Python数据分析_用户偏好分析
本文主要介绍Python中的pandas进行数据分析的两个案例、偏好分析TGI、用户留存分析。
Python数据分析_用户偏好分析
【模块一:用户偏好分析和TGI】
【理解】用户偏好分析与TGI的介绍
-
目标:理解用户偏好分析与TGI的介绍
-
实施
-
问题1:什么是用户偏好分析?
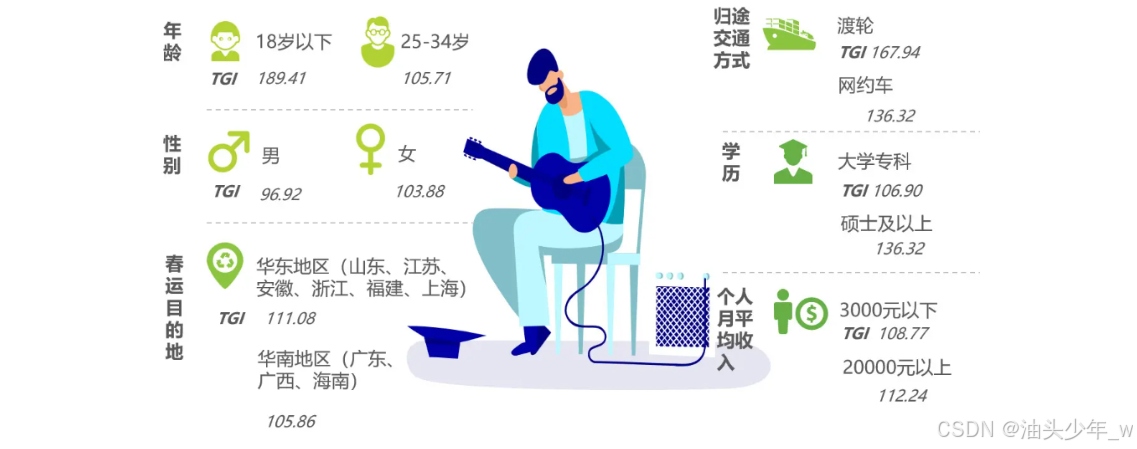
在这里插入图片描述
- 理解:我们常说的用户偏好分析是一种分析方向,它基于用户属性和行为等数据,可以分析用户对于某些产品、服务或特征的喜好程度。通过用户偏好分析,品牌可以更好地了解目标客户群体的需求和行为特点,从而制定契合度更高的产品策略、宣传策略等
- 应用场景
- 电子商务:通过分析用户购买历史、浏览行为和喜好,电子商务平台可以向用户提供个性化的产品推荐。这有助于提高销售量、提升用户满意度,并帮助用户更快地找到需要的商品。
- 社交媒体:社交媒体平台可以利用用户的个人资料、点赞行为、分享内容等信息,向用户推荐感兴趣的朋友、话题、新闻和其他内容。
- 音乐和视频流媒体:音乐和视频流媒体服务可以根据用户以往的听歌或观看记录,向用户推荐符合其口味的音乐和视频内容。
- 新闻推荐:新闻聚合平台可以根据用户对不同主题、来源的关注程度以及阅读历史,向用户推荐与其兴趣相关的新闻文章。
- 搜索引擎:通过分析用户之前的搜索历史以及点击模式,搜索引擎可以提供更精准的搜索结果和个性化的建议。
- 个性化广告投放:基于用户的兴趣和行为模式,广告平台可以更精准地将广告投放给目标用户,提高广告效果并节省资源开支。
- 餐饮和旅游预订网站:分析用户过去的选择和偏好,为用户推荐餐厅、菜品或旅游目的地。
- 衡量方式
- 目标群体指数(Target Group Index):TGI可帮助公司了解特定用户群体对某种产品或品牌的偏好程度是否高于总体水平
- 占有率(Share of Wallet):用来衡量客户在某个特定产品或服务领域上的支出与总支出的比例。该指标帮助了解客户对特定品类的偏好程度。
- 满意度调查:通过调查用户对产品、服务或网站的满意程度来了解其偏好。这通常通过定期问卷调查、反馈收集等方式进行。
- 行为数据分析:分析用户在平台上的各种行为,例如搜索记录、点击模式、购买记录、浏览时长等,从中挖掘用户的偏好模式。
- 社交媒体互动分析:对用户在社交媒体上的互动行为进行分析,包括点赞、分享、评论和关注信息等,以便了解用户对内容或产品的喜好。
- 加入会员/订阅:用户选择加入会员或者订阅特定产品或服务通常表明他们对该产品或服务的偏好。
- A/B测试:将用户分成两组(实验组和对照组),向其中一组推荐新功能或产品变体,并检查用户的反应,从而了解用户的偏好。
- 主观评价:采用定性信息、用户反馈和评价来理解用户对产品或服务的偏好。
-
问题2:什么是TGI?
- TGI:Target Group Index 目标群体指数
- 关系:用于反映目标群体在特定研究范围内强势或者弱势的程度。TGI指数在用户偏好分析中扮演了衡量不同人群偏好的重要角色,为市场营销策略和产品定位提供了有力的数据支持。
- 标准
-
TGI=100,表示目标群体和总体在某特征或行为上的表现相同。
-
TGI>100,表示目标群体在某特征或行为上的表现高于总体,具有较高的偏好程度,数值越大偏好越强。
-
TGI<100,表示目标群体在某特征或行为上的表现低于总体,具有较低的偏好程度,数值越小偏好越弱。
-
- 应用:用户画像,用户偏好(爱好,媒介接触,生活习惯),购买行为等
-
问题3:TGI怎么计算?
