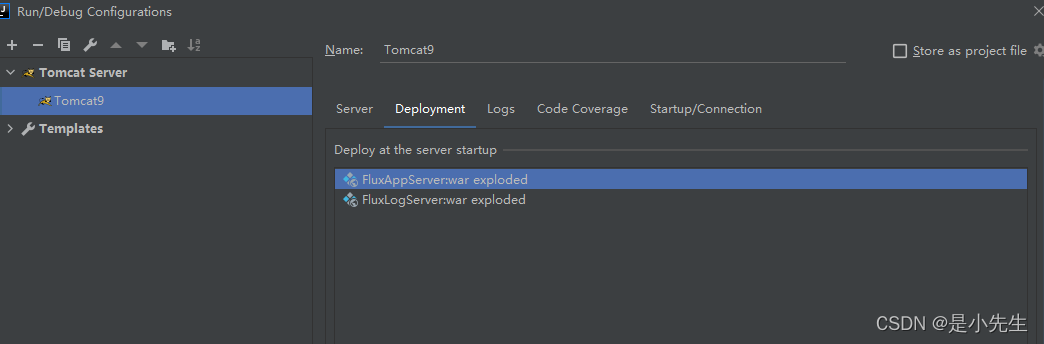
④、添加本地tomcat环境,指定发布到Tomcat的web工程,并指定访问的路径:
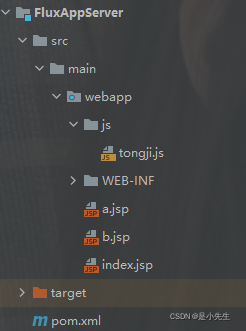
⑤、添加FluxAppServer工程相关的js文件与网页文件
tongji.js:
/**函数可对字符串进行编码,这样就可以在所有的计算机上读取该字符串。*/ function ar_encode(str) { //进行URL编码 return encodeURI(str); } /**屏幕分辨率*/ function ar_get_screen() { var c = ""; if (self.screen) { c = screen.width+"x"+screen.height; } return c; } /**颜色质量*/ function ar_get_color() { var c = ""; if (self.screen) { c = screen.colorDepth+"-bit"; } return c; } /**返回当前的浏览器语言*/ function ar_get_language() { var l = ""; var n = navigator; if (n.language) { l = n.language.toLowerCase(); } else if (n.browserLanguage) { l = n.browserLanguage.toLowerCase(); } return l; } /**返回浏览器类型IE,Firefox*/ function ar_get_agent() { var a = ""; var n = navigator; if (n.userAgent) { a = n.userAgent; } return a; } /**方法可返回一个布尔值,该值指示浏览器是否支持并启用了Java*/ function ar_get_jvm_enabled() { var j = ""; var n = navigator; j = n.javaEnabled() ? 1 : 0; return j; } /**返回浏览器是否支持(启用)cookie */ function ar_get_cookie_enabled() { var c = ""; var n = navigator; c = n.cookieEnabled ? 1 : 0; return c; } /**检测浏览器是否支持Flash或有Flash插件*/ function ar_get_flash_ver() { var f="",n=navigator; if (n.plugins && n.plugins.length) { for (var ii=0;ii<n.plugins.length;ii++) { if (n.plugins[ii].name.indexOf('Shockwave Flash')!=-1) { f=n.plugins[ii].description.split('Shockwave Flash ')[1]; break; } } } else if (window.ActiveXObject) { for (var ii=10;ii>=2;ii--) { try { var fl=eval("new ActiveXObject('ShockwaveFlash.ShockwaveFlash."