物联网大数据时代:时序数据库选型深度指南,为何IoTDB脱颖而出?
摘要 物联网设备产生海量时序数据,具有高并发写入、精确时间戳和指数级增长的特点,传统数据库难以满足需求。时序数据库通过优化存储结构、高效压缩算法和查询引擎,成为物联网数据处理的理想选择。选型需考量写入吞吐量、查询性能、扩展性、数据模型和生态集成等因素。Apache IoTDB以其树形数据模型、超高压缩率、千万级写入能力和毫秒级查询响应脱颖而出,成为物联网时序数据库的首选方案。其独立自研架构、标准文
一、引言
从智能家居的温湿度传感器,到工业生产线上的设备运行状态监控,再到智慧城市的交通流量感知,以及遍布全球的各类智能终端,物联网设备正以前所未有的速度连接、感知并生成数据。
这些数据具有鲜明的特征:都带有精确的时间戳,以高并发、持续不断的方式产生,并且在数据量上呈现出指数级增长的趋势。更重要的是,物联网数据往往是“写多读少”的典型场景——设备持续不断地上传数据,而对这些数据的查询和分析则相对集中于特定的时间段或需求。
传统的关系型数据库(如MySQL、PostgreSQL)或通用型NoSQL数据库(如MongoDB、Cassandra)在处理这类数据时,有一些吃力。它们在数据模型上并非为时间序列优化,导致存储效率低下,数据冗余高;在查询性能上,面对海量时间点数据的聚合、范围查询和多维分析时力不从心,响应迟缓;同时,在面对物联网场景下持续高并发的写入和PB级甚至EB级的数据量时,传统数据库的扩展性也显得捉襟见肘,难以满足业务的快速发展需求。
为了应对物联网大数据带来的独特挑战,时序数据库应运而生。时序数据库是一种专门为高效存储、管理和查询时序数据而设计的数据库。它通过采用优化的存储结构(如列式存储)、高效的数据压缩算法(如差值编码、行程编码等)以及针对时间维度设计的索引和查询引擎,极大地提升了时序数据的存储效率和查询性能。与传统数据库相比,时序数据库能够更好地处理高并发写入、海量数据存储、复杂时间范围查询和聚合分析等任务,从而成为物联网、工业互联网、金融、监控等领域不可或缺的基础设施。
面对市场上琳琅满目的时序数据库产品,如何在复杂的物联网场景中做出明智的选型?本文提供一份深度、实用的时序数据库选型指南,深入解析Apache IoTDB,如何凭借其独特的架构设计和卓越性能,成为物联网大数据时代构建智慧物联基石的优选方案。
二、物联网大数据背景下的时序数据
物联网设备产生的时序数据量是惊人的。单个传感器每秒可能生成数条数据,而一个大型物联网系统可能拥有数百万甚至上亿的设备。每天产生的数据量可达TB甚至PB级别,长期累积下来将达到PB级甚至EB级的存储规模。传统数据库在应对如此海量的数据时,面临存储成本高昂、性能急剧下降的问题。因此,物联网背景下的时序数据库必须具备:
- 极致的存储效率: 能够通过高效的数据压缩算法(如无损压缩、有损压缩、差值编码等)大幅降低存储空间占用,从而有效控制硬件成本。
- 灵活的数据生命周期管理: 支持数据的冷热分层存储(例如,近期数据存储在高性能介质上,历史数据迁移至成本更低的存储介质),以及基于时间或业务规则的过期数据自动清理机制(TTL, Time-To-Live),以优化存储资源和查询性能。
物联网数据的显著特点是持续、高频的写入。数百万设备可能同时向数据库发送数据,要求数据库具备每秒处理百万甚至千万级别数据点的高并发写入能力,并且能够稳定处理乱序写入(即数据到达顺序与时间戳不一致的情况)。同时,为了支撑实时监控、预警和业务分析,对这些数据的查询也提出了极高的性能要求:
- 毫秒级查询响应: 无论是单点查询、时间范围查询、聚合查询(如求平均值、最大值、最小值、计数等),还是跨多个测点的复杂多维分析,都要求在毫秒级别内返回结果。
- 支持复杂查询模式: 能够高效处理基于时间窗口的聚合、降采样、插值、时间对齐以及多测点关联查询等复杂操作。
许多物联网应用场景对数据的实时性有着极高的要求。例如,工业控制系统需要实时监测设备状态并进行异常预警;智能交通系统需要实时分析路况以优化信号灯配时。时序数据库不仅要能快速写入数据,还要能以极低的延迟进行数据采集、处理和分析,从而:
- 能够快速响应数据变化,及时发现异常并触发告警,为决策者提供实时洞察。
- 为自动化控制、预测性维护等实时决策系统提供数据支撑。
三、时序数据库选型核心考量
性能是时序数据库的核心竞争力,直接决定了系统处理物联网数据的能力上限。
- 写入吞吐量: 衡量数据库每秒能够处理的数据点数量。物联网场景下,设备数量庞大且持续产生数据,要求数据库具备极高的写入吞吐量,能够稳定承载百万甚至千万级的数据点写入,并支持乱序写入,以应对网络延迟或设备端数据积压导致的写入顺序不一致问题。
- 查询响应时间: 衡量数据库执行查询并返回结果所需的时间。无论是实时监控、历史数据分析还是异常检测,都要求查询响应时间尽可能短,最好能达到毫秒级,以支持实时决策和快速洞察。这包括单点查询、时间范围查询、聚合查询(如求和、平均、最大、最小、计数等)以及复杂的多维分析查询。
- 数据压缩率: 时序数据通常具有高度重复性或规律性,优秀的时序数据库会采用先进的压缩算法(如差值编码、行程编码、Gorilla编码等)来大幅减少存储空间占用。高压缩率意味着更低的存储成本和更高的I/O效率,对于PB级甚至EB级的数据存储至关重要。
- 物联网设备的数量和数据量呈爆发式增长,数据库必须具备良好的扩展性。
- 垂直扩展 (Vertical Scaling): 通过增加单台服务器的CPU、内存、存储等资源来提升性能。
- 水平扩展 (Horizontal Scaling): 通过增加服务器节点来分散负载,实现线性扩展,这是应对海量数据和高并发写入的根本途径。选型时需关注数据库是否支持分布式架构、数据分片、集群管理等功能。
时序数据库的数据模型和查询能力直接影响数据的组织、管理和分析效率。
- 能够直观地映射物联网设备的层级结构,支持为设备、传感器、测点添加多维标签(Tags)和属性(Attributes),便于数据的分类、过滤和检索。理想的数据模型应允许用户根据业务需求灵活定义数据结构,而不仅仅是固定的时间戳和值。
- 提供直观易用的查询语言,最好是类SQL或具备强大表达力的领域特定语言(DSL)。该语言应支持丰富的时序数据操作函数,包括:
- 时间窗口聚合: 按分钟、小时、天等时间粒度进行数据聚合。
- 降采样: 将高频数据转换为低频数据,减少数据量。
- 插值: 填充缺失数据点。
- 时间对齐: 将不同设备或测点的数据对齐到统一的时间轴上进行比较分析。
- 复杂过滤与关联: 支持基于时间、设备、测点、标签等多维度的复杂数据过滤和跨测点/设备的数据关联查询。
- 能够高效处理多维分析、趋势预测、异常检测、模式识别等高级分析需求,为上层应用提供强大的数据支撑。
有效的数据存储和管理策略是确保系统长期稳定运行的关键。
- 存储效率: 高压缩率是降低存储成本的关键。此外,还需关注数据库是否支持稀疏数据存储,即只存储有值的数据点,避免存储大量空值。
- 数据生命周期管理 : 支持数据的冷热分层存储,以及基于时间或业务规则的过期数据自动清理机制(TTL, Time-To-Live),以优化存储资源和查询性能。
- 数据可靠性与高可用性: 确保数据不丢失且服务不中断。通过数据复制、集群容错、故障自动切换、数据备份与恢复等机制来实现。
一个成熟的时序数据库应能与现有技术栈无缝集成,降低开发和运维成本。
- 提供多语言(如Java, Python, Go, C++等)的API和SDK,方便开发人员快速集成和开发应用。
- 能够与主流的物联网平台、消息队列(如Kafka, MQTT)、可视化工具(如Grafana, Tableau)、大数据分析框架(如Spark, Flink)等进行无缝集成,形成完整的数据处理链路。
- 对于开源项目,活跃的社区意味着更快的迭代速度、更丰富的资源、更及时的技术支持和问题解决。对于商业产品,则需关注厂商提供的技术支持服务水平。
除了技术指标,运维的便捷性和总拥有成本(TCO)也是选型时不可忽视的因素。
- 数据库的部署、配置、监控、扩容、升级和故障排查是否简单便捷。是否提供图形化管理界面、完善的监控指标和日志系统。
- 在给定性能要求下,数据库所需的CPU、内存、存储等硬件资源量。资源消耗越少,硬件成本越低。
四、IoTDB为何脱颖而出?
