图形学、人机交互、VR/AR、可视化等领域文献速读【持续更新中...】
本文提出了 Hier-SLAM,这是一种基于语义的三维高斯溅射 SLAM 方法,具备全新的层级类别表示方式,能够实现精准的全局三维语义建图、良好的扩展性,以及三维世界中显式的语义标签预测。随着环境复杂度的增加,语义 SLAM 系统的参数量急剧上升,使得场景理解变得尤为困难且成本高昂。为了解决这一问题,本文引入了一种。
(1)笔者在时间有限的情况下,想要多积累一些自身课题之外的新文献、新知识,所以开了这一篇文章。
(2)想通过将文献喂给大模型,并向大模型提问的方式来快速理解文献的重要信息(如基础idea、contribution、大致方法等)。
(3)计划周更4-5篇文献。
(4)文章内容大多由AI产生,经笔者梳理而成。如果有误,敬请批评指正。
文章目录
- 一、Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
- 二、DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation
- 三、Sample2SQL: A Visual Interface for Querying Risky Enterprises
- 四、ReLive: Walking into Virtual Reality Spaces from Video Recordings of One’s Past Can Increase the Experiential Detail and Affect of Autobiographical Memories
- 五、Mood-Driven Colorization of Virtual Indoor Scenes
一、Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting
作者:Boying Li, Zhixi Cai, Yuan-Fang Li, Ian Reid, and Hamid Rezatofighi
机构:Monash & MBZUAI
原文链接:https://arxiv.org/abs/2409.12518
代码链接:https://github.com/LeeBY68/Hier-SLAM
发表:ICRA 2025
摘要:
本文提出了 Hier-SLAM,这是一种基于语义的三维高斯溅射 SLAM 方法,具备全新的层级类别表示方式,能够实现精准的全局三维语义建图、良好的扩展性,以及三维世界中显式的语义标签预测。随着环境复杂度的增加,语义 SLAM 系统的参数量急剧上升,使得场景理解变得尤为困难且成本高昂。
为了解决这一问题,本文引入了一种紧凑的层级语义表示,将语义信息有效嵌入到 3D Gaussian Splatting 中,并借助大语言模型(LLM)的能力构建结构化语义编码。此外,本文设计了一种新的语义损失函数,通过层内(inter-level)和跨层(cross-level)联合优化,进一步提升层级语义信息的学习效果。本文还对整个 SLAM 系统进行了全面优化,显著提升了追踪建图性能及运行速度。
Hier-SLAM 在建图和定位精度方面均超越现有的稠密 SLAM 方法,并在运行速度上实现了 2 倍加速。同时,在语义渲染性能上也达到了与现有方法相当的水平,同时在存储开销与训练时间方面大幅下降。令人印象深刻的是,该系统的渲染速度可达每秒 2000 帧(含语义)或 3000 帧(无语义)。尤其重要的是,Hier-SLAM 首次展现了在超过 500 类语义场景中仍能高效运行的能力,充分体现了其强大的扩展性。
1. 什么是语义SLAM系统呢?
语义SLAM(Semantic SLAM)是同时定位与建图(SLAM)技术的升级版,它不仅构建环境的几何地图,还能识别并标注地图中物体的语义信息(如“椅子”“墙壁”“行人”),让机器真正“理解”周围场景。
2. 本文是如何实现层级语义表示与3D高斯泼溅的融合的?
(1)层级树结构构建:
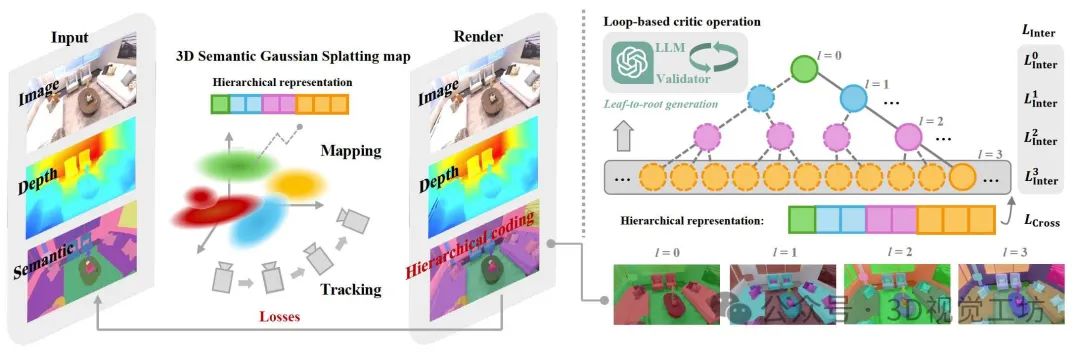
(i)语义树定义:将语义类别组织为树状结构 G=(V,E),其中节点 V 表示不同层级的语义类(如“背景→结构→平面→墙”),边 E 表示类别的从属关系。
(ii)LLM辅助生成:
- 输入一组语义标签(如ScanNet的550类),利用LLM(如GPT-4)自底向上迭代聚类,生成层次结构。
- 通过循环校验机制(Loop-based Critic)修正LLM输出:对比LLM生成的聚类结果与输入标签,剔除无关类别(Unseen
Classes)并补全遗漏节点(Omitted Nodes),直至所有标签被正确归类。
(2)紧凑编码设计:
每个3D高斯 primitive 的语义嵌入 h 由各层级嵌入h’拼接而成。
(3)语义优化策略:
- 层级内损失(Inter-level Loss):每层单独计算交叉熵损失,确保层级内分类正确性。
- 跨层级损失(Cross-level Loss):通过共享线性层 F 将层级编码映射为扁平概率分布,与真实标签计算全局交叉熵损失,保证层级间一致性。
通俗易懂的解释:
这篇文章的“语义压缩”方法,可以类比为整理一个杂乱的文件柜:
步骤1:用AI给文件分类(LLM建树)
把一堆未分类的文件(如550种物体标签)交给AI(如ChatGPT),让它按“大类→子类”自动整理。例如:第一层:“家具” vs “电器” 第二层:“家具”下分“椅子”“桌子”……
AI可能分错,所以加了自动修正程序:检查遗漏的标签(如“漏了台灯”),重新让AI补分,直到所有文件归位。
步骤2:给每个物体贴层级标签(紧凑编码)
以前:每个物体直接标记具体名称(如“办公椅”),需要大量标签。
现在:改为层级路径编码(如“家具/椅子/办公椅”),只需记录每层的选择(如1-2-3),大幅节省空间。
步骤3:双重检查(层级优化)
逐层检查:确保“椅子”确实属于“家具”。
整体检查:最终生成的标签(如“办公椅”)要与真实名称一致。
效果:
原本存1000种物体需要1000个标签,现在只需20个数字编码(类似压缩成文件夹路径)。
机器人看到“办公椅”时,既能知道它是“椅子”,也能明白它属于“家具”,适合高层决策(如“避开所有家具”)。
3.本文的核心贡献是什么?