+ii+"');"); if (fl) { f=ii + '.0'; break; } } catch(e) {} } } return f; } /**匹配顶级域名*/ function ar_c_ctry_top_domain(str) { var pattern = "/^aero$|^cat$|^coop$|^int$|^museum$|^pro$|^travel$|^xxx$|^com$|^net$|^gov$|^org$|^mil$|^edu$|^biz$|^info$|^name$|^ac$|^mil$|^co$|^ed$|^gv$|^nt$|^bj$|^hz$|^sh$|^tj$|^cq$|^he$|^nm$|^ln$|^jl$|^hl$|^js$|^zj$|^ah$|^hb$|^hn$|^gd$|^gx$|^hi$|^sc$|^gz$|^yn$|^xz$|^sn$|^gs$|^qh$|^nx$|^xj$|^tw$|^hk$|^mo$|^fj$|^ha$|^jx$|^sd$|^sx$/i"; if(str.match(pattern)){ return 1; } return 0; } /**处理域名地址*/ function ar_get_domain(host) { //如果存在则截去域名开头的 "www." var d=host.replace(/^www\./, ""); //剩余部分按照"."进行split操作,获取长度 var ss=d.split("."); var l=ss.length; //如果长度为3,则为xxx.yyy.zz格式 if(l == 3){ //如果yyy为顶级域名,zz为次级域名,保留所有 if(ar_c_ctry_top_domain(ss[1]) && ar_c_ctry_domain(ss[2])){ } //否则只保留后两节 else{ d = ss[1]+"."+ss[2]; } } //如果长度大于3 else if(l >= 3){ //如果host本身是个ip地址,则直接返回该ip地址为完整域名 var ip_pat = "^[0-9]*\.[0-9]*\.[0-9]*\.[0-9]*$"; if(host.match(ip_pat)){ return d; } //如果host后两节为顶级域名及次级域名,则保留后三节 if(ar_c_ctry_top_domain(ss[l-2]) && ar_c_ctry_domain(ss[l-1])) { d = ss[l-3]+"."+ss[l-2]+"."+ss[l-1]; } //否则保留后两节 else{ d = ss[l-2]+"."+ss[l-1]; } } return d; } /**返回cookie信息*/ function ar_get_cookie(name) { //获取所有cookie信息 var co=document.cookie; //如果名字是个空 返回所有cookie信息 if (name == "") { return co; } //名字不为空 则在所有的cookie中查找这个名字的cookie var mn=name+"="; var b,e; b=co.indexOf(mn); //没有找到这个名字的cookie 则返回空 if (b < 0) { return ""; } //找到了这个名字的cookie 获取cookie的值返回 e=co.indexOf(";", b+name.length); if (e < 0) { return co.substring(b+name.length + 1); } else { return co.substring(b+name.length + 1, e); } } /** 设置cookie信息 操作符: 0 表示不设置超时时间 cookie是一个会话级别的cookie cookie信息保存在浏览器内存当中 浏览器关闭时cookie消失 1 表示设置超时时间为10年以后 cookie会一直保存在浏览器的临时文件夹里 直到超时时间到来 或用户手动清空cookie为止 2 表示设置超时时间为1个小时以后 cookie会一直保存在浏览器的临时文件夹里 直到超时时间到来 或用户手动清空cookie为止 * */ function