毕业设计:基于python渔业数据可视化分析系统 Flask框架 海洋捕捞品类 全国渔业 渔业加工(源码+文档)✅
毕业设计:基于python渔业数据可视化分析系统 Flask框架 海洋捕捞品类 全国渔业 渔业加工(源码+文档)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、Flask框架、数据分析、Echarts可视化、HTML、数据大屏
功能模块:
(1)可视化大屏主页面的展示。
(2)渔业产能分布地图的可视化展示。
(3)海洋捕捞品类的可视化展示。
(4)从业人员比重的可视化展示。
(5)淡水捕捞品种数量分布图的可视化展示。
(6)海洋捕捞较去年增长的可视化展示。
(7)全国渔业经济总产值的可视化展示。
(8)渔业加工能力增减的可视化展示。
2、项目界面
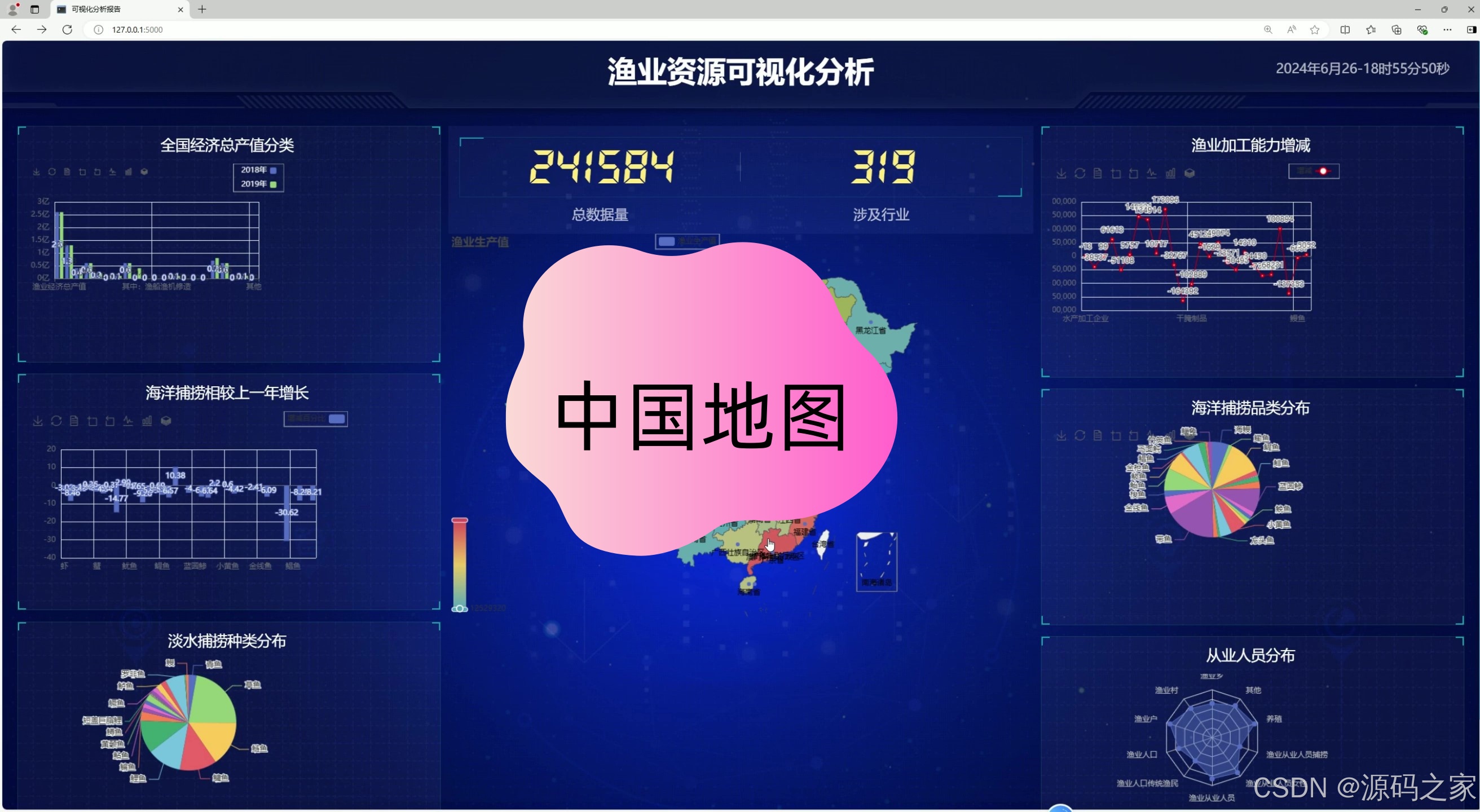
1、可视化分析大屏
2、渔业产能分布地图

在分析全国渔业产能分布时,数据显示山东、江苏和广东三省的产能位居前列。这三个沿海省份由于其得天独厚的地理优势和发达的渔业基础设施,成为了中国渔业产量的重要支柱。山东省以其广阔的海域和丰富的物种资源,成为了领头羊。江苏紧随其后,其产能的高位不仅得益于宽广的海岸线,还源于其先进的渔业技术和管理。广东省则凭借温暖的气候和充足的阳光,为各类海产品提供了良好的生长环境。
3、海洋捕捞品类分布
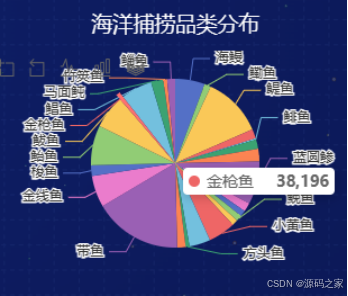
当前海洋捕捞中,带鱼的产量占据了主导地位,其后是金线鱼等其他品种。带鱼以其广泛的市场需求和相对稳定的生态数量,在捕捞量上一直保持领先。金线鱼以及其它一些经济价值较高的鱼类也构成了重要的捕捞对象,这些品种的捕捞在一定程度上反映了中国海洋捕捞业的发展趋势与市场需求。
4、从业人员比重分布
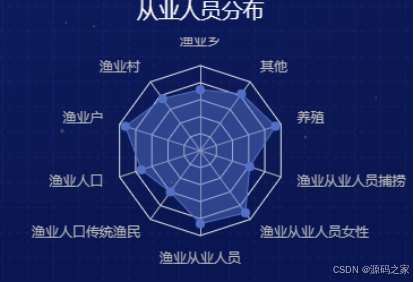
渔业人员构成的雷达图表明,渔业户和养殖业占据了较大的比重,其次是直接从事捕捞的从业人员。渔业户的大比例体现了中国渔业的家庭作坊特色,而养殖业的兴起则是近年来渔业发展的一个重要趋势。从业人员的分布也显示了渔业产业链的多样化和从业人员技能的多元化需求。
5、淡水捕捞品种数量分布图
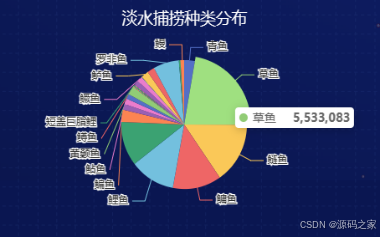
在淡水捕捞领域,草鱼、鲢鱼和鳙鱼的总产量占据了半数以上,显示出这三种鱼类在淡水水域的主导地位。这些品种不仅适应性强,生长周期短,而且市场需求量大,因此,成为了淡水捕捞中的主要对象。
6、海洋捕捞较去年增长图
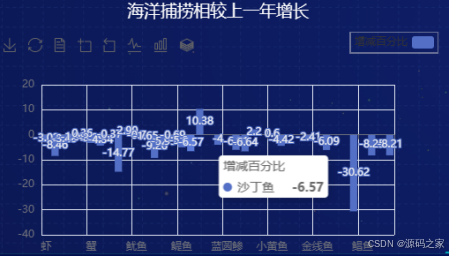
分析近年的数据可以看出,海洋捕捞的总体趋势呈现出下降的状态。这可能与海洋资源的过度捕捞、生态环境的变化以及国家对海洋保护政策的加强有关。这一变化促使业界重新审视捕捞行为,推动着渔业资源的可持续利用。
7、全国渔业经济总产值
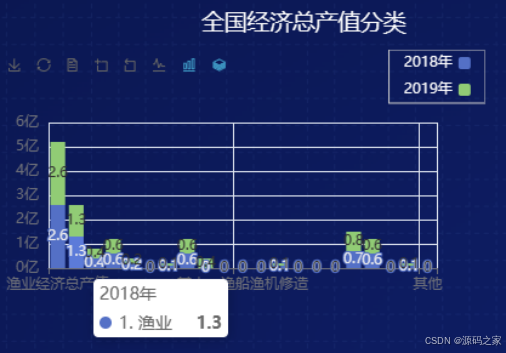
尽管面临种种挑战,全国渔业经济总产值却呈现上升趋势。这一增长可能得益于渔业增值服务的发展,如休闲渔业、高值海产品的深加工等,这些都为渔业经济的增长提供了新的动力。
8、渔业加工能力增减
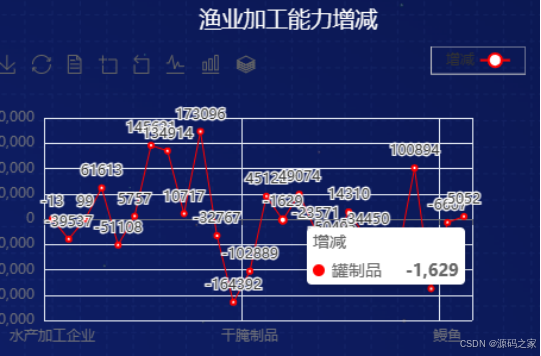
