pytorch学习笔记-使用DataLoader加载固有Datasets(CIFAR10),使用tensorboard进行可视化
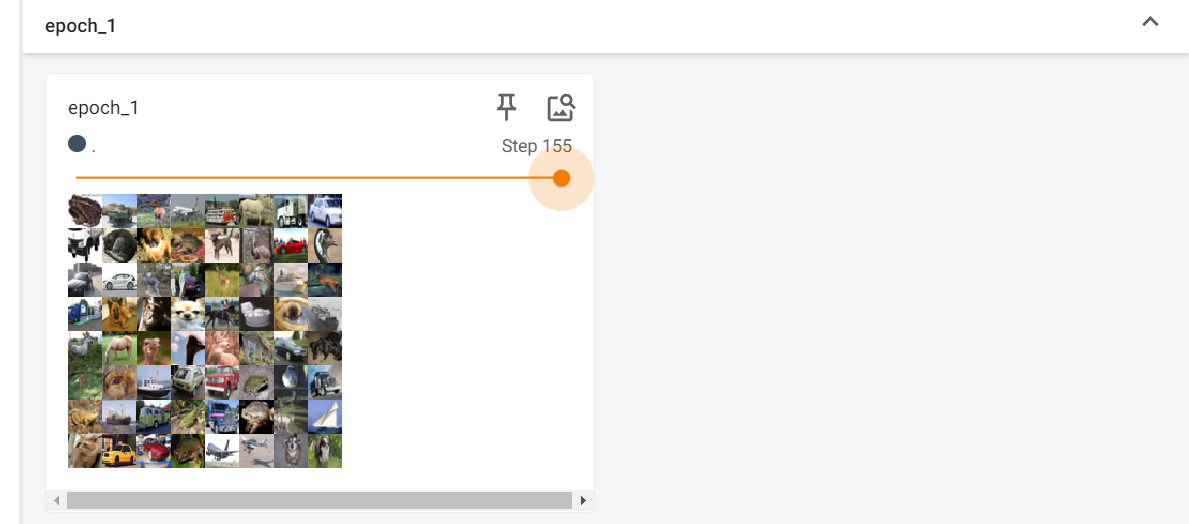
说明一下下面的transforms虽然只用了一个可以直接写到datasets.CIFAR10里面完全没问题,但是我还是更加建议下面的这样写,感觉是一个更好的习惯,对于以后使用多个transform的组合时很有利~随便截了不同epoch的最后一个batch构成情况,可以看到内容组合不一样,这是因为我们进行了打乱操作,这样可以保证不同的epoch学习到的batch组合情况不一样。呃这里为什么要单独列出
·
大概就是DataLoader的基本语法操作吧…毕竟博主也是刚开始学习
import torchvision
from torchvision import transforms, datasets
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
说明一下下面的transforms虽然只用了一个可以直接写到datasets.CIFAR10里面完全没问题,但是我还是更加建议下面的这样写,感觉是一个更好的习惯,对于以后使用多个transform的组合时很有利~
transfrom的使用具体可以参考上一篇blog
#设置通用transforms
dataset_transfroms = transforms.Compose([
transforms.ToTensor()
])
test_data = datasets.CIFAR10(root="./dataset",
train=False,
transform=dataset_transfroms)
num_workers:采用设置的子进程加载数据到内存
drop_last:数据总量对batch_size取余,余数部分是否drop
呃这里为什么要单独列出来一下呢是因为想提醒一下最好drop,因为博主隐约记得自己好像踩过batch_size大小不一样的报错坑(
# num_workers:采用设置的子进程加载数据到内存
# drop_last:数据总量对batch_size取余,余数部分是否drop
test_loader = DataLoader(dataset=test_data,
batch_size=64,
shuffle=True,
num_workers=0,
drop_last=True)
# img, target = test_data[0]
writer = SummaryWriter("dataloader_logs")
注(以下为个人理解,有错欢迎指正):
- test_loader是按批次读取的,一次读出的(也就是data)是含有batch_size个图片的
- 单次epoch中需要学到所有数据
- 内循环中,会将所有数据都遍历到,外层循环中,决定epoch次学习所有数据
- 在深度学习训练中,对数据进行打乱,然后多次epoch读取到不同内容组合的batch数据进行学习
# test_loader是按批次读取的,一次读出的(也就是data)是含有batch_size个图片的
# 单次epoch中需要学到所有数据
# 内循环中,会将所有数据都遍历到,外层循环中,决定epoch次学习所有数据
# 在深度学习训练中,对数据进行打乱,然后多次epoch读取到不同内容的batch的数据进行学习
# 添加多张图是add_images
for epoch in range(5):
step=0
for data in test_loader:
imgs, target = data
writer.add_images("epoch_{}".format(epoch),imgs,step)
step +=1
writer.close()
# tensorboard --logdir=dataloader_logs
随便截了不同epoch的最后一个batch构成情况,可以看到内容组合不一样,这是因为我们进行了打乱操作,这样可以保证不同的epoch学习到的batch组合情况不一样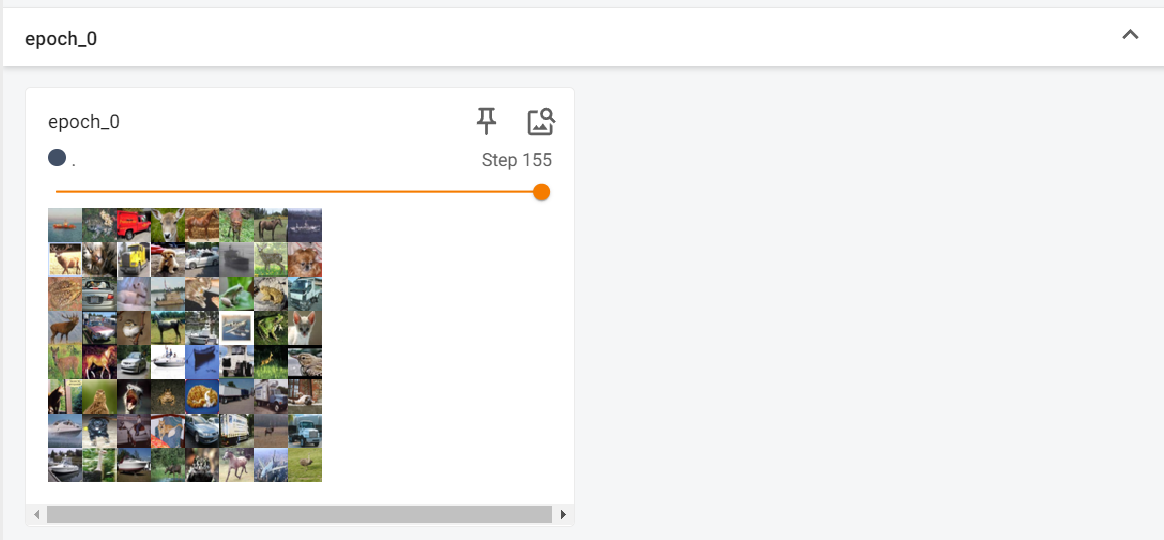

永洪科技,致力于打造全球领先的数据技术厂商,具备从数据应用方案咨询、BI、AIGC智能分析、数字孪生、数据资产、数据治理、数据实施的端到端大数据价值服务能力。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)