ar_set_cookie(name, val, cotp) { var date=new Date; var year=date.getFullYear(); var hour=date.getHours(); var cookie=""; if (cotp == 0) { cookie=name+"="+val+";"; } else if (cotp == 1) { year=year+10; date.setYear(year); cookie=name+"="+val+";expires="+date.toGMTString()+";"; } else if (cotp == 2) { hour=hour+1; date.setHours(hour); cookie=name+"="+val+";expires="+date.toGMTString()+";"; } var d=ar_get_domain(document.domain); if(d != ""){ cookie +="domain="+d+";"; } cookie +="path="+"/;"; document.cookie=cookie; } /**返回客户端时间*/ function ar_get_stm() { return new Date().getTime(); } /**返回指定个数的随机数字串*/ function ar_get_random(n) { var str = ""; for (var i = 0; i < n; i ++) { str += String(parseInt(Math.random() * 10)); } return str; } /* main function */ function ar_main() { //收集完日志 提交到的路径 var dest_path = "http://localhost:8090/FluxLogServer/servlet/LogServlet?"; var expire_time = 30 * 60 * 1000;//会话超时时长 //处理uv //--获取cookie ar_stat_uv的值 var uv_str = ar_get_cookie("ar_stat_uv"); var uv_id = ""; //--如果cookie ar_stat_uv的值为空 if (uv_str == ""){ //--为这个新uv配置id,为一个长度20的随机数字 uv_id = ar_get_random(20); //--设置cookie ar_stat_uv 保存时间为10年 ar_set_cookie("ar_stat_uv", uv_id, 1); } //--如果cookie ar_stat_uv的值不为空 else{ //--获取uv_id uv_id = uv_str; } //处理ss //--获取cookie ar_stat_ss var ss_str = ar_get_cookie("ar_stat_ss"); var ss_id = ""; //sessin id var ss_no = 0; //session有效期内访问页面的次数 //--如果cookie中不存在ar_stat_ss 说明是一次新的会话 if (ss_str == ""){ //--随机生成长度为10的session id ss_id = ar_get_random(10); //--session有效期内页面访问次数为0 ss_no = 0; //--拼接cookie ar_stat_ss 值 格式为 会话编号_会话期内访问次数_客户端时间_网站id value = ss_id+"_"+ss_no+"_"+ar_get_stm(); //--设置cookie ar_stat_ss ar_set_cookie("ar_stat_ss", value, 