在众多时序数据库中,Apache IoTDB 作为专为物联网(IoT)场景设计和优化的时序数据库,凭借其独特的技术架构和功能特性,在解决物联网时序数据挑战方面表现出色,逐渐成为构建智慧物联基石的优选方案。
Apache IoTDB 源于清华大学,超 10 年演进,Apache 物联网时序数据库领域首个 Top-Level 项目。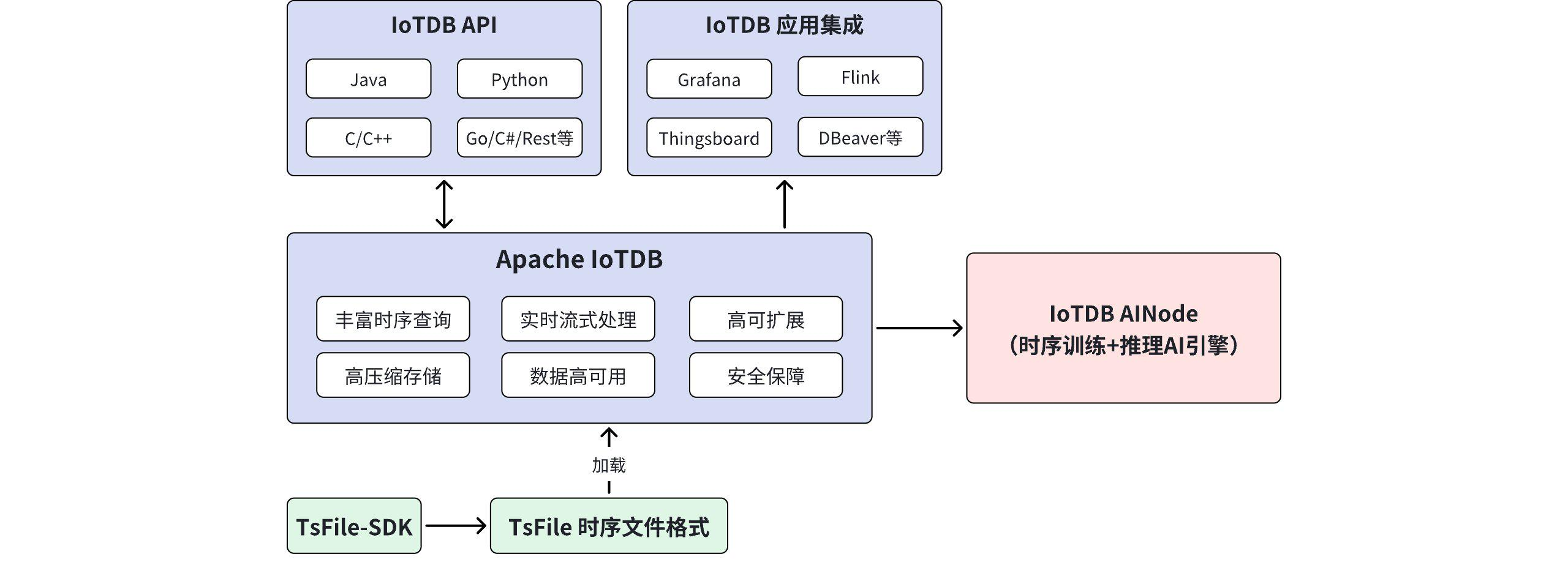
企业版官网地址:https://timecho.com。
下载地址:https://iotdb.apache.org/zh/Download/
IoTDB 的核心优势之一在于其对物联网数据特性的深刻理解和优化。
- 树形结构数据模型: IoTDB 采用天然契合物联网设备层级关系的树形数据模型。这种模型不仅易于理解,也极大地提升了查询效率,尤其是在进行路径匹配或层级聚合时。
- 除了时间序列数据本身,IoTDB 还支持为设备和传感器添加丰富的标签(Tags)和属性(Attributes)。通过标签,用户可以进行多维度的过滤和聚合查询。
Apache IoTDB 的独特优势:
- 独立自研:Apache IoTDB 是由清华大学发起,Apache 基金会唯一的时序数据库 Top-Level 项目,从 0 到 1 自主研发,底层数据文件到分布式架构均不依赖第三方系统。
- 时序数据标准文件格式:底层时序数据文件格式 TsFile 为 Apache Top-Level 项目,相比通用文件格式,写入/查询吞吐、压缩比可提升 3-15 倍,显著降低存储成本,并实现在线、离线数据高效流转。
- 双时序模型:树、表双模型支持,同时适配工业监控场景与设备管理场景,架构灵活性与分析效率双保障,方便用户根据自身需求选择更合适的模型。
- 千万级数据写入:采用列式写入模式,实现高频数据毫秒级接入,并首创乱序分离存储引擎,实现乱序数据无感写入,轻松应对海量数据高并发写入需求。
- 毫秒级查询响应:通过高效的索引机制和查询优化,大幅提升数据查询效率,并支持降采样查询、时序分段查询、数据补齐与修复等操作,内置超 70 种 UDF 函数帮助分析。
- 商业友好:Apache IoTDB 遵循 Apache 2.0 协议,允许企业修改、使用项目代码用于商业化应用,开源协议稳定,无需担心变更。
面对物联网海量数据的高并发写入和快速查询需求,IoTDB 展现出强大的性能。
- IoTDB 针对时序数据的特点进行了深度优化,能够支持百万级甚至千万级每秒的数据点写入,并能稳定处理乱序数据写入,确保数据能够高效、可靠地从海量设备端汇入数据库。
- IoTDB 采用了多种先进的时序数据压缩算法(如差值编码、行程编码、Gorilla 编码、数据类型自适应编码等),结合其独特的 TsFile 存储格式,能够实现极高的数据压缩率。这不仅大幅降低了存储成本,也减少了磁盘I/O,从而提升了查询性能。