-
公式:[ 目标群体中具有某一特征的群体所占比例 / 总体中具有相同特征的群体所占比例 ] * 100
-
核心:总体【所有人】、目标群体【观察群体】、某一特征【喜好属性】
-
举例:假定待分析的是:上海 90后 单身狗 的情况
- 【上海】—— 总体, 假设有100人
- 【90后】—— 目标群体,假设有80人
- 【单身狗】—— 特征群体,假设有50人
- 【90后单身狗】——45人
- 假设90后的单身狗是45人 => 目标群体中具有某一特征的群体所占比例 45 / 80=> 56%
- 假设上海的单身狗是50人 => 总体中具有相同特征的群体所占比例 50 / 100=> 50%
- 90后单身狗的TGI = 56 / 50 = 1.12 * 100 = 112
-
-
-
小结:理解用户偏好分析与TGI的介绍
【理解】用户偏好分析案例的需求
-
目标:理解用户偏好分析案例的需求
-
实施
-
背景:XXX零售便利店公司
-
问题:公司目前在全国开放了1000+门店,为了实现更好的运营,加快市场拓展,希望能够对用户群体进行偏好分析,促进用户的精细化运营效果,辅助支撑运营决策
-
需求
- 目标群体的产品偏好:了解特定人群对产品或品牌的偏好程度,使用TGI来衡量该目标群体相对于整个市场总体的偏好情况。
- 广告或促销策略:为了确定某一广告或促销活动在特定人群中的影响力和效果,使用TGI了解活动对特定目标群体的吸引力。
- 购买行为分析:当企业希望了解特定人群对其产品的购买意向和程度时,TGI能够帮助评估目标群体对产品的偏好程度。
- 地区性偏好:对于特定地理区域,公司有时需要了解不同的市场中对产品的偏好程度。TGI比较不同地区对产品的偏好情况。
- 新产品研发:在推出新产品或服务时,公司需要了解潜在的目标用户群对其偏好,并与现有产品进行对比。TGI可用于评估潜在用户对新产品的接受程度。
-
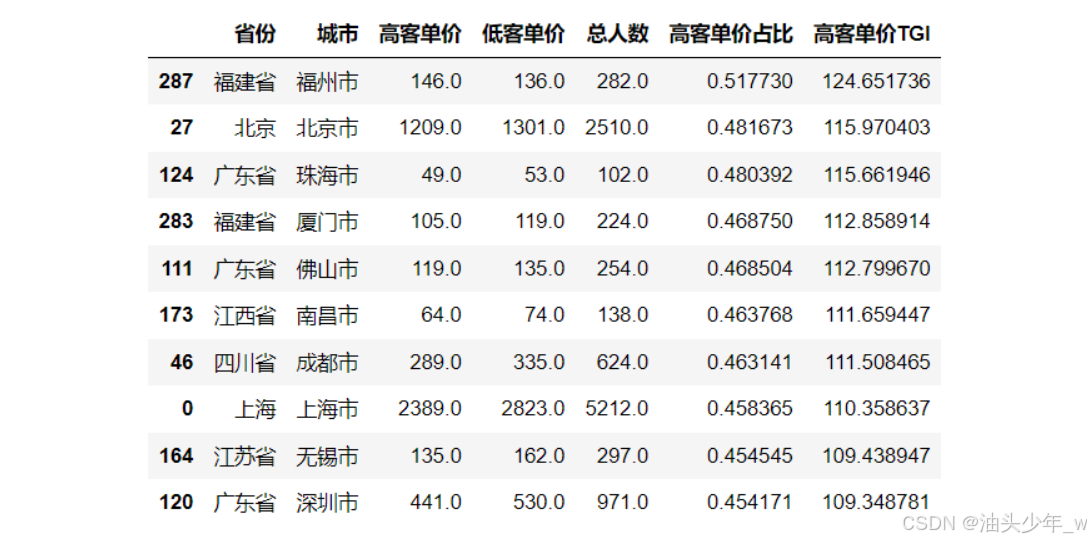
目标:查询出偏好高客单价的城市Top10
-
客单价: 每个用户的平均消费金额
-
高客单价:超过50,算高客单价用户
-
低客单价:小于等于50,算低客单价用户
-
TGI = 每个城市高客单价用户占比 / 所有数据中高客单价人数占比 * 100
-
总体:所有城市的人群
-
目标人群:每个城市的人群
-
特征:高客单价
订单ID 订单金额 城市 用户ID o01 100 上海 u01 o02 100 上海 u01 o03 100 上海 u01 o04 10 北京 u02 o05 10 北京 u02 o06 50 广州 u03 -- 上海的高客单价的用户占比 = 上海具有高客单价人数 / 上海消费总人数 -- 所有城市的高客单价的用户占比 = 高客单价人数 / 总的人数
-
-
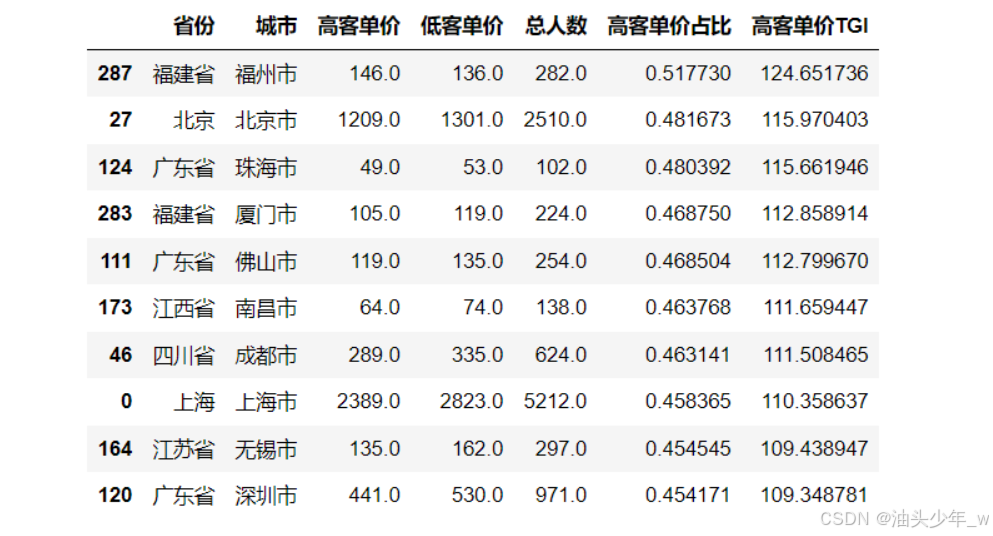
- 小结:理解用户偏好分析案例的需求
【理解】用户偏好分析数据探索
-
目标:理解用户偏好分析数据探索
-
实施
-
原始数据
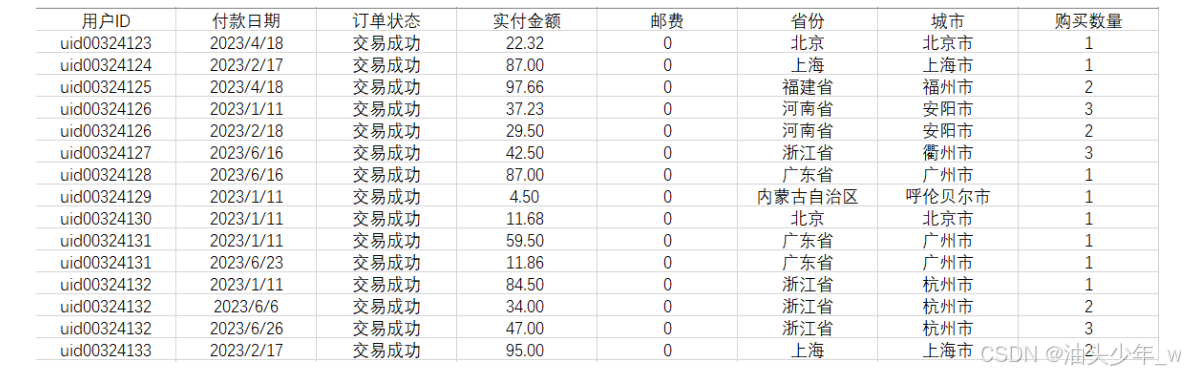
-
目标结果
-
实现流程
-
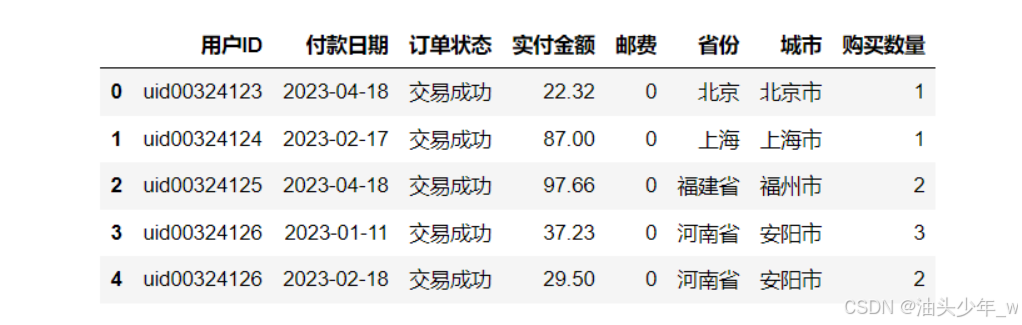
step1:读取数据,将原始数据读到程序中,构建DataFrame
-
step2:查询每个用户的客单价和城市信息:统计每个用户的客单价信息以及所对应的城市信息
