Dify+数据库+ECharts打造数据可视化图表,让数据自己说话!
今天分享一下如何利用Dify平台,结合强大的Echarts图表库,轻松搭建工作流。将数据库中的数据直接转化为精美的可视化图表,让数据开口说话。
前言
厌倦了盯着冰冷、枯燥的数据却找不到重点?
想象一下,只需简单几步,这些数据就能变身为令人惊艳的炫酷图表,瞬间抓住所有人的眼球!
释放数据的真正潜力,用 Echarts 让你的数据“活”起来,讲述它自己的故事。
图表作为一种直观、高效的数据呈现方式,能够化繁为简,让冰冷的数据焕发活力,帮助我们更好地理解和分析信息。
下图是Echarts官网上各种图表示例,是不是还挺炫酷的。
今天分享一下如何利用Dify平台,结合强大的Echarts图表库,轻松搭建工作流。
将数据库中的数据直接转化为精美的可视化图表,让数据开口说话。
1 Mysql数据库准备
在开始数据可视化之旅前,我们需要先准备好数据源。
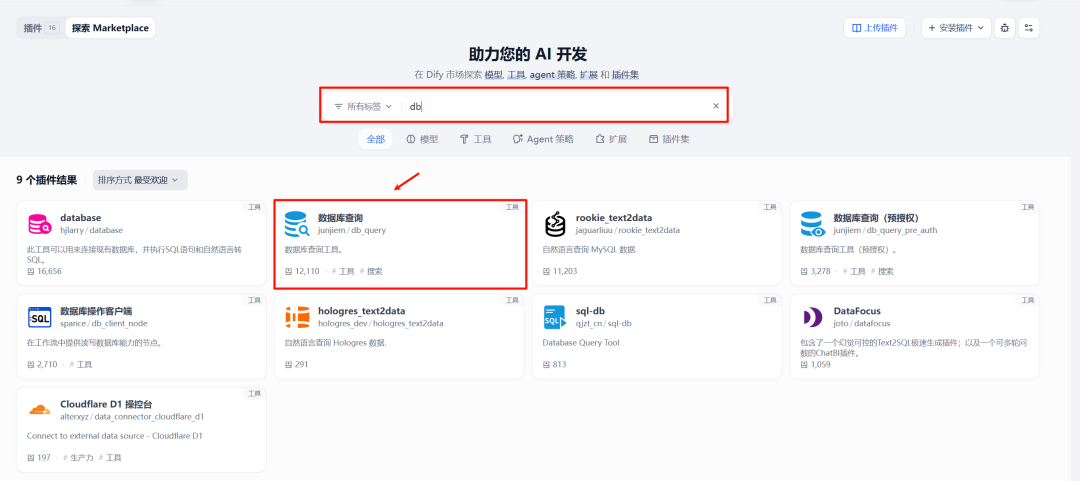
1.1 安装数据库插件
在插件市场搜索“db”可以看到数据库相关的插件。这次使用下图的数据库查询插件。
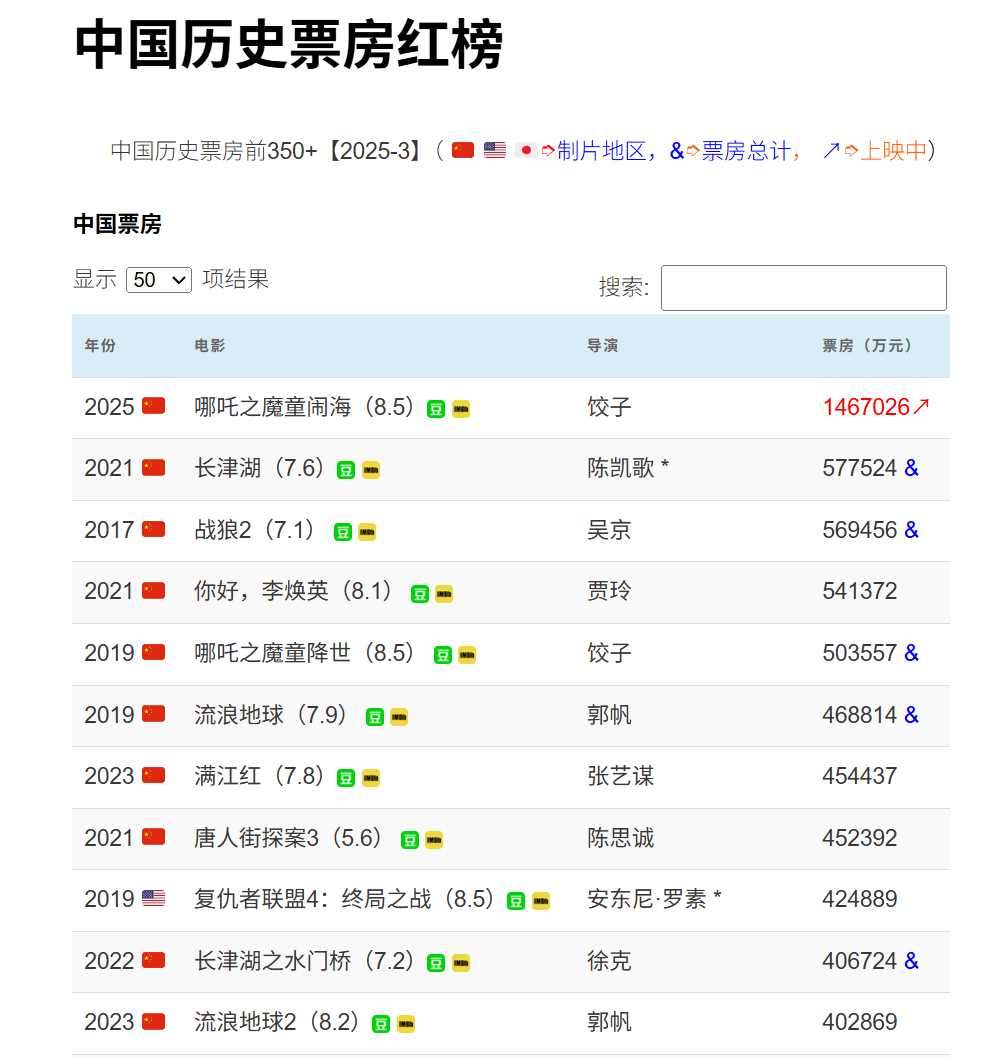
1.2 新建库表
这次就用中国历史票房红榜的数据了。
我们选取其中的年份、电影名称、评分、导演、票房来新建数据表。
新建数据库test。
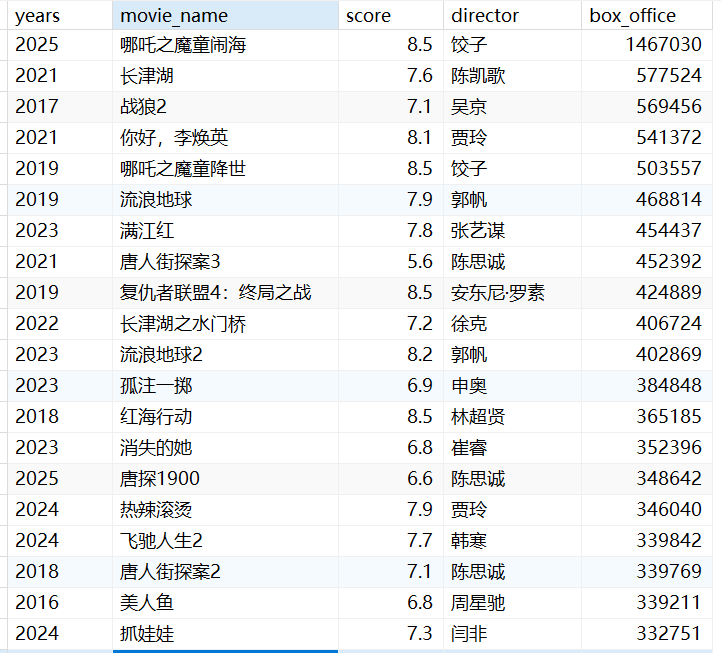
新建数据库表boxoffice结构如下:
-- ----------------------------
-- Table structure for boxoffice
-- ----------------------------
