逻辑回归可视化——绘制决策边界
具体代码如下,现在的代码是基于之前的逻辑回归Sigmoid函数的得到的结果最优参数,这是之前博客的地址:https://blog.csdn.net/qq_41938259/article/details/104139237使用的数据集也在这个链接里给出了,以下附上代码,代码使用了psutil来显示实时的内存使用率,和3百万次迭代的for循环的运算时间。import osimport...
·
具体代码如下,现在的代码是基于之前的逻辑回归Sigmoid函数的得到的结果最优参数,这是之前博客的地址:https://blog.csdn.net/qq_41938259/article/details/104139237
使用的数据集也在这个链接里给出了,
以下附上代码,代码使用了psutil来显示实时的内存使用率,和3百万次迭代的for循环的运算时间。
import os
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import psutil
import datetime
# 定义sigmoid函数
def sigmoid(x):
return 1.0/(1.0 + np.exp(-x))
# 逻辑回归计算参数的核心
# 会涉及numpy矩阵运算
def logicRegression(data, label):
dataMatrix = data.to_numpy()
labelMat = label.to_numpy()
m, n = dataMatrix.shape
alpha = 0.001
weights = np.ones((n, 1))
startTime = datetime.datetime.now()
for cycle in range(3000000):
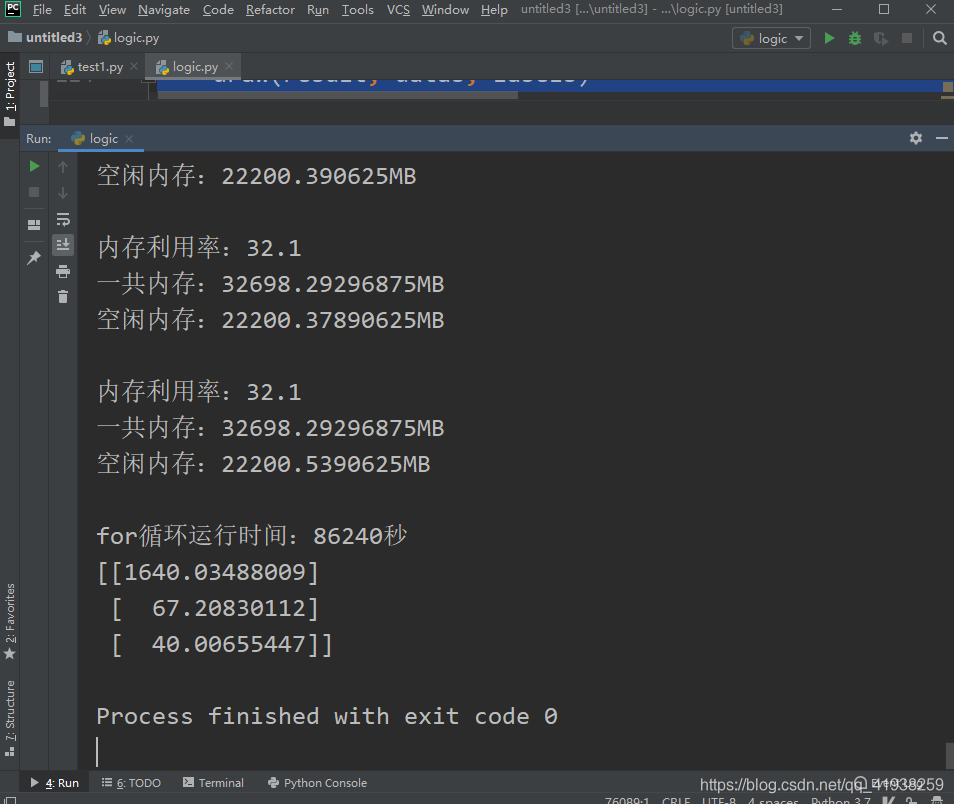
mem = psutil.virtual_memory()
print('内存利用率:{}\n一共内存:{}MB\n空闲内存:{}MB\n'.format(mem.percent, mem.total/(2**20), mem.free/(2**20)))
vector = sigmoid(dataMatrix.dot(weights))
error = labelMat - vector
weights = weights + alpha * (dataMatrix.T).dot(error)
endTime = datetime.datetime.now()
print('for循环运行时间:{}秒'.format((startTime-endTime).seconds))
return weights
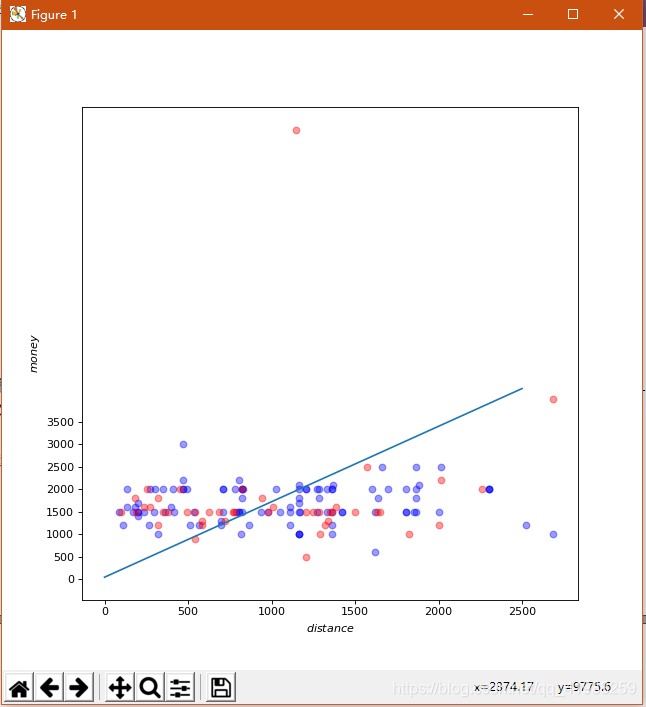
# 可视化模型x1、y1是faster的距离(副作用)和收入/生活费(正作用)
# x2、y2是lower的距离(副作用)和收入/生活费(正作用)
def visualize_model(x1, y1, x2, y2):
fig = plt.figure(figsize=(6, 6), dpi=80)
ax = fig.add_subplot(111)
ax.set_xlabel("$distance$")
ax.set_xticks(range(0, 3000, 500))
ax.set_ylabel("$money$")
ax.set_yticks(range(0, 4000, 500))
ax.scatter(x1, y1, color="b", alpha=0.4)
ax.scatter(x2, y2, color="r", alpha=0.4)
plt.legend(shadow=True)
plt.show()
def draw(result, data, label):
data = np.array(data)