with t1 as ( select 用户ID , avg(实付金额) as 平均每次支付金额 from table group by 用户ID ), t2 as ( select 用户ID , case when 平均每次支付金额 > 50 then '高客单价' else '低客单价' end as 客单价类别 from t1 ), t3 as ( select distinct 用户ID, 省份,城市 from table ) select t2.* , t3.省份 , 城市 from t2 join t3 on t2.用户ID = t3.用户ID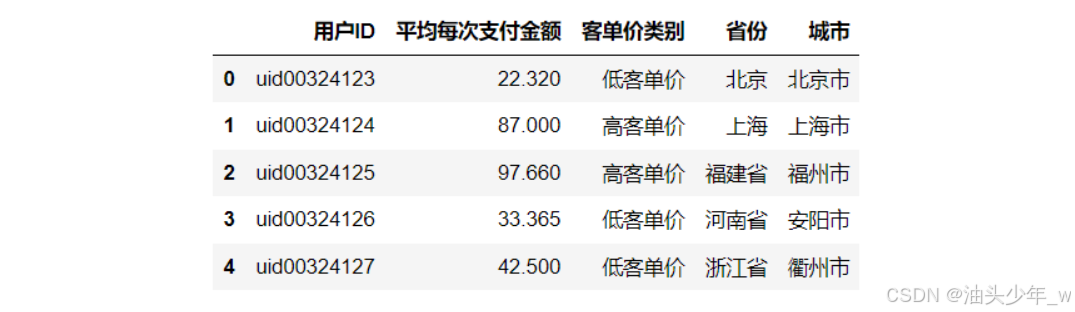
-
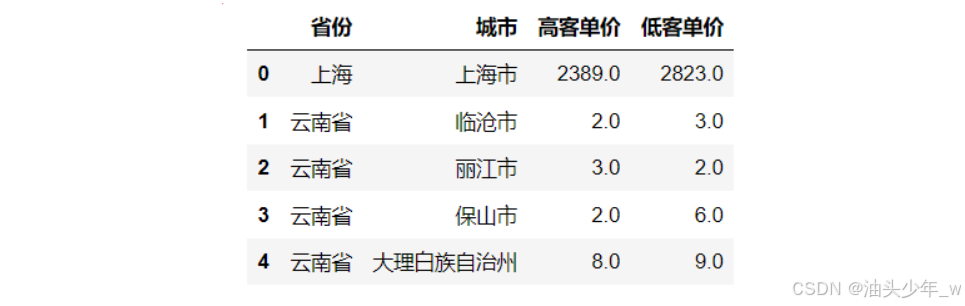
step3:计算每个省份的客单价信息:统计每个省份城市的高客单价和低客单价的信息
-
step4:计算高客单价的TGI:统计高客单价的用户全体占每个省份城市的用户的比例
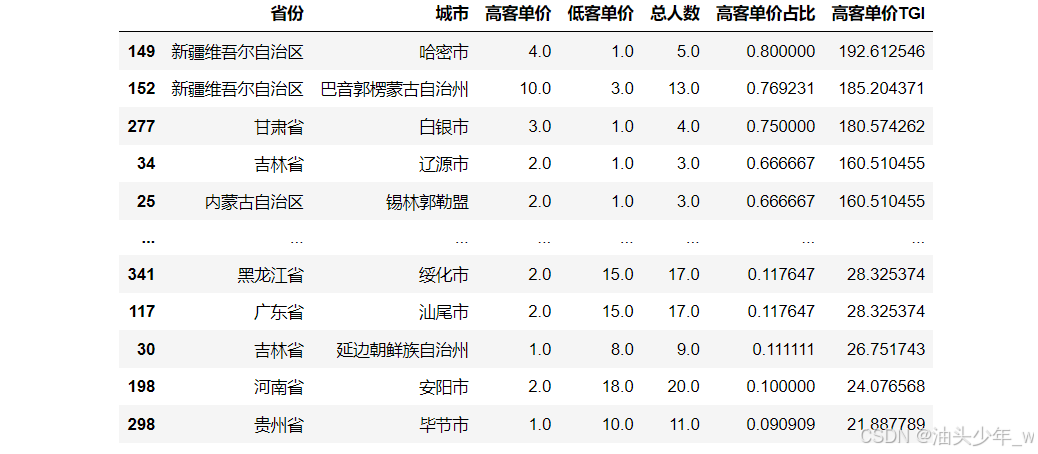
-
step5:过滤小样本影响获取结果:将样本量较小的城市信息进行过滤,获取高客单价TGI最高的Top10
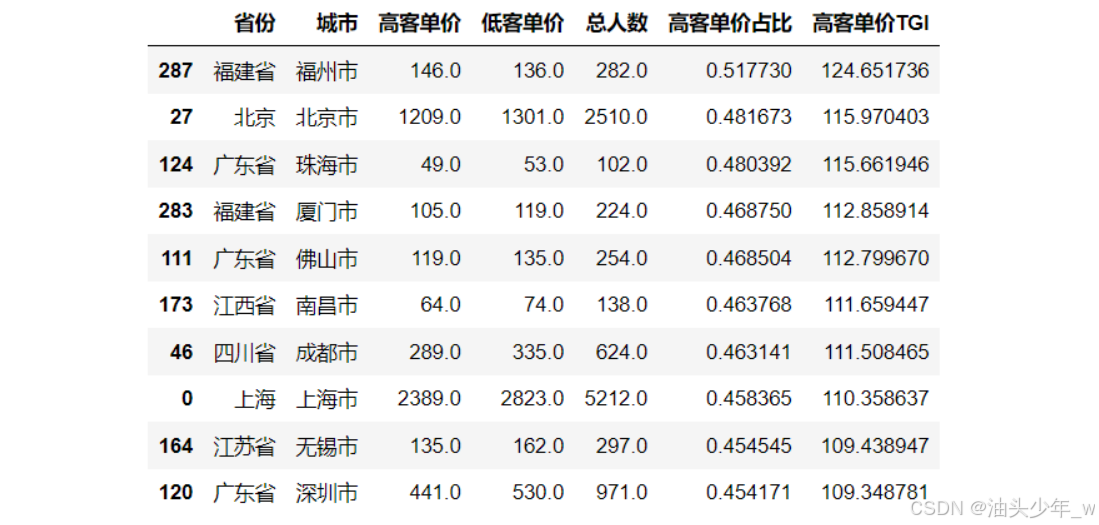
-
-
-
小结:理解用户偏好分析数据探索
【实现】用户偏好分析数据准备
-
目标:实现用户偏好分析数据准备
-
实施
-
step1:读取数据
# 导包 import pandas as pd # 读取数据 PreferenceAnalysis.xlsx df = pd.read_excel('../data/9、PreferenceAnalysis.xlsx', engine='openpyxl') df.head() # 查看汇总的一些信息 df.info() -
step2:查询每个用户的客单价和城市信息
# 统计每个用户的平均支付金额 gp_user = df.groupby('用户ID',as_index=False)['实付金额'].mean() gp_user.columns = ['用户ID','平均每次支付金额'] gp_user.head() # 定义一个函数,用于基于平均支付金额标记用户是高客单价用户【>50】还是低客单价用户【<=50】 def if_high(x): if x > 50: return '高客单价' else: return '低客单价' # 调用函数对每个用户进行标记 gp_user['客单价类别'] = gp_user['平均每次支付金额'].apply(if_high) gp_user.head() # 关联获取用户省份信息 # 每个用户在每个省份每个城市只保留一条数据 df.drop_duplicates(subset=['用户ID','省份','城市']) #先去重 df_dup = df.drop_duplicates(subset=['用户ID','省份','城市']) #再合并 df_merge = pd.merge(gp_user,df_dup,on = '用户ID',how = 'left') #返回关键字段 df_merge = df_merge[['用户ID','平均每次支付金额','客单价类别','省份','城市']] df_merge.head() -
step3:计算每个省份的客单价信息