(1)层次化语义表示:提出一种树状层次结构编码语义信息,利用大语言模型(LLM)生成语义类别的层次关系(如“背景→结构→平面→墙”),将语义信息压缩为紧凑的符号编码。例如,10层二叉树可覆盖1024个类别,仅需20维编码(每层2维Softmax)。通过几何与语义属性联合优化,构建多级树结构,显著减少存储需求(相比扁平表示降低66%)。
(2)层次化语义损失函数:设计跨层级(Cross-level)和层级内(Inter-level)联合优化损失,结合交叉熵损失,实现从粗到细的语义理解。
(3)高效SLAM系统:在3D高斯泼溅框架中集成层次化语义表示,优化跟踪(Tracking)与建图(Mapping)模块。系统在保持高精度(ScanNet数据集上ATE RMSE为3.2cm)的同时,实现2000 FPS(带语义)/3000 FPS(无语义)的实时渲染速度,存储需求降低至910.5MB(原需2.7GB)。
(4)扩展性验证:在包含550个语义类别的ScanNet数据集中,通过LLM辅助的层次化编码将语义参数压缩7倍,首次实现复杂场景的高效语义理解。
二、DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation

作者:Bangbang Yang, Wenqi Dong, Lin Ma, Wenbo Hu, Xiao Liu, Zhaopeng Cui, Yuewen Ma
机构:(1)PICO, ByteDance (2)State Key Lab of CAD&CG, Zhejiang University
文章链接:https://arxiv.org/abs/2310.13119
项目链接:https://ybbbbt.com/publication/dreamspace/
发表:IEEE VR 2024
摘要:
基于扩散模型的方法在二维媒体生成领域已取得显著成功,然而在三维空间应用(如XR/VR)中实现同等水平的场景级网格纹理生成仍面临挑战,主要受限于三维几何结构的复杂性及沉浸式自由视角渲染的技术要求。本文提出了一种创新的室内场景纹理生成框架,通过文本驱动生成具有精细细节与真实空间一致性的纹理。其核心思想是:首先从场景中心视角生成风格化的360°全景纹理,继而通过修复与模仿技术将其扩散至其他区域。为确保纹理与场景的语义对齐,我们开发了一种新颖的双重纹理对齐机制,采用由粗到细的全景纹理生成方法,同时考量场景的几何特征与纹理线索。针对纹理传播过程中的复杂几何干扰,我们设计了分离式处理策略:先在置信区域执行纹理修复,再通过隐式模仿网络合成被遮挡区域与微细结构的纹理。大量实验及真实室内场景的沉浸式VR应用证明,该方法能生成高质量纹理,并为VR头显设备提供引人入胜的体验。
1. 文章简介
本文《DreamSpace: Dreaming Your Room Space with Text-Driven Panoramic Texture Propagation》提出了一种创新的文本驱动室内场景纹理生成框架,旨在解决三维空间应用中场景级网格纹理合成的关键挑战。针对现有扩散模型在2D媒体生成的成功难以迁移到3D场景的问题,作者提出以下技术贡献:
(1)全景纹理生成:采用自上而下的流程,首先生成中心视点的360°风格化全景纹理,通过改进的潜在扩散模型(LDM)实现粗到细的生成策略,结合非对称环形填充和分块扩散技术保障高分辨率与无缝投影。