- 无论是单点查询、时间范围查询、聚合查询(如求平均值、最大值、最小值、计数等),还是基于路径和标签的复杂多维分析,IoTDB 都能在毫秒级别内返回结果。其查询引擎针对时序数据特点进行了优化,支持高效的降采样、插值、时间对齐等操作。
IoTDB 不仅仅是一个云端数据库,其轻量级设计使其具备了独特的边缘计算能力,实现了边缘与云端的无缝协同。
- IoTDB 可以以轻量级的形式部署在边缘网关或工业PC等资源受限的边缘设备上,实现数据的本地存储、预处理和实时分析,减少对云端的网络带宽依赖。
- IoTDB 支持边缘数据到云端的可靠同步,确保数据的完整性和一致性。这种边缘-云协同架构使得数据可以在离源头最近的地方进行处理,降低了延迟,提高了系统的响应速度和韧性。
- 边缘端的 IoTDB 可以对原始数据进行预聚合、降采样或过滤,只将关键数据上传至云端,进一步降低网络传输和云端存储成本。
IoTDB 作为 Apache 顶级项目,拥有活跃的社区和不断完善的生态系统,为用户提供了良好的开发和运维体验。
- IoTDB 提供了类 SQL 的查询语言(IoTDB SQL),使得熟悉关系型数据库的用户能够快速上手,降低了学习曲线。同时,它也扩展了针对时序数据特有的函数和语法,方便用户进行复杂的时序分析。
- 提供多语言(Java、Python、Go 等)的客户端 API 和 JDBC/ODBC 驱动,方便开发人员集成到现有应用中。同时,也提供了命令行工具、可视化管理工具等,简化了数据库的运维管理。
- IoTDB 能够与主流的物联网平台、消息队列(如 Kafka、MQTT)、大数据分析框架(如 Apache Spark、Apache Flink)、可视化工具(如 Grafana)等进行无缝集成,构建端到端的数据处理和分析链路。
- 作为 Apache 顶级项目,IoTDB 拥有一个充满活力的全球开源社区,持续进行功能迭代、性能优化和问题修复,提供了强大的技术支持和保障。
IoTDB 在设计之初就考虑了大规模物联网部署的成本效益和未来扩展需求。
- 得益于其卓越的数据压缩能力,IoTDB 能够显著降低硬件存储成本。
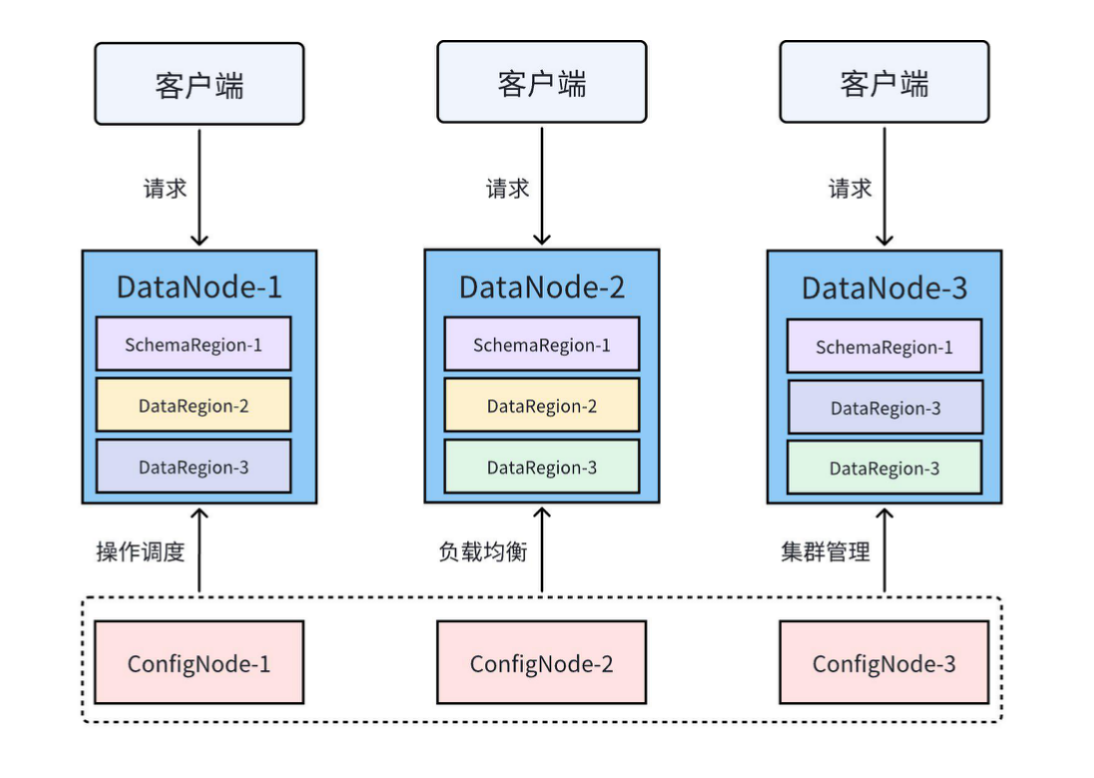
- IoTDB 支持分布式集群部署,具备高可用性、故障自动切换和数据分片能力,可以随着数据量的增长进行线性水平扩展,满足未来业务发展的需求。
- 作为开源软件,IoTDB 软件本身免费,用户可以自由下载和使用,降低了软件许可费用。
IoTDB应用编程示例:
C++
#include "Session.h"
#include <iostream>
#include <string>
#include <vector>
#include <sstream>
int main(int argc, char **argv)
{
Session *session = new Session("127.0.0.1", 6667, "root", "root");
session->open();
std::vector<std::pair<std::string, TSDataType::TSDataType>> schemas;
