大数据hudi之集成flink:核心参数设置
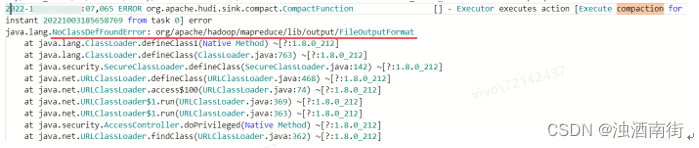
注意:如果没有按照5.2.1中yarn-session模式解决hadoop依赖冲突问题,那么无法compaction生成parquet文件,报错很隐晦,在Exception中看不到,要搜索TaskManager中关于compaction才能看到报错。在进行insert/upsert操作时,Hudi可以将文件大小维护在一个指定文件大小。可以flink建表时在with中指定,或Hints临时指定参数的
·
去重参数
通过如下语法设置主键:
-- 设置单个主键
create table hoodie_table (
f0 int primary key not enforced,
f1 varchar(20),
...
) with (
'connector' = 'hudi',
...
)
-- 设置联合主键
create table hoodie_table (
f0 int,
f1 varchar(20),
...
primary key(f0, f1) not enforced
) with (
'connector' = 'hudi',
...
)
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hoodie.datasource.write.recordkey.field | 主键字段 | 支持主键语法 PRIMARY KEY 设置,支持逗号分隔的多个字段 | |
| precombine.field (0.13.0 之前版本为write.precombine.field) | 去重时间字段 | record 合并的时候会按照该字段排序,选值较大的 record 为合并结果;不指定则为处理序:选择后到的 record |
并发参数
1)参数说明
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| write.tasks | writer 的并发每个 writer 顺序写 1~N 个 buckets | 4 | 增加并发对小文件个数没影响 |
| write.bucket_assign.tasks | bucket assigner 的并发 | Flink的并行度 | 增加并发同时增加了并发写的 bucekt 数,也就变相增加了小文件(小 bucket) 数 |
| write.index_bootstrap.tasks | Index bootstrap 算子的并发,增加并发可以加快 bootstrap 阶段的效率,bootstrap 阶段会阻塞 checkpoint,因此需要设置多一些的 checkpoint 失败容忍次数 | Flink的并行度 | 只在 index.bootstrap.enabled 为 true 时生效 |
| read.tasks | 读算子的并发(batch 和 stream) | 4 | |
| compaction.tasks | online compaction 算子的并发 | writer 的并发 | online compaction 比较耗费资源,建议走 offline compaction |
2)案例演示
可以flink建表时在with中指定,或Hints临时指定参数的方式:在需要调整的表名后面加上 /*+ OPTIONS() */
insert into t2 /*+ OPTIONS('write.tasks'='2','write.bucket_assign.tasks'='3','compaction.tasks'='4') */
select * from sourceT;
压缩参数
1)参数说明
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| compaction.schedule.enabled | 是否阶段性生成压缩 plan | true | 建议开启,即使compaction.async.enabled 关闭的情况下 |
| compaction.async.enabled | 是否开启异步压缩 | true | 通过关闭此参数关闭在线压缩 |
| compaction.tasks | 压缩 task 并发 | 4 | |
| compaction.trigger.strategy | 压缩策略 | num_commits | 支持四种策略:num_commits、time_elapsed、num_and_time、 |
| num_or_time | |||
| compaction.delta_commits | 默认策略,5 个 commits 压缩一次 | 5 | |
| compaction.delta_seconds | 3600 | ||
| compaction.max_memory | 压缩去重的 hash map 可用内存 | 100(MB) | 资源够用的话建议调整到 1GB |
| compaction.target_io | 每个压缩 plan 的 IO 上限,默认 5GB | 500(GB) |
2)案例演示
CREATE TABLE t3(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t3',
'compaction.async.enabled' = 'true',
'compaction.tasks' = '1',
'compaction.schedule.enabled' = 'true',
'compaction.trigger.strategy' = 'num_commits',
'compaction.delta_commits' = '2',
'table.type' = 'MERGE_ON_READ'
);
set table.dynamic-table-options.enabled=true;
insert into t3
select * from sourceT/*+ OPTIONS('rows-per-second' = '5')*/;
注意:如果没有按照5.2.1中yarn-session模式解决hadoop依赖冲突问题,那么无法compaction生成parquet文件,报错很隐晦,在Exception中看不到,要搜索TaskManager中关于compaction才能看到报错。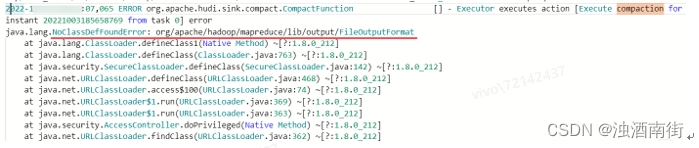
文件大小
1)参数说明
Hudi会自管理文件大小,避免向查询引擎暴露小文件,其中自动处理文件大小起很大作用。在进行insert/upsert操作时,Hudi可以将文件大小维护在一个指定文件大小。
目前只有 log 文件的写入大小可以做到精确控制,parquet 文件大小按照估算值。
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hoodie.parquet.max.file.size | 最大可写入的 parquet 文件大小 | 20 * 1024 * 1024默认 120MB(单位 byte) | 超过该大小切新的 file group |
| hoodie.logfile.to.parquet.compression.ratio | log文件大小转 parquet 的比率 | 0.35 | hoodie 统一依据 parquet 大小来评估小文件策略 |
| hoodie.parquet.small.file.limit | 在写入时,hudi 会尝试先追加写已存小文件,该参数设置了小文件的大小阈值,小于该参数的文件被认为是小文件 | 104857600默认100MB(单位 byte) | 大于 100MB,小于 120MB 的文件会被忽略,避免写过度放大 |
| hoodie.copyonwrite.record.size.estimate | 预估的 record 大小,hoodie 会依据历史的 commits 动态估算 record 的大小,但是前提是之前有单次写入超过 | ||
| hoodie.parquet.small.file.limit 大小,在未达到这个大小时会使用这个参数 | 1024默认 1KB(单位 byte) | 如果作业流量比较小,可以设置下这个参数 | |
| hoodie.logfile.max.size | LogFile最大大小。这是在将Log滚转到下一个版本之前允许的最大大小。 | 1073741824默认1GB(单位 byte) |
2)案例演示
CREATE TABLE t4(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://hadoop1:8020/tmp/hudi_flink/t4',
'compaction.tasks' = '1',
'hoodie.parquet.max.file.size'= '10000',
'hoodie.parquet.small.file.limit'='5000',
'table.type' = 'MERGE_ON_READ'
);
set table.dynamic-table-options.enabled=true;
insert into t4
select * from sourceT /*+ OPTIONS('rows-per-second' = '5')*/;
Hadoop 参数
从 0.12.0 开始支持,如果有跨集群提交执行的需求,可以通过 sql 的 ddl 指定 per-job 级别的 hadoop 配置
| 名称 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| hadoop.${you option key} | 通过 hadoop.前缀指定 hadoop 配置项 | 支持同时指定多个 hadoop 配置项 |

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 1
1 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)