大数据Hadoop之终于弄懂了MapReduce中reduce阶段Iterable迭代出的是同一个对象
1. 前言:之前在看一个老师写流量统计案例时,他刚开始的Mapper代码是这样写的:然后他说这样每次都要造对象,所以他改成了这样:但是这样我就不理解了,因为你每次获取一行数据都要将其对应的上行流量、下行流量放到一个对象中,又因为每一行的数据不同,所以你每次都应该new 一个对象,用来存放数据。如果改成第二种方式,在对一个文件每一行数据读取时,你始终用的就是同一个对象,你每次set值都是对前一个值得
1. 前言:
之前在看一个老师写流量统计案例时,他刚开始的Mapper代码是这样写的: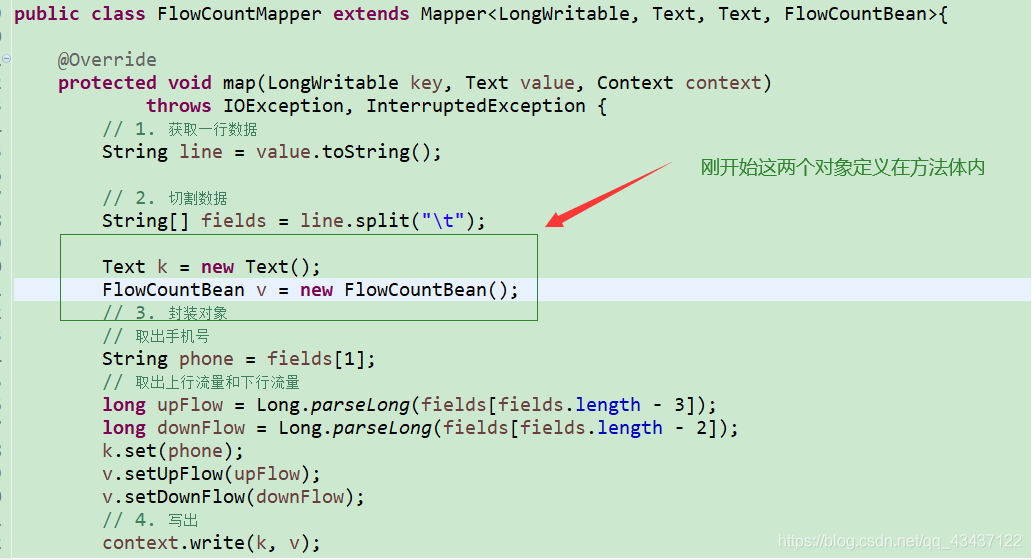
然后他说这样每次都要造对象,所以他改成了这样: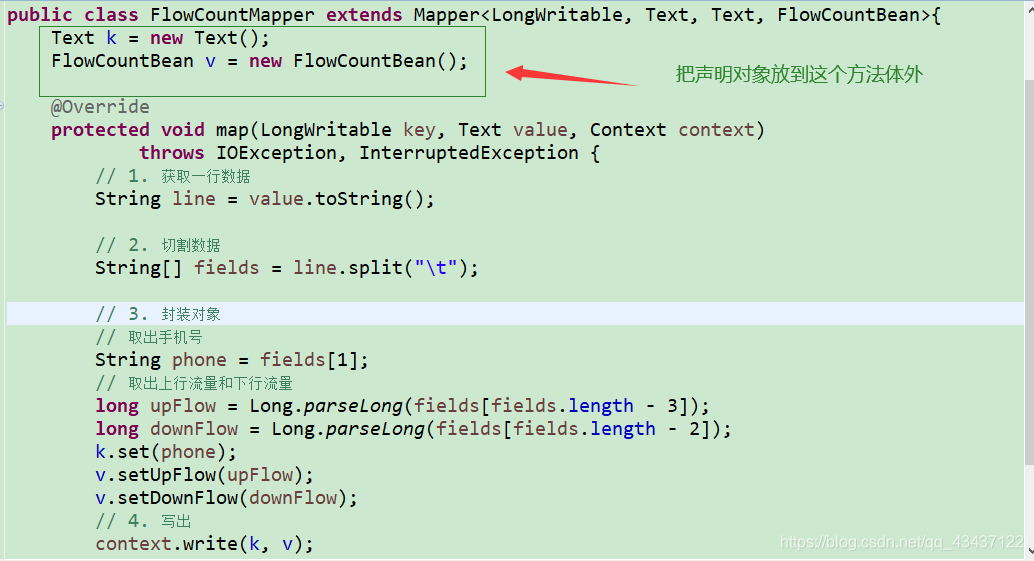
但是这样我就不理解了,因为你每次获取一行数据都要将其对应的上行流量、下行流量放到一个对象中,又因为每一行的数据不同,所以你每次都应该new 一个对象,用来存放数据。如果改成第二种方式,在对一个文件每一行数据读取时,你始终用的就是同一个对象,你每次set值都是对前一个值得覆盖,那么最终不就得不到正确答案了吗?结果证明,老师那样写的没错。
2. 各种猜想之后,开始自行DeBug研究:
通过多次尝试,我决定遍历reduce阶段的values,然后输出它每一个对象的地址值,来确定这些对象是不是同一个,答案是“是”。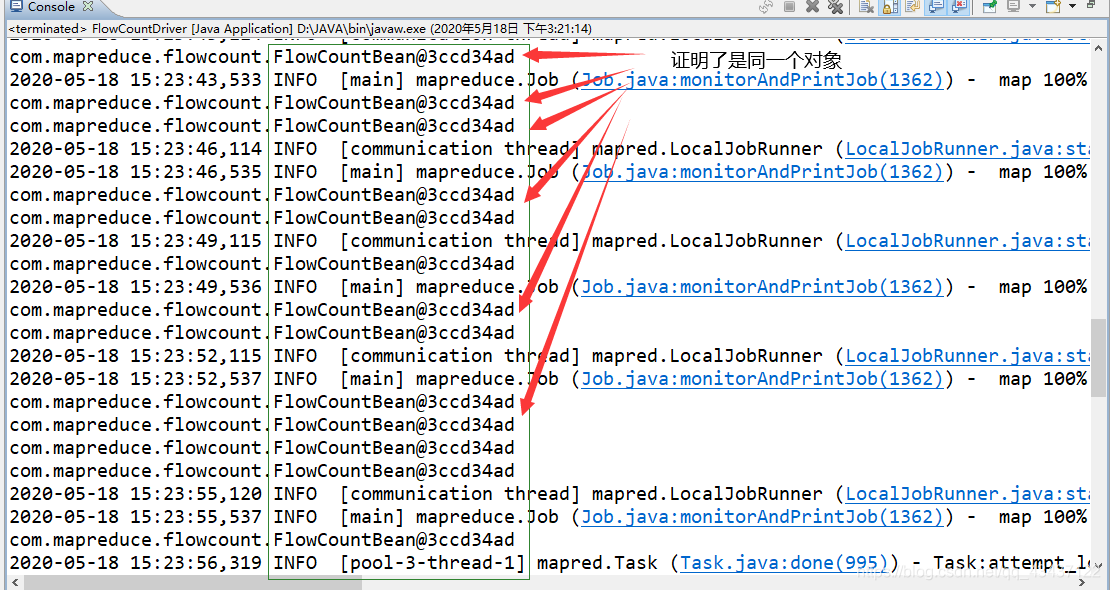
3. 原因分析:归根结底还是因为Hadoop的序列化机制。(你一看怎么和搜到的其他博文解释的一样,别急往最后看)