schemas.push_back({"s0", TSDataType::INT64});
schemas.push_back({"s1", TSDataType::INT64});
schemas.push_back({"s2", TSDataType::INT64});
int64_t val = 0;
Tablet tablet("root.db.d1", schemas, /*maxRowNum=*/ 10);
tablet.rowSize++;
tablet.timestamps[0] = 0;
val=100; tablet.addValue(/*schemaId=*/ 0, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=200; tablet.addValue(/*schemaId=*/ 1, /*rowIndex=*/ 0, /*valAddr=*/ &val);
val=300; tablet.addValue(/*schemaId=*/ 2, /*rowIndex=*/ 0, /*valAddr=*/ &val);
session->insertTablet(tablet);
tablet.reset();
std::unique_ptr<SessionDataSet> res = session->executeQueryStatement("select ** from root.db");
while (res->hasNext()) {
std::cout << res->next()->toString() << std::endl;
}
res.reset();
session->close();
delete session;
return 0;
}
Java
package org.apache.iotdb;
import org.apache.iotdb.isession.SessionDataSet;
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
public class SessionExample {
private static Session session;
public static void main(String[] args)
throws IoTDBConnectionException, StatementExecutionException {
session =
new Session.Builder()
.host("172.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("s1", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s2", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("s3", TSDataType.FLOAT));