DROPTABLE IF EXISTS `boxoffice`;
CREATETABLE `boxoffice` (
`years` varchar(64) CHARACTERSET utf8 COLLATE utf8_unicode_ci NULLDEFAULTNULL,
`movie_name` varchar(255) CHARACTERSET utf8 COLLATE utf8_unicode_ci NULLDEFAULTNULL,
`score` floatNULLDEFAULTNULL,
`director` varchar(64) CHARACTERSET utf8 COLLATE utf8_unicode_ci NULLDEFAULTNULL,
`box_office` floatNULLDEFAULTNULL
) ENGINE = MyISAM CHARACTERSET= utf8 COLLATE= utf8_unicode_ci ROW_FORMAT =Dynamic;
数据如下:
2 Echarts插件工作流
完成数据库准备后,就可以在Dify中搭建工作流,实现数据的自动化图表转换。
首先安装Echarts图表插件。
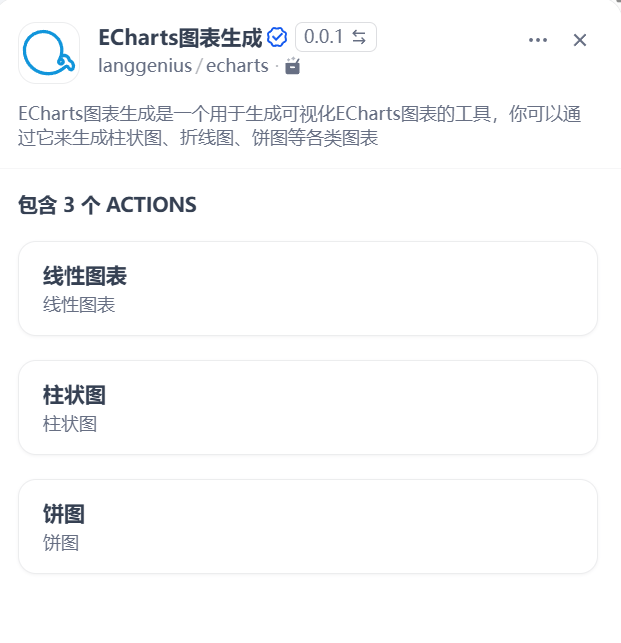
看一下这个插件的详情,目前只支持线性图表、柱状图、饼图三种类型。
整体工作流如下:

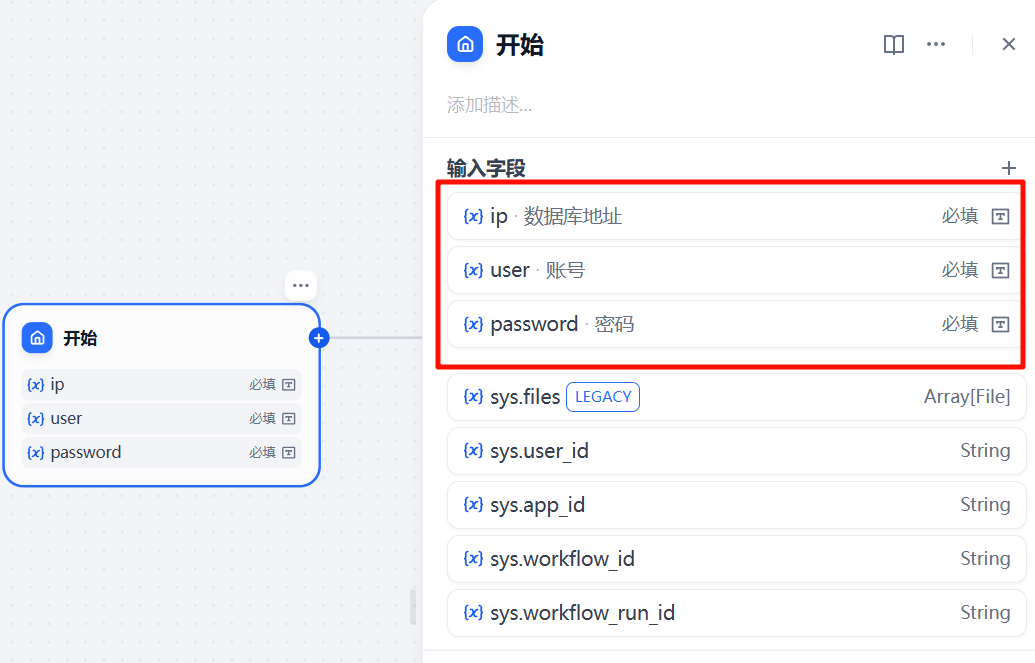
2.1 开始节点
开始节点新增了三个变量,输入Mysql数据库IP、账号和密码。
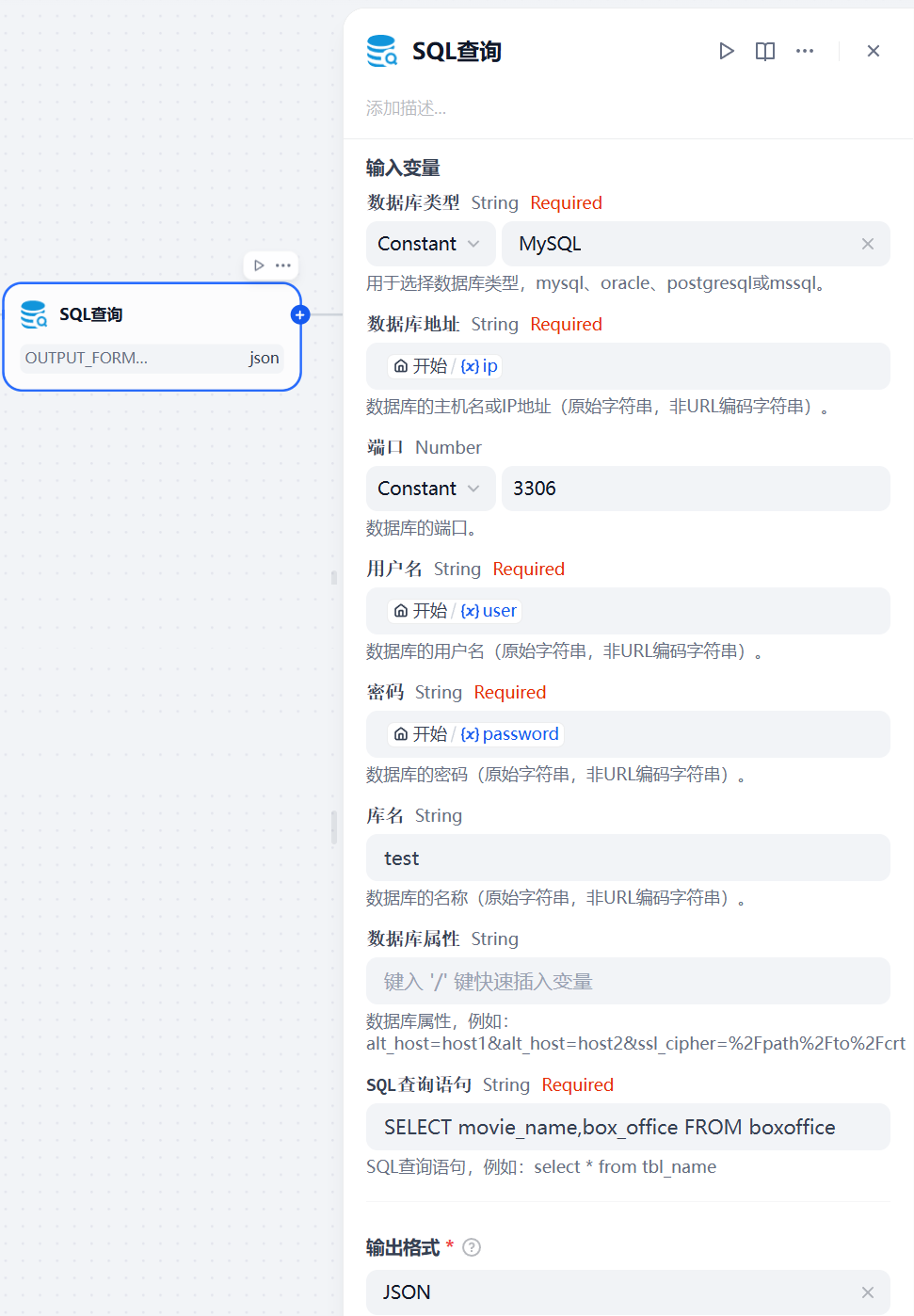
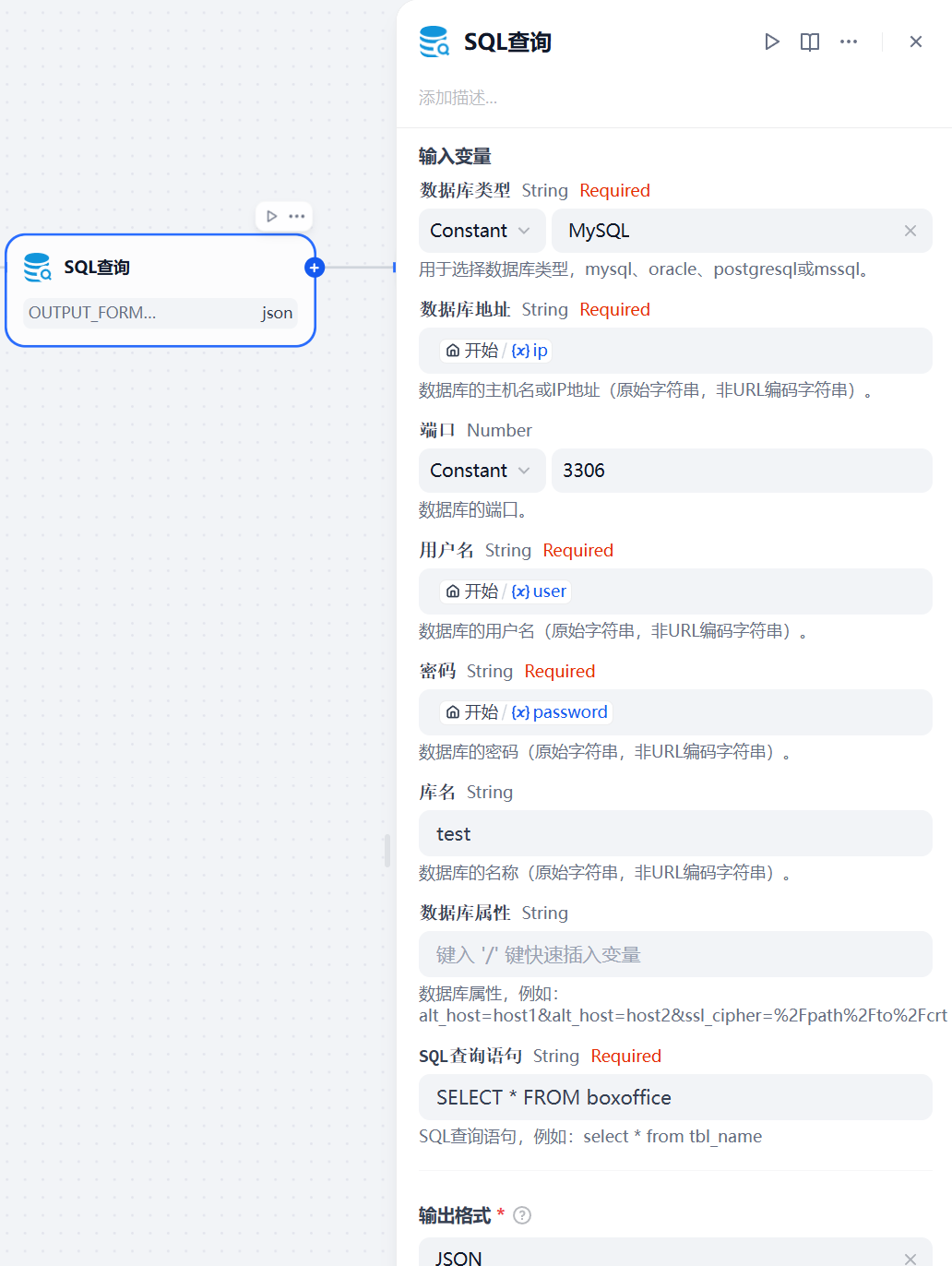
2.2 数据库节点
输入参数:
1、数据库类型:选择MySQL
2、数据库地址:关联开始节点的IP地址
3、端口:3306,如果你不是默认端口,根据实际来设置
4、用户名:关联开始节点的数据库用户名
5、密码:关联开始节点的数据库密码
6、库名:test,根据你实际的数据库名设置
7、SQL查询语句:SELECT movie_name,box_office FROM boxoffice,我这里只需要电影名称和票房生成柱状图。
输出参数:这里为json格式,方便后续处理数据。
2.3 代码执行节点
为Echart图表X轴和Y轴的数据。X轴为电影名称,Y轴为票房。
输入变量关联数据库查询节点的json输出。
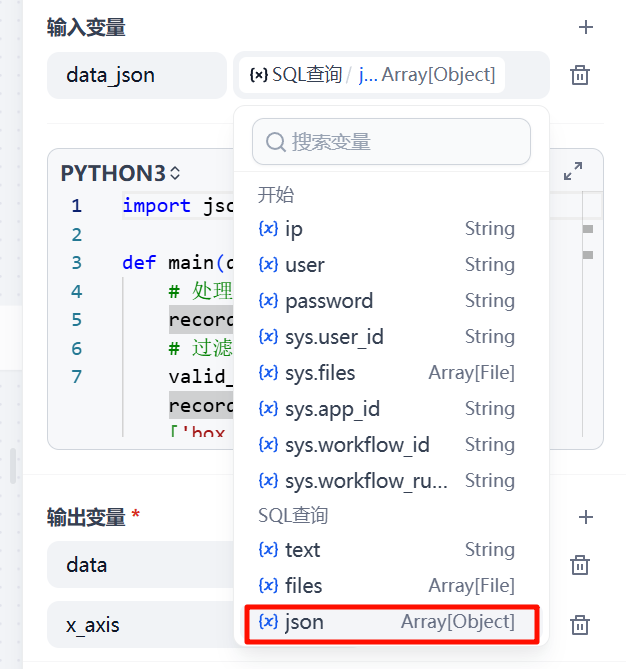
输出变量为data和x_axis。
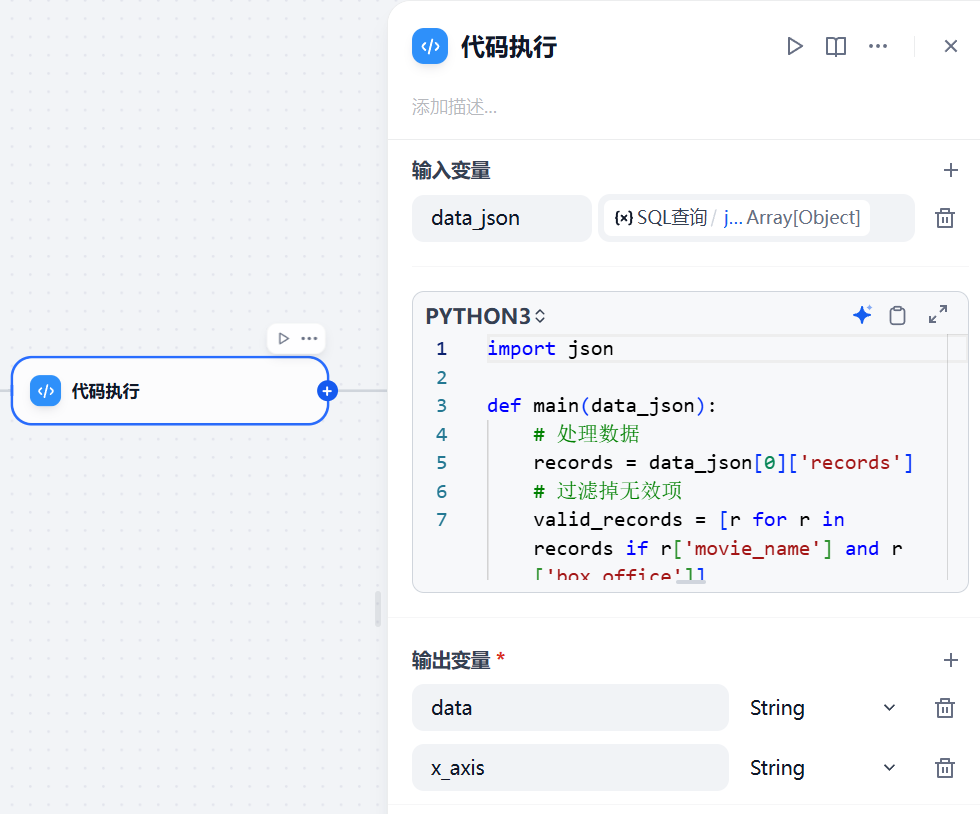
从数据库查询返回的电影票房数据中,筛选出有效的电影名称和票房信息。
将所有电影的票房用分号“;”拼接成一个字符串,所有电影名称也用分号“;”拼接成一个字符串。
分别作为柱状图的“数据”和“x轴”参数输出,方便后续直接用于柱状图插件进行可视化展示。
import json
defmain(data_json):
# 处理数据
records = data_json[0]['records']
# 过滤掉无效项
valid_records = [r for r in records if r['movie_name'] and r['box_office']]
# 生成柱状图需要的参数
data = ";".join(str(r['box_office']) for r in valid_records)
x_axis = ";".join(r['movie_name'] for r in valid_records)