(2)双重纹理对齐:提出风格优先与对齐优先的双通道纹理生成机制,通过深度边缘感知的泊松混合解决几何-纹理错位问题,在保持风格质量的同时提升几何一致性。
(3)全场景纹理传播:设计分区域处理策略,对可见区域采用置信扩散修复,对遮挡/微小结构区域采用基于坐标的隐式纹理模仿网络(MLP),实现纹理的空间连贯性填充。
实验表明,该方法在真实场景数据集(DreamSpot/Replica)上显著优于StyleMesh、TEXTure等方法(CLIP分数提升14.4%,美学评分提升9.6%),并通过VR应用验证了其在头显设备中的沉浸式体验。局限性包括对PBR材质支持不足及超大场景适配性问题。
通俗易懂版介绍
这篇文章开发了一个叫DreamSpace的"AI装修神器",能用文字描述自动给3D房间模型换上梦幻风格的墙纸、地板和家具贴图。比如输入"星空主题",系统就会把房间变成银河效果,沙发、电视等物品还能保持原有形状但变成星空纹理。
核心技术有三招:
(1)全景照片生成:先站在房间中心,用AI生成一张包裹整个房间的360°全景风格图(类似手机全景拍照,但内容是AI画的星空/森林等主题)。
(2)智能对齐:通过"双保险"策略让贴图完美贴合家具边缘,避免出现扭曲或错位。
(3)死角填充:对于柜子缝隙、沙发底部等死角,AI会参考已生成部分智能补全,而不是简单复制。
实际效果:
(1)比传统方法贴图更精准,VR眼镜中观看时不会出现接缝或穿帮。
(2)支持实时渲染,生成的3D房间能直接导入VR设备漫游。
(3)目前局限是不能做金属反光等复杂材质,超大教堂类场景也暂不支持。
2. 介绍一下这篇文章中的framework
DreamSpace 是一个基于扩散模型(Diffusion Model)的 文本驱动室内场景纹理生成框架,旨在为 3D 场景网格(Mesh)生成高质量、语义一致且空间连贯的纹理。其核心流程分为三个阶段:
(1)全景纹理生成(Panoramic Texture Generation)
- 输入:用户文本描述(如“星空主题”)+ 真实场景的 3D 网格(带初始纹理和几何)。
- 方法:
粗到细生成:先用低分辨率全景扩散模型生成基础结构,再通过超分辨率提升细节。
双重纹理对齐(Dual Texture Alignment):生成“风格优先”和“对齐优先”两种纹理,并用深度边缘感知的泊松混合(Poisson Blending)优化几何贴合。 - 输出:高分辨率 360° 全景纹理(Equirectangular 投影)。
(2)初始纹理投影(Initial Texture Projection)
- 将全景纹理通过 UV 映射 投影到 3D 网格的可见部分,形成初步风格化场景。
(3)全场景纹理传播(Holistic Texture Propagation)
- 置信区域修复(Confidential Inpainting):在少量新视角下,用扩散模型修复未被初始全景覆盖的可见区域。
- 隐式纹理模仿(Implicit Texture Imitating):对遮挡区域(如家具底部、墙壁缝隙),训练一个 MLP 网络 从已风格化区域学习颜色映射,预测合理纹理。
- 最终输出:完整 UV 纹理贴图,可直接用于 3D 引擎(如 Unity/Unreal)或 VR 设备。
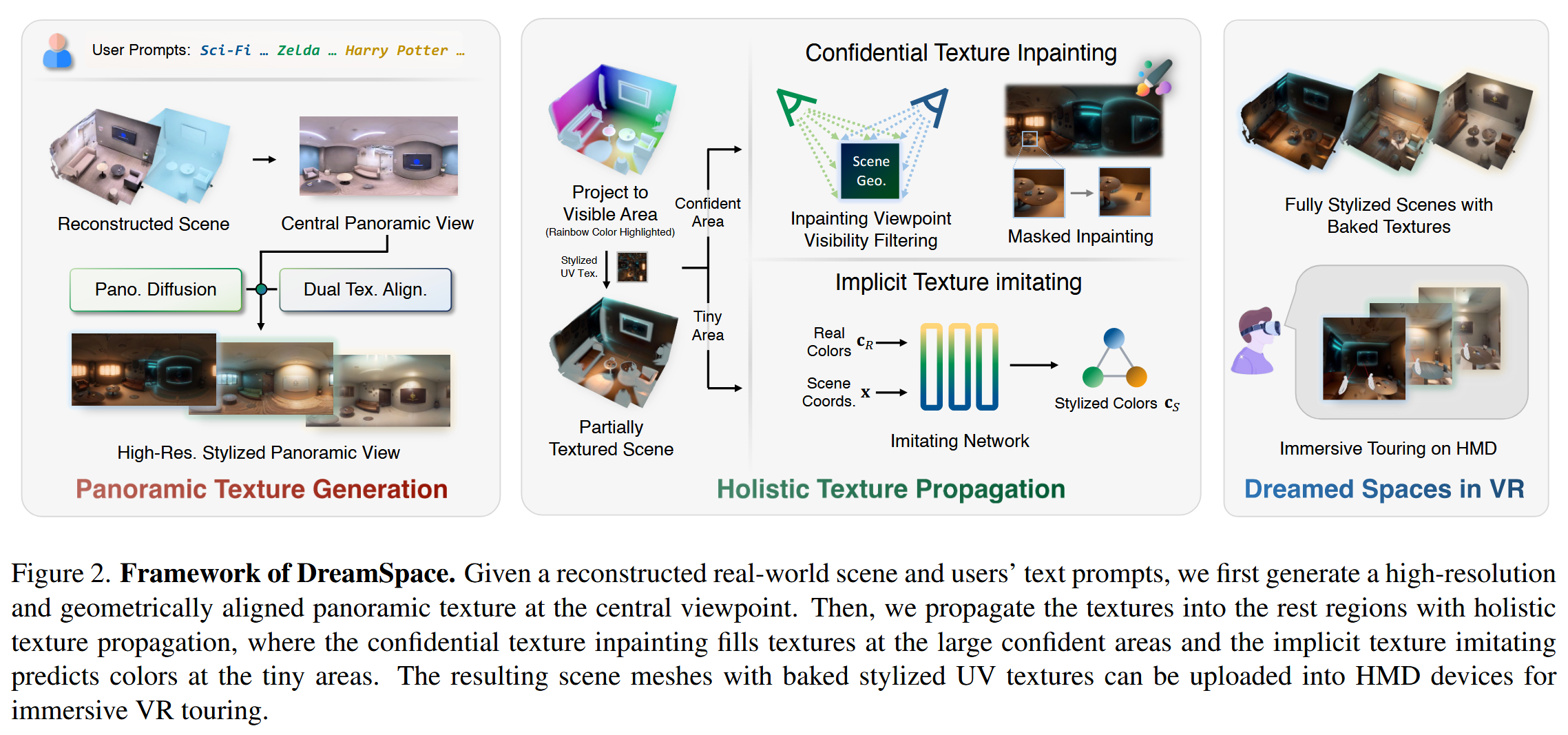
给定一个重建的真实场景和用户的文本描述,我们首先在中心视点生成高分辨率且几何对齐的全景纹理。随后,通过整体纹理传播技术将纹理扩展至其余区域——其中,置信纹理修复负责填充大范围的可信区域,而隐式纹理模仿则预测细小区域的色彩。最终生成的场景网格附带有烘焙后的风格化UV纹理,可直接上传至头戴显示设备(HMD),用于沉浸式VR漫游体验。

