大数据Hadoop底层技术和原理
map reduce底层原理
·
mapreduce原理:
分而治之,一个大任务分成多个小的子任务(map)并行执行后,合并结果(reduce)
比如说我们有一千副扑克牌,不含大小王,混在一起,但是其中一副少了一张牌,所以总数是 51999 张,(一副扑克牌共54张牌,除了大小王还有52张)

先把牌随机的分一下,分成五份,分给五个人做,
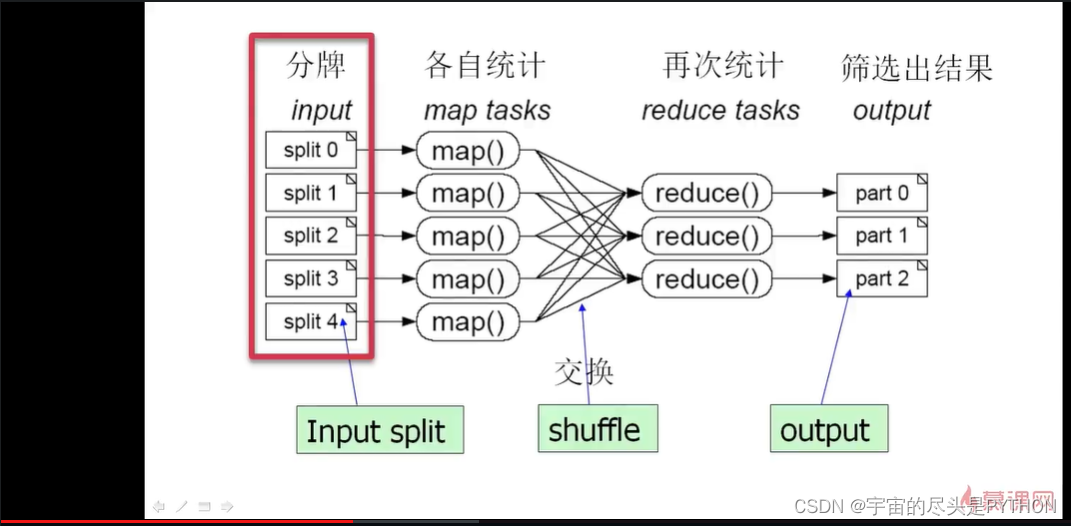

五个人 分别统计自己手上分到的牌,每种牌出现的花色和次数,这就是Map的操作
统计的每个结果为:

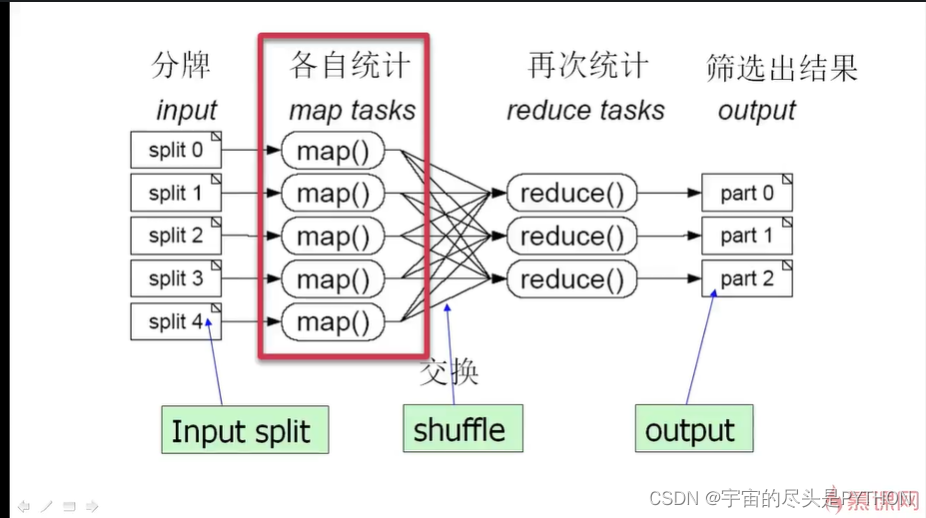
然后我们约定好了, 凡是红色A的,我们放一个地方,红色1放一个地方,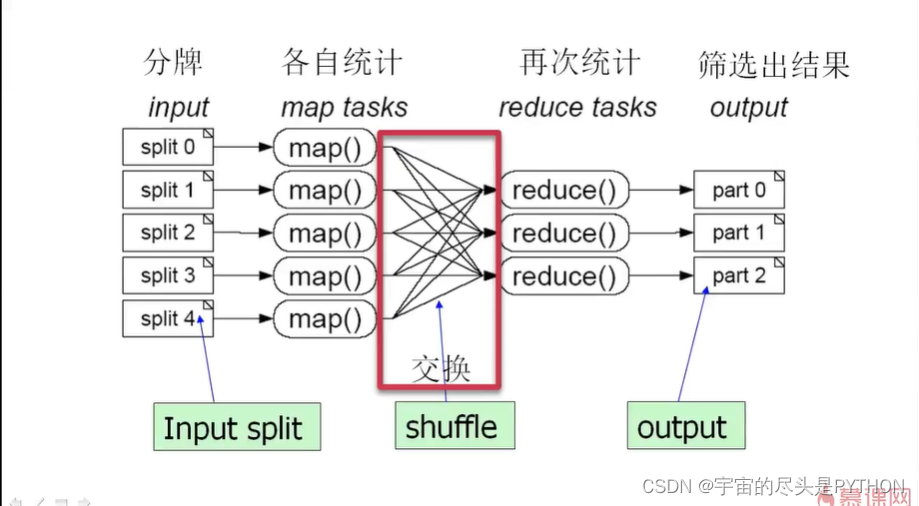
然后进行再次统计,
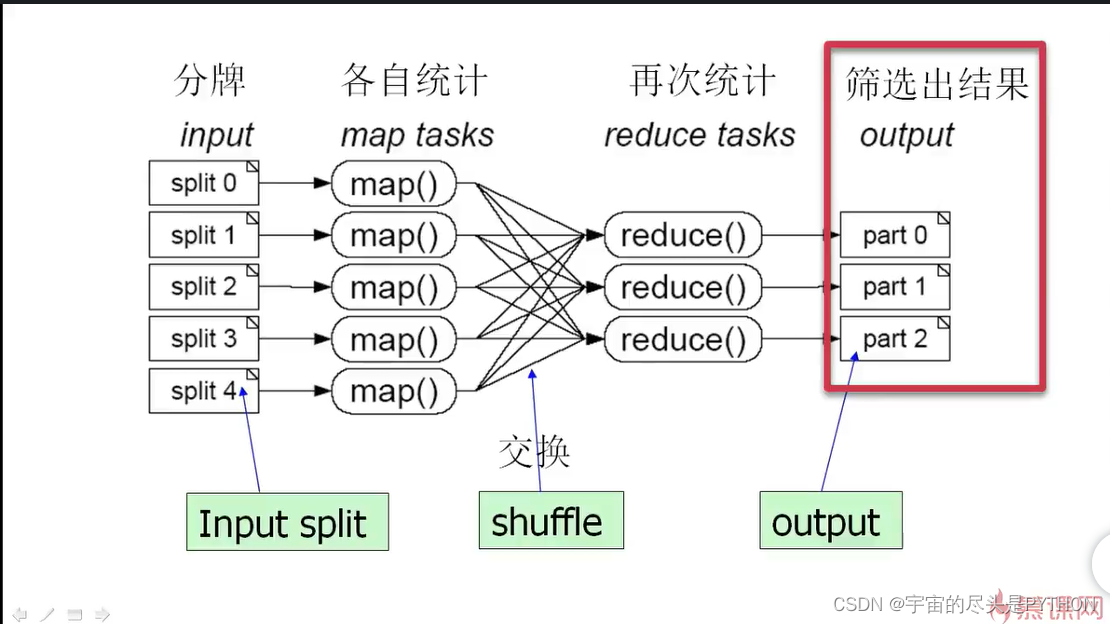
找到有999张牌的那个,就是少的那张牌。
mapreduce工作原理
找出访问最多的IP地址:
一个作业job
一个JOB完成需要分成多个task
task分为 maptask reducetask
还有在整个hadoop mapreduce体系结构中有两类节点,第一个的job Tracker
它也是一个master管理节点 客户端提交一个任务(Job)过来,job Tracker把它放到候选队列里面去,在适当的时候来进行调度,选择一个job出来,将这个job拆分成多个map任务和reduce任务,这个map任务分发给下面的tasktracker来做,tasktracker就是实际做这个任务,做这个事情、、、、未完待续。。。
以上内容来源于
https://www.imooc.com/video/8033
2022-11-16号
1.spark的组件包括

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐



 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)