CentOS7下的大数据集群(Hadoop生态)安装部署
通过以上步骤,可构建一个稳定可靠的 Hadoop 大数据集群,支持海量数据的存储与计算。生产环境中需注意定期备份 NameNode 元数据(文档段落:),并根据业务流量动态调整节点资源。参考官方文档()可进一步学习 HA 集群配置、安全认证等高级特性。
·
一、集群化环境前置准备
1.1 虚拟机集群规划
1.1.1 节点角色分配(3 节点方案)
| 节点名称 | IP 地址 | 角色分配 |
|---|---|---|
| node1 | 192.168.88.130 | Namenode、ResourceManager、HistoryServer、WebProxyServer、Zookeeper |
| node2 | 192.168.88.131 | Datanode、NodeManager、Zookeeper |
| node3 | 192.168.88.132 | Datanode、NodeManager、Zookeeper |
1.1.2 基础环境配置(所有节点执行)
- 克隆虚拟机:
通过 VMware 克隆 3 台 CentOS 虚拟机,配置固定 IP 并修改主机名(文档段落:-)。bash
hostnamectl set-hostname node1 # 各节点分别设置为node1/node2/node3 - 关闭防火墙与 SELinux(文档段落:-):
bash
systemctl stop firewalld && systemctl disable firewalld sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux reboot - 配置主机名映射(文档段落:-):
bash
echo "192.168.88.130 node1" >> /etc/hosts echo "192.168.88.131 node2" >> /etc/hosts echo "192.168.88.132 node3" >> /etc/hosts
1.2 SSH 免密登录配置(文档段落:-)
bash
# 生成密钥对(node1执行)
ssh-keygen -t rsa -b 4096 -N ""
# 分发公钥到node2/node3
ssh-copy-id node2 && ssh-copy-id node3
# 验证免密登录
ssh node2 "echo hello from node1"
二、JDK 环境统一部署
2.1 下载与安装(所有节点执行)
bash
# 下载JDK 8压缩包(文档段落:-)
wget https://download.oracle.com/java/8/latest/jdk-8u351-linux-x64.tar.gz
# 解压并创建软链接
tar -zxvf jdk-8u351-linux-x64.tar.gz -C /export/server
ln -s /export/server/jdk1.8.0_351 /export/server/jdk
2.2 环境变量配置
bash
# 编辑系统配置文件(文档段落:-)
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$JAVA_HOME/bin:$PATH
source /etc/profile # 立即生效
# 验证安装
java -version # 应输出"1.8.0_351"
三、Hadoop 集群核心组件部署
3.1 安装包下载与解压
bash
# 下载Hadoop 3.3.0(文档段落:-)
wget http://archive.apache.org/dist/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
# 解压并创建软链接(node1执行)
tar -zxvf hadoop-3.3.0.tar.gz -C /export/server
ln -s /export/server/hadoop-3.3.0 /export/server/hadoop
3.2 核心配置文件修改
3.2.1 hadoop-env.sh(文档段落:-)
bash
vim /export/server/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/export/server/jdk # 配置Java路径
export HADOOP_HOME=/export/server/hadoop
3.2.2 core-site.xml(文档段落:-)
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value> <!-- NameNode地址 -->
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value> <!-- 缓冲区大小 -->
</property>
</configuration>
3.2.3 hdfs-site.xml(文档段落:-)
xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value> <!-- NameNode元数据存储路径 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value> <!-- DataNode数据存储路径 -->
</property>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 数据副本数 -->
</property>
</configuration>
3.2.4 yarn-site.xml(文档段落:-)
xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value> <!-- ResourceManager地址 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value> <!-- Shuffle服务 -->
</property>
</configuration>
四、集群角色配置与启动
4.1 角色分配与目录创建
| 节点 | 角色 | 数据目录创建命令 |