#先筛选出需要的列 df_merge = df_merge[['用户ID','客单价类别','省份','城市']] #再用透视表 result = pd.pivot_table(df_merge,index =['省份','城市'], columns = '客单价类别', aggfunc = 'count') result.head() # 获取低客单价的信息 result['用户ID']['低客单价'].reset_index().head() # 获取高客单价的信息 result['用户ID']['高客单价'].reset_index().head() # 合并数据,得到每个省份每个城市的高客单价和低客单价 tgi = pd.merge(result['用户ID']['高客单价'].reset_index(), result['用户ID']['低客单价'].reset_index(), on = ['省份','城市'],how = 'inner') tgi.head()
-
-
小结:实现用户偏好分析数据准备
【实现】用户偏好分析TGI计算
-
目标:实现用户偏好分析TGI计算
-
实施
-
step4:计算TGI
# 计算TGI = 高客单价在当前城市的人数占比 / 高客单价在所有人群中的占比 # 计算城市人数 tgi['总人数'] = tgi['高客单价'] + tgi['低客单价'] # 计算高客单价在当前城市的占比 tgi['高客单价占比'] = tgi['高客单价'] / tgi['总人数'] tgi.head() # 去掉空值 tgi = tgi.dropna() # 计算高客单价在所有人群中的占比 total_percentage = tgi['高客单价'].sum() / tgi['总人数'].sum() print(total_percentage) # 计算TGI tgi['高客单价TGI'] = tgi['高客单价占比'] / total_percentage * 100 tgi = tgi.sort_values('高客单价TGI',ascending = False) tgi -
step5:获取最终结果
# 筛选出当前城市人数 高于 平均城市人数的 数据 tmp = tgi.loc[tgi['总人数'] > tgi['总人数'].mean(),:] # 取出TGI最高的Top10 rs = tmp.nlargest(10, '高客单价TGI') rs
-
-
小结:实现用户偏好分析TGI计算
【模块二:同期群分析】
【理解】同期群分析的介绍
-
目标:理解同期群分析的介绍
-
实施
-
问题1:什么是同期群分析?
- 概念:同期群分析是一种用于比较为不同时间段、地区或其他条件下的群体而进行的统计分析方法。
- 设计:该分析旨在确定特定群体在时间或空间上的变化情况,对比两个或多个相似的群体并分析其差异。这种分析方法可通过比较群体之间的关键指标来观察到跨时间或跨空间的变化。
-
问题2:同期群分析在哪些场景下可以得到什么效果?
-
商品同期群:商品LTV模型:观察商品在上市后,每个时间节点的销量,进而调整商品营销策略,实现利益最大化
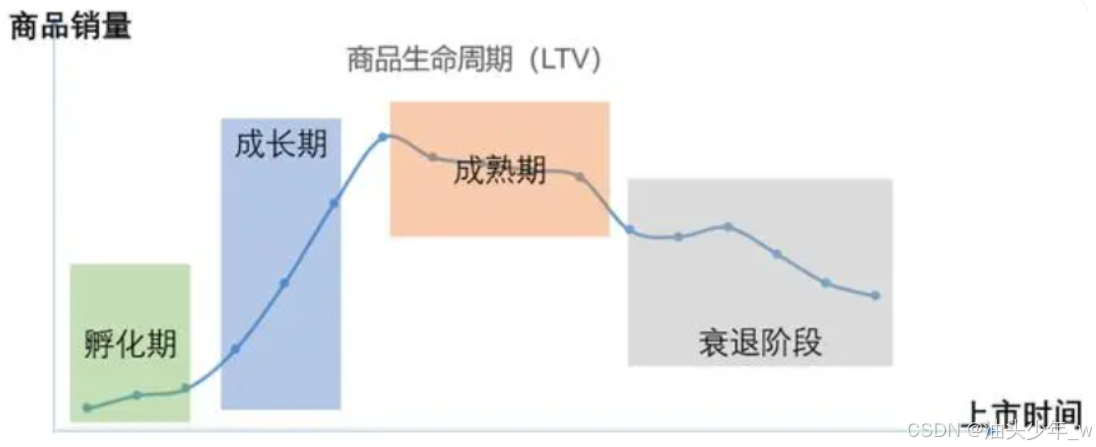
-
用户同期群:用户留存率模型:基于用户访问,计算每个周期用户的留存情况
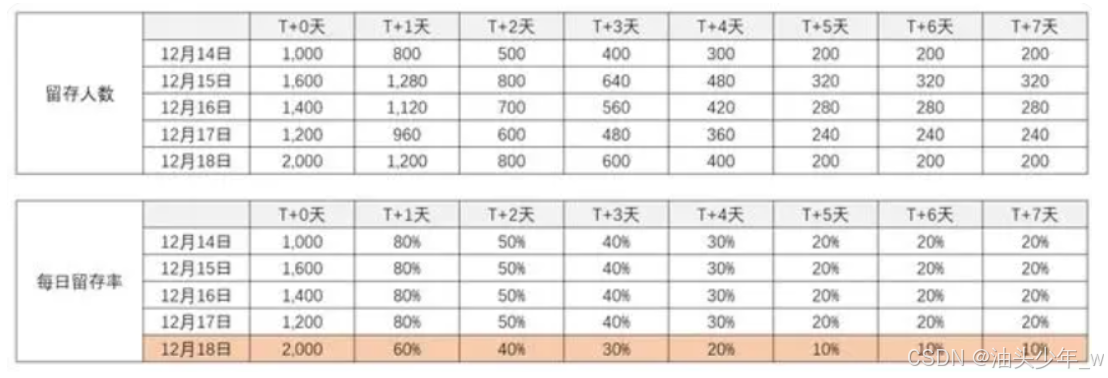
-
用户同期群:用户LTV模型:基于用户在某一时间点开始,后续每个月的用户留存、付费情况,观察运营效果
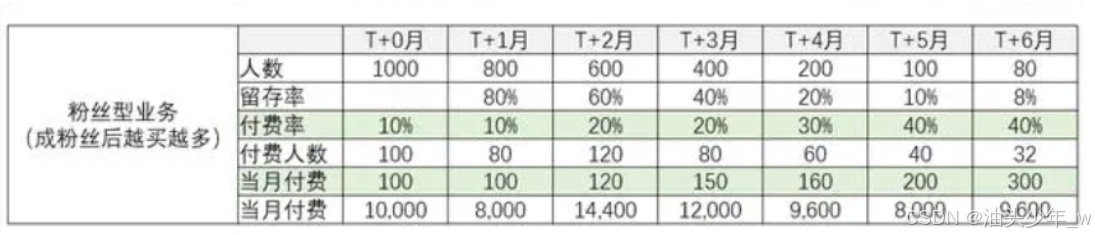
-
渠道同期群:渠道质量分析模型:观察每个渠道投放后转化的用户情况,评估投放效果,提高ROI,辅助精准投放
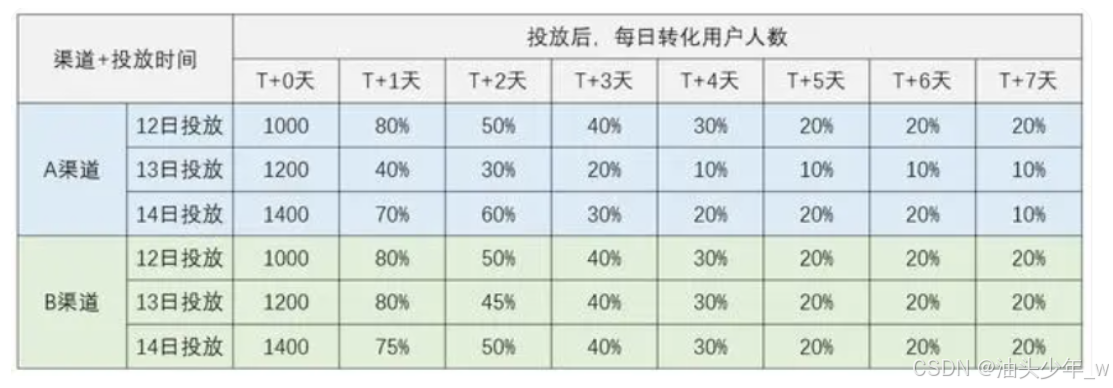
-
-
问题3:怎么做同期群分析?