0); } //--如果cookie中存在ar_stat_ss else { //获取ss相关信息 var items = ss_str.split("_"); //--ss_id var cookie_ss_id = items[0]; //--ss_no var cookie_ss_no = parseInt(items[1]); //--ss_stm var cookie_ss_stm = items[2]; //如果当前时间-当前会话上一次访问页面的时间>30分钟,虽然cookie还存在,但是其实已经超时了!仍然需要重新生成cookie if (ar_get_stm() - cookie_ss_stm > expire_time) { //--重新生成会话id ss_id = ar_get_random(10); //--设置会话中的页面访问次数为0 ss_no = 0; } //--如果会话没有超时 else{ //--会话id不变 ss_id = cookie_ss_id; //--设置会话中的页面方位次数+1 ss_no = cookie_ss_no + 1; } //--重新拼接cookie ar_stat_ss的值 value = ss_id+"_"+ss_no+"_"+ar_get_stm(); ar_set_cookie("ar_stat_ss", value, 0); } //当前地址 var url = document.URL; url = ar_encode(String(url)); //当前资源名 var urlname = document.URL.substring(document.URL.lastIndexOf("/")+1); urlname = ar_encode(String(urlname)); //返回导航到当前网页的超链接所在网页的URL var ref = document.referrer; ref = ar_encode(String(ref)); //网页标题 var title = document.title; title = ar_encode(String(title)); //网页字符集 var charset = document.charset; charset = ar_encode(String(charset)); //屏幕信息 var screen = ar_get_screen(); screen = ar_encode(String(screen)); //颜色信息 var color =ar_get_color(); color =ar_encode(String(color)); //语言信息 var language = ar_get_language(); language = ar_encode(String(language)); //浏览器类型 var agent =ar_get_agent(); agent =ar_encode(String(agent)); //浏览器是否支持并启用了java var jvm_enabled =ar_get_jvm_enabled(); jvm_enabled =ar_encode(String(jvm_enabled)); //浏览器是否支持并启用了cookie var cookie_enabled =ar_get_cookie_enabled(); cookie_enabled =ar_encode(String(cookie_enabled)); //浏览器flash版本 var flash_ver = ar_get_flash_ver(); flash_ver = ar_encode(String(flash_ver)); //当前ss状态 格式为"会话id_会话次数_当前时间" var stat_ss = ss_id+"_"+ss_no+"_"+ar_get_stm(); //拼接访问地址 