3. 文章是如何实现双重纹理对齐的
(1)双通道纹理生成
风格优先纹理(Style-first Panorama):使用全景扩散模型(LDM)生成高视觉质量的纹理,但几何贴合较弱。(“好看但可能歪的图”:AI自由发挥,保证星空效果炫酷,但可能没对准家具边缘。)
对齐优先纹理(Align-first Panorama):基于真实场景纹理,通过Canny边缘控制强制几何对齐,但风格质量较低。(对齐但略丑的图":AI严格按真实家具轮廓生成,风格较单调。)
(2)深度感知混合
- 从全景深度图提取深度边缘(如家具轮廓),生成混合掩膜。(AI先用深度图找到桌子/沙发的边缘线(像描边工具))
- 通过泊松图像编辑将对齐优先纹理融合到风格优先纹理中。
边缘区域:优先使用对齐优先纹理(保证几何贴合)(在边缘线附近,用"对齐图"修正位置(确保纹理不穿帮)。)
平坦区域:保留风格优先纹理(维持视觉质量)(其他区域保留"好看图"的绚丽效果。)
4.文章是如何“先用低分辨率全景扩散模型生成基础结构,再通过超分辨率提升细节”的?
(1)低分辨率基础结构生成
- 输入条件:文本提示(如“星空主题”);场景中心视点的低分辨率(如512×1024)全景深度图与边缘图。
- 模型:基于Latent Diffusion Model (LDM)的全景扩散模型,通过以下改进实现结构一致性:
水平环形填充(Horizontal Circular Padding):替换UNet的常规卷积,强制左右边界连续。
多条件控制:联合调节深度、边缘和文本嵌入 - 输出:低分辨率(如1024×2048)全景纹理,保留场景宏观布局(如墙壁/家具位置),但缺乏细节。
(2)超分辨率细节增强
- 方法:
分块扩散上采样(Tiled Diffusion):将低分辨率全景图分块输入通用LDM,通过扩散过程逐步提升分辨率(如3倍至3072×6144)。
极区修复(Polar Inpainting):将全景图上下极区转换为透视投影,修复扭曲的顶/底部分(如天花板/地板)。水平滚动图像,修复左右边界接缝。 - 输出:高分辨率无缝全景图,细节丰富(如家具木纹、星空的光点),符合等距柱状投影(Equirectangular Projection)要求。

三、Sample2SQL: A Visual Interface for Querying Risky Enterprises
作者:Hongjia Wu, Shanchen Zou, Jiazhi Xia, Hongxin Zhang, Wei Chen
机构:(1)State Key Lab of CAD&CG, Zhejiang University (2)Central South University
文章链接:https://ieeexplore.ieee.org/document/10541717
发表:PacificVis 2024
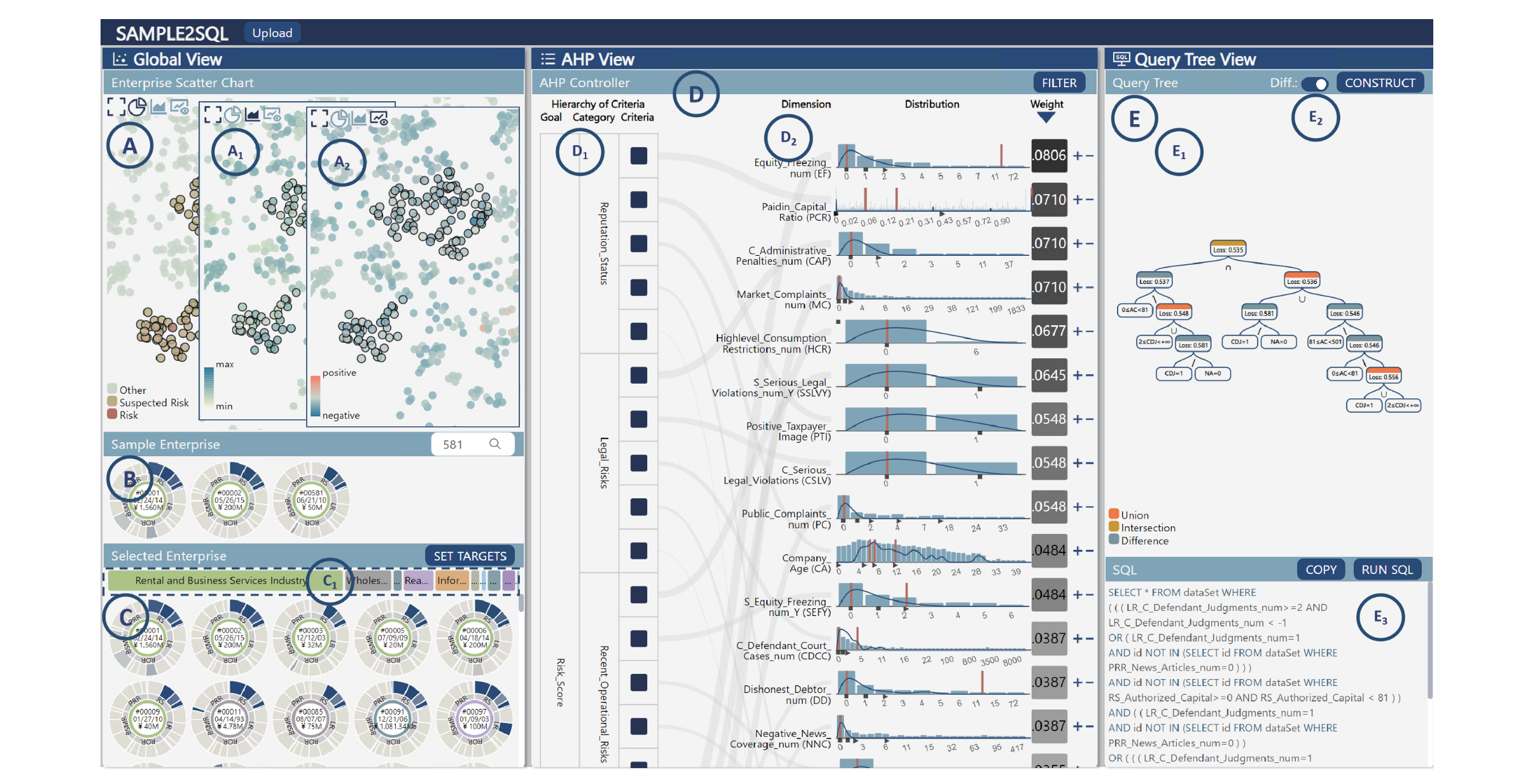
可视化界面包含三个主要视图:全局视图、AHP(层次分析法)视图和查询树视图。全局视图展示了不同粒度级别的信息,包括企业散点图 (A)、样本企业列表 (B) 和选定企业列表 ©。AHP 视图 (D) 分为两个部分,左侧 (D1) 显示 AHP 模型的层次结构,右侧 (D2) 显示每个维度的数据分布。查询树视图 (E) 用于构建 SQL 查询语句,由上部的查询树 (E1) 和下部的 SQL 语句文本框 (E3) 组成。