return {
"data": data,
"x_axis": x_axis
}
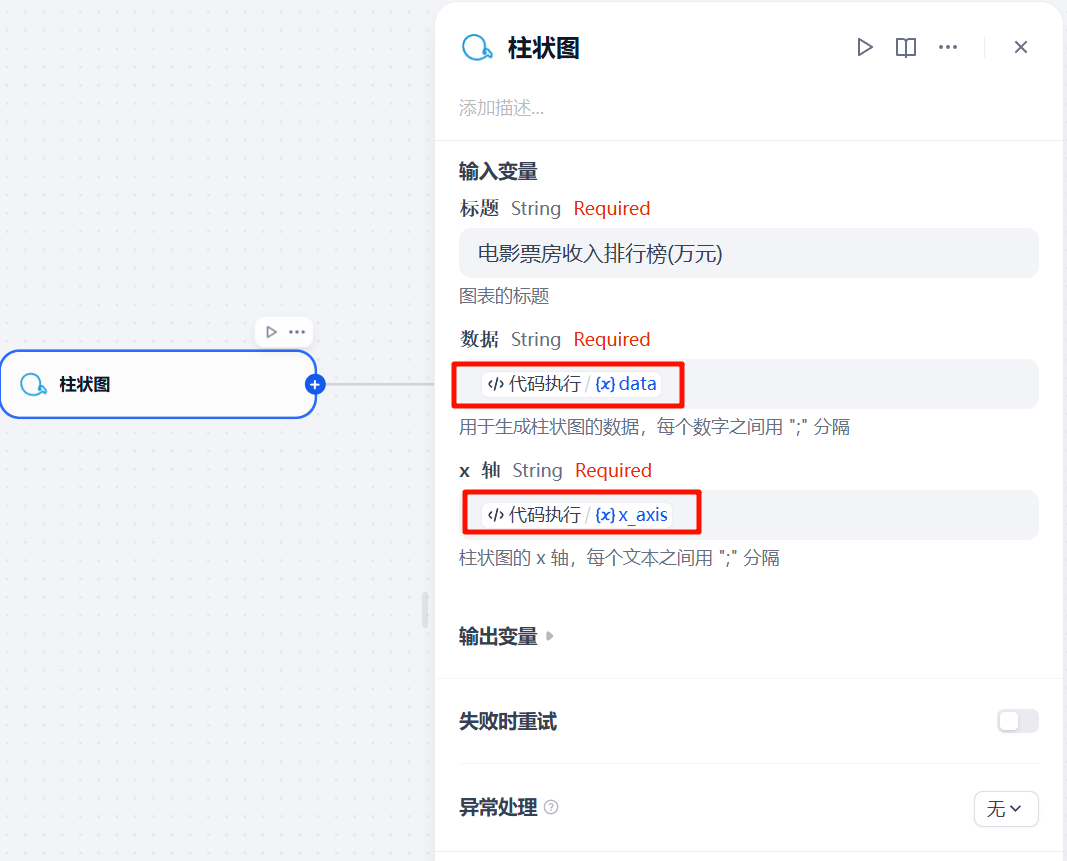
2.4 Echarts图表节点
输入图表标题、数据和X轴。
2.5 结束节点
2.6 测试
输入数据库IP地址、账号及密码。

看到可以生成漂亮的柱状图了。
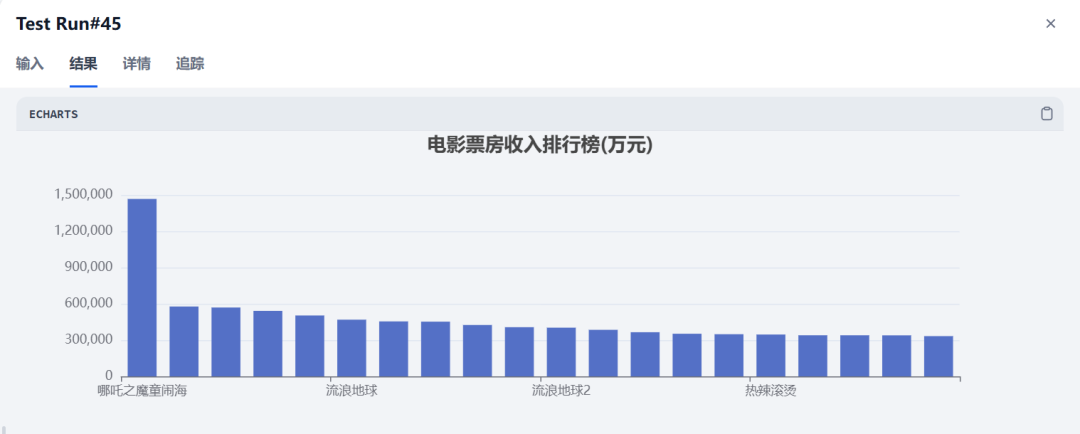
SQL节点的输出为json格式的数据,是一个列表。
所以代码执行节点的输入就是这个列表,列表的第一个数据是字典类型,取得record键值的数据。
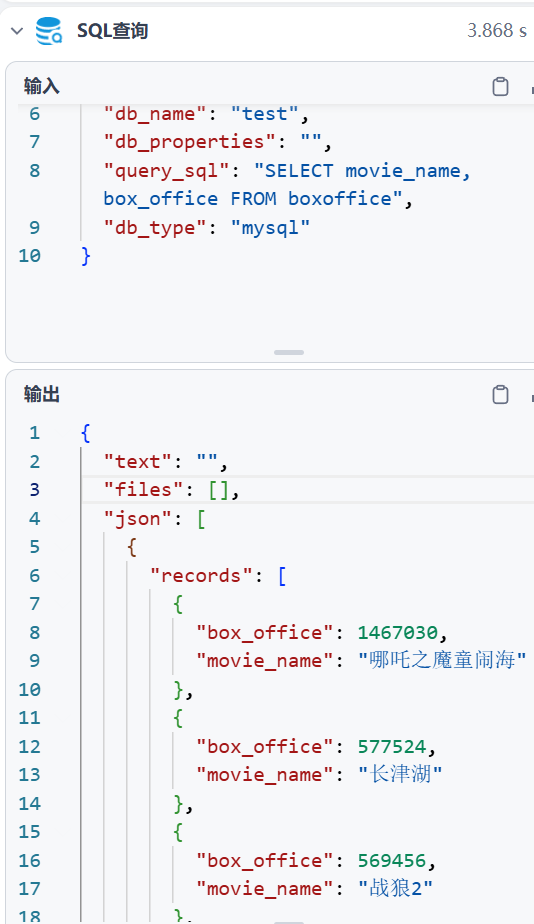
看一下柱状图的输入,data和x轴的数据都是字符串,数据用分号分隔。
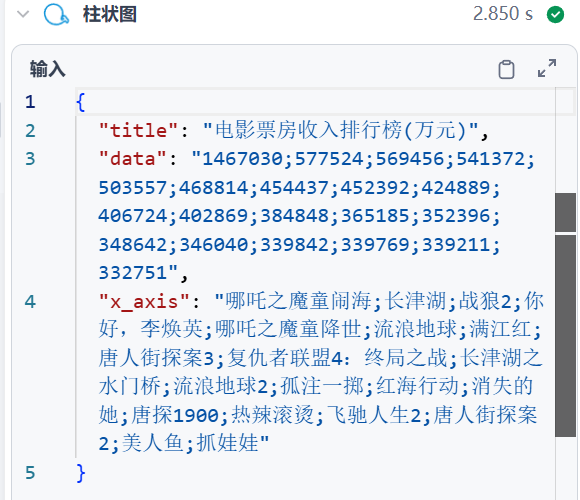
关于折线图和饼图的使用方式与柱状图类似,都是构建data和x轴的数据。
3 Echarts任意图表对话流
在刚才的示例中可以发现,目前Echart图表支持的图形比较有限。
如果我们想在Dify中支持其他类型的图表,可以直接使用代码节点实现。
还可以多个图表组合在一起。
我用个对话流来完成吧。整体流程如下:

3.1 开始节点
增加数据库地址、用户名、密码三个字段。其实这几个变量也可以直接在数据库中设置的。
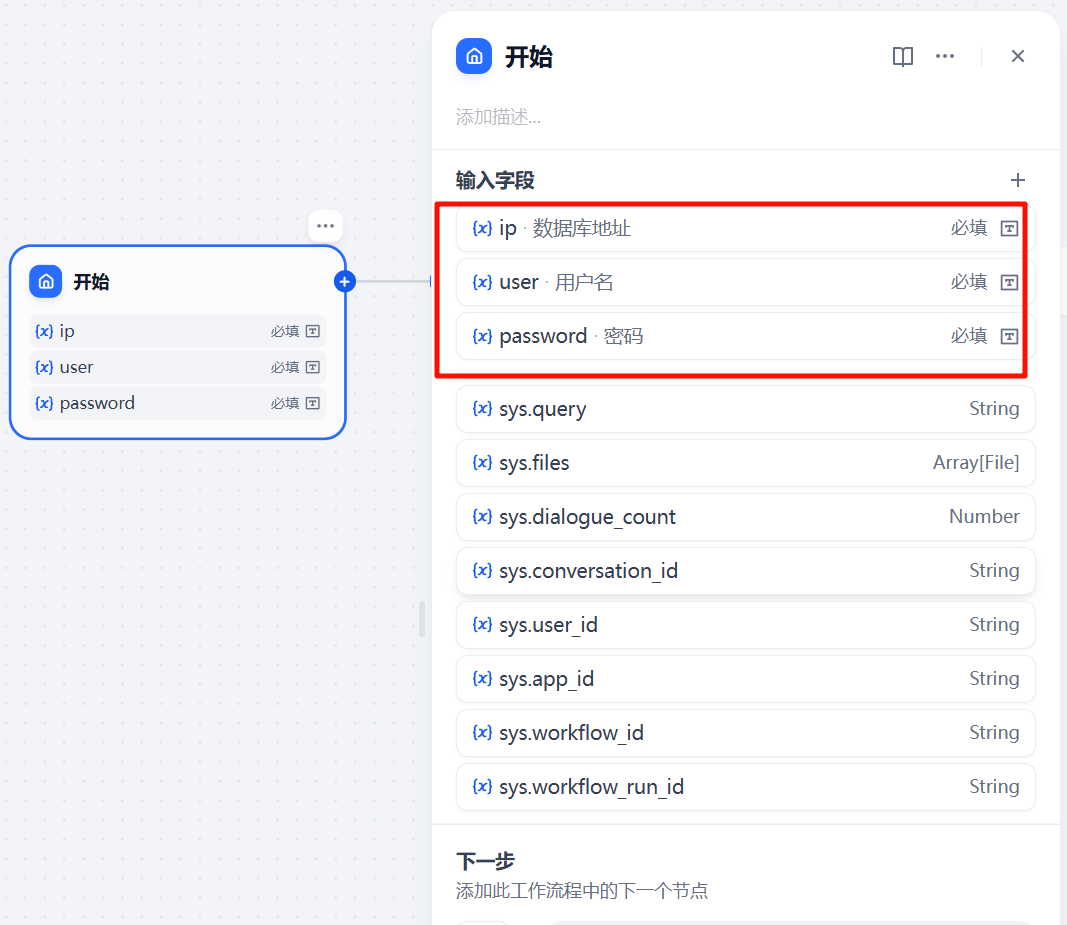
3.2 数据库节点
和2.2节类似,只是SQL语句不一样。
这里把所有字段都提取出来。
SELECT * FROM boxoffice
3.3 代码执行节点
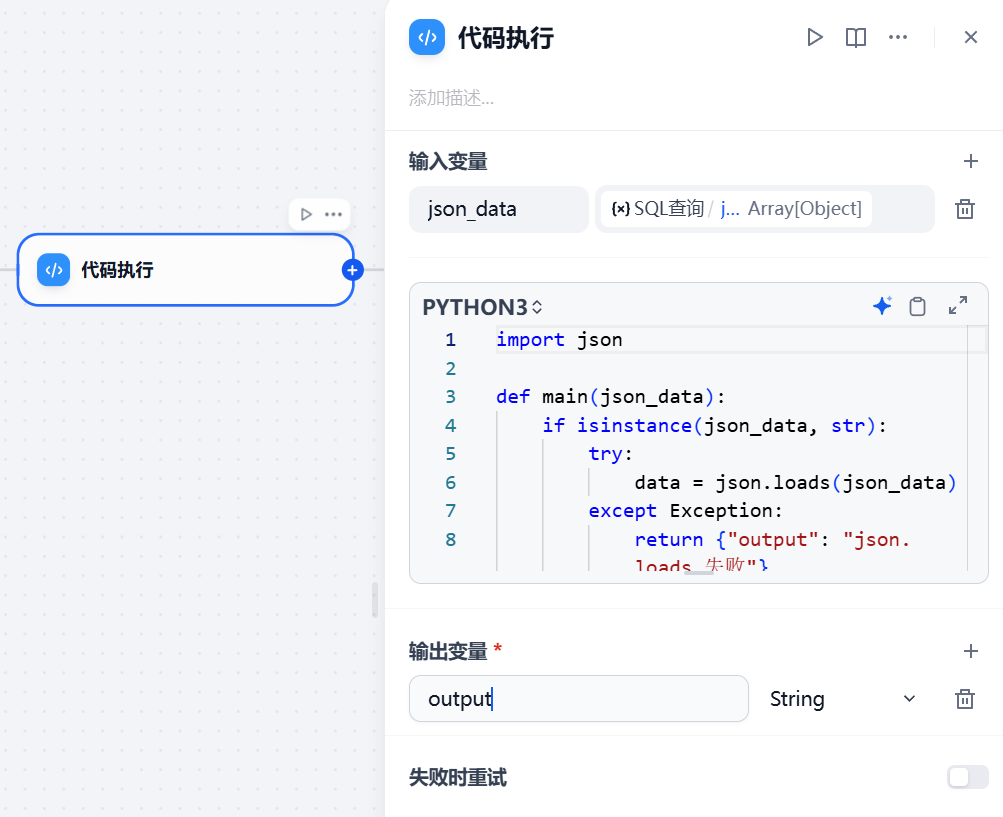
