高光谱图像分类-基于Python的多分类器对比与结果可视化
本文是基于 Python 的高光谱图像分类实验指南,以 “dc_hx.mat” 光谱数据与 “dc_gt.mat” 标签数据为实验对象,利用 Scikit-learn 和 Matplotlib 等工具,完成高光谱图像分类实验。实验涵盖数据预处理、训练测试集划分、KNN、SVM 等多分类器训练评估及全图分类可视化四大步骤。
一、实验目的
-
高光谱数据预处理:从3D数据转换为2D样本,去除无效标签,归一化处理
-
多分类器对比:学习KNN、SVM、随机森林等算法的实现与调参
-
性能评估:计算OA(总体准确率)、AA(平均准确率)和Kappa系数
-
结果可视化:绘制分类结果图并对比不同算法的表现
二、数据集与工具
-
数据集:高光谱图像
dc_hx.mat(光谱数据)与dc_gt.mat(标签数据)
上述数据为公开数据,可自行替换
-
工具:Python + Scikit-learn + Matplotlib
三、实验步骤与代码解析
1. 数据加载与预处理
关键代码:
# 加载数据
data = sio.loadmat('dc_hx.mat')['dc']
labels = sio.loadmat('dc_gt.mat')['dc_gt']
# 3D转2D(样本×特征)
X = data.reshape(-1, data.shape[-1])
y = labels.ravel()
# 去除无标签样本(标签为0的像素)
X = X[y > 0]
y = y[y > 0]
# 归一化
scaler = StandardScaler()
X = scaler.fit_transform(X) 说明:
-
高光谱数据维度为
(宽×高×波段),需转换为(样本数×特征数)供模型训练 -
归一化可消除不同波段量纲差异,提升模型收敛速度
2. 划分训练集与测试集
关键代码:
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=42, stratify=y
) 参数解析:
-
test_size=0.1:10%数据作为测试集 -
stratify=y:保持训练集与测试集的类别分布一致
3. 多分类器训练与评估
支持的算法:
-
K近邻(KNN)
-
支持向量机(SVM,RBF核)
-
随机森林(Random Forest)
-
逻辑回归(Logistic Regression)
-
决策树(Decision Tree)
-
朴素贝叶斯(Naive Bayes)
评估指标:
-
OA(Overall Accuracy):总体分类准确率
-
AA(Average Accuracy):各类别准确率的平均值
-
Kappa系数:衡量分类结果与随机分类的一致性
关键代码:
for name, clf in classifiers.items():
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
oa = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
aa = np.mean(np.diag(cm) / np.sum(cm, axis=1))
kappa = cohen_kappa_score(y_test, y_pred)
results[name] = {"OA": oa, "AA": aa, "Kappa": kappa} 4. 全图分类与可视化
关键代码:
# 全图分类
image_2d = data.reshape(-1, data.shape[-1])
image_2d = scaler.transform(image_2d)
classified_image = clf.predict(image_2d)
classified_image = classified_image.reshape(data.shape[:2])
# 可视化
plt.imshow(classified_image, cmap='jet')
plt.title(f"{name} Classification") 效果图示例:
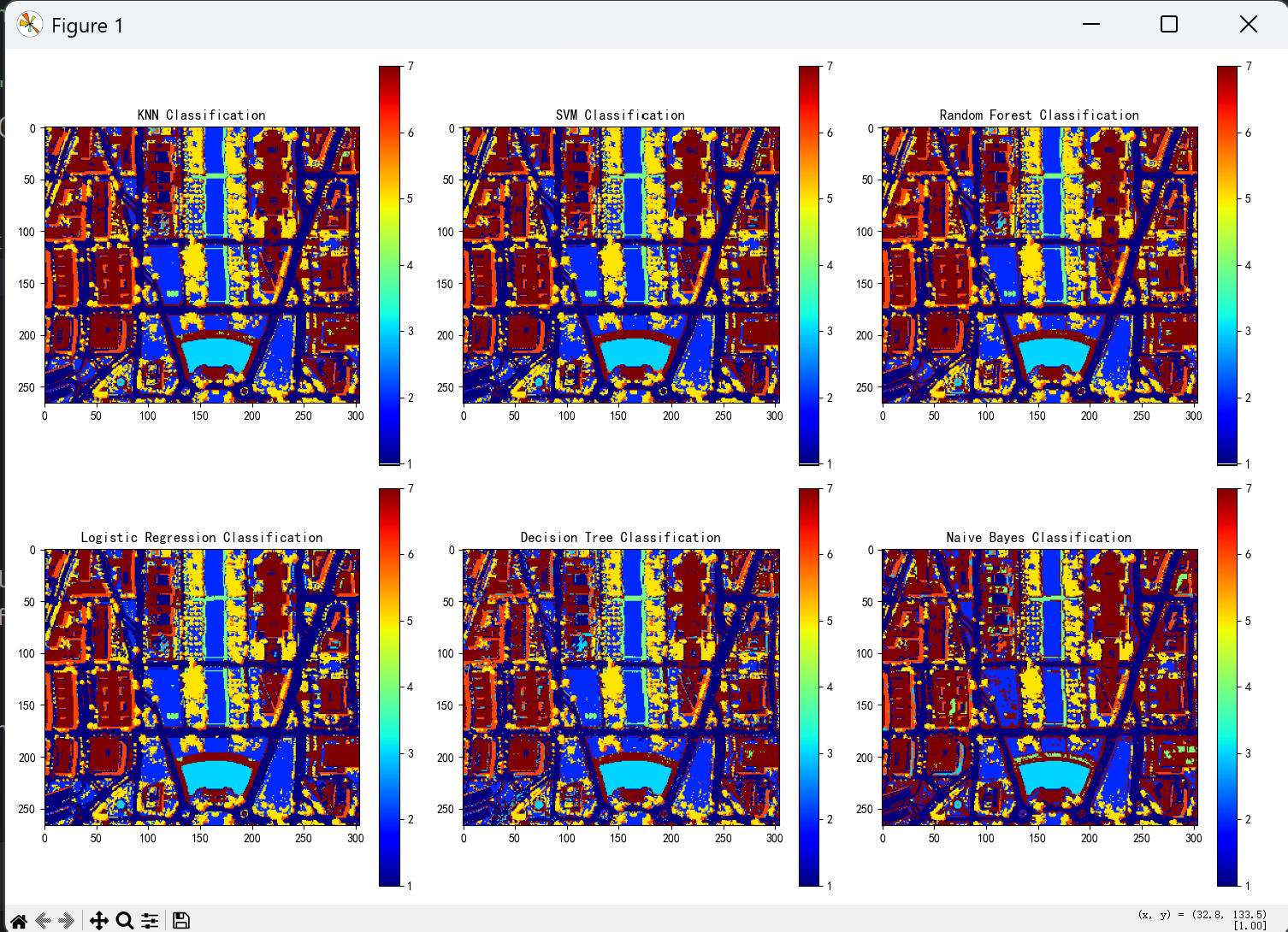


永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)