摘要:
我们提出了一种针对高风险企业的可视化查询系统。用户只需输入少量高风险企业的样本,即可通过交互式分析获得表达查询结果的 SQL 语句,从而方便后续的任务操作和理解风险标准。由于企业的多样性和经济指标的复杂性,对于普通用户来说,理解、评估和查询高风险企业是一项具有挑战性的任务。为了解决这个问题,我们的可视化查询系统通过可视化分析界面集成了多标准决策技术和数据挖掘。该系统利用从少量已知风险公司样本中获得的知识,能够高效地识别高风险企业。我们的系统包括一个用于表达领域知识的层次分析模型、一个查询树构建算法和一个精心设计的可视化界面。两个真实案例证明了我们系统的有效性。
1. 简要介绍一下这篇文章
区域企业法律风险评估需综合分析政治、市场、法律等多维数据,但传统方法面临数据量大、维度高、信息不对称等挑战。现有系统多聚焦于风险模型设计或自然语言转SQL,缺乏结合领域知识与可视化探索的端到端解决方案。
核心贡献:
(1)交互式规则模型调整:
- 基于层次分析法(AHP)构建可解释的风险评估模型,支持通过可视化界面动态调整维度权重(如“法律诉讼次数”权重提升)。
- 提出简化的AHP计算流程,仅需专家排序维度重要性即可生成一致性矩阵,降低交互负担。
(2)查询树构建算法:
- 将SQL语句抽象为树结构,叶节点为离散化后的过滤条件(如2 < 企业年龄 < 5),非叶节点为布尔组合(AND/OR)。
- 定义目标函数(基于Jaccard指数)优化查询条件,贪心算法生成近似最优SQL语句,支持对目标企业集合的语义匹配。
(3)可视化分析流水线:
- 全局视图:UMAP降维散点图展示区域企业分布,太阳图(Sunburst)编码企业多维度数据与AHP权重。
- AHP视图:条形图对比样本企业与整体数据分布,突出关键风险维度(如“失信记录数”分布偏移)。
- 查询树视图:树形结构可视化SQL条件组合,支持节点点击预览查询结果。
实验验证:
- 使用中国杭州8,300家企业真实数据,案例显示系统能快速识别高风险企业(如失信企业集群),生成可解释SQL语句(如筛选失信记录 > 5 AND 行业 = “租赁服务”)。
- 专家评估表明,系统将规则模型调整时间缩短60%,SQL构建效率提升75%。
局限性:
- 仅支持单表查询,缺乏多表连接(JOIN)等复杂操作。
- 时间序列分析能力不足,未考虑企业动态风险变化。
通俗易懂版本介绍:
这是一款名为Sample2SQL的“企业风险扫描神器”,专为投资机构、政府监管部门设计。用户只需输入几家已知的高风险企业(比如因违规被处罚的公司),系统就能自动分析这些企业的共同特征,并生成标准的数据库查询语句(SQL),快速找出其他具有相似风险的企业。
核心功能:
(1)智能风险打分:
系统内置一个评分模型(类似考试判卷规则),比如“法律诉讼次数多”的企业扣分多。用户可以通过拖拽调整不同指标的权重(如把“失信记录”的权重调高)。
(2)可视化分析:
- 全局地图:所有企业显示为散点图,高风险企业标红,点击可查看详情(如行业、注册资本)。
- 对比功能:用条形图对比高风险企业和普通企业的差异(比如高风险企业的“被告案件数”普遍偏高)。
- SQL生成器:系统自动将分析结果转换成SQL查询语句,像搭积木一样组合条件(例如“找出租赁行业且失信记录>5次的企业”)。
2. 什么是层次分析法?AHP模型是如何得到的?