我们了解ArrayList在内存中,对象也在内存中,ArrayList存储的是对对象地址的引用,不停更改值后add到ArrayList中,那么所有的值都被覆盖,因为地址都是同一个。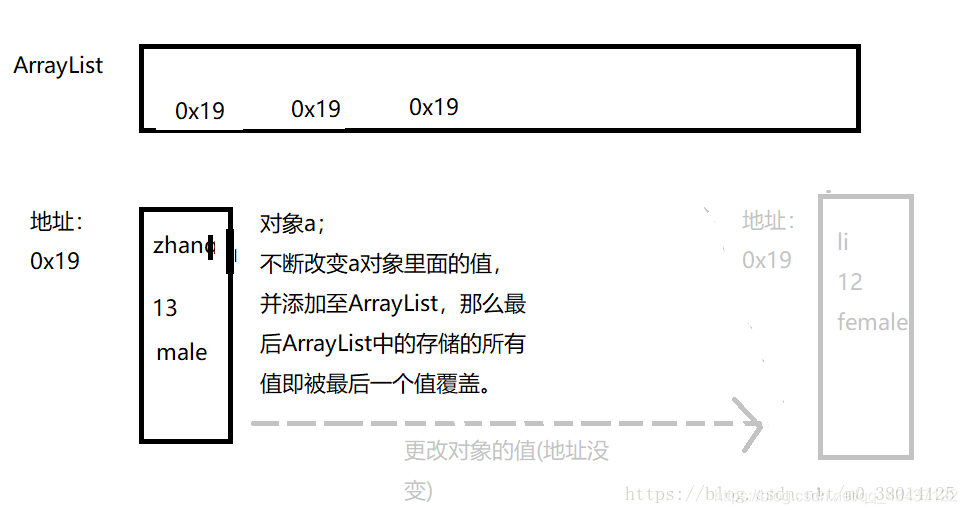
但context.write()同一对象(值不同)时,不会出现这种情况,因为它直接被序列化存储了,不会被覆盖。
4. 看看源码:
Iterable的实现是org.apache.hadoop.mapreduce.task.ReduceContextImpl.ValueIterable
Iterator实现是org.apache.hadoop.mapreduce.task.ReduceContextImpl.ValueIterator
其中next()实现时,调用的是org.apache.hadoop.io.serializer.WritableSerialization的deserialize(Writable w)方法,
Writable deserialize(Writable w) IOException {
Writable writable;
(w == ) {
writable
= (Writable) ReflectionUtils.(, getConf());
} {
writable = w;
}
writable.readFields();
writable;
}
该方法只是调用了入参w的readFields方法,并没有创建新对象,除非w是null。所以每次输出的对象地址值肯定相同,但是它们里
面封装的数据值是不同的。
总结:经过序列化后,你在map阶段每次context出k v时,虽然所有v是同一个对象,但是此时这个对象已经是被序列化的。你再次对它里面的属性赋值,并不会覆盖之前你已经赋过的值,所以你可以理解成它们彼此是独立的互不影响。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)