label = np.array(label)
m,n = data.shape
x1 = []
y1 = []
x2 = []
y2 = []
for i in range(m):
if int(label[i]) == 1:
x1.append(data[i, 1])
y1.append(data[i, 2])
else:
x2.append(data[i, 1])
y2.append(data[i, 2])
fig = plt.figure(figsize=(8, 8), dpi=80)
ax = fig.add_subplot(111)
ax.scatter(x1, y1, color="b", alpha=0.4)
ax.scatter(x2, y2, color="r", alpha=0.4)
ax.set_xlabel("$distance$")
ax.set_xticks(range(0, 3000, 500))
ax.set_ylabel("$money$")
ax.set_yticks(range(0, 4000, 500))
x = range(0, 3000, 500)
y = (result[0]+result[1]*x)/result[2]
ax.plot(x, y)
plt.show()
if __name__ == '__main__':
# 打开文件操作
os.chdir('D:\\')
# 读取实验集
data = pd.read_excel('附件1.xlsx', sep=',')
result = data['III']
distance = data['II']
money = data['VI']
X = data['IV']
Y = data['X']
mistake = data['V']
test1 = pd.DataFrame({'result': result, 'distance': distance, 'money': money, 'mistake': mistake})
# 删去因为取票,而不得买错票的
# faster是买高铁票的人,而且是买对的
# lower是买普快的人,也是买对的
test1 = test1[(test1.mistake == 0)]
faster = test1[(test1.result == 1)]
lower = test1[test1.result == 0]
# 整理数据
faster = pd.DataFrame({'distance': faster['distance'], 'money': faster['money']})
lower = pd.DataFrame({'distance': lower['distance'], 'money': lower['money']})
# 丢弃有误数据
lower = lower.drop(index=129)
# 可视化步骤,红单点标签值为0,蓝点为1
# visualize_model(faster['distance'], faster['money'], lower['distance'], lower['money'])
# 准备逻辑回归的数据集
m, n = test1.shape
datas = pd.DataFrame({'X0': np.array([1]*m), 'X1': test1['distance'], 'X2': test1['money']})
labels = pd.DataFrame({'label': test1['result']})
# 运行伙计回归并打印结果
result = logicRegression(datas, labels)
print(result)
draw(result, datas, labels)
这里有输出结果:
END

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)