- 确定研究问题:首先需要明确研究问题,比如你希望比较不同时间段或地区内的群体变化情况。确保清楚了解所需比较的对象和指标。
- 选择适当的数据:收集相关数据以进行分析。这可能包括销售数据、用户行为数据、调查结果等。确保数据集包括足够数量的样本以代表要比较的两个或多个群体。
- 定义同期群体:将群体按照相似性质进行分类,确保不同群体在比较中是可以对应的。例如,如果进行时间跨度的同期群分析,确保相同时间段属于同一群体。
- 选择比较指标:选定用于比较的关键指标,比如销售额、顾客满意度、市场份额等。这些指标应该能够反映出群体之间的差异。
- 数据清洗与处理:对所收集的数据进行清洗和处理,确保数据质量,并进行必要的转换以便后续分析使用。
- 分析对比:结合所选择的比较指标,对不同群体的数据进行对比分析,观察各项指标的变化情况。可以使用统计方法或者可视化工具来展现数据的对比。
- 得出结论:根据对比分析的结果,得出结论并识别不同群体间的差异和共同点。基于这些结论,提出改进建议或制定相关策略。
- 监控和反馈:值得注意的是,同期群分析通常是一个动态的过程。建议在对比分析后续定期监测不同群体的发展,以及实施改进措施后的效果。
-
-
小结:理解同期群分析的介绍
【理解】同期群分析案例的需求
-
目标:理解同期群分析案例的需求
-
实施
-
背景:XXX线上电商平台
-
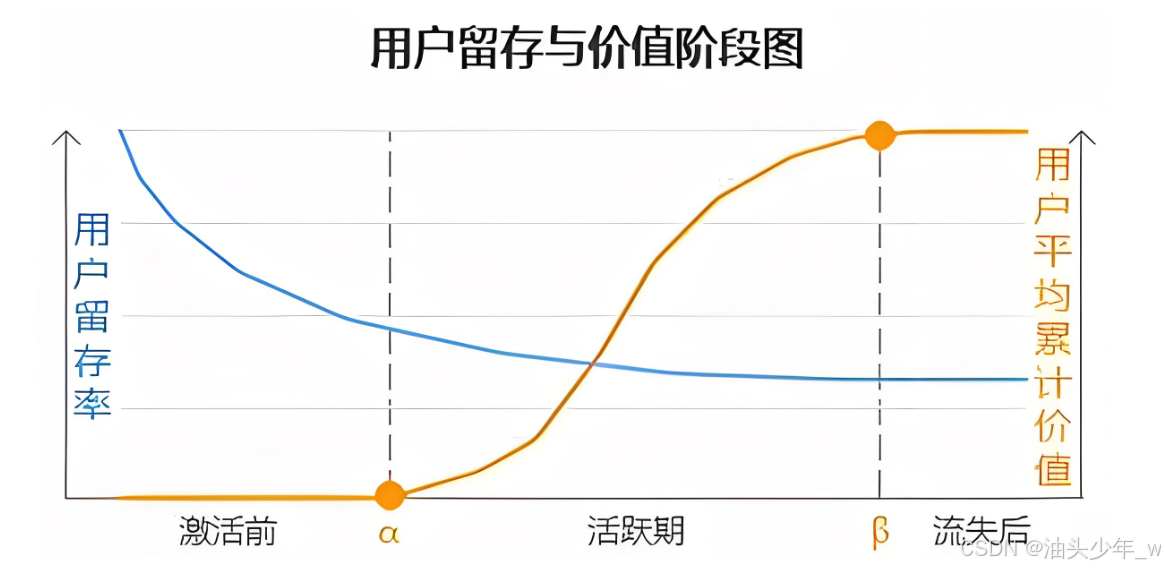
问题:目前企业稳定运营,但是希望通过用户留存率分析来观察用户质量,辅助制定用户运营计划,实现用户精细化运营
-
需求
- 客户价值洞察:通过留存率模型分析,企业可以更好地了解每个阶段的客户留存情况。通过识别留存良好和流失严重的部分,可以有效评估不同客户群体的潜在价值。
- 客户忠诚度:留存率直接关系到客户忠诚度,了解并改善客户留存率可以帮助企业加强与现有客户的联系,并鼓励他们继续购买或使用产品和服务。
- 预测未来收入:通过留存率模型,企业可以预测未来收入情况。稳定的留存率通常意味着更可靠的现金流,有助于规划长期发展战略。
- 改进产品或服务:留存率模型可以揭示客户离开的原因,从而为产品或服务改进提供指导。基于留存率数据,企业可以优化客户体验,降低流失率。
- 资源投入优化:分析留存率可以帮助企业更明智地分配资源。通过专注于提高留存率较低的客户群体,企业可以更有效地利用营销和客户支持资源。
- 竞争优势:保持良好的留存率可以为企业树立竞争优势。在竞争激烈的市场中,吸引新客户的成本通常比留住现有客户的成本更高。
- 反映产品质量和服务水平:留存率模型可以帮助企业了解客户对产品质量和服务水平的满意度,从而引导企业改进产品和服务,提升整体品牌形象。
-
目标
-
-
小结:理解同期群分析案例的需求
【理解】同期群分析数据探索
-
目标:理解同期群分析数据探索
-
实施
-
原始数据
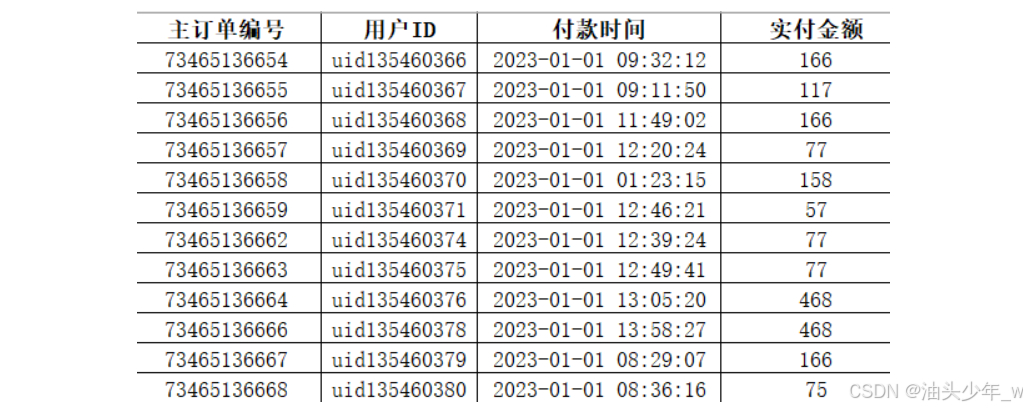
-
目标结果
-
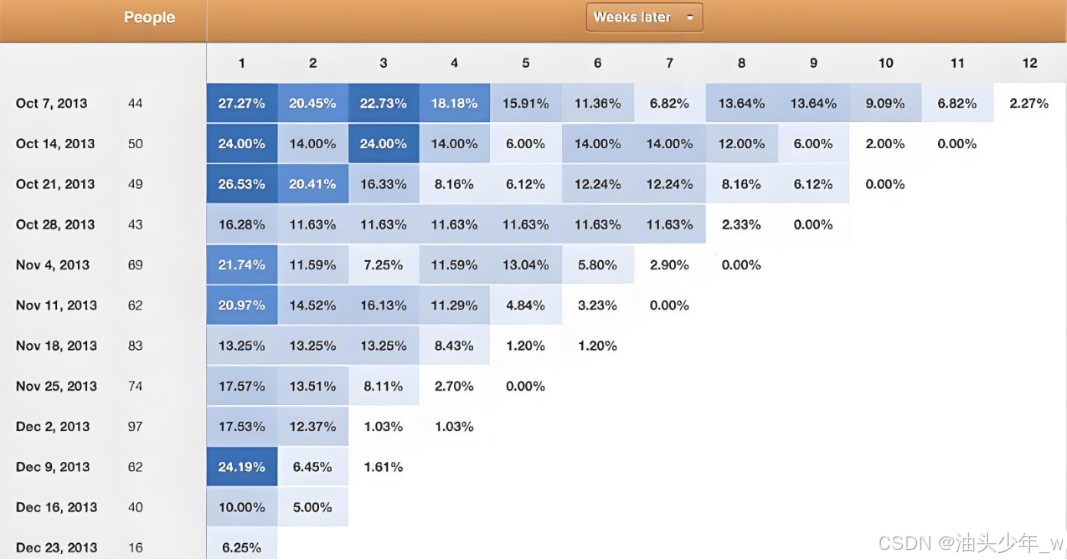
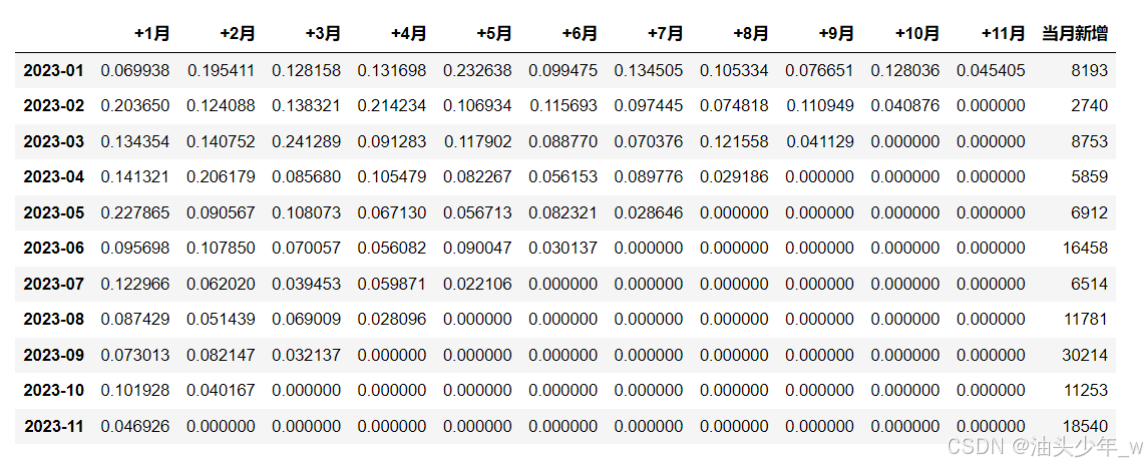
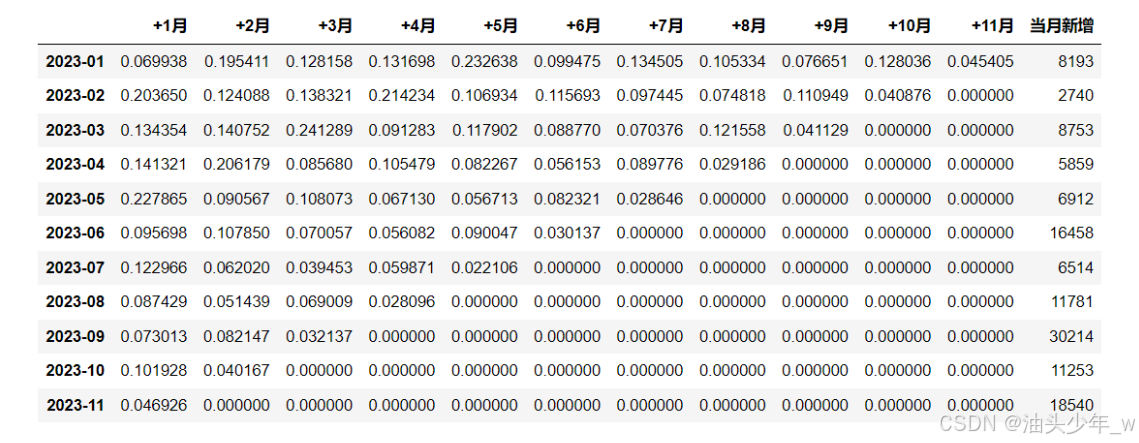
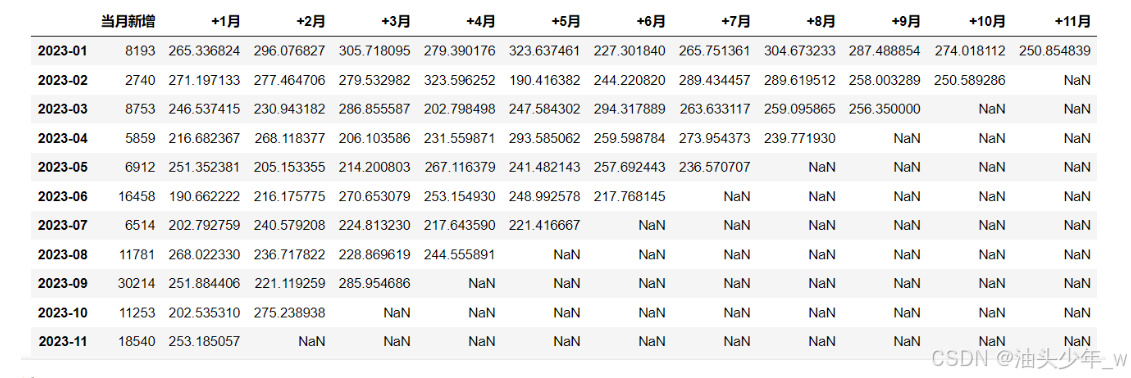
每个月的用户留存率
- 留存率:下一个周期这部分新增用户中留存用户 / 第一个周期新增用户总个数
- 举个栗子
- 1月:新增8193
- 2月:4000
- 3月:2000
- 下一个月的留存率 = 8193个人中在2月份访问的人数 4000 / 1月新增 8193
- 下下一个月的留存率 = 8193个人中在3月份访问的人数 2000 / 1月新增 8193
- 2月:新增2740
- 3月:1000
- 4月:500
- 下一个月的留存率 = 2740个人中在3月份访问的人数 1000 / 2月新增 2740
- 下下一个月的留存率 = 2740 个人中在4月份访问的人数 500/ 2月新增 2740
- 1月:新增8193
-
每个月的用户留存客单价 = 用户留存消费总金额 / 用户留存人数
-
-
实现流程
-
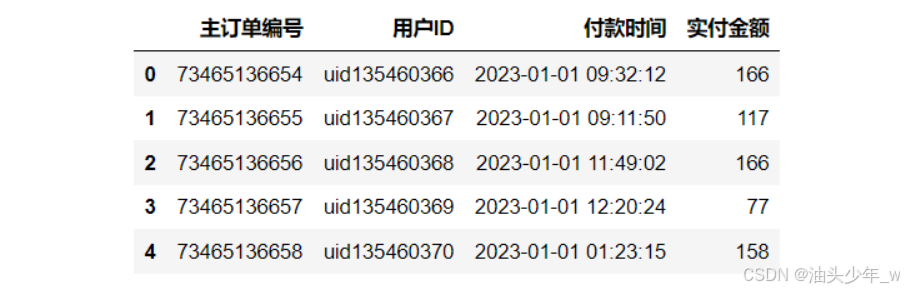