|---|---|---|
| node1 | Namenode | mkdir -p /data/nn |
| node2/node3 | Datanode | mkdir -p /data/dn |
| 所有节点 | NodeManager | mkdir -p /data/nm-local /data/nm-log |
4.2 格式化 NameNode(node1 执行)
bash
hadoop namenode -format # 首次启动前执行(文档段落:)
4.3 启动 HDFS 集群
bash
# 启动NameNode和DataNode
start-dfs.sh # 文档段落:
# 验证进程(node1应看到NameNode,node2/node3应看到DataNode)
jps | grep -E "NameNode|DataNode"
4.4 启动 YARN 集群
bash
start-yarn.sh # 文档段落:
# 验证进程(node1应看到ResourceManager,node2/node3应看到NodeManager)
jps | grep -E "ResourceManager|NodeManager"
五、集群状态验证与管理
5.1 网页管理界面
- HDFS 状态:访问
http://node1:9870,查看文件系统概览、节点列表。 - YARN 状态:访问
http://node1:8088,查看应用程序运行情况、资源使用统计。
5.2 命令行验证
5.2.1 查看 HDFS 文件系统
bash
hadoop fs -ls / # 列出根目录文件
hadoop fs -mkdir /test # 创建测试目录
hadoop fs -put /etc/hosts /test/hosts.txt # 上传文件到HDFS
5.2.2 运行 MapReduce 示例程序
bash
# 执行单词计数示例(文档段落:)
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /test/hosts.txt /output
# 查看结果
hadoop fs -cat /output/part-r-00000
六、常见故障排查与优化
6.1 节点无法启动
可能原因:
- 防火墙未关闭:确保所有节点防火墙已禁用(文档段落:)。
- SSH 免密失败:检查
~/.ssh/authorized_keys是否包含所有节点公钥(文档段落:)。 - 配置文件错误:使用
hadoop namenode -checkpoint检查配置语法。
6.2 数据写入失败
解决方法:
- 检查
dfs.replication配置是否与节点数匹配,建议设置为 2 或 3。 - 确保 DataNode 数据目录权限正确:
chown -R hadoop:hadoop /data/dn。
6.3 性能优化建议
- 调整副本数:生产环境建议
dfs.replication=3,提升数据可靠性。 - 增加资源配置:在
yarn-site.xml中配置 NodeManager 内存:xml
<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> <!-- 8GB内存 --> </property>
七、Hadoop 生态组件扩展部署(可选)
7.1 HBase 集群部署(依赖 HDFS)
- 配置
hbase-site.xml(文档段落:-):xml
<property> <name>hbase.rootdir</name> <value>hdfs://node1:8020/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> - 启动 HBase:
bash
start-hbase.sh hbase shell # 进入HBase命令行,创建表测试
7.2 Kafka 集群部署(依赖 Zookeeper)
- 配置
server.properties:properties
zookeeper.connect=node1:2181,node2:2181,node3:2181 - 创建主题:
bash
kafka-topics.sh --create --zookeeper node1:2181 --topic test --partitions 3 --replication-factor 2
八、生产环境最佳实践
8.1 高可用架构设计
8.1.1 主备 NameNode
bash
# 配置SecondaryNameNode(node2执行)
vim /export/server/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.secondary.http.address</name>
<value>node2:50090</value>
</property>
8.1.2 磁盘均衡
bash
# 自动平衡DataNode磁盘空间
start-balancer.sh -threshold 10 # 允许10%的空间差异
8.2 监控体系搭建
- Prometheus+Grafana:
- 通过
hadoop-exporter采集指标,配置 Prometheus 抓取规则。 - 在 Grafana 中导入 Hadoop 监控模板,实时展示 CPU、内存、磁盘利用率。
- 通过
- 日志聚合:
使用 Flume 或 Logstash 将 Hadoop 日志收集到 Elasticsearch,通过 Kibana 搜索分析。
九、总结:Hadoop 集群部署核心流程
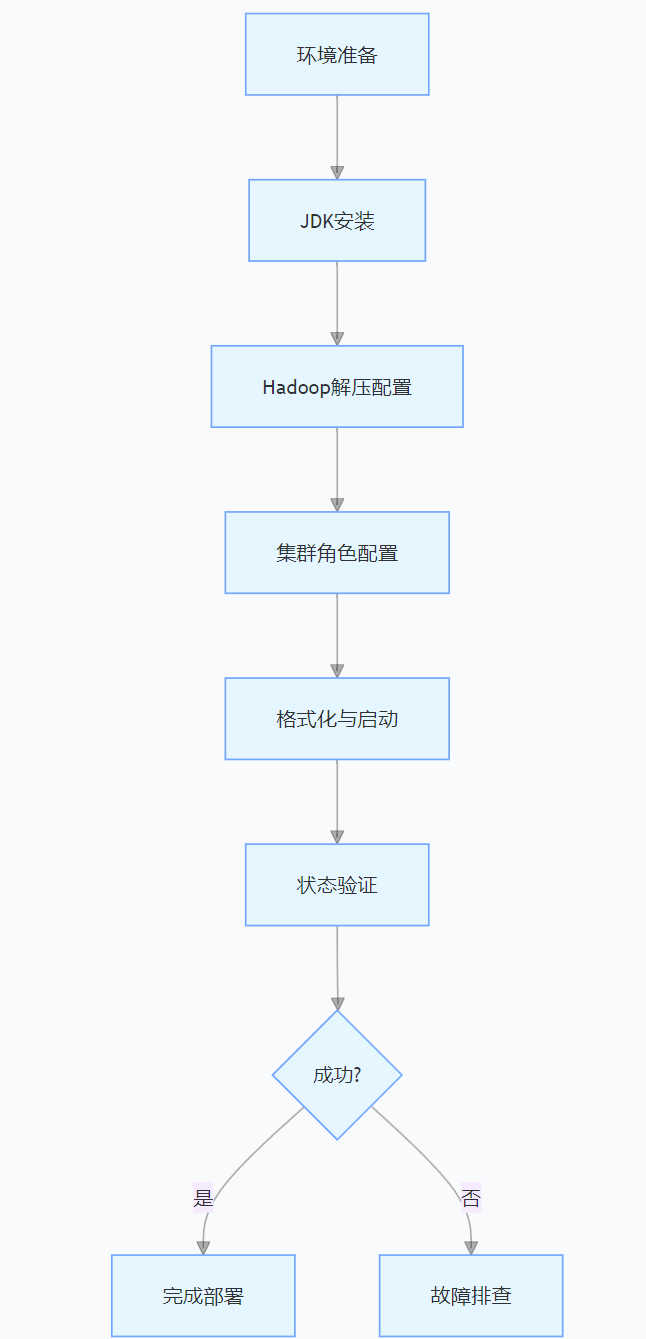
通过以上步骤,可构建一个稳定可靠的 Hadoop 大数据集群,支持海量数据的存储与计算。生产环境中需注意定期备份 NameNode 元数据(文档段落:),并根据业务流量动态调整节点资源。参考官方文档(Hadoop Documentation)可进一步学习 HA 集群配置、安全认证等高级特性。

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐

 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)