Tablet tablet = new Tablet("root.db.d1", schemaList, 10);
tablet.addTimestamp(0, 1);
tablet.addValue("s1", 0, 1.23f);
tablet.addValue("s2", 0, 1.23f);
tablet.addValue("s3", 0, 1.23f);
tablet.rowSize++;
session.insertTablet(tablet);
tablet.reset();
try (SessionDataSet dataSet = session.executeQueryStatement("select ** from root.db")) {
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
}
}
session.close();
}
}
IoTDB典型应用场景:
- 设备状态监控与预测性维护:实时采集生产线上的各类设备(如机床、风机、泵、机器人等)的运行数据(温度、振动、电流、压力、转速等)。
- 电网运行监控与故障诊断:实时采集变电站、输电线路、配电网的电压、电流、功率、频率等数据,以及智能电表的用户用电数据。
- 新能源发电预测与调度:收集风力、光伏发电站的实时发电量、气象数据(风速、光照等)。
- 环境监测与预警:实时采集城市各区域的空气质量(PM2.5、CO2、O3等)、噪音、水质等环境数据。
- 智能交通流量分析:收集道路传感器、摄像头捕获的车辆流量、速度、拥堵指数等交通数据。
- 车辆状态监控与故障诊断:实时采集车辆的发动机转速、油耗、电池电量、轮胎压力、车辆位置等数据。
- 驾驶行为分析与车队管理:分析车辆的加速、减速、急转弯等驾驶行为数据,以及车辆的行驶轨迹。
- 农作物生长环境监测:实时监测大棚或农田的温度、湿度、光照、土壤水分、PH值等环境参数。
- 畜牧养殖精细化管理:监测牲畜的体温、活动量、心率等生理指标,以及养殖场的环境数据。
五、结束语
在物联网(IoT)浪潮席卷全球的今天,海量时序数据的有效管理、存储与分析,已成为推动各行业数字化转型和智能化升级的关键。Apache IoTDB 作为一款专为物联网场景设计和优化的时序数据库,凭借其独特的技术优势和卓越性能,正在成为解决这一挑战的理想选择。
Apache IoTDB 不仅仅是一个时序数据库,它更是物联网时代数据基础设施的关键组成部分。随着物联网应用的不断深化和技术演进,IoTDB 将持续发挥其核心优势,不断创新,为构建万物互联的智能世界提供坚实的数据基石,助力各行业实现真正的数字化、智能化转型。


永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 41
41 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)