step1:读取数据,读取数据加载到程序中构建DataFrame
-
step2:增加年月时间列,构建数据对应的年-月列,方便后期按照月份进行分组
select *, substr(付款时间, 1, 7) as 时间标签 from table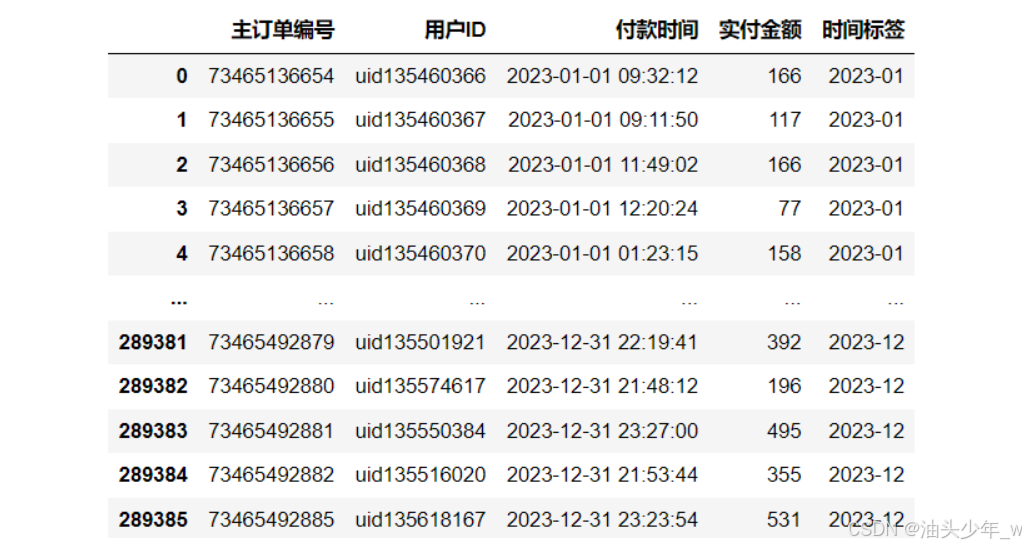
- step3:计算2月新增用户信息,查询2月的用户ID,然后与1月的用户ID进行比较,筛选出2月的新增用户ID
with t1 as ( -- 获取2月份有哪些用户消费了 select 用户ID , sum(实付金额) as 消费总金额 from table where 时间标签 = '2023-02' group by 用户ID ) -- hive -- 找出2月份新增的用户 select count(t1.用户id) -- 2月份消费的用户 from t1 -- 1月份消费的用户 -- 左边有,结果一定会有,右边没有会补null left join (select 用户ID from table where 时间标签 = '2023-01') history on t1.用户ID = t2.用户ID -- 在2月份消费了,但是在1月份没有消费 where t2.用户ID is null; -- mysql:user_new with t1 as ( -- 获取2月份有哪些用户消费了 select 用户ID , sum(实付金额) as 消费总金额 from table where 时间标签 = '2023-02' group by 用户ID ), t2 as ( -- 2月份新增的用户ID select t1.用户ID from t1 where t1.用户ID not in (select 用户ID from table where 时间标签 = '2023-01') ; ) select '2月份' as month_str count(t1.用户ID) from t2 ;
-
step4:计算2月新增用户在往后每个月的留存用户,计算2月新增的用户ID在后面每个月出现的情况
-- 3月份留存: 2月份新增这些人有多少在3月份也访问了 -- 找出2月份的这些新增用户哪些人在3月份 select '3月份' as month_str , count(t2.用户ID) -- 2月份新增的用户ID from t2 -- 筛选 2月份新增的用户 中 在三月份也访问了的 where t2.用户ID in (select 用户ID from table where 时间标签 = '2023-03')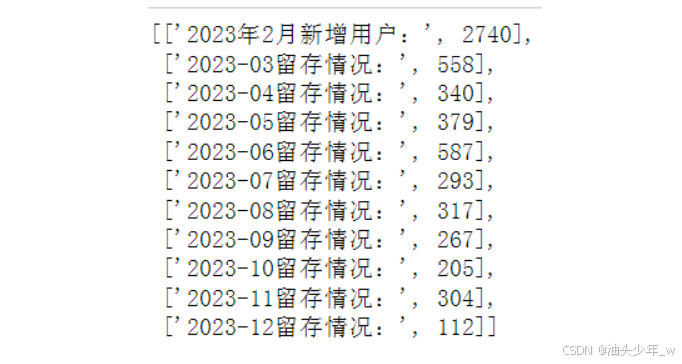
-
step5:每个月回购用户实现,循环计算每个月的新增用户在后续每个月的用户留存情况
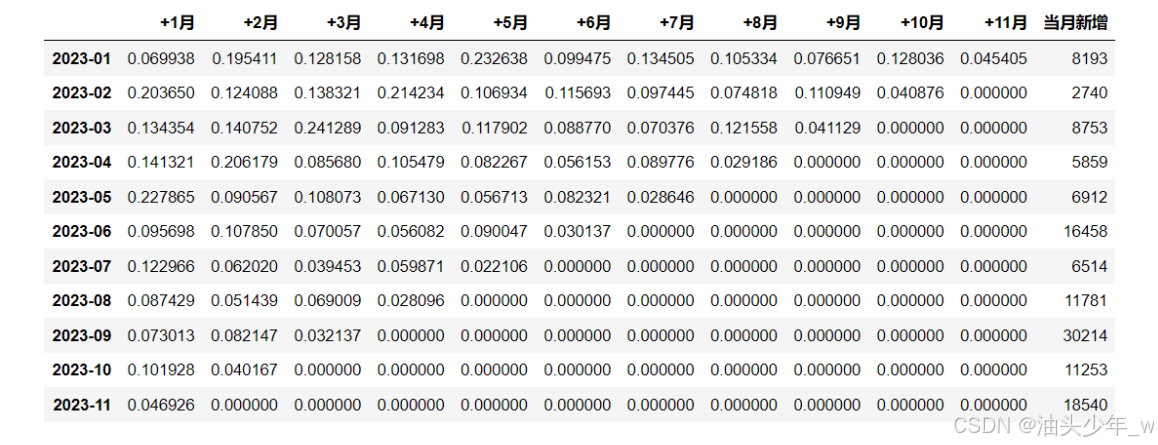
-
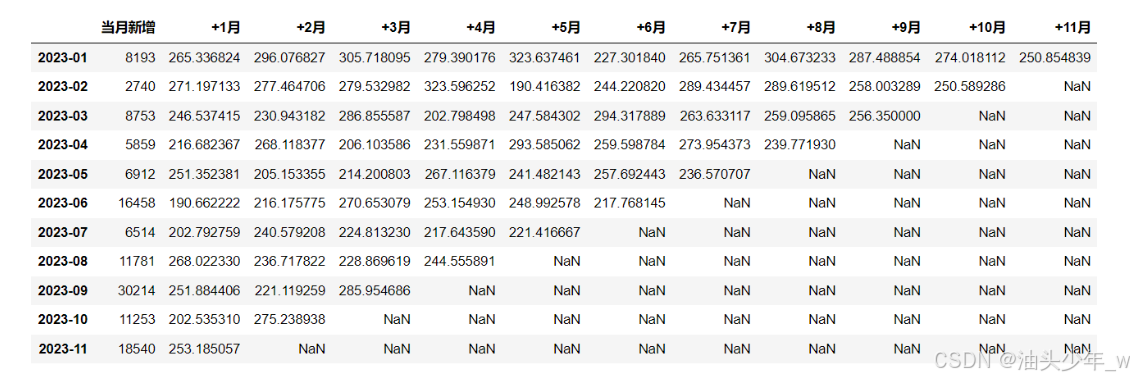
step6:每个月留存客单的实现,计算每个月的留存客单价 = 留存用户消费金额 / 留存用户个数
-
-
-
小结:理解同期群分析数据探索
【实现】同期群分析单月处理
-
目标:实现同期群分析单月处理
-
实施
-
step1:读取数据
# 加载数据 df = pd.read_excel('../data/10、group_anlysis.xlsx', engine='openpyxl') print('订单行数:',len(df)) # 查看数据内容 df.head() -
step2:增加年月时间列
# 增加时间标签,年-月 df['时间标签'] = df['付款时间'].astype(str).str[:7] df -
step3:计算2月新增用户信息