增加如上信息 dest=dest_path+"url="+url+"&urlname="+urlname+"&title="+title+"&chset="+charset+"&scr="+screen+"&col="+color+"&lg="+language+"&je="+jvm_enabled+"&ce="+cookie_enabled+"&fv="+flash_ver+"&cnv="+String(Math.random())+"&ref="+ref+"&uagent="+agent+"&stat_uv="+uv_id+"&stat_ss="+stat_ss; //通过插入图片访问该地址 document.getElementsByTagName("body")[0].innerHTML += "<img src=\""+dest+"\" border=\"0\" width=\"1\" height=\"1\" />"; } window.onload = function(){ //触发main方法 ar_main(); }pom.xml:
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.tomcat</groupId> <artifactId>tomcat-servlet-api</artifactId> <version>7.0.63</version> <scope>provided</scope> </dependency>a.jsp:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <script type="text/javascript" src="js/tongji.js"></script> <title>页面A</title> </head> <body> <span>页面A</span> AAAAAAAAAAAAA <a href="http://localhost:8090/FluxAppServer/b.jsp">BBBB</a> </body> </html>b.jsp:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <!DOCTYPE html> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> <script type="text/javascript" src="js/tongji.js"></script> <title>页面B</title> </head> <body> BBBBBBBBBBBBB </body> </html>index.jsp:
<html> <body> <h2>Hello World!</h2> </body> </html>
⑥、添加FluxLogServer工程相关文件
pom.xml
<dependency> <groupId>org.apache.tomcat</groupId> <artifactId>tomcat-servlet-api</artifactId> <version>7.0.63</version> <scope>provided</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency> <dependency> <groupId>org.apache.flume</groupId> <artifactId>flume-ng-core</artifactId> <version>1.9.0</version> </dependency> <dependency> <groupId>org.apache.flume.flume-ng-clients</groupId> <artifactId>flume-ng-log4jappender</artifactId> <version>1.9.0</version> </dependency>log4j配置:日志一条线发给控制台,另一条线发给我们的flume,注意地址是我们的hadoop01的地址