层次分析法(Analytic Hierarchy Process, AHP)是一种结构化决策方法,用于处理多准则复杂问题,由Thomas Saaty于1970年代提出。其核心步骤包括:
(1)构建层次模型:目标层(如“评估企业风险”)、准则层(如“法律风险”“财务风险”)、方案层(如“涉诉案件数量”、“失信被执行人次数”、“税务违规情况”等)。
(2)构造判断矩阵:通过两两比较准则重要性(如“法律风险 vs 财务风险,哪个更重要?”),用1-9标度量化。
(3)计算权重:特征向量法求权重,一致性检验(CR<0.1)确保逻辑合理。
(4)综合评分:加权计算各方案总分。
在Sample2SQL中,实现了:用户输入样本 → AHP模型动态优化 → 自动生成SQL的无缝流程。
在这篇工作中,作者与领域专家(投资公司的量化分析师和投资经理)进行了长时间(8 个月)的合作,通过反复的讨论来确定模型的结构和参数。
AHP 模型根据用户设定的权重和企业在各个维度上的数据,计算出一个综合的风险评分。这个评分可以用来对企业进行排序或分类,识别出潜在的高风险企业。系统使用“查询树构建算法”来自动生成 SQL 语句。该算法的输入是目标企业集合,目标是找到一组 SQL 过滤条件,能够尽可能精确地匹配这些目标企业。
3. 查询树构建算法是怎么实现的?
查询树构建算法旨在解决以下优化问题:给定企业数据集 D 和目标企业集合 No,寻找最优查询条件 oˆ,使得通过 oˆ 查询到的企业子集 Noˆ 与 No 的相似度尽可能高。算法采用贪心策略,从基本查询条件出发,通过布尔运算逐步构建复杂的查询条件,并使用基于 Jaccard 指数的损失函数 L(oˆ) 评估每个查询条件的优劣。为了防止查询树过于复杂,算法引入正则化项 λHeight,并限制查询树的最大高度 Hmax。算法迭代进行,每次选择损失函数值最小的查询条件加入查询树,直到损失函数收敛或达到最大迭代次数。
通俗易懂的描述:
想象一下,你有一堆企业的信息,你想从中找到一些“坏公司”(高风险企业)。你已经有一些“坏公司”的样本(目标集合),你想找到和它们类似的公司。
“查询树构建算法”就像一个聪明的助手,它会帮你自动生成一个 SQL 查询语句,来找到这些“坏公司”。
这个助手是怎么工作的呢?
(1)划分特征: 助手会把每个公司的各种特征(例如,公司年龄、注册资本)划分成几个范围,例如“公司年龄小于 5 年”、“公司年龄在 5 到 10 年之间”等等。
(2)尝试各种组合: 助手会尝试各种特征的组合,例如“公司年龄小于 5 年 并且 涉诉案件数量大于 10 起”。
(3)评估效果: 助手会评估每种组合的效果,看看它能找到多少“坏公司”,以及找到的公司有多大程度上和已知的“坏公司”相似。
(4)构建查询树: 助手会把这些组合按照效果好坏组织成一棵树,效果最好的组合放在树的顶端。
(5)生成 SQL 语句: 最后,助手会把这棵树转换成一个 SQL 查询语句,你就可以用这个语句在数据库里找到和你已知的“坏公司”类似的公司了。
为了防止生成的 SQL 语句太复杂,助手会限制树的高度,并且会尽量选择简单的组合。
总而言之,“查询树构建算法”就像一个自动化的 SQL 查询生成器,它会根据你提供的一些“坏公司”的样本,自动生成一个 SQL 查询语句,帮你找到更多类似的“坏公司”。
四、ReLive: Walking into Virtual Reality Spaces from Video Recordings of One’s Past Can Increase the Experiential Detail and Affect of Autobiographical Memories

作者:Valdemar Danry, Eli Villa, Samantha Chan, Pattie Maes
机构:MIT Media Lab
文章链接:https://ieeexplore.ieee.org/abstract/document/10919245