在渔业加工领域中,水产品干腌制品的生产能力突显增长,这一方面得益于现代消费者对健康、便捷食品的需求上升,另一方面也反映了渔业加工行业在产品多样化和保质保鲜技术上的进步。
3、项目说明
摘 要
随着信息技术的不断发展,数据可视化在各个领域中得到了广泛的应用。渔业资源数据的可视化系统也成为了渔业管理和研究中不可或缺的工具。本次课题旨在设计和开发一个针对渔业资源数据的可视化系统,以便更好地理解和利用渔业资源数据。
系统选择Flask框架,采用了Scrapy爬虫技术,使用Pycharm作为开发工具,选择MySQL组织后台数据库,使用Python为编程语言,内嵌了Pandas库,同时配合NumPy,Echarts进行进行开发,分别实现渔业产能分布地图、海洋捕捞品类、从业人员比重、淡水捕捞品种数量分布图、海洋捕捞较去年增长、全国渔业经济总产值的可视化展示等功能。
关键词:数据分析;自动化;可视化;Web应用;Python
渔业资源数据可视化系统基本达到了预期的目标。使用PyCharm进行开发,使用Navicat和MySQL管理数据库,利用Python语言和Flask框架开发,结合Echarts实现了大屏可视化。系统开发页面直观清晰且能稳定运行。系统主要实现一下功能:
(1)可视化大屏主页面的展示。
(2)渔业产能分布地图的可视化展示。
(3)海洋捕捞品类的可视化展示。
(4)从业人员比重的可视化展示。
(5)淡水捕捞品种数量分布图的可视化展示。
(6)海洋捕捞较去年增长的可视化展示。
(7)全国渔业经济总产值的可视化展示。
(8)渔业加工能力增减的可视化展示。
渔业资源数据可视化系统可以帮助用户更清晰地查看每个省渔业数据和相关信息。系统通过大数据相关技术,将渔业数据、鱼类数据、渔业加工能力、捕捞量,例如:渔业数据的产值、海鱼种类、淡水鱼种类、从业人员、分布;鱼类数据的属性:渔业加工能力的名称、时间、企业类型、能力指数以及捕捞量的类型、产地、数量和时间范围可视化展示出来。根据对全国渔业产能的分布分析,数据呈现出山东、江苏和广东三省的渔业产能处于领先地位。进一步的研究揭示,海洋捕捞领域中,带鱼产量位居榜首,紧随其后的是金线鱼等其他品种。渔业人员构成的雷达图清晰展示了渔业户和养殖业在整体人员结构中的显著比重,其次是从事捕捞工作的从业人员。而在淡水捕捞领域,草鱼、鲢鱼和鳙鱼的总产量超过半数,突显了这三种鱼类在淡水水域的重要地位。这些数据不仅进一步强调了全国渔业产能分布的特点和趋势,而且,为深入探讨渔业行业的结构和资源利用提供了重要参考。整个系统构成了一个强大的工具集,使得从数据收集到处理、分析直至最后的数据可视化和报告生成的各个环节都能高效、顺畅地运行。
在系统界面和用户交互设计方面,尚未实现最佳实践,部分界面可能过于复杂或不直观,影响了用户体验和系统的易用性;在系统开发中,未充分考虑到安全性方面的问题,这可能会导致系统面临数据泄露或恶意攻击的风险,对系统的稳定性和安全性构成威胁。综上所述,系统的基本开发工作已完成,但鉴于技术水平的限制,部分功能尚未实现,系统的功能仍有许多提升的空间。
4、核心代码
from flask import Flask, render_template
from flask_sqlalchemy import SQLAlchemy
from pyecharts.charts import Map
from pyecharts import options as opts
import pandas as pd