log4j.rootLogger = info,stdout,flume log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = %m%n log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender log4j.appender.flume.Hostname =192.168.186.128 log4j.appender.flume.Port = 44444 log4j.appender.flume.UnsafeMode = trueLogServlet:
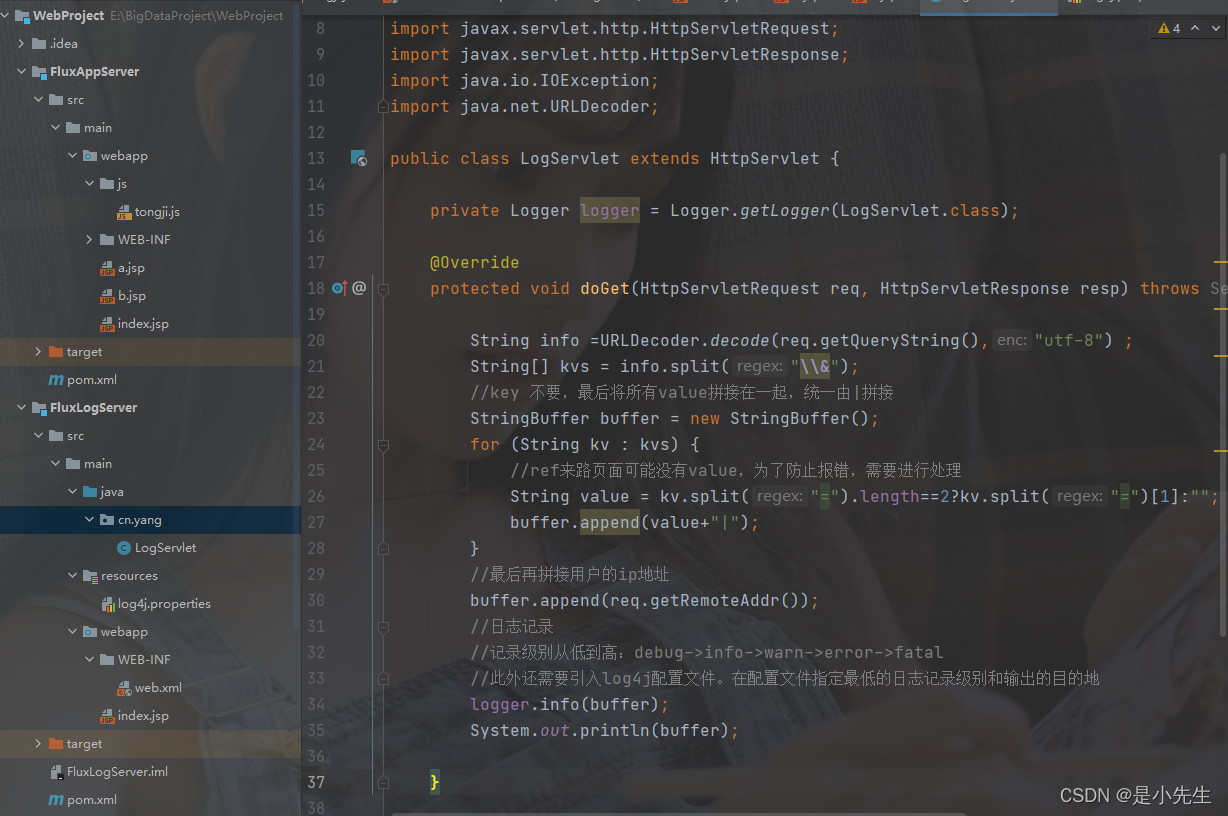
package cn.yang; import org.apache.log4j.Logger; import javax.servlet.ServletException; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.io.IOException; import java.net.URLDecoder; public class LogServlet extends HttpServlet { private Logger logger = Logger.getLogger(LogServlet.class); @Override protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { String info =URLDecoder.decode(req.getQueryString(),"utf-8") ; String[] kvs = info.split("\\&"); //key 不要,最后将所有value拼接在一起,统一由|拼接 StringBuffer buffer = new StringBuffer(); for (String kv : kvs) { //ref来路页面可能没有value,为了防止报错,需要进行处理 String value = kv.split("=").length==2?kv.split("=")[1]:""; buffer.append(value+"|"); } //最后再拼接用户的ip地址 buffer.append(req.getRemoteAddr()); //日志记录 //记录级别从低到高:debug->info->warn->error->fatal //此外还需要引入log4j配置文件。在配置文件指定最低的日志记录级别和输出的目的地 logger.info(buffer); System.out.println(buffer); } @Override protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException { doGet(req, resp); } }
⑦、项目初始结构为:
⑧、 最后启动tomcat
3、字段说明
|
字段 |
字段名 |
字段说明 |
|
url |
||
|
a.jsp |
urlname |
|
|
页面A |
title |
页面标题 |
|
UTF-8 |
chset |
字符集 |
|
scr |
1024*768 |
屏幕 |
|
24-bit |
col |
颜色 |
|
lg |
zh-cn |
语言 |
|
je |
0 |
浏览器是否支持java |
|
ec |
1 |
是否支持并启用cookie |