重头戏在这里了。
输入变量关联数据库节点的json数据。
输出变量为output,字符串类型。
代码如下:
import json
defmain(json_data):
"""
将电影票房和评分数据转换为 Echarts 散点图配置
:param json_data: 输入的 json 数据(已知为列表类型,且结构固定)
:return: {"output": markdown 格式的 echarts 配置}
"""
records = json_data[0]['records']
# 数据清洗与转换
scatter_data = []
for record in records:
name = str(record.get("movie_name", "")).strip()
box_office = record.get("box_office", "")
rating = record.get("score", "")
ifnot name or box_office in ("", None) or rating in ("", None):
continue
scatter_data.append([name, box_office, rating])
# 构建 Echarts 配置
echarts_config = {
"title": {
"text": "电影票房收入与观众评分的关系",
"subtext": "数据来源:中国票房红榜",
"left": "center"
},
"tooltip": {
"trigger": "item",
"formatter": "{c}"
},
"xAxis": {
"name": "票房收入 (万元)",
"type": "value",
"min": 0,
"max": 1500000
},
"yAxis": {
"name": "观众评分",
"type": "value",
"min": 0,
"max": 10
},
"series": [
{
"name": "电影",
"type": "scatter",
"data": [[row[0], row[1], row[2]] for row in scatter_data],
"symbolSize": 10,
"label": {
"show": False,
},
"encode": {
"x": 1,
"y": 2,
"tooltip": [0, 1, 2]
}
}
]
}
output = "```echarts\n" + json.dumps(echarts_config, indent=2, ensure_ascii=False) + "\n```"
return {"output": output}
# 你可以用如下方式测试
# result = main(json_data)
# print(result)
整个代码主要为四部分:数据读取、数据清洗和转换、构建 Echarts 配置、输出。
最后将 Echarts 配置用 markdown 代码块(echarts … )的形式输出,便于在支持 Echarts 的平台直接渲染出可视化图表。
代码的核心在于构建 Echarts 配置。
其他图形也是大同小异,根据实际图形修改即可。
不会写的也不要紧,扔给AI就可以了。
1. title(标题)
“text”:主标题,这里是“电影票房收入与观众评分的关系”。
“subtext”:副标题,注明数据来源。
“left”:标题居中显示。
2. tooltip(提示框)
“trigger”: “item”,鼠标悬停在某个点上时显示提示框。