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://username:password@localhost/dbname'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app)
class ProductStatistics(db.Model):
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
product_name = db.Column(db.String(255), nullable=False)
year = db.Column(db.Integer)
production = db.Column(db.BigInteger)
absolute_change = db.Column(db.BigInteger)
percentage_change = db.Column(db.Float)
@app.route('/')
def index():
# 读取数据
df = pd.read_excel('data/全国数据渔业产值.xlsx')
# 预处理数据,将省份名称转换为地图可以识别的形式
province_name_map = {
'北京': '北京市',
'天津': '天津市',
'河北': '河北省',
'山西': '山西省',
'蒙': '内蒙古自治区',
'辽宁': '辽宁省',
'吉林': '吉林省',
'黑龙江': '黑龙江省',
'上海': '上海市',
'江苏': '江苏省',
'浙江': '浙江省',
'安徽': '安徽省',
'福建': '福建省',
'江西': '江西省',
'山东': '山东省',
'海南': '海南省',
'湖北': '湖北省',
'湖南': '湖南省',
'广西': '广西壮族自治区',
'重庆': '重庆市',
'四川': '四川省',
'贵州': '贵州省',
'云南': '云南省',
'西藏': '西藏自治区',
'陕西': '陕西省',
'甘肃': '甘肃省',
'青海': '青海省',
'宁夏': '宁夏回族自治区',
'新疆': '新疆维吾尔自治区',
'河南': '河南省',
'广东': '广东省'
}
df['省份'] = df['省份'].str.strip()
df['省份'] = df['省份'].map(province_name_map)
# 将 '合 计' 列的数据转换为数值类型,错误的转换将被设置为 NaN
df['合 计'] = pd.to_numeric(df['合 计'], errors='coerce')
# 使用 0 填充 NaN 值
df['合 计'] = df['合 计'].fillna(0)
def map_visualize(data_frame, province_col, value_col, title):
province = data_frame[province_col].tolist()
value = data_frame[value_col].tolist()
c = (
Map()
.add(title, [list(z) for z in zip(province, value)], "china")
.set_global_opts(
title_opts=opts.TitleOpts(title=title),
visualmap_opts=opts.VisualMapOpts(max_=max(value)),