|
fv |
27.0 |
浏览器的flash版本 |
|
ref |
来源页面 |
|
|
uagent |
Mozilla/5.0…… |
浏览器 |
|
stat_uv |
78024453153757966560 |
uv_id |
|
stat_ss |
4633702647_8_1511204198645 |
ssid_sscount_sstime |
|
cip |
0:0:0:0:0:0:0:1 |
公网ip |
五、日志服务器-Flume连通
1、新建weblog.conf

内容如下:
a1.sources=r1
a1.sinks=s1
a1.channels=c1
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
a1.sinks.s1.type=logger
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.s1.channel=c1 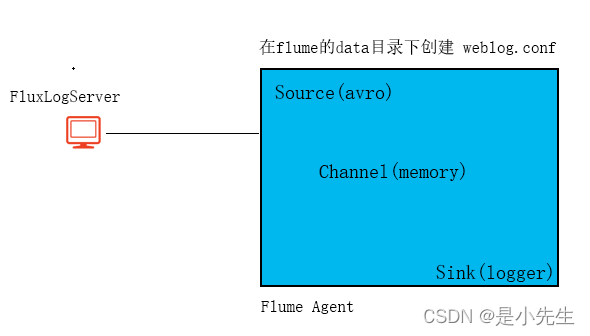
启动flume,在flume的data目录下执行:
../bin/flume-ng agent -n a1 -c ./ -f ./weblog.conf
-Dflume.root.logger=INFO,console
启动成功
然后我们启动tomcat,访问a.jsp。就会发现我们的flume捕捉到了数据


2、离线批处理搭建 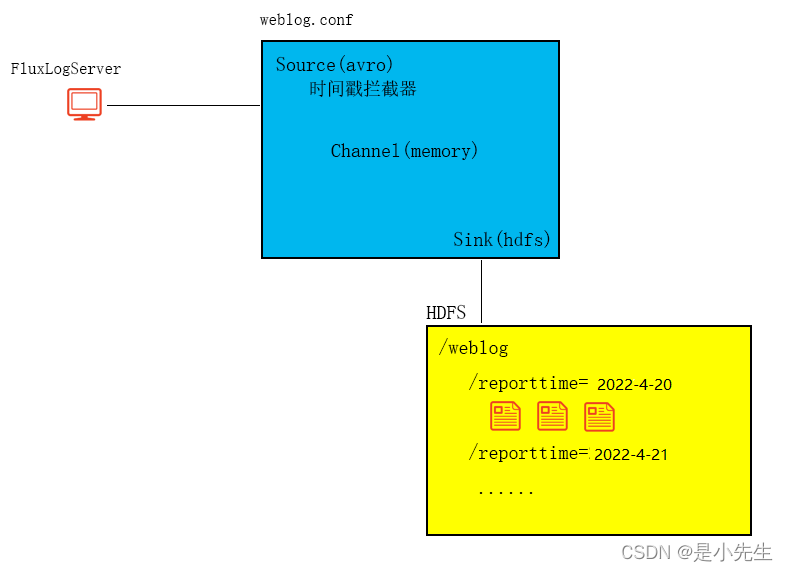
①、配置flume,编辑weblog.conf
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=avro
a1.sources.r1.bind=0.0.0.0
a1.sources.r1.port=44444
a1.sources.r1.interceptors=i1
a1.sources.r1.interceptors.i1.type=timestamp
a1.sinks.k1.type=hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.186.128:9000/weblog/reportTime=%Y-%m-%d
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.rollInterval=30
a1.sinks.k1.hdfs.rollSize=0
a1.sinks.k1.hdfs.rollCount=1000
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
a1.sources.r1.channels=c1
a1.sinks.k1.channel=c1②、启动hadoop
start-all.sh
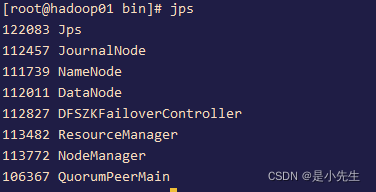
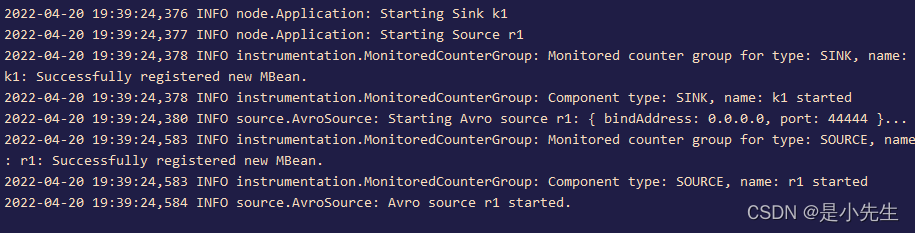
③、启动flume
../bin/flume-ng agent -n a1 -c ./ -f ./weblog.conf -Dflume.root.logger=INFO,console
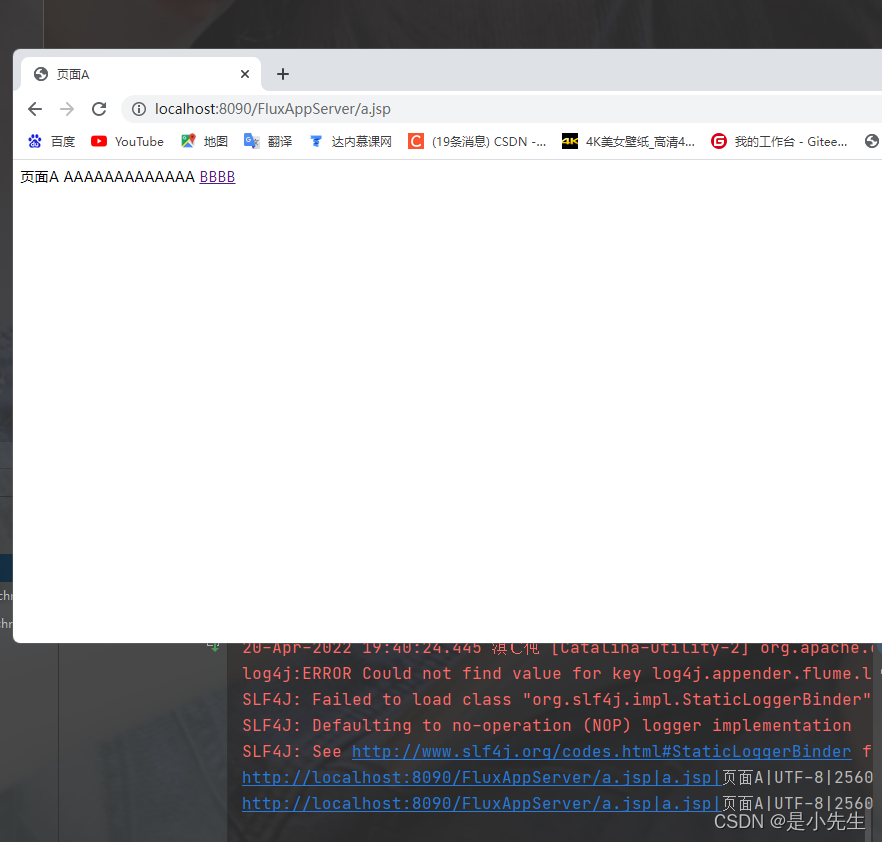
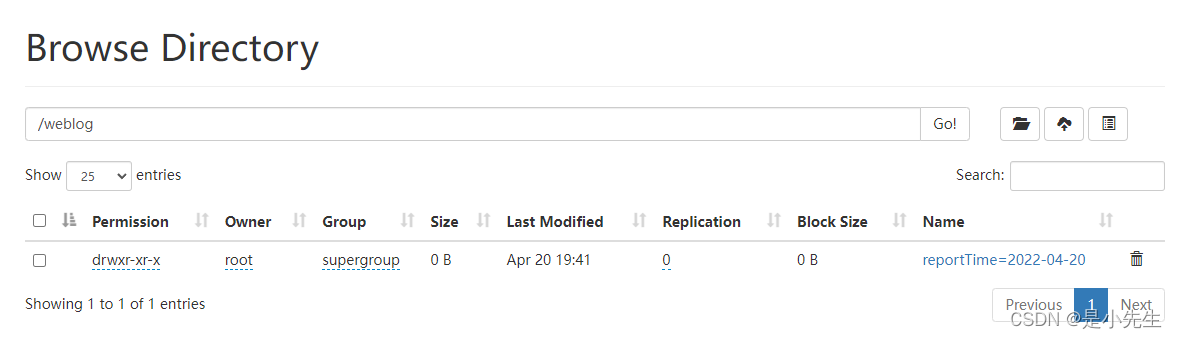
④、启动tomcat,访问埋点服务器进行测试,看HDFS上是否能够产生数据

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 2
2 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)