“formatter”: “{c}”,提示框内容显示该点的所有数据(即 [电影名, 票房, 评分])。
3、xAxis(x 轴配置)
“name”:x 轴名称,这里是“票房收入 (万元)”。
“type”: “value”:x 轴为数值轴。
“min”/“max”:设置x轴的最小值和最大值,保证坐标轴范围合适。
4. yAxis(y 轴配置)
“name”:y 轴名称,这里是“观众评分”。
“type”: “value”:y 轴为数值轴。
“min”/“max”:设置y轴的最小值和最大值(0~10分)。
5. series(数据系列)
“name”:系列名称,这里是“电影”。
“type”: “scatter”:图表类型为散点图。
“data”:数据部分,格式为 [[电影名, 票房, 评分], …],每个点包含电影名、票房、评分。
“symbolSize”:每个点的大小,这里固定为10。
“label”:标签设置,“show”: False 表示不直接在点上显示标签。
“encode”:数据维度映射
“x”: 1:第2列(票房)作为x轴
“y”: 2:第3列(评分)作为y轴
“tooltip”: [0, 1, 2]:提示框显示全部三列(电影名、票房、评分)
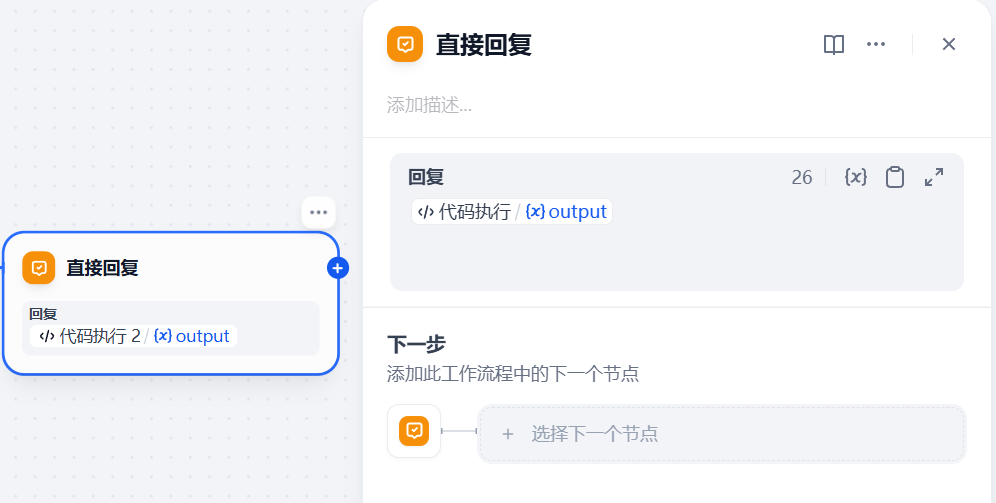
3.4 直接回复
关联代码执行节点的output变量。
3.5 测试
测试的时候也是输入数据库地址、用户名和密码。
散点图表生成好了。
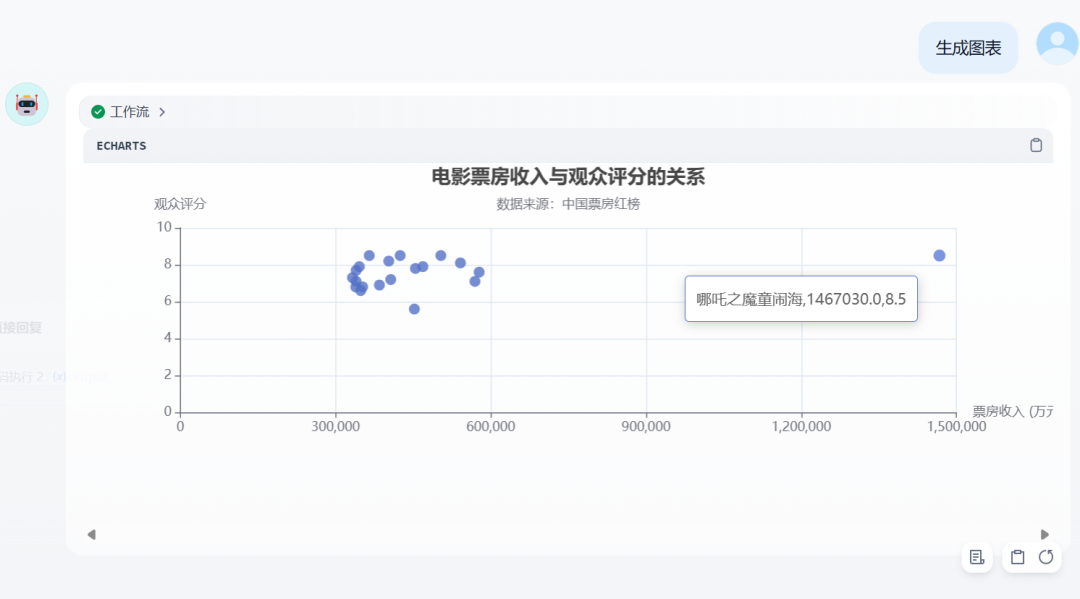
散点图非常适合分析异常数据。
最明显的异常值就是右侧的《哪吒之魔童闹海》电影,评分和票房远远高于其他电影。
还有最下面的观众评分最低的电影《唐人街探案3》,属于高票房低评分。