)
)
return c
# 创建地图
map_total = map_visualize(df, "省份", "合 计", "渔业生产值")
# 渲染地图到 HTML 文件
map_total.render("渔业生产值.html")
# 最后使用 render_embed 方法渲染地图
map_total = map_total.render_embed()
result = {
'all_count': 1000,
'today_count': 20
}
return render_template('index.html', map_total=map_total,result=result)
if __name__ == "__main__":
app.run(debug=True)
import pandas as pd
from pyecharts.charts import Bar
from pyecharts import options as opts
# 读取Excel文件
df = pd.read_excel('data/全国渔业经济总产值.xlsx')
# 提取年份列作为x轴数据
categories = df['指 标'].tolist()
# 提取2018年和2019年的数据,并将非数值类型的数据和空值替换为0
data_2018 = (pd.to_numeric(df['2018年'], errors='coerce').fillna(0) / 100000000).round(1).tolist()
data_2019 = (pd.to_numeric(df['2019年'], errors='coerce').fillna(0) / 100000000).round(1).tolist()
# 创建柱状图对象
bar = Bar(init_opts=opts.InitOpts(width="1600px", height="800px"))
# 添加x轴数据
bar.add_xaxis(categories)
# 添加y轴数据
bar.add_yaxis('2018年', data_2018)
bar.add_yaxis('2019年', data_2019)
# 设置全局配置项
bar.set_global_opts(
toolbox_opts=opts.ToolboxOpts(item_size=10, pos_top="0%", pos_left="0%"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="right", orient="vertical", item_width=10, item_height=10, textstyle_opts=opts.TextStyleOpts(color="white")),
# 设置y轴的最小值为0
yaxis_opts=opts.AxisOpts(min_=0, axislabel_opts=opts.LabelOpts(formatter="{value}亿")),
)
# 渲染图表
bar.render('全国渔业经济总产值.html')
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 52
52 0
0- 0



 已为社区贡献76条内容
已为社区贡献76条内容

所有评论(0)