发表:TVCG 2025
摘要
随着先进机器学习方法在空间重建方面的快速发展,理解这些技术对自传记忆的心理和情感影响变得愈发重要。在一项被试内研究中,我们发现允许用户在从他们的视频重建的旧空间中漫步,显著增强了他们对过去记忆的旅行感,增加了这些记忆的生动性,并提升了情感强度,相较于仅仅观看同一事件的视频。这些发现强调,无论技术如何进步,虚拟现实的沉浸体验都能深刻影响记忆现象学和情感参与。随着能够实现沉浸式记忆重建的系统变得愈加普及,批判性地审视它们对人类认知和现实感知的影响变得至关重要。
1. 简要介绍一下文章和method
这篇文章探讨了利用虚拟现实(VR)技术重建个人记忆的影响,特别是通过从个人视频中生成沉浸式的3D环境。研究表明,参与者在这种重建的空间中行走时,比起单纯观看视频,他们的记忆重温感、情感强度和记忆的生动性均显著提升。实验结果显示,沉浸式体验能够增强自传记忆的现象学特征,改善记忆的连贯性和细节。文章强调,随着这些技术的普及,深入研究其对人类认知和现实感知的影响至关重要。
这篇文章的方法主要包括以下几个步骤:
(1)视频转化:首先,研究团队使用FFmpeg将参与者提交的个人视频转化为一系列有序的图像序列,设置帧率为10帧每秒,以便进行后续处理。
(2)3D重建:采用Meshroom这一光学测量软件,通过光摄影测量技术(photogrammetry)将图像序列转化为3D可步行的虚拟环境。研究选择Meshroom是因为它在处理短视频时更具有效性。
(3)用户研究设计:进行了一项被试内研究,邀请14名参与者。每位参与者提交至少三个与其个人经历相关的视频。随机选择一个视频进行3D重建。
(4)实验条件:参与者在两个条件下进行实验:一是观看原始2D视频,二是在重建的3D虚拟空间中行走。通过随机顺序控制实验顺序,以减少变量干扰。
(5)数据收集与分析:在每个实验条件后,参与者填写问卷,包括自传记忆重温测试(ART)、情感量表(PANAS)和重建准确性评估。数据通过普通最小二乘法(OLS)线性回归分析进行处理,以评估不同条件对记忆和情感的影响。
(6)定性分析:研究还通过半结构化访谈收集参与者的反馈,以深入了解他们的体验和感受。
2. 简要介绍一下研究结果
这篇文章的研究结果主要包括以下几个方面:
(1)记忆重温感:参与者在虚拟现实(VR)环境中行走时,感受到的“重温”记忆的程度显著高于观看视频的情况。VR条件下的自传记忆重温评分明显更高,表明沉浸式体验增强了记忆的回溯感。
(2)情感强度:在VR环境中,参与者的情感反应显著增强。情感量表(PANAS)的评分显示,参与者在沉浸于重建的空间时,体验到的情感强度要高于视频观看时的情感反应。
(3)记忆的生动性和连贯性:参与者在VR环境中对记忆的细节和连贯性评估也更高。自传记忆重温测试(ART)的结果显示,参与者在VR条件下对空间布局的记忆更为清晰,且记忆内容的连贯性也得到了改善。
(4)重建准确性:研究还发现,虚拟环境的重建准确性与情感反应和记忆质量之间存在显著关联。重建得越准确,参与者的情感反应和记忆的生动性、连贯性就越强。
(5)定性反馈:通过访谈,参与者普遍表示在VR环境中体验到的记忆更为生动,能够更好地回忆起特定的物品和情境。尽管存在一些细节缺失,许多参与者能够凭借想象力填补这些空白。
总体而言,研究结果表明,虚拟现实技术显著提升了个人记忆的回忆体验和情感参与,显示出其在自传记忆重建领域的潜力。
五、Mood-Driven Colorization of Virtual Indoor Scenes

作者:Boying Li, Zhixi Cai, Yuan-Fang Li, Ian Reid, and Hamid Rezatofighi
机构:(1)George Mason University (2)Tianjin University of Finance & Economics (3)Zhejiang University