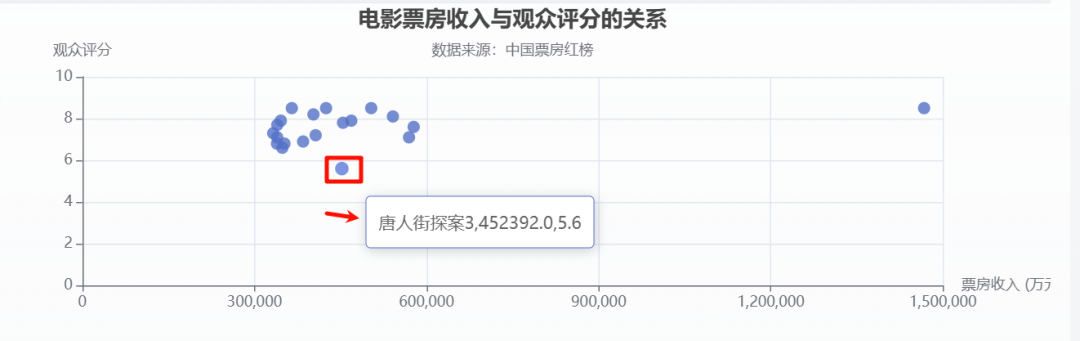
也很容易观察到最高票房、最低票房、最高评分、最低评分的电影。
最高票房:哪吒之魔童闹海 (1467026 万元)
最低票房:抓娃娃 (332751 万元)
最高评分:多部电影评分为 8.5
最低评分:唐人街探案3 (5.6)
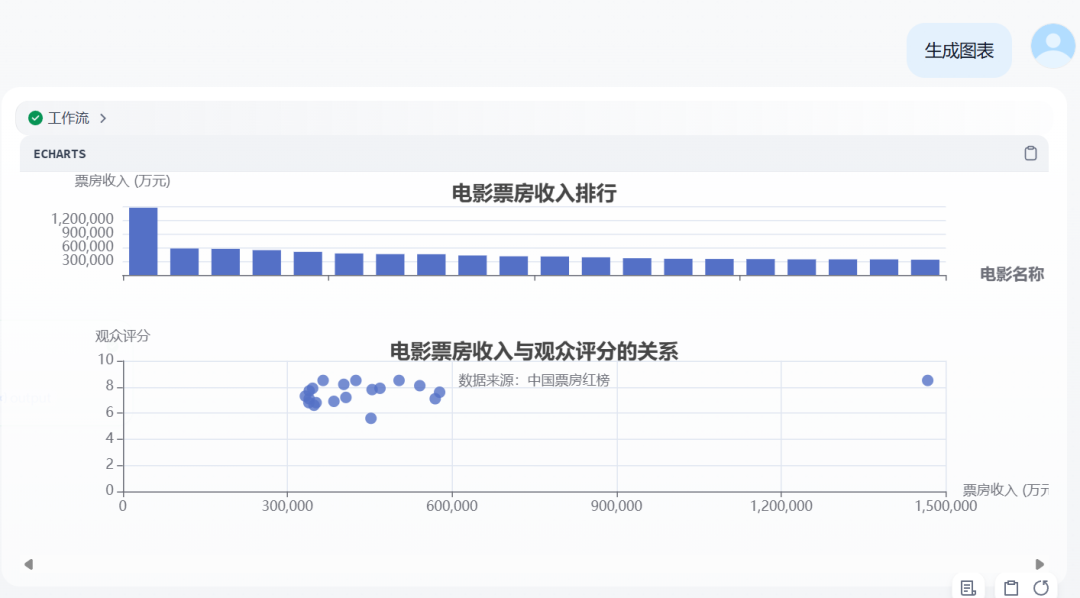
除了生成单图外,也可以在代码节点中直接生成两张图表,如下。
需要更改一下代码的内容。
通过本文的介绍,我们看到Dify平台为连接数据库与Echarts图表提供了强大而灵活的桥梁。
无论是利用其内置插件快速生成常规图表,还是通过代码节点深度定制复杂的Echarts可视化方案,Dify都能有效地简化开发流程,提升数据呈现的效率与美观度。
但是我还是希望Echarts插件能够原生支持更多种类的图形,用户将能以更低的门槛、更便捷的方式,释放Echarts的全部可视化魅力。
数据,并非生来冰冷。
赋予它色彩,
赋予它形态,
它便有了温度。
每一张图表,
都是一个未被讲述的故事。
等待我们,
去聆听,
去发现。
用心去看,
数据会说话。
最后的最后
感谢你们的阅读和喜欢,作为一位在一线互联网行业奋斗多年的老兵,我深知在这个瞬息万变的技术领域中,持续学习和进步的重要性。
为了帮助更多热爱技术、渴望成长的朋友,我特别整理了一份涵盖大模型领域的宝贵资料集。
这些资料不仅是我多年积累的心血结晶,也是我在行业一线实战经验的总结。
这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。如果你愿意花时间沉下心来学习,相信它们一定能为你提供实质性的帮助。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)