# 以2月份为例 month = '2023-02' #筛选出2月相关的订单 sample = df.loc[df['时间标签'] == month,:] print('2月订单数量:',len(sample)) sample.head(10) # 统计2月每个用户的实付金额 sample_c = sample.groupby('用户ID')['实付金额'].sum().reset_index() print('2月用户数量:',len(sample_c)) sample_c.head(10) # 取出前一个月的数据 history = df.loc[df['时间标签'] == '2023-01', :] history.head(10) # 计算2月的新增用户数 sample_c = sample_c.loc[ sample_c['用户ID'].isin(history['用户ID']) == False, :] print('2023年2月新增用户:',len(sample_c)) sample_c.head(10) -
step4:计算2月新增用户在往后每个月的留存用户
# 计算这批新增用户,在往后每个月的留存情况 # 定义一个空列表 re = [] # 循环取出每个月 for i in ['2023-03', '2023-04', '2023-05', '2023-06','2023-07','2023-08','2023-09','2023-10','2023-11','2023-12']: # 取出这个月的数据 next_month = df.loc[df['时间标签'] == i,:] # 用这批用户的ID与当前月的用户ID进行比较,获取所有复购的用户ID target_users = sample_c.loc[sample_c['用户ID'].isin(next_month['用户ID']),:] # 将这个月用户留存的个数存储在列表中 re.append([i+'留存情况:',len(target_users)]) # 输出列表 re # 将2月份单独计算的数据加入进去 re.insert(0,['2023年2月新增用户:',len(sample_c)]) re
-
-
小结:实现同期群分析单月处理
【实现】同期群分析需求实现
-
目标:实现同期群分析需求实现
-
实施
-
step5:每个月回购用户实现
# 获取数据中的每个月份 unique month_lst = df['时间标签'].unique() print(month_lst) # 定义一个空的DataFrame final , 用于存储最后的结果 final = pd.DataFrame() # 循环取出每个月份对应的下标 for i in range(len(month_lst) - 1): # 构造一个和月份个数一样长的列表,方便后续格式统一 count = [0] * len(month_lst) # 筛选出当月订单,并按用户ID分组 target_month = df.loc[df['时间标签'] == month_lst[i], :] # 计算这个月每个用户的实付金额:获取所有下单的用户ID target_users = target_month.groupby('用户ID')['实付金额'].sum().reset_index() #如果是第一个月,则跳过(因为不需要和历史数据验证是否为新增用户) if i == 0: new_target_users = target_month.groupby('用户ID')['实付金额'].sum().reset_index() # 如果不是第一个月 else: # 获取上个月的用户信息 history = df.loc[df['时间标签'].isin(month_lst[:i]),:] # 取出当前这个月的新增的用户ID new_target_users = target_users.loc[target_users['用户ID'].isin(history['用户ID']) == False,:] # 将当月新增用户数放在列表的第一个值中 count[0] = len(new_target_users) #以月为单位,循环遍历,计算留存情况 for j, ct in zip(range(i + 1, len(month_lst)), range(1, len(month_lst))): # 下一个月的订单 next_month = df.loc[df['时间标签'] == month_lst[j],:] # 下一个月的用户ID next_users = next_month.groupby('用户ID')['实付金额'].sum().reset_index() #计算在该月仍然留存的用户数量 isin = new_target_users['用户ID'].isin(next_users['用户ID']).sum() count[ct] = isin #格式转置 result = pd.DataFrame({month_lst[i]:count}).T #合并 final = pd.concat([final,result]) # 设置列名 final.columns = ['当月新增','+1月','+2月','+3月','+4月','+5月','+6月','+7月','+8月','+9月','+10月','+11月'] # 输出结果 final # 计算比例 result = final.divide(final['当月新增'], axis = 0).iloc[:,1:] result['当月新增'] = final['当月新增'] # 输出 result -
step6:每个月留存客单的实现
#引入时间标签 month_lst = df['时间标签'].unique() #后面加了个m,代表金额相关 final_m = pd.DataFrame() #中间代码相同 for i in range(len(month_lst) - 1): #构造和月份一样长的列表,方便后续格式统一 count = [0] * len(month_lst) #筛选出当月订单,并按用户昵称分组 target_month = df.loc[df['时间标签'] == month_lst[i],:] target_users = target_month.groupby('用户ID')['实付金额'].sum().reset_index() #如果是第一个月,则跳过(因为不需要和历史数据验证是否为新增用户) if i == 0: new_target_users = target_month.groupby('用户ID')['实付金额'].sum().reset_index() else: #如果不是,找到之前的历史订单 history = df.loc[df['时间标签'].isin(month_lst[:i]),:] #筛选出未在历史订单中出现过的新增用户 new_target_users = target_users.loc[target_users['用户ID'].isin(history['用户ID']) == False,:] #将当月新增用户数放在第一个值中 count[0] = len(new_target_users) #以月为单位,循环遍历,计算留存情况 for j,ct in zip(range(i + 1,len(month_lst)),range(1,len(month_lst))): #下一个月的订单 next_month = df.loc[df['时间标签'] == month_lst[j],:] next_users = next_month.groupby('用户ID')['实付金额'].sum().reset_index() #计算在该月仍然留存的用户的回购金额 isin_m = next_users.loc[next_users['用户ID'].isin(new_target_users['用户ID']) == True,'实付金额'].sum() count[ct] = isin_m #格式转置 result = pd.DataFrame({month_lst[i]:count}).T #合并 final_m = pd.concat([final_m,result]) final_m.columns = ['当月新增','+1月','+2月','+3月','+4月','+5月','+6月','+7月','+8月','+9月','+10月','+11月'] final_m # 计算留存客单价 result_m = final_m / final result_m['当月新增'] = final_m['当月新增'] result_m
-
-
小结:实现同期群分析需求实现

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)