原文链接:https://ieeexplore.ieee.org/document/9714118
发表:TVCG 2022
摘要
在虚拟现实(VR)中,设计虚拟场景以引发观众特定情绪是一项具有挑战性的任务。由于情绪的主观性,这一目标充满了不确定性。我们提出了一种新颖的方法,自动调整虚拟室内场景中物体纹理的颜色,以匹配目标情绪。我们使用了一个包含25,000张图像的数据集,这些图像包括建筑/家庭室内场景,用于训练一个分类器,通过深度学习提取特征。这一方法有助于优化过程,使虚拟场景能够自动根据目标情绪进行色彩化。我们在四个不同的室内场景上进行了测试,并通过用户研究展示了该方法的有效性,重点关注用户在使用VR头戴设备时的体验影响。
1.请讲一下这篇文章的pipeline
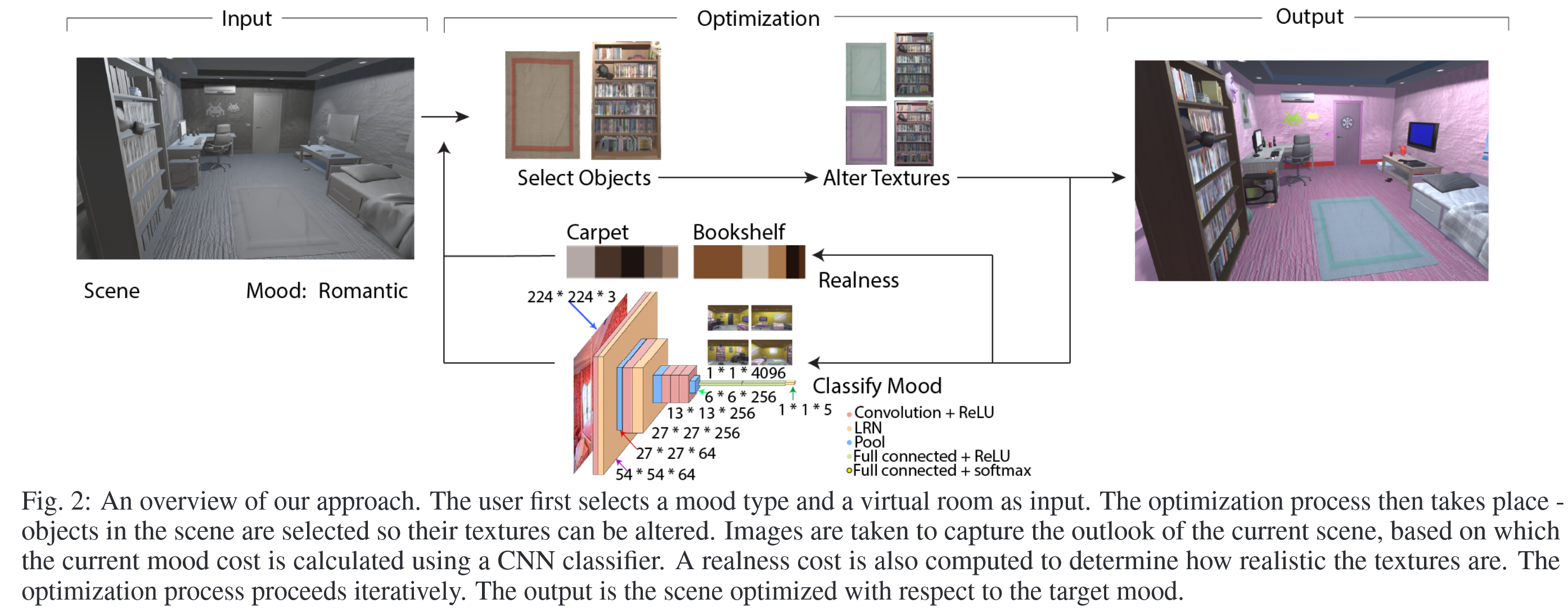
输入选择:用户选择一个目标情绪和一个虚拟室内场景(如卧室、餐厅等)。
特征提取:使用预训练的深度学习模型(如VGG-F)从输入图像中提取特征,以识别与目标情绪相关的图像特征。
优化过程:采用随机优化方法,迭代调整场景中物体的纹理颜色,直到达到满意的情绪匹配。计算总成本函数,包括情绪成本和真实感成本,以指导优化过程。
生成输出:最终生成与目标情绪匹配的优化场景,并展示给用户。
用户验证:进行用户研究,评估优化结果是否有效地引发了目标情绪,并收集用户反馈以验证方法的有效性。
2.请问是如何“使用预训练的深度学习模型从输入图像中提取特征,以识别与目标情绪相关的图像特征的”?
特征提取:使用预训练的VGG-F深度学习模型,对输入的室内图像进行处理。该模型通过多个卷积层和池化层提取图像的层次特征。
图像分类:提取的特征被输入到一个分类器中(如支持向量机SVM),用于分类图像的情绪。模型会根据训练时学习到的特征和情绪标签,评估输入图像与不同情绪的匹配程度。
情绪评分:对于每种情绪,模型会计算出一个得分,表示输入图像与该情绪的相关性,得分越高,表示越可能与目标情绪匹配。
3.“采用随机优化方法,迭代调整场景中物体的纹理颜色,直到达到满意的情绪匹配。” 随机优化方法是怎么工作的?
随机优化方法是一种用于解决复杂优化问题的算法,通常用于大规模搜索空间。具体过程如下:
初始状态:随机选择一个初始状态(例如,场景中物体的纹理颜色)。
目标函数:定义一个总成本函数,该函数由多个部分组成,包括情绪成本和真实感成本,用于评估当前状态的质量。
邻域生成:在当前状态的基础上,随机生成一个或多个邻近状态,这些状态是通过小幅修改当前状态(如调整颜色)得到的。
接受标准:比较新状态的成本与当前状态的成本。如果新状态的成本更低,则接受新状态;如果成本更高,则以一定概率接受新状态,以避免陷入局部最优解。
迭代过程:重复上述过程,直到达到预设的停止条件(如成本变化小于一定值或达到最大迭代次数)。
4.“特征提取:使用预训练的深度学习模型(如VGG-F)从输入图像中提取特征,以识别与目标情绪相关的图像特征。”这个阶段的作用是什么?为啥不直接进入到优化过程阶段?
特征提取阶段的作用是为优化过程提供必要的信息基础,具体来说,原因如下:
理解图像内容:特征提取帮助系统理解输入图像的内容,包括颜色、纹理、形状等。这些信息是判断图像传达情绪的关键。
情绪识别:通过提取特征,系统可以识别出图像与不同情绪的关联。例如,鲜艳的颜色可能与“快乐”相关,而阴暗的色调可能与“忧伤”相关。
为优化提供依据:在优化过程中,系统需要知道当前图像的情绪特征才能进行调整。如果没有这些特征信息,系统无法判断如何修改颜色或纹理以匹配目标情绪。
减少试错成本:通过提取特征,系统可以更有效地进行优化,减少随机尝试的次数,从而提高效率。
简单来说,特征提取就像是为优化过程打下基础。只有理解了输入图像中的情绪特征,系统才能进行有效的调整,以达成目标情绪。直接进入优化过程可能导致无效或不准确的结果。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)